Pretrained Model
- 미리 학습된 모델.
- Pretrained model을 이용해 현재 문제를 해결한다.
- 새로 모델을 정의 하고 학습시키는 것 보다 Pretrained 모델을 사용해 모델을 정의하면 훨씬 좋은 성능의 모델을 만들 수 있다.
- Pretrain model을 사용하는 방식
- 제로샷 전이학습(Zero shot transfer learning)
- 추가 학습없어 Pretrained 모델을 해결하려는 문제에 그대로 사용한다.
- 전이학습 (Transfer learning)
- Pretrained 모델의 일부분을 재학습 시킨다. 주로 출력 Layer를 학습시킨다.
- 미세조정 (Fine tuning)
- Pretrained 모델의 파라미터를 초기 파라미터로 사용하여 Custom Dataset으로 학습을 진행하여 모델의 모든 파라미터를 업데이트 시킨다.
- 제로샷 전이학습(Zero shot transfer learning)
Pytorch에서 제공하는 Pretrained Model
- 분야별 라이브러리에서 제공
- torchvision: https://pytorch.org/vision/stable/models.html
- torch hub 를 이용해 모델과 학습된 parameter를 사용할 수 있다.
- 이외에도 많은 모델과 학습된 paramter가 인터넷상에 공개되 있다.
- 딥러닝 모델기반 application을 개발 할 때는 대부분 Transfer Learning을 한다.
- 다양한 분야에서 연구된 많은 딥러닝 모델들이 구현되어 공개 되어 있으며 학습된 Parameter들도 제공되고 있다.
- paperswithcode에서 State Of The Art(SOTA) 논문들과 그 구현된 모델을 확인할 수 있다.
State Of The Art(SOTA): 특정 시점에 특정 분야에서 가장 성능이 좋은 모델을 말한다.
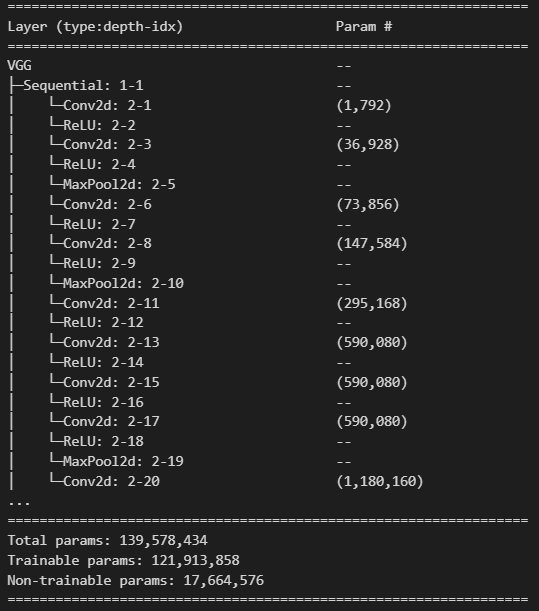
VGGNet Pretrained 모델을 이용해 이미지 분류
- Pytorch가 제공하는 VGG 모델은 ImageNet dataset으로 학습시킨 weight를 제공한다.
- 120만장의 trainset, 1000개의 class로 구성된 데이터셋.
- Output으로 1000개의 카테고리에 대한 확률을 출력한다.
# ImageNet 1000개의 class 목록 !pip install wget import wget url = 'https://gist.github.com/yrevar/942d3a0ac09ec9e5eb3a/raw/238f720ff059c1f82f368259d1ca4ffa5dd8f9f5/imagenet1000_clsidx_to_labels.txt' imagenet_filepath = wget.download(url)#image net label 텍스트파일을 dictionry 읽기 ### JSON 형식 텍스트파일 -> json 표준모듈 사용. (key: 정수이면 loading시 Exception발생.) with open("imagenet1000_clsidx_to_labels.txt", "rt") as fr: index_to_class = eval(fr.read())
Pretrained Model 로딩
import torch from torchvision import models, transforms #models: Pretrained모델클래스 제공 모듈 from torchinfo import summary device = 'cuda' if torch.cuda.is_available() else "cpu" print(device)cpu
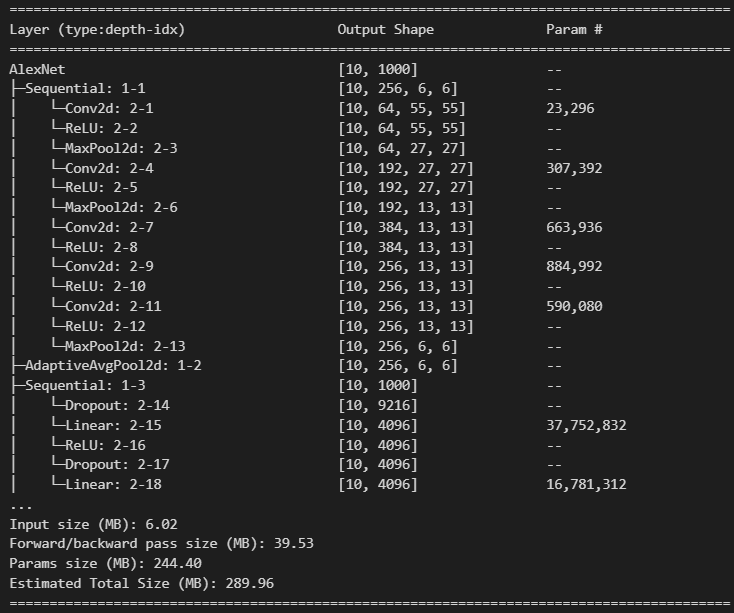
load_model = models.vgg19( #weights=models.VGG19_Weights.IMAGENET1K_V1, # ImageNet 으로 학습된 파라미터 weights=models.VGG19_Weights.DEFAULT, # default 학습 파라미터(최신)를 사용. )alexnet = models.alexnet(weights=models.AlexNet_Weights.DEFAULT)summary(alexnet, (10, 3, 224, 224))
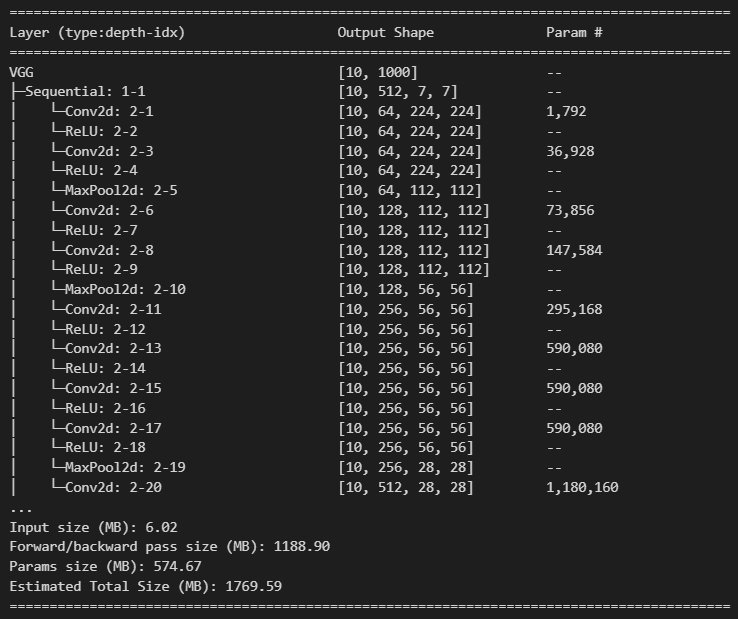
summary(load_model, (10, 3, 224, 224))
# 추론할 이미지 다운로드 import requests from io import BytesIO from PIL import Image # img_url = 'https://upload.wikimedia.org/wikipedia/commons/thumb/2/25/Common_goldfish.JPG/800px-Common_goldfish.JPG' # img_url = 'https://cdn.download.ams.birds.cornell.edu/api/v1/asset/169231441/1800' # img_url = 'https://blogs.ifas.ufl.edu/news/files/2021/10/anole-FB.jpg' # img_url = 'https://i.namu.wiki/i/cYqEXrePCtlQsBwfGI74KsAGtBLbWuusa1mFKURGpZ3tRawwqwPzoohZLKkZthemCqDrTgh_SVRMgVB430-s9OA6fhafsOwBiGmfS2izCtPcrCB6RkHp5xqFd-StNUA7bmwnFPE-wERW8LSFYSPH3Q.webp' img_url = 'https://upload.wikimedia.org/wikipedia/commons/thumb/2/26/YellowLabradorLooking_new.jpg/640px-YellowLabradorLooking_new.jpg' res = requests.get(img_url) # Image.open(BytesIO()) # 메모리의 image를 PIL를 이용해서 조회. test_img = Image.open(BytesIO(res.content)) # res: http 응답정보. res.content: 다운받은 binary 파일 test_img
# transform - > ToTensor(), Resize() transform = transforms.Compose([ transforms.Resize((224, 224)), # Pretained 모델 입력 size transforms.ToTensor(), #PIL.Image -> torch.Tensor, 0 ~ 1, channel first ])input_data = transform(test_img).unsqueeze(dim=0) input_data.shapetorch.Size([1, 3, 224, 224])
model = load_model.to(device) with torch.no_grad(): pred = model(input_data)pred.shape # class가 1000개.torch.Size([1, 1000])
pred_index = pred.argmax(dim=1) pred_proba = pred.softmax(dim=1).max(dim=1).values print(pred_index, pred_proba)tensor([208]) tensor([0.7751])
pred_class = index_to_class[pred_index.item()] pred_class'Labrador retriever'

Transfer learning (전이학습)
- 사전에 학습된 신경망의 구조와 파라미터를 재사용해서 새로운 모델(우리가 만드는 모델)의 시작점으로 삼고 해결하려는 문제를 위해 다시 학습시킨다.
- 전이 학습을 통해 다음을 해결할 수 있다.
- 데이터 부족문제
- 딥러닝은 대용량의 학습데이터가 필요하다.
- 충분한 데이터를 수집하는 것은 항상 어렵다.
- 과다한 계산량
- 신경망 학습에는 엄청난 양의 계산 자원이 필요하다.
- 데이터 부족문제
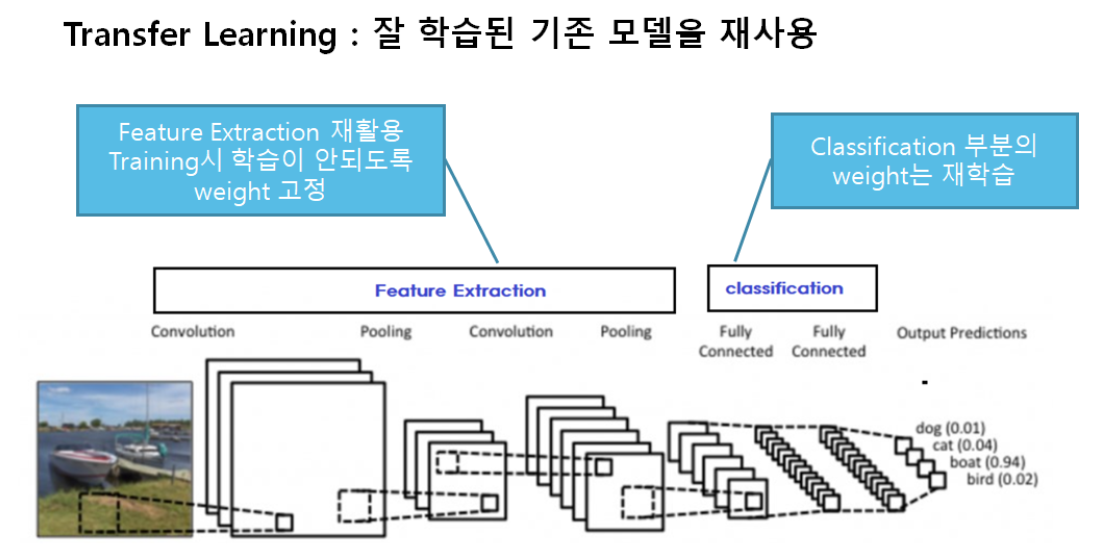
- 미리 학습된(pre-trained) Model을 이용하여 모델을 구성한 뒤 현재 하려는 예측 문제를 해결한다.
- 보통 Pretrained Model에서 Feature Extraction 부분을 사용한다.
- Computer Vision 문제의 경우 Bottom 쪽의 Convolution Layer(Feature Extractor)들은 이미지에 나타나는 일반적인 특성을 추출하므로 다른 대상을 가지고 학습했다고 하더라도 재사용할 수 있다.
- Top 부분 Layer 부분은 특히 출력 Layer의 경우 대상 데이터셋의 목적에 맞게 변경 해야 하므로 재사용할 수 없다.
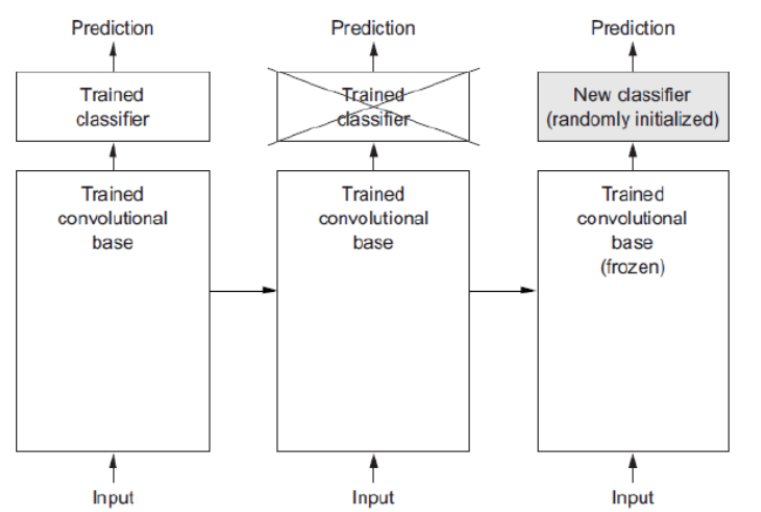
Frozon: Training시 parameter가 update 되지 않도록 하는 것을 말한다.
Feature extraction 재사용
- Pretrained Model에서 Feature Extractor 만 가져오고 추론기(Fully connected layer)만 새로 정의한 뒤 그 둘을 합쳐서 모델을 만든다.
- 학습시 직접 구성한 추론기만 학습되도록 한다.
- Feature Extractor는 추론을 위한 Feature 추출을 하는 역할만 하고 그 parameter(weight)가 학습되지 않도록 한다.
- 모델/레이어의 parameter trainable 여부 속성 변경
- model/layer 의
parameters()메소드를 이용해 weight와 bias를 조회한 뒤requires_grad속성을False로 변경한다.
- model/layer 의
Backbone, Base network
전체 네트워크에서 Feature Extraction의 역할을 담당하는 부분을 backbone/base network라고 한다. 추론을 담당하는 block은 head 라고 한다.
Fine-tuning(미세조정)
- Transfer Learning을 위한 Pretrained 모델을 내가 학습시켜야 하는 데이터셋(Custom Dataset)으로 재학습시키는 것을 fine tunning 이라고 한다.
- 주어진 문제에 더 적합하도록 Feature Extractor의 가중치들도 조정 한다.
Fine tuning 전략
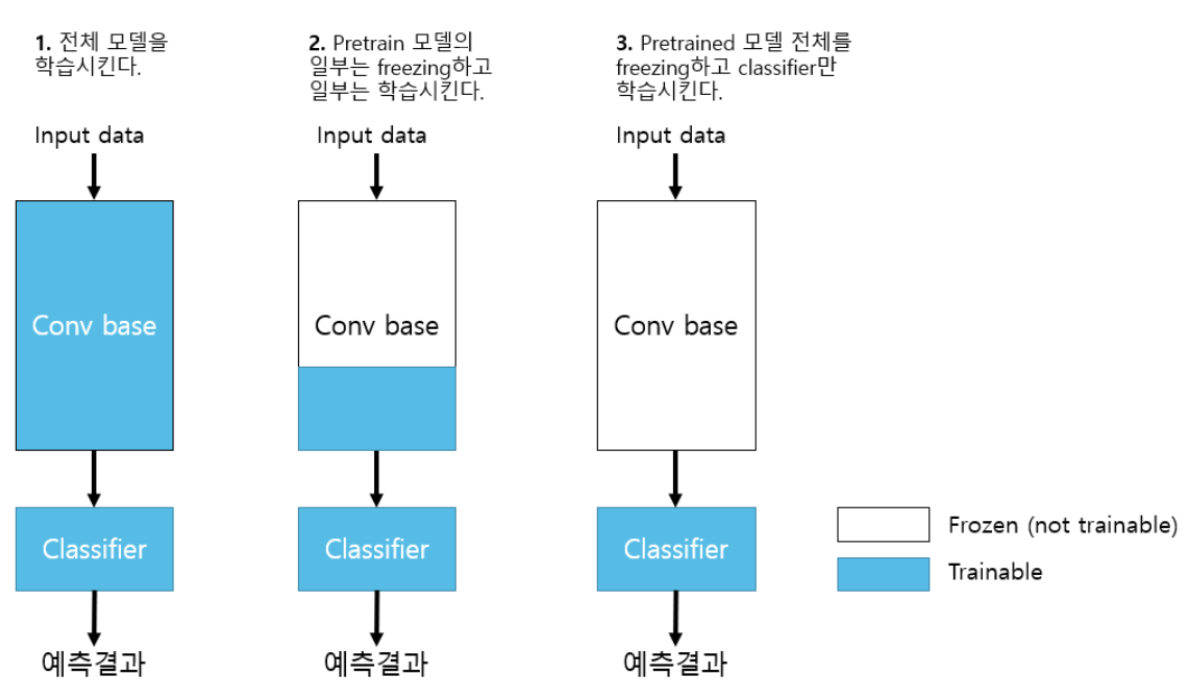
- 세 전략 모두 추론기는 trainable로 한다.
1. 전체 모델을 전부 학습시킨다.(1번)
- Pretrained 모델의 weight는 Feature extraction 의 초기 weight 역할을 한다.
- Train dataset의 양이 많고 Pretrained 모델이 학습했던 dataset과 Custom dataset의 class간의 유사성이 낮은 경우 적용.
- 학습에 시간이 많이 걸린다.
2. Pretrained 모델 Bottom layer들(Input과 가까운 Layer들)은 고정시키고 Top layer의 일부를 재학습시킨다.(2번)
- Train dataset의 양이 많고 Pretrained 모델이 학습했던 dataset과 Custom dataset의 class간의 유사성이 높은 경우 적용.
- Train dataset의 양이 적고 Pretained 모델이 학습했던 dataset과 custom dataset의 class간의 유사성이 낮은 경우 적용
3. Pretrained 모델 전체를 고정시키고 classifier layer들만 학습시킨다.(3번)
- Train dataset의 양이 적고 Pretrained 모델이 학습했던 dataset과 Custom dataset의 class간의 유사성이 높은 경우 적용.
Custom dataset: 내가 학습시키고자 하는 dataset
1번 2번 전략을 Fine tuning 이라고 한다.

# google colab에서 실행시 src_path = "/content/drive/MyDrive/DeepLearning_class/module" target_path = "/content/module" import shutil shutil.copytree(src_path , target_path)import torch import torch.nn as nn import torch.optim as optim from torchvision import models, datasets, transforms from torchinfo import summary from torch.utils.data import DataLoader from module.train import fit from module.utils import plot_fit_result import os from zipfile import ZipFile !pip install gdown -U import gdown # 사용전에 항상 upgrade를 하는 것이 좋다. device = 'cuda' if torch.cuda.is_available() else "cpu"# download url = 'https://drive.google.com/uc?id=1YIxDL0XJhhAMdScdRUfDgccAqyCw5-ZV' path = r'data/cats_and_dogs_small.zip' gdown.download(url, path, quiet=False)# 압축 풀기 target_path = 'data/cats_and_dogs' with ZipFile(path) as zf: # 압축파일 경로를 넣어서 생성. zf.extractall(target_path) # 지정한 디렉토리에 압축 품. (default: 현재 작업 디렉토리.)#### 개/고양이 분류 이미지 데이터셋11126112 ## Train: 2000장(고양이: 1000, 개: 1000) ## Validation/Test: 각각 1000장 (고양이: 500, 개: 500)#### 하이퍼파라미터 변수 정의 batch_size = 64 epochs = 1 lr = 0.001Dataset, DataLoader
Dataset
- torchvision.datasets.ImageFolder를 이용
- transform: image augmentation 정의
# transforms ### trainset용, testset/validation용을 다르게 정의 ### trainset: augmentation 적용, test/validation set은 augmentation을 적용하지 않는다. ### transform 정의 -> ### 입력으로 ndarray가 들어올 경우 torch.Tensor나 PIL.Image 객체로 변환. ## 대부분 augmentation 함수들은 입력으로 torch.Tensor나 PIL의 Image객체를 받는다. ### transform 정의 순서 -> augmentation -> resize -> ToTensor -> Normalizetrain_transform = transforms.Compose([ transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.5, hue=0.15),# 값 1개: (1-값 ~ 1+값) transforms.RandomHorizontalFlip(), # p=0.5(default) transforms.RandomVerticalFlip(), transforms.RandomRotation(degrees=180), # -180 ~ 180 (360 내에서 랜덤하게 회전.) transforms.Resize((224, 224)), # Model의 input size에 맞춰서 resize transforms.ToTensor(), # augmentation 다음에 진행. (0 ~ 1 scaling.) # transforms.RandomErasing(), # 입력으로 torch.Tensor만 가능 transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) # ImageNet에 적용해서 좋았던 값들. ## Standard Scaling{(pixcel-평균)/표준편차}-> (평균, 표준편차) -> tuple(채널별) ]) # validation/test set 용 transform. test_transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) ])os.path.join(target_path, "train")'data/cats_and_dogs\train'
# Dataset 정의 train_set = datasets.ImageFolder( os.path.join(target_path, "train"), # Dataset 디렉토리 transform=train_transform # transform 설정. ) valid_set = datasets.ImageFolder( os.path.join(target_path, "validation"), transform=test_transform ) test_set = datasets.ImageFolder( os.path.join(target_path, 'test'), transform=test_transform )# train_set # valid_set test_setDataset ImageFolder
Number of datapoints: 1000
Root location: data/cats_and_dogs\test
StandardTransform
Transform: Compose(
Resize(size=(224, 224), interpolation=bilinear, max_size=None, antialias=True)
ToTensor()
Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
)### class 확인 print(train_set.classes) print(train_set.class_to_idx) ### dataset size 확인 print(len(train_set), len(valid_set), len(test_set))['cats', 'dogs']
{'cats': 0, 'dogs': 1}
2000 1000 1000DataLoader
os.cpu_count() # cpu 작업할 할수 있는 thread개수 가 16개. => 개수 조회.16
from torch.utils.data import DataLoadertrain_loader = DataLoader( train_set, batch_size=batch_size, shuffle=True, drop_last=True, num_workers=os.cpu_count() # Dataset에서 datapoint loading(CPU작업)을 병렬로 처리한다. # -> cpu개수 지정.=>한번에 몇개씩 가져올것인지 지정 ) valid_loader = DataLoader(valid_set, batch_size=batch_size, num_workers=os.cpu_count()) test_loader = DataLoader(test_set, batch_size=batch_size, num_workers=os.cpu_count())# step 수 - len(DataLoader) print(len(train_loader), len(test_loader), len(valid_loader))31 16 16
# 이미지 확인 ## 1 batch 조회 batch_one = next(iter(train_loader)) # List - (X들, y들) type(batch_one)list
len(batch_one)2
batch_one[1][1] # 0: cats, 1: dogstensor(0)
batch_one[1].shapetorch.Size([64])
batch_one[0].shape # image들torch.Size([64, 3, 224, 224])
import matplotlib.pyplot as plt plt.imshow(batch_one[0][25].permute(1, 2, 0)) plt.show()
Transfer Learing
- VGG19 모델을 가져와서 Feature Extractor (Conv base) 부분을 사용해 모델 정의
- Feature Extractor: VGG19, Classifier: 새로 정의
- Feature Extractor 는 frozen 시킨다.
모델의 파라미터 frozen 시키기.
- model.parameters()
- 모델의 모든 파라미터들(weight, bias)을 제공하는 generator.
- layer 별로 weight->bias 순으로 제공.
- 파라미터의 학습가능 여부
파라미터.requires_grade값에 따라 결정.True: 학습가능(tainable),False: 학습이 안되는 파라미터(Frozon-none trainable)
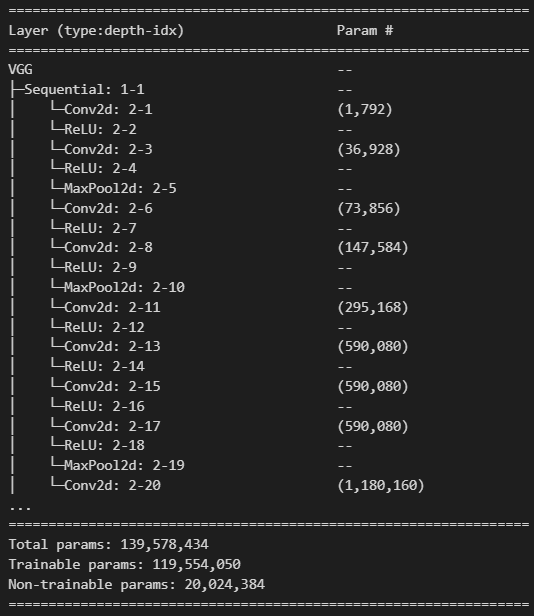
test_model = models.vgg19(weights=models.VGG19_Weights.DEFAULT)# test_model 확인 ## layer 함수 객체들 확인 print(test_model) # (features): Sequential -> features: Sequential객체가 할당된 instance변수 이름. # Sequential: Layer의 타입. #### __init__() -> self.features = nn.Sequntial(....)VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): ReLU(inplace=True)
(18): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(19): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(24): ReLU(inplace=True)
(25): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(26): ReLU(inplace=True)
(27): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(31): ReLU(inplace=True)
(32): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(33): ReLU(inplace=True)
(34): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(35): ReLU(inplace=True)
(36): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)## 모델의 파라미터들 조회 for param in test_model.parameters(): print(type(param), param.shape, param.requires_grad, sep=" || ")<class 'torch.nn.parameter.Parameter'> || torch.Size([64, 3, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([64]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([64, 64, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([64]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([128, 64, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([128]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([128, 128, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([128]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([256, 128, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([256]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([256, 256, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([256]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([256, 256, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([256]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([256, 256, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([256]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512, 256, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512, 512, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512, 512, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512, 512, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512, 512, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512, 512, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512, 512, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512, 512, 3, 3]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([512]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([4096, 25088]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([4096]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([4096, 4096]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([4096]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([1000, 4096]) || True
<class 'torch.nn.parameter.Parameter'> || torch.Size([1000]) || True# Conv2d(3:입력채널수-필터1개의 채널수, 64:출력채널-필터개수, kernel_size=(3:h, 3:w), ...)\ # 필터shape: 64, 3, 3, 3# 파라미터들을 frozon: 학습이 안되도록 상태를 변경. requires_grad 속성을 False로 변경 for param in test_model.parameters(): param.requires_grad = False모델 정의
model = models.vgg19(models.VGG19_Weights.DEFAULT) # 모든 파라미터를 non-trainable 변경. (frozon) for param in model.parameters(): param.requires_grad = Falsesummary(model)
model.classifier = nn.Sequential( nn.Linear(in_features=25088, out_features=4096), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(4096, 2) # cats, dogs 두개를 분류. )summary(model)
Train
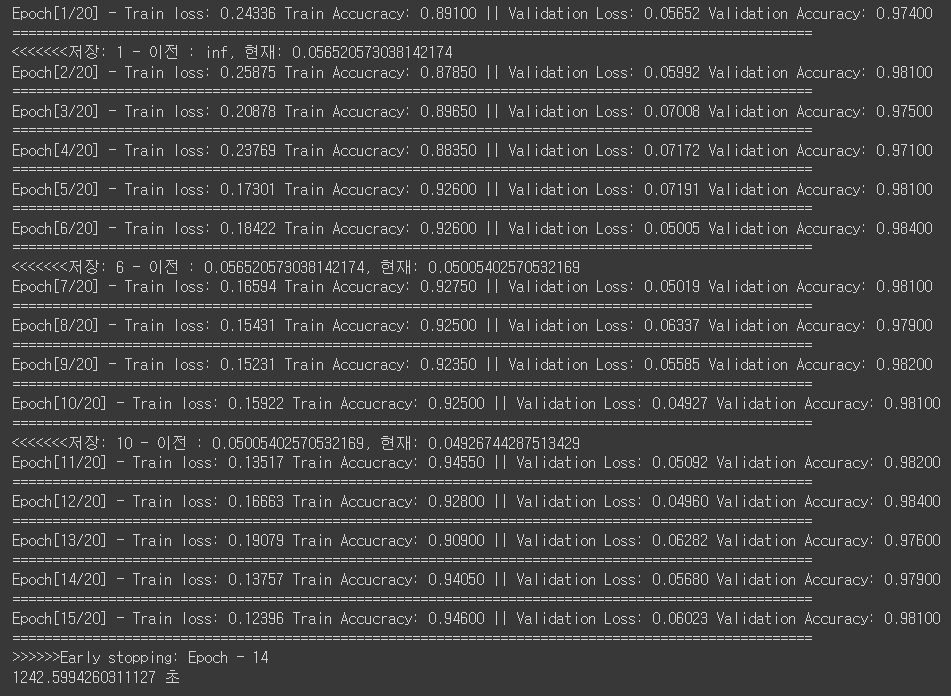
# save_path = 'saved_models/cat_dog_vgg19_base_model.pth' save_path = '/content/drive/MyDrive/DeepLearning_class/saved_models/cat_dog_vgg19_base_model.pth' model = model.to(device) loss_fn = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=lr) epochs = 20 # 위의 변수를 변경. result = fit(train_loader, valid_loader, model, loss_fn, optimizer, epochs, save_best_model=True, save_model_path=save_path, device=device, mode='multi', early_stopping=True, patience=5)
from module.train import test_multi_classification model.to(device) loss, acc = test_multi_classification(test_loader, model, loss_fn, device=device)print(loss, acc)0.06257702608854743 0.981
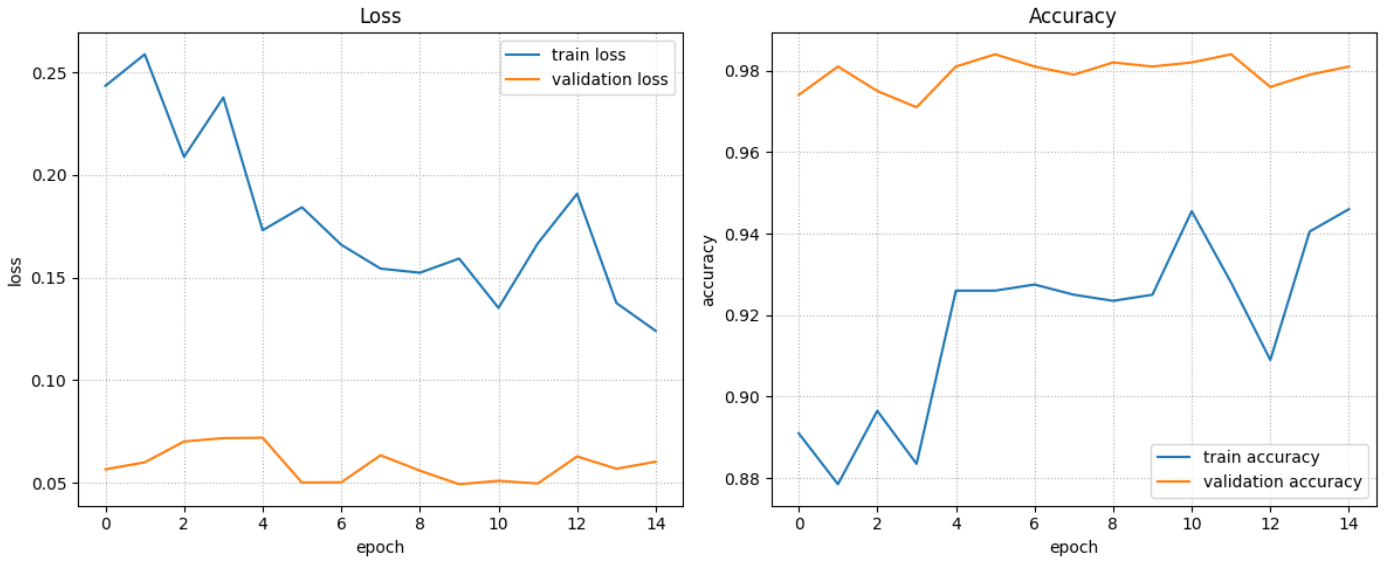
plot_fit_result(*result)
Backbone 의 일부를 학습
- Top 쪽 layer들을 학습하고 Bottom 쪽 Layer들은 frozon.
import torch import torch.nn as nn import torch.optim as optim from torchvision import models, datasets, transforms !pip install torchinfo from torchinfo import summary from torch.utils.data import DataLoader from module.train import fit from module.utils import plot_fit_result import os from zipfile import ZipFile !pip install gdown -U import gdown # 사용전에 항상 upgrade를 하는 것이 좋다. device = 'cuda' if torch.cuda.is_available() else "cpu" deviceos.makedirs("data", exist_ok=True) # download url = 'https://drive.google.com/uc?id=1YIxDL0XJhhAMdScdRUfDgccAqyCw5-ZV' path = r'data/cats_and_dogs_small.zip' gdown.download(url, path, quiet=False)# 압축 풀기 target_path = 'data/cats_and_dogs' with ZipFile(path) as zf: # 압축파일 경로를 넣어서 생성. zf.extractall(target_path) # 지정한 디렉토리에 압축 품. (default: 현재 작업 디렉토리.)#### 하이퍼파라미터 변수 정의 batch_size = 64 epochs = 20 lr = 0.001Transform, Dataset, DataLoader 생성
- trainset transform은 augmentation 적용.
- Dataset: cats_and_dogs_small dataset 이용
- train, test, valid
# Transform train_transform = transforms.Compose([ transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.5, hue=0.15), transforms.RandomHorizontalFlip(), transforms.RandomVerticalFlip(), transforms.RandomRotation(degrees=180), transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) ]) test_transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) ])# dataset # data_path = r"C:\Classes\deeplearning\datasets\cats_and_dogs_small" data_path = "data/cats_and_dogs/" train_set = datasets.ImageFolder(os.path.join(data_path, "train"), transform=train_transform) valid_set = datasets.ImageFolder(os.path.join(data_path, "validation"), transform=test_transform) test_set = datasets.ImageFolder(os.path.join(data_path, "test"), transform=test_transform)epochs = 1 batch_size = 64 lr = 0.001VGG19 모델을 이용해서 모델 생성.
model = models.vgg19(weights=models.VGG19_Weights.DEFAULT)# Frozon ### model.features(instance 변수명) Sequential에 있는 layer 함수들. 0 ~ 33 ### 34 ~ : trainable # nn.Sequential : iterable -> for in : Layer를 반환. ## model.parameters(): 모델안의 모든 weight, bias 들을 하나씩 제공하는 generator ## Layer.parameters() : Layer의 weight와 bias를 하나씩 제공. for i, layer in enumerate(model.features): if i <= 33: # 0 ~ 33 index의 layer들의 parameter들 requires_grad=False(Frozon) for param in layer.parameters(): param.requires_grad = Falsefor weight in model.parameters(): print(weight.requires_grad)False
False
False
False
False
False
False
False
False
False
False
False
False
False
False
False
False
False
False
False
False
False
False
False
False
...
True
True
True
True
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...## classifier를 변경. model.classifier = nn.Sequential( nn.Linear(25088, 4096), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(4096, 2) )summary(model)
### train model = model.to(device) loss_fn = nn.CrossEntropyLoss() optim = optim.Adam(model.parameters(), lr=lr) # saved_model_path = r"saved_models/cat_dog_finetuning_model.pth" saved_model_path = "/content/drive/MyDrive/DeepLearning_class/saved_models/cat_dog_finetuning_model.pth" epochs = 20 result = fit(train_loader, valid_loader, model, loss_fn, optim, epochs, save_model_path=saved_model_path, patience=3, mode="multi", device=device)Epoch[1/20] - Train loss: 0.30844 Train Accucracy: 0.87150 || Validation Loss: 0.09920 Validation Accuracy: 0.97200
<<<<<<<저장: 1 - 이전 : inf, 현재: 0.09919649321091129
Epoch[2/20] - Train loss: 0.22754 Train Accucracy: 0.89900 || Validation Loss: 0.04879 Validation Accuracy: 0.97600
<<<<<<<저장: 2 - 이전 : 0.09919649321091129, 현재: 0.04879064951092005
Epoch[3/20] - Train loss: 0.18927 Train Accucracy: 0.91350 || Validation Loss: 0.04549 Validation Accuracy: 0.97900
<<<<<<<저장: 3 - 이전 : 0.04879064951092005, 현재: 0.045494507081457414
Epoch[4/20] - Train loss: 0.20847 Train Accucracy: 0.90500 || Validation Loss: 0.06108 Validation Accuracy: 0.97700
Epoch[5/20] - Train loss: 0.17952 Train Accucracy: 0.92050 || Validation Loss: 0.02826 Validation Accuracy: 0.98800
<<<<<<<저장: 5 - 이전 : 0.045494507081457414, 현재: 0.028261271509109065
Epoch[6/20] - Train loss: 0.20338 Train Accucracy: 0.91900 || Validation Loss: 0.03200 Validation Accuracy: 0.98700
Epoch[7/20] - Train loss: 0.18603 Train Accucracy: 0.92100 || Validation Loss: 0.06027 Validation Accuracy: 0.98100
Epoch[8/20] - Train loss: 0.18817 Train Accucracy: 0.92300 || Validation Loss: 0.06522 Validation Accuracy: 0.97300
<<<<<<<<Early stopping: Epoch - 7
672.3558197021484 초최종평가
from module.train import test_multi_classification model.to(device) loss, acc = test_multi_classification(test_loader, model, loss_fn, device=device) print(loss, acc)0.07444948515694705 0.977
새로운 데이터 추정
import torch from PIL import Image from torchvision import transforms# 추론함수 def predict(image_path, model, transform, device): # "model로 image_path의 이미지를 추론한 결과를 반환." img = Image.open(image_path) # 추론대상 이미지 loading input_data = transform(img) # shape: (C, H, W) input_data = input_data.unsqueeze(dim=0) # (C, H, W) -> (1, C, H, W) input_data = input_data.to(device) # 추론 model = model.to(device) model.eval() with torch.no_grad(): pred = model(input_data) pred_proba = pred.softmax(dim=-1) # 확률값으로 변경. pred_label = pred_proba.argmax(dim=-1).item() # Tensor([3]) -> 3 pred_proba_max = pred_proba.max(dim=-1).values.item() class_name = "cat" if pred_label == 0 else "dog" return pred_label, class_name, pred_proba_max # (0, cat, 0.87)best_model = torch.load("saved_models/cat_dog_finetuning_model.pth", map_location=torch.device(device)) # 추정할 때 사용할 transform -> test, validation용과 동일하게 정의 (augmentation은 안함.) transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) ])path = "test_img/cat.jpg" path = "test_img/dog.jpg" path = "test_img/dog2.jfif" path = "test_img/image.jpg" result = predict( path, best_model, transform, "cpu" ) print(result)(1, 'dog', 0.9815358519554138)