모델 저장
- 학습한 모델을 저장장치에 파일로 저장하고 나중에 불러와 사용(추가 학습, 예측 서비스) 할 수 있도록 한다.
- 파이토치는 모델의 파라미터만 저장하는 방법과 모델 구조와 파라미터 모두를 저장하는 두가지 방식을 제공한다.
- 저장 함수
torch.save(저장할 객체, 저장경로)
- 보통 저장파일의 확장자는
pt나pth를 지정한다.
모델 전체 저장하기 및 불러오기
- 저장하기
torch.save(model, 저장경로)
- 불러오기
load_model = torch.load(저장경로)
- 저장시 pickle을 이용해 직렬화하기 때문에 불어오는 실행환경에도 모델을 저장할 때 사용한 클래스가 있어야 한다.
모델의 파라미터만 저장
- 모델을 구성하는 파라미터만 저장한다.
- 모델의 구조는 저장하지 않기 때문에 불러올 때 모델을 먼저 생성하고 생성한 모델에 불러온 파라미터를 덮어씌운다.
- 모델의 파라미터는 state_dict 형식으로 저장한다.
state_dict
- 모델의 파라미터 Tensor들을 레이어 단위별로 나누어 저장한 Ordered Dictionary (OrderedDict)
모델객체.state_dict()메소드를 이용해 조회한다.- 모델의 state_dict을 조회 후 저장한다.
torch.save(model.state_dict(), "저장경로")
- 생성된 모델에 읽어온 state_dict를 덮어씌운다.
new_model.load_state_dict(torch.load("state_dict저장경로"))
Checkpoint를 저장 및 불러오기
- 학습이 끝나지 않은 모델을 저장 후 나중에 이어서 학습시킬 경우에는 모델의 구조, 파라미터 뿐만 아니라 optimizer, loss 함수등 학습에 필요한 객체들을 저장해야 한다.
- Dictionary에 필요한 요소들을 key-value 쌍으로 저장후
torch.save()를 이용해 저장한다.
# 저장
torch.save({
'epoch':epoch,
'model_state_dict':model.state_dict(),
'optimizer_state_dict':optimizer.state_dict(),
'loss':train_loss
}, "저장경로")
# 불러오기
model = MyModel()
optimizer = optim.Adam(model.parameter())
# loading된 checkpoint 값 이용해 이전 학습상태 복원
checkpoint = torch.load("저장경로")
model.load_state_dict(checkpoint['model_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
epoch = checkpoint['epoch']
loss = checkpoint['loss']import torch from torch import nn class MyNetwork(nn.Module): def __init__(self): super().__init__() # nn.Module instance 초기화 self.lr = nn.Linear(784, 64) self.out = nn.Linear(64, 10) self.relu = nn.ReLU() def forward(self, X): X = torch.flatten(X, start_dim=1) X = self.lr1(X) X = self.relu(X) X = self.out(X) return Xsample_model = MyNetwork() # 모델을 저장 torch.save(sample_model, "saved_models/sample_model.pth") load_model = torch.load("saved_models/sample_model.pth")sample_model.out.weightParameter containing:
tensor([[ 0.1062, 0.0660, 0.0706, -0.1232, 0.0936, 0.0939, -0.1018, -0.1233,
0.1146, -0.0206, 0.0324, -0.0910, -0.0644, 0.0414, 0.0329, -0.0756,
-0.0999, 0.0689, -0.0079, -0.0006, 0.0372, 0.0741, 0.0557, 0.0426,
0.0567, 0.0768, 0.0302, 0.1181, 0.0750, 0.0716, 0.0661, 0.0324,
0.0204, 0.1200, 0.1226, 0.0099, -0.0411, 0.0362, -0.1211, -0.0642,
-0.0782, 0.0990, -0.0618, -0.0229, 0.0842, -0.0222, -0.0678, -0.0775,
0.0890, -0.1242, 0.0580, 0.1039, -0.0613, 0.1120, -0.0895, -0.1189,
-0.0090, -0.0771, 0.1222, 0.0278, 0.0568, 0.0611, -0.1173, 0.0980],
[-0.0403, -0.1164, -0.1014, -0.0152, 0.0437, 0.0548, 0.0632, 0.0700,
0.0834, -0.0079, -0.0647, 0.1155, -0.1225, 0.0784, 0.0746, 0.0355,
-0.0918, -0.0097, -0.0404, -0.1062, 0.0332, 0.0416, 0.0646, 0.1038,
0.0759, 0.0772, 0.0310, -0.0529, -0.0516, -0.1095, 0.0054, 0.1236,
-0.0246, -0.0313, 0.0074, 0.0229, -0.0427, 0.0905, 0.0733, -0.0442,
-0.0063, -0.0325, -0.1250, 0.0203, -0.0710, -0.0420, -0.0014, -0.0145,
0.0323, -0.0103, -0.0865, -0.0667, 0.0410, 0.0735, 0.0367, -0.0193,
-0.0270, 0.1074, -0.0356, -0.0410, 0.0646, 0.0148, -0.0853, 0.0222],
[ 0.1116, -0.0894, 0.0188, -0.0057, -0.0626, 0.1239, -0.1229, -0.0320,
0.1128, -0.0946, 0.1238, -0.0929, -0.0097, -0.0421, -0.0950, 0.1199,
0.0898, 0.0595, -0.0954, 0.0364, -0.1030, 0.0379, 0.0932, -0.0614,
-0.0817, -0.0060, 0.1057, -0.1019, -0.1074, 0.0415, -0.1136, -0.0997,
-0.1122, -0.1156, -0.1228, -0.0920, -0.0489, 0.0979, 0.0952, -0.0568,
0.0951, 0.0587, 0.0612, -0.0993, 0.0104, 0.0961, 0.0069, 0.1120,
0.0795, 0.1087, -0.0431, -0.0422, -0.0775, 0.0475, -0.0886, -0.0022,
-0.0598, -0.0642, -0.1144, 0.0723, 0.1092, -0.0545, 0.0416, 0.0111],
...
0.0808, -0.0778, -0.0265, -0.0946, -0.0095, 0.0061, -0.0168, 0.0826,
0.0985, 0.0983, -0.0846, 0.0148, 0.0792, 0.1174, -0.0230, -0.0810,
-0.0673, 0.0983, -0.0882, -0.0917, 0.0220, 0.0274, -0.0299, 0.0561,
0.0715, -0.0588, -0.0089, -0.1179, -0.0205, 0.1158, -0.1239, -0.0633]],
requires_grad=True)
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...load_model.out.weightParameter containing:
tensor([[ 0.1062, 0.0660, 0.0706, -0.1232, 0.0936, 0.0939, -0.1018, -0.1233,
0.1146, -0.0206, 0.0324, -0.0910, -0.0644, 0.0414, 0.0329, -0.0756,
-0.0999, 0.0689, -0.0079, -0.0006, 0.0372, 0.0741, 0.0557, 0.0426,
0.0567, 0.0768, 0.0302, 0.1181, 0.0750, 0.0716, 0.0661, 0.0324,
0.0204, 0.1200, 0.1226, 0.0099, -0.0411, 0.0362, -0.1211, -0.0642,
-0.0782, 0.0990, -0.0618, -0.0229, 0.0842, -0.0222, -0.0678, -0.0775,
0.0890, -0.1242, 0.0580, 0.1039, -0.0613, 0.1120, -0.0895, -0.1189,
-0.0090, -0.0771, 0.1222, 0.0278, 0.0568, 0.0611, -0.1173, 0.0980],
[-0.0403, -0.1164, -0.1014, -0.0152, 0.0437, 0.0548, 0.0632, 0.0700,
0.0834, -0.0079, -0.0647, 0.1155, -0.1225, 0.0784, 0.0746, 0.0355,
-0.0918, -0.0097, -0.0404, -0.1062, 0.0332, 0.0416, 0.0646, 0.1038,
0.0759, 0.0772, 0.0310, -0.0529, -0.0516, -0.1095, 0.0054, 0.1236,
-0.0246, -0.0313, 0.0074, 0.0229, -0.0427, 0.0905, 0.0733, -0.0442,
-0.0063, -0.0325, -0.1250, 0.0203, -0.0710, -0.0420, -0.0014, -0.0145,
0.0323, -0.0103, -0.0865, -0.0667, 0.0410, 0.0735, 0.0367, -0.0193,
-0.0270, 0.1074, -0.0356, -0.0410, 0.0646, 0.0148, -0.0853, 0.0222],
[ 0.1116, -0.0894, 0.0188, -0.0057, -0.0626, 0.1239, -0.1229, -0.0320,
0.1128, -0.0946, 0.1238, -0.0929, -0.0097, -0.0421, -0.0950, 0.1199,
0.0898, 0.0595, -0.0954, 0.0364, -0.1030, 0.0379, 0.0932, -0.0614,
-0.0817, -0.0060, 0.1057, -0.1019, -0.1074, 0.0415, -0.1136, -0.0997,
-0.1122, -0.1156, -0.1228, -0.0920, -0.0489, 0.0979, 0.0952, -0.0568,
0.0951, 0.0587, 0.0612, -0.0993, 0.0104, 0.0961, 0.0069, 0.1120,
0.0795, 0.1087, -0.0431, -0.0422, -0.0775, 0.0475, -0.0886, -0.0022,
-0.0598, -0.0642, -0.1144, 0.0723, 0.1092, -0.0545, 0.0416, 0.0111],
...
0.0808, -0.0778, -0.0265, -0.0946, -0.0095, 0.0061, -0.0168, 0.0826,
0.0985, 0.0983, -0.0846, 0.0148, 0.0792, 0.1174, -0.0230, -0.0810,
-0.0673, 0.0983, -0.0882, -0.0917, 0.0220, 0.0274, -0.0299, 0.0561,
0.0715, -0.0588, -0.0089, -0.1179, -0.0205, 0.1158, -0.1239, -0.0633]],
requires_grad=True)
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...#### static_dict 저장, load state_dict = sample_model.state_dict() print(type(state_dict))<class 'collections.OrderedDict'>
torch.save(state_dict, "saved_models/sample_model_weights.pth")load_state_dict = torch.load("saved_models/sample_model_weights.pth") type(load_state_dict)collections.OrderedDict
### 모델을 생성하고 load한 state_dict의 파라미터들도 변경(덮어쓰기) new_model = MyNetwork() new_model.load_state_dict(load_state_dict)new_model.out.weightParameter containing:
tensor([[ 0.1062, 0.0660, 0.0706, -0.1232, 0.0936, 0.0939, -0.1018, -0.1233,
0.1146, -0.0206, 0.0324, -0.0910, -0.0644, 0.0414, 0.0329, -0.0756,
-0.0999, 0.0689, -0.0079, -0.0006, 0.0372, 0.0741, 0.0557, 0.0426,
0.0567, 0.0768, 0.0302, 0.1181, 0.0750, 0.0716, 0.0661, 0.0324,
0.0204, 0.1200, 0.1226, 0.0099, -0.0411, 0.0362, -0.1211, -0.0642,
-0.0782, 0.0990, -0.0618, -0.0229, 0.0842, -0.0222, -0.0678, -0.0775,
0.0890, -0.1242, 0.0580, 0.1039, -0.0613, 0.1120, -0.0895, -0.1189,
-0.0090, -0.0771, 0.1222, 0.0278, 0.0568, 0.0611, -0.1173, 0.0980],
[-0.0403, -0.1164, -0.1014, -0.0152, 0.0437, 0.0548, 0.0632, 0.0700,
0.0834, -0.0079, -0.0647, 0.1155, -0.1225, 0.0784, 0.0746, 0.0355,
-0.0918, -0.0097, -0.0404, -0.1062, 0.0332, 0.0416, 0.0646, 0.1038,
0.0759, 0.0772, 0.0310, -0.0529, -0.0516, -0.1095, 0.0054, 0.1236,
-0.0246, -0.0313, 0.0074, 0.0229, -0.0427, 0.0905, 0.0733, -0.0442,
-0.0063, -0.0325, -0.1250, 0.0203, -0.0710, -0.0420, -0.0014, -0.0145,
0.0323, -0.0103, -0.0865, -0.0667, 0.0410, 0.0735, 0.0367, -0.0193,
-0.0270, 0.1074, -0.0356, -0.0410, 0.0646, 0.0148, -0.0853, 0.0222],
[ 0.1116, -0.0894, 0.0188, -0.0057, -0.0626, 0.1239, -0.1229, -0.0320,
0.1128, -0.0946, 0.1238, -0.0929, -0.0097, -0.0421, -0.0950, 0.1199,
0.0898, 0.0595, -0.0954, 0.0364, -0.1030, 0.0379, 0.0932, -0.0614,
-0.0817, -0.0060, 0.1057, -0.1019, -0.1074, 0.0415, -0.1136, -0.0997,
-0.1122, -0.1156, -0.1228, -0.0920, -0.0489, 0.0979, 0.0952, -0.0568,
0.0951, 0.0587, 0.0612, -0.0993, 0.0104, 0.0961, 0.0069, 0.1120,
0.0795, 0.1087, -0.0431, -0.0422, -0.0775, 0.0475, -0.0886, -0.0022,
-0.0598, -0.0642, -0.1144, 0.0723, 0.1092, -0.0545, 0.0416, 0.0111],
...
0.0808, -0.0778, -0.0265, -0.0946, -0.0095, 0.0061, -0.0168, 0.0826,
0.0985, 0.0983, -0.0846, 0.0148, 0.0792, 0.1174, -0.0230, -0.0810,
-0.0673, 0.0983, -0.0882, -0.0917, 0.0220, 0.0274, -0.0299, 0.0561,
0.0715, -0.0588, -0.0089, -0.1179, -0.0205, 0.1158, -0.1239, -0.0633]],
requires_grad=True)
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
문제 유형별 MLP 네트워크
- MLP(Multi Layer Perceptron), DNN(Deep Neural Network), ANN (Artificial Neural Network)
- Fully Connected Layer(nn.Linear)로 구성된 네트워크모델(딥러닝 모델)
Regression(회귀)
Boston Housing Dataset
보스턴 주택가격 dataset은 다음과 같은 속성을 바탕으로 해당 타운 주택 가격의 중앙값을 예측하는 문제.
- CRIM: 범죄율
- ZN: 25,000 평방피트당 주거지역 비율
- INDUS: 비소매 상업지구 비율
- CHAS: 찰스강에 인접해 있는지 여부(인접:1, 아니면:0)
- NOX: 일산화질소 농도(단위: 0.1ppm)
- RM: 주택당 방의 수
- AGE: 1940년 이전에 건설된 주택의 비율
- DIS: 5개의 보스턴 직업고용센터와의 거리(가중 평균)
- RAD: 고속도로 접근성
- TAX: 재산세율
- PTRATIO: 학생/교사 비율
- B: 흑인 비율
- LSTAT: 하위 계층 비율
- Target
- MEDV: 타운의 주택가격 중앙값(단위: 1,000달러)
import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, TensorDataset from torchinfo import summaryimport pandas as pd import numpy as np import matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler # 딥러닝 모델은 선형함수 기반 -> Feature Scaling 전처리를 하면 성능이 올라간다.device = "cuda" if torch.cuda.is_available() else "cpu" # device = "mps" if torch.backends.mps.is_available() else "cpu" # m1, m2 print(device)cpu
# Data 준비 -> DataLoader(Dataset) df = pd.read_csv("data/boston_hosing.csv") # X, y 분리 X_boston = df.drop(columns="MEDV").values y_boston = df['MEDV'].values.reshape(-1, 1) X_boston.shape, y_boston.shape, X_boston.dtype, y_boston.dtype((506, 13), (506, 1), dtype('float64'), dtype('float64'))
X_boston = X_boston.astype("float32") y_boston = y_boston.astype("float32") X_boston.dtype, y_boston.dtype(dtype('float32'), dtype('float32'))
# train/test set 분리 X_train, X_test, y_train, y_test = train_test_split( X_boston, y_boston, test_size=0.2, random_state=0 ) # 분류: stratify=y, 회귀는 설정하지 않음. print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)(404, 13) (102, 13) (404, 1) (102, 1)
# Feature Scaling (Feature간의 scaling-값의 범위/단위 을 통일시킨다.) ## 전처리 - trainset기반으로 학습하고 나머지를 변경. scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)### Dataset 생성 - TensorDataset trainset = TensorDataset( torch.tensor(X_train_scaled), # X torch.tensor(y_train)# y ) testset = TensorDataset(torch.tensor(X_test_scaled), torch.tensor(y_test))len(testset)102
### DataLoader train_loader = DataLoader( trainset, # Dataset 200, # batch_size shuffle=True, # epoch이 끝날때 마다 전체 데이터를 섞을지 여부. drop_last=True, # 마지막 batch의 데이터개수가 batch_size 보다 적을 경우 학습하지 않는다 ) test_loader = DataLoader(testset, len(testset)) print("step수:", len(train_loader), len(test_loader))# 2. 모델 정의 print(X_train_scaled.shape) # (404, 13: input shape) print(y_train.shape) # (404, 1: output shape)(404, 13)
(404, 1)# 모델 정의 -> nn.Module을 상속, # __init__(): 초기화, forward(): 추론 처리. class BostonModel(nn.Module) :def __init__(self) : # 1. 상위(부모)클래스의 __init__()을 호출해서 초기화.(필수) super().__init__() # instance 변수 초기화 -> forword()에서 사용할 함수들(Layer) 초기화. # 입력 features 개수: 13 -> in_features: 13 self.lr1 = nn.Linear(in_features=13, out_features=32) self.lr2 = nn.Linear(32, 16) self.lr3 = nn.Linear(16, 1) # output layer(집값 1개를 추론: out_features: 1) # 활성함수 Layer - 파라미터가 없기 때문에 하나를 여러번 사용해도 된다. self.relu = nn.ReLU()def forward(self, X) : # __init__()에서 초기화한 Layer함수들을 이용해서 추론작업흐름을 정의 out = self.lr1(X) # 선형함수-Linear() out = self.relu(out)# 비선형 함수(활성) - ReLU out = self.lr2(out) out = self.relu(out) # lr3의 출력이 모델의 최종 출력(모델이 추정한 값.) ### 회귀: 추정대상-집값 1개. #### out_features: 1, activation함수는 사용안함. #(추정할 값의 scale따라 activation함수를 사용할 수있다. # 0 ~ 1: logistic 함수(nn.Sigmoid), -1 ~ 1: hyperbolic tangent(nn.Tanh) out = self.lr3(out) return out# 모델 instance 생성 model = BostonModel()## 모델 구조를 확인 print(boston_model) # 모델의 attribute 중 Layer들을 출력. # (변수이름): instanceBostonModel(
(lr1): Linear(in_features=13, out_features=32, bias=True)
(lr2): Linear(in_features=32, out_features=16, bias=True)
(lr3): Linear(in_features=16, out_features=1, bias=True)
(relu): ReLU()
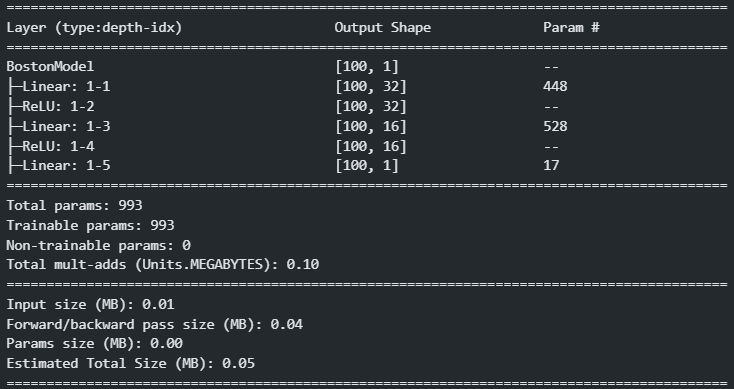
)# torchinfo.summary(모델) # torchinfo.summary(모델, dummy_input_shape) summary(boston_model, (100, 13)) # (batch: 100, feature수: 13)
# 파라미터 개수 계산 ## Linear(in, out) in * out + out (in: 개별 unit의 weight 수, out: unit을 몇개 만들기 개수. bias는 unit당 한개씩 필요.) ## Linear(13, 32) 13 * 32 + 32##### 3. Train(학습-fitting) -> 학습 + 검증 ######### 모델, loss함수, optimizer 준비. epochs = 1000 # 몇 epoch 학습할지. (epoch: 학습할 때 전체 train data 사용 단위.) lr = 0.001 # 학습율->optimizer에 설정할 값 model = BostonModel().to(device) # 모델을 계산할 device를 설정. loss_fn = nn.MSELoss() # 회귀의 loss함수: mean_squared_error optimizer = optim.RMSprop( model.parameters(), #모델의 파라미터들. lr=lr ) # optimizer생성 - 모델파라미터들, 학습률####### train + evaluation import time # 시간을 재기 위해서 ## epoch별 검증 결과를 저장할 변수 train_loss_list = [] valid_loss_list = [] # 1 epoch 학습 두단계: 학습(train_loader) -> 검증(test_loader) s = time.time() for epoch in range(epochs): # epoch별 처리 ########################## # 학습 ########################## # 1. 모델을 train 모드로 변환 -> 모델을 구성하는 layer함수들을 train 모드로 변환. model.train() train_loss = 0.0 # 현재 epoch의 train_loss를 저장할 변수 # batch 단위로 학습 -> dataloader를 순환반복. for X_train, y_train in train_loader: ### 한 step 학습 # 2. X, y를 device로 옮긴다. => 모델과 같은 device로 이동. X_train, y_train = X_train.to(device), y_train.to(device) # 3. X -입력-> model -추정> pred : 모델 추정 - forward propagation (model.forward() 호출) pred_train = model(X_train) # 4. loss 계산 loss = loss_fn(pred_train, y_train) #(모델추정값, 정답) # 5. 모델의 파라미터들의 gradient 계산 loss.backward() # 6. 파라미터들 업데이트 (w.data = w.data - w.grad * lr) optimizer.step() # 7. 파라미터의 gradient값 초기화(0으로 변경.) optimizer.zero_grad() ## 로그출력을 위해 loss를 train_loss에 누적 train_loss += loss.item() # 한 에폭 학습이 완료 - train loss 평균 계산. train_loss /= len(train_loader) #train_loss = train_loss / len(train_loader) ########################### # 검증 - 한 에폭학습한 결과에 대한 검증 ########################## # 1. 모델을 evalution 모드로 변환 - 검증/최종평가/추론 model.eval() val_loss = 0.0 # 현재 epoch에 대한 검증 결과(loss)를 저장할 변수. # 검증(평가, 추론)은 gradient를 계산할 필요가 없으므로 forward시 grad_fn을 만들 필요가 없다. with torch.no_grad(): # with 문 내에서 하는 연산에서는 grad_fn을 만들지 않는다. for X_val, y_val in test_loader: #1. device로 옮기기 X_val, y_val = X_val.to(device), y_val.to(device) #2. 모델을 이용해 추정 pred_val = model(X_val) #3. 검증 - MSE loss_val = loss_fn(pred_val, y_val) # 로그출력을 위해서 검증 결과를 val_loss에 누적 val_loss += loss_val.item() # val_loss 평균 val_loss /= len(test_loader) #### 한 에폭의 학습/검증 완료 -> train_loss, val_loss 평균를 list에 추가. train_loss_list.append(train_loss) valid_loss_list.append(val_loss) print(f"[{epoch+1:04d}/{epochs}] train loss: {train_loss} validation loss: {val_loss}") e = time.time() print(f"학습에 걸린 시간: {e-s} 초")[0001/1000] train loss: 583.9738464355469 validation loss: 554.475341796875
[0002/1000] train loss: 567.0885314941406 validation loss: 543.37548828125
[0003/1000] train loss: 558.9695129394531 validation loss: 530.3565673828125
[0004/1000] train loss: 544.1291809082031 validation loss: 515.218505859375
[0005/1000] train loss: 528.82177734375 validation loss: 497.8270568847656
[0006/1000] train loss: 506.54376220703125 validation loss: 479.5061950683594
[0007/1000] train loss: 487.619873046875 validation loss: 460.14019775390625
[0008/1000] train loss: 467.37249755859375 validation loss: 440.0032043457031
[0009/1000] train loss: 441.4295196533203 validation loss: 419.39599609375
[0010/1000] train loss: 420.26947021484375 validation loss: 398.3730163574219
[0011/1000] train loss: 395.4829559326172 validation loss: 377.41650390625
[0012/1000] train loss: 370.796142578125 validation loss: 356.918212890625
[0013/1000] train loss: 352.0693664550781 validation loss: 336.5556335449219
[0014/1000] train loss: 331.05409240722656 validation loss: 316.63934326171875
[0015/1000] train loss: 308.834228515625 validation loss: 297.3157043457031
[0016/1000] train loss: 287.31776428222656 validation loss: 278.8677673339844
[0017/1000] train loss: 267.16204833984375 validation loss: 261.2577819824219
[0018/1000] train loss: 247.9029083251953 validation loss: 244.56549072265625
[0019/1000] train loss: 230.97164154052734 validation loss: 228.80361938476562
[0020/1000] train loss: 212.74188995361328 validation loss: 214.12252807617188
[0021/1000] train loss: 196.69847869873047 validation loss: 200.44688415527344
[0022/1000] train loss: 181.50080108642578 validation loss: 187.83543395996094
[0023/1000] train loss: 164.381103515625 validation loss: 176.40640258789062
[0024/1000] train loss: 156.09925079345703 validation loss: 165.81024169921875
[0025/1000] train loss: 145.3577651977539 validation loss: 156.1038055419922
...
[0998/1000] train loss: 3.7113815546035767 validation loss: 18.47628402709961
[0999/1000] train loss: 3.683616876602173 validation loss: 17.782758712768555
[1000/1000] train loss: 3.7629929780960083 validation loss: 18.368406295776367
학습에 걸린 시간: 4.840130090713501 초
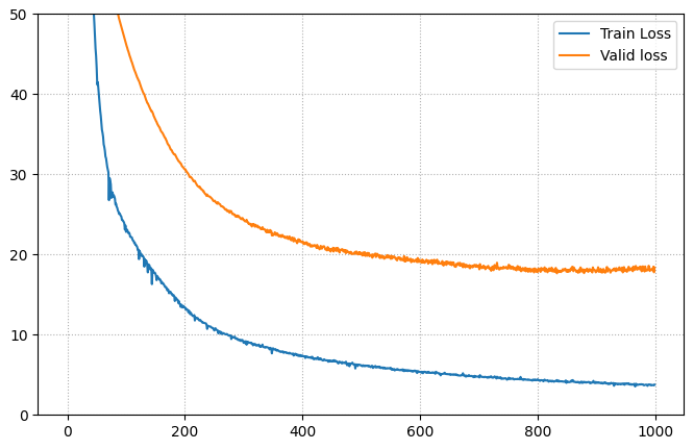
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...#### 학습결과를 시각화 plt.figure(figsize=(8, 5)) plt.plot(range(epochs), train_loss_list, label='Train Loss') plt.plot(range(epochs), valid_loss_list, label="Valid loss") plt.ylim(0, 50) plt.legend() plt.grid(True, linestyle=":") plt.show()
## 모델 저장 - 모델 전체를 저장. boston_model_save_path = "saved_models/boston_model.pth" torch.save(model, boston_model_save_path)### 저장된 모델 load load_model = torch.load(boston_model_save_path)
분류 (Classification)
Fashion MNIST Dataset - 다중분류(Multi-Class Classification) 문제
10개의 범주(category)와 70,000개의 흑백 이미지로 구성된 패션 MNIST 데이터셋.
이미지는 해상도(28x28 픽셀)가 낮고 다음처럼 개별 의류 품목을 나타낸다:
|
|
|
그림 패션-MNIST 샘플 (Zalando, MIT License). |
이미지는 28x28 크기이며 Gray scale이다. 레이블(label)은 0에서 9까지의 정수 배열이다. 아래 표는 이미지에 있는 의류의 클래스(class)들이다.
| 레이블 | 클래스 |
|---|---|
| 0 | T-shirt/top |
| 1 | Trousers |
| 2 | Pullover |
| 3 | Dress |
| 4 | Coat |
| 5 | Sandal |
| 6 | Shirt |
| 7 | Sneaker |
| 8 | Bag |
| 9 | Ankle boot |
import torch import torch.nn as nn from torch.utils.data import DataLoader from torchvision import datasets, transforms from torchinfo import summary import matplotlib.pyplot as plt import numpy as np device = "cuda" if torch.cuda.is_available() else "cpu" # device = "mps" if torch.backends.mps.is_available() else "cpu"### 1. Dataset 생성 - Built-in dataset 이용 root_path = r"C:\Classes\deeplearning\datasets" trainset = datasets.FashionMNIST( root=root_path, train=True, download=True, transform=transforms.ToTensor() ) testset = datasets.FashionMNIST( root=root_path, train=False, download=True, transform=transforms.ToTensor() )# Validatation set 을 trainset으로 부터 생성 trainset, validset = torch.utils.data.random_split(trainset, [50000, 10000]) len(trainset), len(testset), len(validset)(50000, 10000, 10000)
testset.classes testset.class_to_idx{'T-shirt/top': 0,
'Trouser': 1,
'Pullover': 2,
'Dress': 3,
'Coat': 4,
'Sandal': 5,
'Shirt': 6,
'Sneaker': 7,
'Bag': 8,
'Ankle boot': 9}# 입력 이미지 확인 idx = 1187 x, y = testset[idx] plt.imshow(x.squeeze(), cmap="Greys") # gray: 최소값(black) ~ 최대값(white), Greys: 반대 plt.title(f"{testset.classes[y]}") plt.show()
### DataLoader 생성 train_loader = DataLoader(trainset, batch_size=128, shuffle=True, drop_last=True) valid_loader = DataLoader(validset, batch_size=128) test_loader = DataLoader(testset, batch_size=128)############# 모델 정의 class FashionMNISTModel(nn.Module):def __init__(self): super().__init__() self.lr1 = nn.Linear(1*28*28, 1024) # 첫번째 Layer함수: in-입력데이터 feature수 self.lr2 = nn.Linear(1024, 512) self.lr3 = nn.Linear(512, 256) self.lr4 = nn.Linear(256, 128) self.lr5 = nn.Linear(128, 64) # output layer 함수 - out: 추론할 값의 개수 (다중분류: y의 class 개수) self.lr6 = nn.Linear(64, 10) # activation 함수 self.relu = nn.ReLU()def forward(self, X): # X.shape : (batch크기, channel, height, width) -입력(1차원)-> Linear() # X.shape을 1차원으로 변환: (batch크기, channel*height*width) # torch.flatten(X, start_dim=1) out = nn.Flatten()(X) # batch축은 유지하고 그 이후 축들을 flatten시킨다. () # lr1 ~ lr6 : lr -> relu : Hidden Layer 계산 out = self.relu(self.lr1(out)) out = self.relu(self.lr2(out)) out = self.relu(self.lr3(out)) out = self.relu(self.lr4(out)) out = self.relu(self.lr5(out)) # lr7 : output layer -> Linear의 처리결과를 출력. (softmax-확률로 계산-는 따로 계산) out = self.lr6(out) return out# 모델구조 확인 f_model = FashionMNISTModel() print(f_model)FashionMNISTModel(
(lr1): Linear(in_features=784, out_features=1024, bias=True)
(lr2): Linear(in_features=1024, out_features=512, bias=True)
(lr3): Linear(in_features=512, out_features=256, bias=True)
(lr4): Linear(in_features=256, out_features=128, bias=True)
(lr5): Linear(in_features=128, out_features=64, bias=True)
(lr6): Linear(in_features=64, out_features=10, bias=True)
(relu): ReLU()
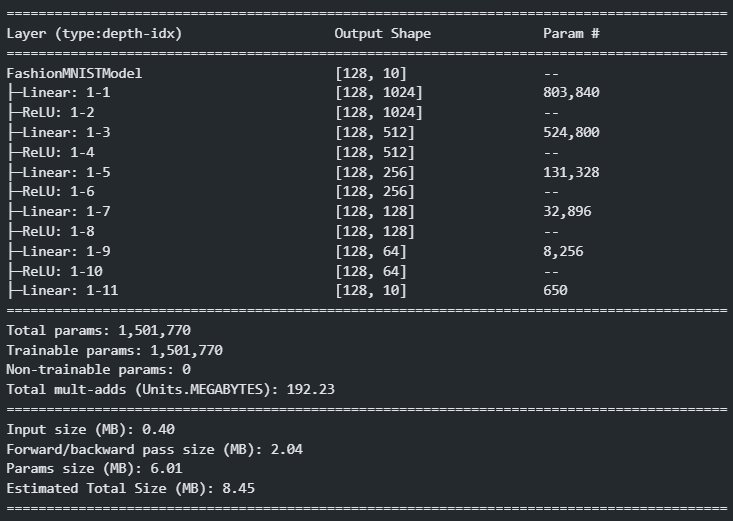
)summary(f_model, (128, 1, 28, 28)) # summary(모델, 입력X의 shape)
#################################### # 학습 + 검증 #################################### lr = 0.001 epochs = 20 ##### Train -> model, loss_fn, optimizer ##### device로 이동해야 할 것: model, X, y (이 셋은 같은 device에 위치시켜야 한다.) model = FashionMNISTModel().to(device) # 다중분류: CrossEntropyLoss()(pred, y) - pred: softmax => log: log_softmax(), y: one-hot encoding #####CrossEntropyLoss() - 모델추정->softmax를 통과하면 안된다. 정답: one hot encoding 처리하면 안된다. loss_fn = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=lr)############### 학습 - train loss, validation loss, validation accuray import time # epoch별 학습+검증 결과를 저장할 리스트 train_loss_list = [] valid_loss_list = [] valid_acc_list = [] s = time.time()for epoch in range(epochs): # 한 epoch 학습 + 검증 ############# Train ############# model.train() train_loss = 0.0 # 현재 epoch의 step별 train loss 의 평균. for X_train, y_train in train_loader: ##### 한 step 학습 # 1. X, y를 device 이동. -> 모델과 같은 device로 이동. X_train, y_train = X_train.to(device), y_train.to(device) # 2. 추론 - forward propagation (model.forward()) pred_train = model(X_train) # 3. loss 계산 loss = loss_fn(pred_train, y_train) # 4. 파라미터들의 gradient 계산 (back propagation) loss.backward() # 5. 파라미터 업데이트 optimizer.step() # 6. 파라미터의 gradient값들을 초기화 optimizer.zero_grad() # loss값을 train_loss변수에 누적 train_loss = train_loss + loss.item() # train_loss += loss.item() # 한 epoch 학습 완료. # step별로 누적된 train_loss의 평균값을 계산. -> step수로 나눔. train_loss = train_loss / len(train_loader) train_loss_list.append(train_loss)############# Validation ######### model.eval() # 현재 epoch 의 검증 결과를 저장할 변수. valid_loss = 0.0 valid_acc = 0.0 # 학습을 하지 않으므로(파라미터 업데이트 안함.) forward(추론) 할 때 gradient 함수를 구할 필요 없다. with torch.no_grad(): for X_valid, y_valid in valid_loader: # 한 배치에 대한 검증. # 1. X, y를 model과 같은 device로 이동. X_valid, y_valid = X_valid.to(device), y_valid.to(device) # 2. 추론 (model.forward) pred_valid = model(X_valid) # 0 ~ 9 일 확률(확률계산 전 값: logit) # 3. 검증 ## 3-1 loss 계산 - loss_fn(): 배치의 데이터별 loss의 평균값. valid_loss = valid_loss + loss_fn(pred_valid, y_valid).item() ## 3-2 accuracy 계산: 예측 class와 정답 class가 같은지 여부. pred_class = pred_valid.argmax(dim=-1) valid_acc = valid_acc + torch.sum(pred_class == y_valid).item() #현재 batch에서 몇개 맞았는지 개수를 누적 # epoch에대한 검증 종료 ### valid_loss평균 (step수로 나눔), valid_acc계산(맞은것의 개수/전체 valid데이터개수) valid_loss = valid_loss / len(valid_loader) valid_acc = valid_acc / len(valid_loader.dataset) # DataLoader.dataset: Dataset을 반환. valid_loss_list.append(valid_loss) valid_acc_list.append(valid_acc) print(f"[{epoch+1}/{epochs}] train loss: {train_loss}, valid loss: {valid_loss}, valid_acc: {valid_acc}") e = time.time() print(f"학습에 걸린시간: {e-s}초")[1/20] train loss: 0.6616536738016666, valid loss: 0.4402015541173235, valid_acc: 0.8413
[2/20] train loss: 0.4084338561464579, valid loss: 0.3932268987350826, valid_acc: 0.8558
[3/20] train loss: 0.35750650339401685, valid loss: 0.3977603827473484, valid_acc: 0.8486
[4/20] train loss: 0.3284882332269962, valid loss: 0.3615136963279941, valid_acc: 0.8699
[5/20] train loss: 0.3073219086115177, valid loss: 0.3472418706816963, valid_acc: 0.8731
[6/20] train loss: 0.2901916005672553, valid loss: 0.36427211289918876, valid_acc: 0.869
[7/20] train loss: 0.2742870061061321, valid loss: 0.3512053067171121, valid_acc: 0.8774
[8/20] train loss: 0.2656584680080414, valid loss: 0.32925364601461193, valid_acc: 0.8833
[9/20] train loss: 0.25169693485666544, valid loss: 0.3254526302784304, valid_acc: 0.8859
[10/20] train loss: 0.24099358283938505, valid loss: 0.33618592678368847, valid_acc: 0.8856
[11/20] train loss: 0.23355363899698625, valid loss: 0.32169665565973593, valid_acc: 0.8878
[12/20] train loss: 0.22593384220814094, valid loss: 0.3300986457851869, valid_acc: 0.886
[13/20] train loss: 0.21517877379098, valid loss: 0.3297061652322359, valid_acc: 0.8908
[14/20] train loss: 0.2064367515918536, valid loss: 0.34137734412392484, valid_acc: 0.8932
[15/20] train loss: 0.20396954489824098, valid loss: 0.32355846030802665, valid_acc: 0.8931
[16/20] train loss: 0.19140137651791939, valid loss: 0.32758019525039045, valid_acc: 0.8897
[17/20] train loss: 0.18201956231242572, valid loss: 0.35042483331281926, valid_acc: 0.8886
[18/20] train loss: 0.17985025443709812, valid loss: 0.33256547473653963, valid_acc: 0.8938
[19/20] train loss: 0.17190322192051471, valid loss: 0.3399254958840865, valid_acc: 0.8948
[20/20] train loss: 0.16518768079769916, valid loss: 0.35594435507738137, valid_acc: 0.8925
학습에 걸린시간: 352.7412667274475초##### 학습 결과 시각화 plt.figure(figsize=(15, 6)) plt.subplot(1, 2, 1) plt.plot(range(20), train_loss_list, label="train") plt.plot(range(20), valid_loss_list, label="validation") plt.title("loss") plt.grid(True, linestyle=":") plt.subplot(1, 2, 2) plt.plot(range(20), valid_acc_list) plt.title('validation accuracy') plt.grid(True, linestyle=":") plt.tight_layout() plt.show()
np.argmin(valid_loss_list)10
valid_loss_list[9] # 10번째 epoch 이 가장 좋은 성능의 모델.0.33618592678368847
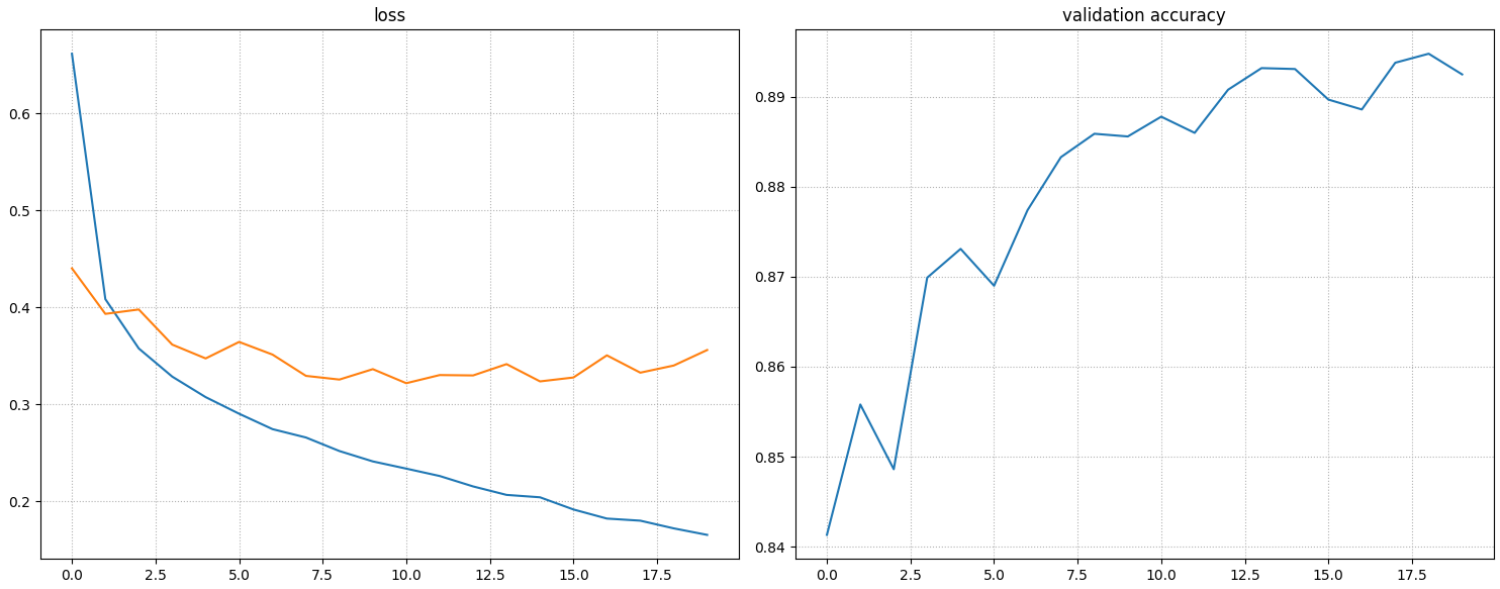
모델저장
- 학습하는 도중 성능이 개선될 때 마다 저장.
- 덮어쓰기로 저장. 학습 완료 후에 가장 성능 좋았던 epoch의 모델이 저장 되 있도록 한다.
- 조기종료(Early stopping) 로직을 같이 처리
- 특정 epoch수가 지나도록 성능 개선이 안되면 학습을 중단
import time ############### 학습 - train loss, validation loss, validation accuray ###################### + 가장 성능 좋은 epoch의 모델 저장 + 조기종료 lr = 0.001 epochs = 100 # epoch수를 최대한 길게 잡는다. model = FashionMNISTModel().to(device) loss_fn = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=lr) ####################################### # 조기 종료 + 모델 저장을 위한 설정(변수)들 추가. # 조기종료 기준 평가 지표: validation loss ####################################### # 가장 성능 좋았을 때의 validation loss를 저장. ### 초기값: 가장 큰수(무한). (loss는 작을 수록 좋으므로 가장 안좋은 loss값으로 초기화) best_score = torch.inf # best_score > valid_loss (valid loss의 성능이 더 좋으면) best_score=valid_loss save_path = "saved_models/fashion_mnist_model.pth" # 조기 종료시 성능개선이 되는 지 기다릴 epoch수. ## patience epoch 동안 성능이 개선되지 않으면 조기종료. patience = 5 # 성능개선 되는지를 몇번 째 기다리는지 저장할 변수. if patience == trigger_count : 조기종료 trigger_count = 0 ################################################### # epoch별 학습+검증 결과를 저장할 리스트 train_loss_list = [] valid_loss_list = [] valid_acc_list = []s = time.time() for epoch in range(epochs): # 한 epoch 학습 + 검증 ############# Train ############# model.train() train_loss = 0.0 # 현재 epoch의 step별 train loss 의 평균. for X_train, y_train in train_loader: ##### 한 step 학습 # 1. X, y를 device 이동. -> 모델과 같은 device로 이동. X_train, y_train = X_train.to(device), y_train.to(device) # 2. 추론 - forward propagation (model.forward()) pred_train = model(X_train) # 3. loss 계산 loss = loss_fn(pred_train, y_train) # 4. 파라미터들의 gradient 계산 (back propagation) loss.backward() # 5. 파라미터 업데이트 optimizer.step() # 6. 파라미터의 gradient값들을 초기화 optimizer.zero_grad() # loss값을 train_loss변수에 누적 train_loss = train_loss + loss.item() # train_loss += loss.item() # 한 epoch 학습 완료. # step별로 누적된 train_loss의 평균값을 계산. -> step수로 나눔. train_loss = train_loss / len(train_loader) train_loss_list.append(train_loss) ############# Validation ######### model.eval() # 현재 epoch 의 검증 결과를 저장할 변수. valid_loss = 0.0 valid_acc = 0.0 # 학습을 하지 않으므로(파라미터 업데이트 안함.) forward(추론) 할 때 gradient 함수를 구할 필요 없다. with torch.no_grad(): for X_valid, y_valid in valid_loader: # 한 배치에 대한 검증. # 1. X, y를 model과 같은 device로 이동. X_valid, y_valid = X_valid.to(device), y_valid.to(device) # 2. 추론 (model.forward) pred_valid = model(X_valid) # 0 ~ 9 일 확률(확률계산 전 값: logit) # 3. 검증 ## 3-1 loss 계산 - loss_fn(): 배치의 데이터별 loss의 평균값. valid_loss = valid_loss + loss_fn(pred_valid, y_valid).item() ## 3-2 accuracy 계산: 예측 class와 정답 class가 같은지 여부. pred_class = pred_valid.argmax(dim=-1) valid_acc = valid_acc + torch.sum(pred_class == y_valid).item() #현재 batch에서 몇개 맞았는지 개수를 누적 # epoch에대한 검증 종료 ### valid_loss평균 (step수로 나눔), valid_acc계산(맞은것의 개수/전체 valid데이터개수) valid_loss = valid_loss / len(valid_loader) valid_acc = valid_acc / len(valid_loader.dataset) # DataLoader.dataset: Dataset을 반환. valid_loss_list.append(valid_loss) valid_acc_list.append(valid_acc) print(f"[{epoch+1}/{epochs}] train loss: {train_loss}, valid loss: {valid_loss}, valid_acc: {valid_acc}") # 한 epoch대한 학습 + 검증 완료 ##################################### # 저장 + 조기종료 ## 모델 저장 여부 체크후 성능 개선됬으면 저장. if valid_loss < best_score: # 성능이 개선됨. print(f"모델저장: {epoch+1} epoch - best valid loss: {best_score:.5f}, 현재 valid_loss: {valid_loss:.5f}") # best 값을 현 epoch의 valid_loss로 변경. best_score = valid_loss # 모델 저장 torch.save(model, save_path) #### 조기종료 trigger_count=0 으로 초기화 trigger_count = 0 else: # 성능 개선이 안됨. # 조기종료 처리. ### trigger_count 를 1 증가. trigger_count += 1 if patience == trigger_count: # 지정한 횟수만큼 대기함. => 종료 print(f"{epoch+1} epoch에서 조기종료. best validation loss: {best_score} 에서 개선안됨.") break # epochs 의 for in 문 break. e = time.time() print(f"학습에 걸린시간: {e-s}초")[1/100] train loss: 0.6583470991788767, valid loss: 0.45711897671977175, valid_acc: 0.8351
모델저장: 1 epoch - best valid loss: inf, 현재 valid_loss: 0.45712
[2/100] train loss: 0.4013376003274551, valid loss: 0.3819148936603643, valid_acc: 0.8638
모델저장: 2 epoch - best valid loss: 0.45712, 현재 valid_loss: 0.38191
[3/100] train loss: 0.3570076781587723, valid loss: 0.3643507174675978, valid_acc: 0.8668
모델저장: 3 epoch - best valid loss: 0.38191, 현재 valid_loss: 0.36435
[4/100] train loss: 0.3288847603859046, valid loss: 0.35550616926784756, valid_acc: 0.869
모델저장: 4 epoch - best valid loss: 0.36435, 현재 valid_loss: 0.35551
[5/100] train loss: 0.305000030153837, valid loss: 0.3781224068584321, valid_acc: 0.8661
[6/100] train loss: 0.2930782368549934, valid loss: 0.3300913144138795, valid_acc: 0.8839
모델저장: 6 epoch - best valid loss: 0.35551, 현재 valid_loss: 0.33009
[7/100] train loss: 0.27073897530253116, valid loss: 0.32913627315171157, valid_acc: 0.8821
모델저장: 7 epoch - best valid loss: 0.33009, 현재 valid_loss: 0.32914
[8/100] train loss: 0.2582684844350204, valid loss: 0.34083666322352013, valid_acc: 0.8755
[9/100] train loss: 0.24929785354015155, valid loss: 0.3220430185334592, valid_acc: 0.8868
모델저장: 9 epoch - best valid loss: 0.32914, 현재 valid_loss: 0.32204
[10/100] train loss: 0.2432257688198334, valid loss: 0.3283542925609818, valid_acc: 0.8869
[11/100] train loss: 0.2357870590228301, valid loss: 0.3339655452136752, valid_acc: 0.887
[12/100] train loss: 0.22197601886895987, valid loss: 0.31975664254985275, valid_acc: 0.8879
모델저장: 12 epoch - best valid loss: 0.32204, 현재 valid_loss: 0.31976
[13/100] train loss: 0.21349067900043267, valid loss: 0.341043203031715, valid_acc: 0.8887
[14/100] train loss: 0.2034082245750305, valid loss: 0.32684850334366666, valid_acc: 0.8871
[15/100] train loss: 0.19794723477501136, valid loss: 0.330617136310173, valid_acc: 0.8958
[16/100] train loss: 0.18876291044438498, valid loss: 0.32770321263542657, valid_acc: 0.8883
[17/100] train loss: 0.18443683478503656, valid loss: 0.33168279822868635, valid_acc: 0.8923
17 epoch에서 조기종료. best validation loss: 0.31975664254985275 에서 개선안됨.
학습에 걸린시간: 310.0695536136627초##### 저장된 모델(best score) 로 test set 최종 평가. # 저장 모델 loading best_model = torch.load(save_path) ## model을 device로 이동. best_model = best_model.to(device) ## evaluation 모드로 변경. best_model.eval() # 검증/평가/추론 할 때 지정. ## 평가 결과를 저장할 변수 test_loss = 0.0 test_acc = 0.0 with torch.no_grad(): for X_test, y_test in test_loader: # 1. model과 같은 device로 옮기기 X_test, y_test = X_test.to(device), y_test.to(device) # 2. 추론 pred_test = best_model(X_test) # class별 logit # 3. 평가 - loss test_loss = test_loss + loss_fn(pred_test, y_test).item() # loss 누적 ## 3. 평가 - accuracy pred_test_class = pred_test.argmax(dim=-1) # 확률 제일 높은 class 조회.(정답 label) test_acc = test_acc + torch.sum(pred_test_class == y_test).item() # 맞은 개수 누적 # 검증 완료 test_loss = test_loss / len(test_loader) test_acc = test_acc / len(test_loader.dataset)print(f"최종 평가결과: loss: {test_loss}, accuracy: {test_acc}")최종 평가결과: loss: 0.3395320085596435, accuracy: 0.8846
위스콘신 유방암 데이터셋 - 이진분류(Binary Classification) 문제
- 이진 분류 문제 처리 모델의 두가지 방법
- positive(1)일 확률을 출력하도록 구현
- output layer: units=1, activation='sigmoid'
- loss: binary_crossentropy
- negative(0)일 확률과 positive(1)일 확률을 출력하도록 구현 => 다중분류 처리 방식으로 해결
- output layer: units=2, activation='softmax', y(정답)은 one hot encoding 처리
- loss: categorical_crossentropy
- positive(1)일 확률을 출력하도록 구현
- 위스콘신 대학교에서 제공한 종양의 악성/양성여부 분류를 위한 데이터셋
- Feature
- 종양에 대한 다양한 측정값들
- Target의 class
- 0 - malignant(악성종양)
- 1 - benign(양성종양)
from sklearn.datasets import load_breast_cancer from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import TensorDataset, DataLoader import numpy as np import matplotlib.pyplot as plt device = "cuda" if torch.cuda.is_available() else "cpu" # device = "mps" if torch.backends.mps.is_available() else "cpu" # macDataset, DataLoader
X, y = load_breast_cancer(return_X_y=True) # X, y type을 float32 변경 X, y = X.astype("float32"), y.astype("float32") # y reshape y = y.reshape(-1, 1) X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.2, random_state=0) print(X_train.shape, X_test.shape, y_train.shape, y_test.shape) print(X_train.dtype, y_train.dtype)(455, 30) (114, 30) (455, 1) (114, 1)
float32 float32# 전처리 # 1. X, y의 dtype=float32 # 2. y의 shape 변경 (batch_size, 1) # 3. X scaling (FMnist-ToTensor() -> 0 ~ 1) scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)# Dataset: 메모리의 ndarray -> Dataset ===> TensorDataset: ndarray->torch.Tensor X_train_tensor = torch.tensor(X_train_scaled) X_test_tensor = torch.tensor(X_test_scaled) y_train_tensor = torch.tensor(y_train) y_test_tensor = torch.tensor(y_test) trainset = TensorDataset(X_train_tensor, y_train_tensor) # args: (inputdata, outputdata) testset = TensorDataset(X_test_tensor, y_test_tensor)# DataLoader train_loader = DataLoader(trainset, batch_size=200, shuffle=True, drop_last=True) test_loader = DataLoader(testset, batch_size=len(testset))Model 정의
class BreastCancerModel(nn.Module):def __init__(self): super().__init__() self.lr1 = nn.Linear(30, 32) self.lr2 = nn.Linear(32, 8) self.lr3 = nn.Linear(8, 1) # 출력 Layer 처리 함수 -> 이진분류로 양성일 확률(1개)을 출력. self.relu = nn.ReLU() self.sig = nn.Sigmoid()def forward(self, X): out = self.relu(self.lr1(X)) out = self.relu(self.lr2(out)) out = self.lr3(out) out = self.sig(out) return out학습
lr = 0.001 epochs = 1000 model = BreastCancerModel().to(device) loss_fn = nn.BCELoss() # 이진분류 loss 함수. - binary crossentropy optimizer = optim.Adam(model.parameters(), lr=lr)import time ########################################################### # 저장할 검증결과: train loss, validation loss, validation accuracy # epoch별 validation loss가 가장 좋은 모델을 저장 (saved_models/breast_cancel_model.pth) # 10 epoch 동안 validation loss가 좋아 지지 안으면 학습 중단(early stopping) ##################################################################### save_path = "saved_models/breast_cancel_model.pth" best_score = torch.inf # 학습하면서 가장 좋은 loss를 저장. patience = 10 # 조기종료 전까지 성능개선을 위해 몇 epoch을 기다릴지 설정. trigger_count = 0 # 성능개선을 위해 몇번째 기다렸는지 count 값. (성능 개선 될 때 마다 초기화.)# 결과 저장할 리스트 train_loss_list = [] valid_loss_list = [] valid_acc_list = [] s = time.time() for epoch in range(epochs): # 학습 model.train() train_loss = 0.0 for X_train, y_train in train_loader: X_train, y_train = X_train.to(device), y_train.to(device) pred_train = model(X_train) loss = loss_fn(pred_train, y_train) loss.backward() optimizer.step() optimizer.zero_grad() train_loss += loss.item() train_loss = train_loss/len(train_loader) train_loss_list.append(train_loss) ### 한 epoch 학습 종료 # 검증 model.eval() valid_loss, valid_acc = 0.0, 0.0 with torch.no_grad(): for X_valid, y_valid in test_loader: X_valid, y_valid = X_valid.to(device), y_valid.to(device) ### loss 계산 pred_valid = model(X_valid) # positive일 확률값. (0.32, 0.91) valid_loss = valid_loss + loss_fn(pred_valid, y_valid).item() ### 정확도 계산 -> 확률을 class(label-0, 1)로 변환. valid_acc = valid_acc + torch.sum((pred_valid > 0.5).type(torch.int32) == y_valid).item() # 검증결과 계산 # valid_loss: step수로 나눠서 평균. valid_acc: testset의 데이터개수 나눠서 정확도를 계산 valid_loss = valid_loss / len(test_loader) valid_acc = valid_acc / len(test_loader.dataset) valid_loss_list.append(valid_loss) valid_acc_list.append(valid_acc) ## 한 에폭의 학습 + 검증 완료 # 로그 출력 print(f"[{epoch+1}/{epochs}] train loss: {train_loss}, validation loss: {valid_loss}, validation accuracy: {valid_acc}") # 모델 저장 (성능 개선시), 조기종료 처리 if valid_loss < best_score: # 성능 개선 print(f"{epoch+1} epoch에서 저장. best_score: {best_score:.5f}가 {valid_loss:.5f}로 개선됨.") best_score = valid_loss torch.save(model, save_path) # 조기종료 trigger_count 초기화 trigger_count = 0 else: # 성능개선이 안됨. trigger_count += 1 if patience == trigger_count: # 조기종료 print(f"{epoch+1} epoch에서 조기 종료. {best_score:.5f}에서 개선되지 않음.") break e = time.time() print("걸린시간: ", e-s)[1/1000] train loss: 0.6839115619659424, validation loss: 0.6708410978317261, validation accuracy: 0.6929824561403509
1 epoch에서 저장. best_score: inf가 0.67084로 개선됨.
[2/1000] train loss: 0.6705925762653351, validation loss: 0.658995509147644, validation accuracy: 0.7719298245614035
2 epoch에서 저장. best_score: 0.67084가 0.65900로 개선됨.
[3/1000] train loss: 0.6567612290382385, validation loss: 0.646835446357727, validation accuracy: 0.8157894736842105
3 epoch에서 저장. best_score: 0.65900가 0.64684로 개선됨.
[4/1000] train loss: 0.6439491510391235, validation loss: 0.6347687244415283, validation accuracy: 0.868421052631579
4 epoch에서 저장. best_score: 0.64684가 0.63477로 개선됨.
[5/1000] train loss: 0.6303856074810028, validation loss: 0.6224480867385864, validation accuracy: 0.9122807017543859
5 epoch에서 저장. best_score: 0.63477가 0.62245로 개선됨.
[6/1000] train loss: 0.616211861371994, validation loss: 0.610153079032898, validation accuracy: 0.9122807017543859
6 epoch에서 저장. best_score: 0.62245가 0.61015로 개선됨.
[7/1000] train loss: 0.6051818132400513, validation loss: 0.5982251763343811, validation accuracy: 0.9210526315789473
7 epoch에서 저장. best_score: 0.61015가 0.59823로 개선됨.
[8/1000] train loss: 0.5890105962753296, validation loss: 0.5866266489028931, validation accuracy: 0.9210526315789473
8 epoch에서 저장. best_score: 0.59823가 0.58663로 개선됨.
[9/1000] train loss: 0.578445166349411, validation loss: 0.575101912021637, validation accuracy: 0.9298245614035088
9 epoch에서 저장. best_score: 0.58663가 0.57510로 개선됨.
[10/1000] train loss: 0.565708190202713, validation loss: 0.5635380744934082, validation accuracy: 0.9298245614035088
10 epoch에서 저장. best_score: 0.57510가 0.56354로 개선됨.
[11/1000] train loss: 0.5540366470813751, validation loss: 0.5520272850990295, validation accuracy: 0.9385964912280702
11 epoch에서 저장. best_score: 0.56354가 0.55203로 개선됨.
[12/1000] train loss: 0.5415427684783936, validation loss: 0.5403131246566772, validation accuracy: 0.9298245614035088
12 epoch에서 저장. best_score: 0.55203가 0.54031로 개선됨.
[13/1000] train loss: 0.5312028229236603, validation loss: 0.5284234881401062, validation accuracy: 0.9385964912280702
...
[135/1000] train loss: 0.04326770640909672, validation loss: 0.09457924962043762, validation accuracy: 0.956140350877193
[136/1000] train loss: 0.03210444375872612, validation loss: 0.09463316947221756, validation accuracy: 0.956140350877193
136 epoch에서 조기 종료. 0.09422에서 개선되지 않음.
걸린시간: 0.8700354099273682
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...### 학습결과 시각화 plt.figure(figsize=(15, 6)) plt.subplot(1, 2, 1) x = len(train_loss_list) plt.plot(range(x), train_loss_list, label="train loss") plt.plot(range(x), valid_loss_list, label='validation loss') plt.legend() plt.grid(True, linestyle=":") plt.subplot(1, 2, 2) plt.plot(range(x), valid_acc_list, label="validation accuracy") plt.legend() plt.grid(True, linestyle=":") plt.tight_layout() plt.show()
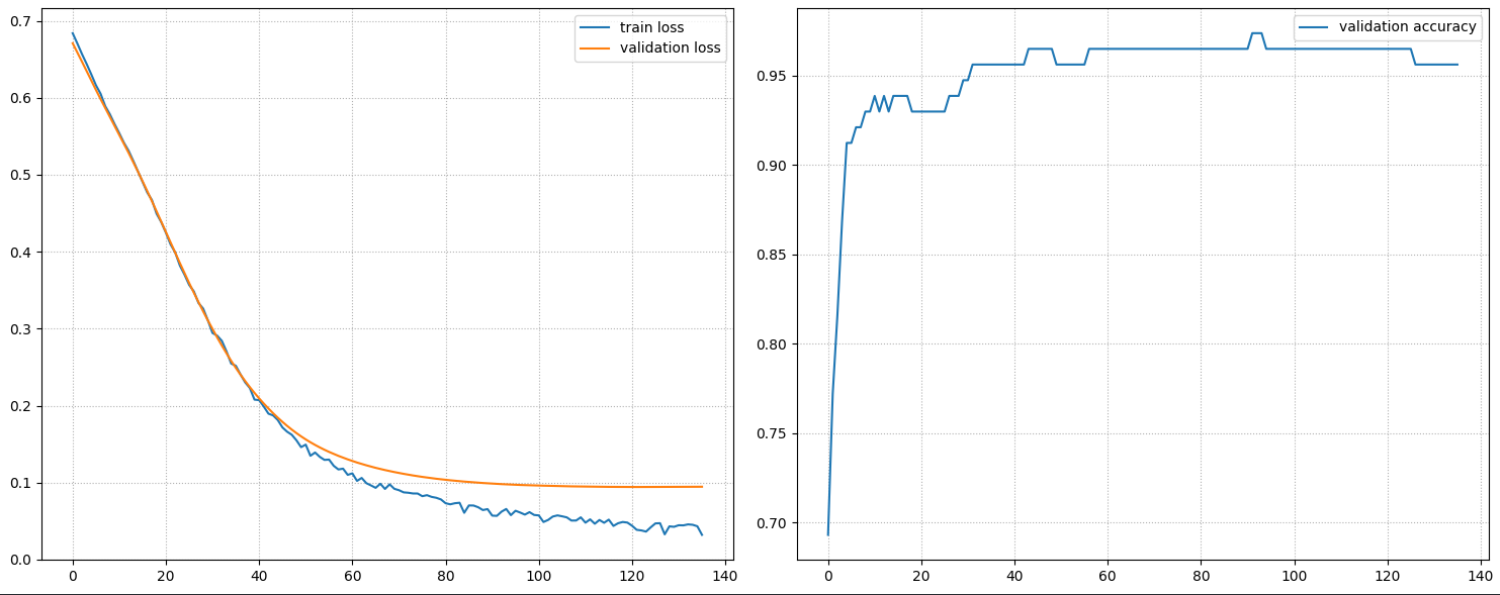
- 학습
- X, y device 이동
- 모델에 X를 넣어서 추론
- loss 계산
- gradient 계산
- 파라미터 업데이터
- 파라미터 초기화
- 검증
- X, y device 이동
- 모델에 X 넣어서 추론
- 검증 결과 계산
모델 유형별 구현 정리
공통
- Input layer(첫번째 Layer)의 in_features
- 입력데이터의 feature(속성) 개수에 맞춰준다.
- Hidden layer 수
- 경험적(art)으로 정한다.
- Hidden layer에 Linear를 사용하는 경우 보통 feature 수를 줄여 나간다. (핵심특성들을 추출해나가는 과정의 개념.)
회귀 모델
- output layer의 출력 unit개수(out_features)
- 정답의 개수
- ex
- 집값: 1
- 아파트가격, 단독가격, 빌라가격: 3 => y의 개수에 맞춘다.
- 출력 Layer에 적용하는 activation 함수
- 일반적으로 None
- 값의 범위가 설정되 있고 그 범위의 값을 출력하는 함수가 있을 경우
- ex) 0 ~ 1: logistic(Sigmoid), -1 ~ 1: hyperbolic tangent(Tanh)
- loss함수
- MSELoss
- 평가지표
- MSE, RMSE, R square()
다중분류 모델
- output layer의 unit 개수
- 정답 class(고유값)의 개수
- 출력 Layer에 적용하는 activation 함수
- Softmax: 클래스별 확률을 출력
- loss함수
- categrocial crossentropy
- 파이토치 함수
- CrossEntropyLoss = NLLLoss(정답) + LogSoftmax(모델 예측값)
- NLLLoss
- 정답을 OneHot Encoding 처리 후 Loss를 계산한다.
- 입력으로 LogSoftmax 처리한 모델 예측값과 onehot encoding 안 된 정답을 받는다.
- 정답을 OneHot Encoding 처리 후 Loss를 계산한다.
- LogSoftmax
- 입력값에 Softmax 계산후 그 Log를 계산한다.
- NLLLoss의 모델 예측값 입력값으로 처리할 때 사용한다.
- 입력값에 Softmax 계산후 그 Log를 계산한다.
pred = model(input)
loss1 = nn.NLLLoss(nn.LogSoftmax(dim=-1)(pred), y)
# or
loss2 = nn.CrossEntropyLoss()(pred, y)이진분류 모델
- output layer의 unit 개수
- 1개 (positive일 확률)
- 출력 Layer에 적용하는 activation 함수
- Sigmoid(Logistic)
- loss 함수
- Binary crossentropy
- 파이토치 함수: BCELoss
