
이번 프로젝트는 기업연계로 기업에서 제공하는 AI를 연동하여 쿠팡이나 알리같은 오픈 마켓을 구현하는 프로젝트였다.
초기에는 AI가 상품데이터, 재고관리, 상품추천, 쇼핑몰 정보 등 대부분 자체적으로 관리해야 하는 정보들을 API로 제공했기 때문에, 해당 API를 하루에 한 번 호출하여 우리 DB에 적재하는 방식으로 데이터를 관리했다. 하지만, 이후에 자체적으로 상품데이터, 재고관리 등을 구축하게 되면서 이 과정이 필요없어져, 이번에 공부했던 내용들을 정리해두려 한다.
🤔 초기 구현과 대용량 데이터 처리의 고민
초기 구현 방식
초기에는 상품데이터가 1000개가량 밖에 되지 않았기때문에 배치처리에 대해 생각을 할 필요가 없었다. 때문에
아래와 같이 구현하였었다.
1.API 호출 및 데이터 수집
- offset 과 limit을 사용해서 모든 데이터를 가져올 때까지 반복 호출.
- 응답에서 HTTP200OK와 JSON데이터를 확인 후 save()
2 데이터 저장 및 업데이트
- 기존 데이터와 중복 여부를 확인하고 변경된 데이터만 업데이트
- 변경된 데이터는 삽입 및 삭제
3.오류 처리 및 재시도 로직
- API 호출 실패 시 재시도 처리
- 실패한 요청은 로그에 기록
👇🏻 초기 구현 방식으로 1000개 상품 데이터 처리 시 실행 시간 측정 결과. 5회 연속 측정 결과 평균 1673ms
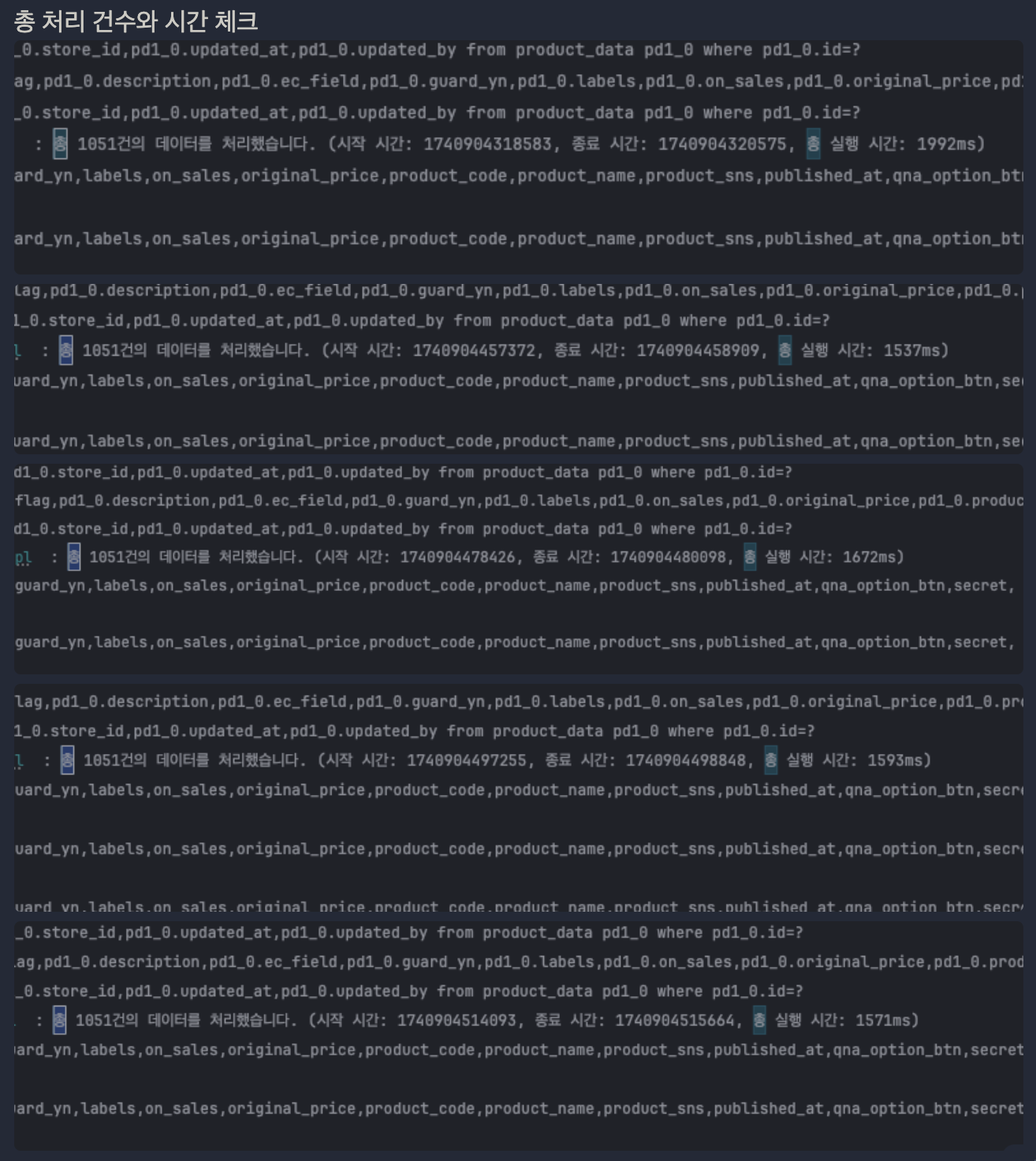
결과는 1~2초로 매우 빠르다. 외부 테스트 서버에 엑셀로 데이터를 먹일수 있었기 때문에 상품데이터를 늘려서 테스트 해보고 싶은 생각이 들었다. 12,000개 까지 데이터를 늘려서 다시 테스트.
총 실행시간 위부터 130960ms, 123012ms, 131477ms
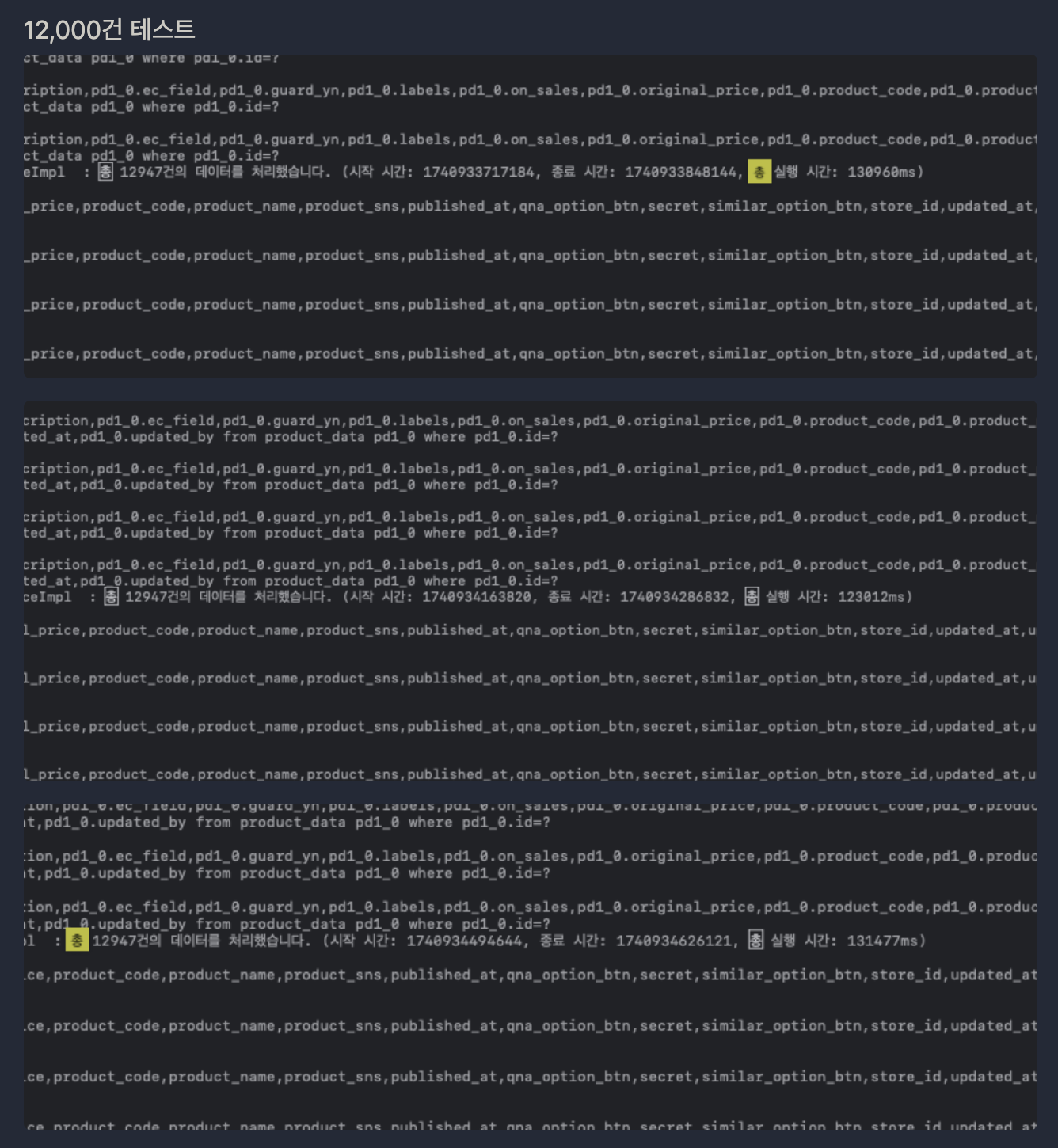
시간이 2분을 넘겨버렸다. 이후에는 limit의 크기를 늘려보면서 5000개가량씩 벌크처리할 때 시간이 제일 적게 걸리는걸 테스트를 통해 알게되었다. 그 이상씩을 처리하려하면 시간이 오히려 더 걸리게 되는데 그 이유로는 대량의 데이터를 처리하게 되면 FullGC 발생, DB 커넥션 유지시간 증가로 인한 성능저하등이 있다고 한다.
데이터 개수를 백만개까지 늘리려고 했을 때, 현재 구조의 문제점에 대해서 생각해 보았다.
- 중간에 데이터 전송이 실패했을경우 이미 성공했던 데이터에 대한 처리가 애매하다.. 기존의 경우에는 @Transactional 의 사용으로 실패시 롤백되기 때문에 처음부터 다시 시도해야 했기 때문에 개선 필요
- 트랜잭션의 범위: 메서드 전체에 @Transactional이 적용되어 있어서 모든 상품 저장이 하나의 트랜잭션으로 처리되고 있다. 데이터를 한번에 처리하려고 하기 때문에 메모리 사용량 증가, 또한 트랜잭션을 오랫동안 점유하는 문제가 있다.(데이터의 개수가 많아질수록 더 나빠짐)
- 에러처리의 부재: 실패한 지점에서 어떤게 문제였는지 로깅 및 모니터링 필요성(실패했을 경우 관리자에게 알림)
- 실패했을경우 어떻게 재시도 할 것인지에 대한 대책
이때부터 개선의 필요성을 느끼기 시작했다.
대용량 데이터 처리와 안정성 문제를 해결하기 위해 여러 방안을 검토했다. 단순히 코드를 개선하는 것보다 이미 검증된 프레임워크를 활용하는 것이 효율적이라고 판단했다. 특히 대용량 데이터 배치 처리에 특화된 Spring Batch가 눈에 들어왔다. Spring Batch를 도입하는 것이 시간과 안정성 측면에서 훨씬 유리하다고 판단했다.
Spring scheduler만 사용했을 때의 한계
-
작업 이력 관리의 어려움
- 작업 실행, 실패, 중지 상태에 대한 로깅 및 모니터링 기능 부재
- 수동으로 로깅 시스템을 구현해야 함
-
에러 처리의 복잡성
- 재시도 로직을 개발자가 직접 구현해야 함
- 유지보수 비용 증가
-
대용량 데이터 처리 한계
- 대량 데이터 처리를 위한 최적화 기능 부재
- 메모리 관리 및 성능 최적화 어려움
-
작업 상태 관리 기능 부재
- 실행 중인 작업의 상태 추적 어려움
- 장애 발생 시 복구 메커니즘 부재
-
확장성 제한
- 복잡한 병렬 처리, 분산 처리 시나리오 구현 어려움
- Scale-Out(서버/노드 수를 늘려 성능 확장) 지원 미흡
Spring batch 도입의 이점
-
상세한 실행 이력 관리
- 내부적으로 Job Repository를 통한 작업 이력 관리
- 다양한 메타데이터 테이블 제공:
- BATCH_JOB_EXECUTION: 작업 상태(EXIT_CODE), 작업 메시지(EXIT_MESSAGE) 제공
- BATCH_STEP_EXECUTION: 작업의 상태와 진행 상황 파악 가능
-
청크 기반 처리로 메모리 최적화
- 대용량 데이터를 청크(chunk) 단위로 분할 처리
- 메모리 사용량 최적화 및 성능 향상
- 각 청크별 독립적 트랜잭션 적용으로 데이터 정합성 보장
-
안정적인 에러 처리 및 복구 메커니즘
- 특정 건에 에러 발생 시 해당 청크만 롤백
- 설정에 따른 자동 재시도 및 에러 로깅
- 실패 지점부터 재시작 가능
-
데이터 무결성과 일관성 보장
- 재시도 및 오류 처리 전략 내장
- 트랜잭션 관리를 통한 데이터 정합성 유지
- 부분 실패 시에도 전체 작업이 중단되지 않음
-
병렬 및 분산 처리 지원
- 멀티 쓰레드 실행
- 병렬 스텝 실행
- 원격 청크 처리
- 데이터 파티셔닝을 통한 성능 최적화
-
모니터링 및 알림 기능
- 작업 실행 상태 모니터링
- 실패 시 이메일 발송 등 후속 조치 구현 용이
스프링 배치에 대한 자세한 학습내용은 깃허브 링크에 정리해두었다.
테스트 데이터 구성
백만 개의 상품 데이터로 테스트하기 위해 아래와 같은 방법을 시도했다.
1.테스트 서버에 직접 JSON 데이터를 주입하는 방식은 데이터 양이 많아지면서 시간이 너무 오래 걸려 사용할 수 없었다.
2. 10만 건까지는 VSCode의 JSON-server를 사용했으나, 데이터 양이 증가하자 브라우저에서 모든 데이터를 렌더링할 수 없는 문제가 발생했다. 아래처럼 json파일의 크기가 너무 크다는 에러가 발생한다.
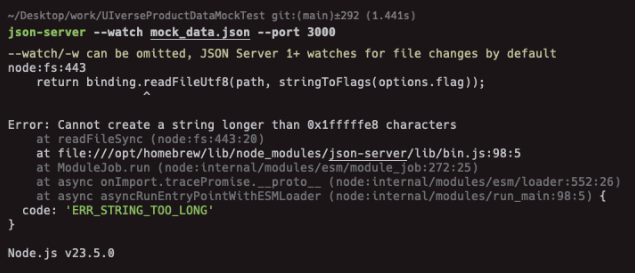
결국 데이터 mocking 방식을 선택하여 Python FastAPI와 SQLite3를 활용해 외부 API 서버를 구현했다. 아래는 sqlite DB에 넣고 조회한 결과이다.
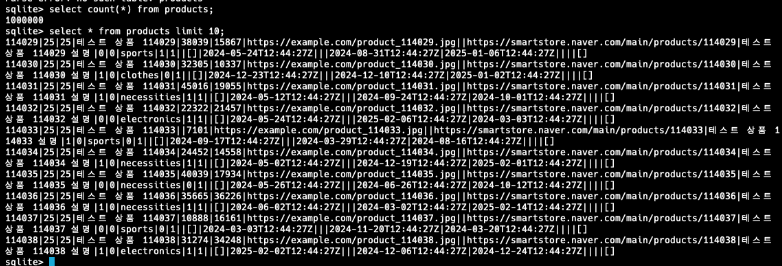
과한 스택들을 붙여 구현한것 같았지만 시간이 제약으로 인해 테스트 목적은 달성할 수 있었다는것에 만족하고 넘어갔다.
⚙️ Spring batch 적용
이제 Spring Batch를 적용하여 대용량 데이터 처리를 개선해 보았다. 먼저 전체적인 파일 구조는 다음과 같다
com.jishop.batch
│
│── ProductDataBatchConfig.java
│
│── ProductDataJobrunne.java
│
│── ProductDataItemReader.java
│
│── ProductDataItemProcessor.java
│
└── ProductDataItemWriter.javaSpring Batch 컴포넌트 구성
ProductDataReader
- ItemReader 인터페이스를 구현하여 외부 API에서 제품 데이터를 배치로 읽어오는 역할
- @Component로 Spring 컨테이너에 빈으로 등록
- @StepScope를 통해 Step 실행 시점에 빈이 생성되도록 설정
- RestTemplate을 사용하여 외부 API와 연동, ProductDataRequest 배열 형태로 데이터 수신
ProductDataProcessor
- ItemProcessor 인터페이스를 구현하여 읽어온 데이터를 정제하고 변환
- 필요한 비즈니스 로직을 적용하여 입력 데이터를 출력 형태로 변환
ProductDataWriter
- ItemWriter 인터페이스를 구현하여 처리된 데이터를 DB에 저장
- Spring Batch 파이프라인의 마지막 단계 담당
@Override
@Transactional
public void fetchAndSaveProductData() {
long startTime = System.currentTimeMillis();
int totalFetched = 0;
int batchSize = 100;
while (true) {
UriComponentsBuilder builder = UriComponentsBuilder.fromHttpUrl(apiUrl)
.queryParam("_start", totalFetched)
.queryParam("_limit", batchSize);
ProductDataRequest[] productDataRequests = restTemplate.getForObject(
builder.toUriString(),
ProductDataRequest[].class
);
if (productDataRequests == null || productDataRequests.length == 0) {
break; // 더 이상 데이터가 없으면 종료
}
for (ProductDataRequest request : productDataRequests) {
productRepository.save(request.toEntity());
}
totalFetched += productDataRequests.length;
}
long endTime = System.currentTimeMillis();
long totalTime = endTime - startTime;
log.info("총 {}건의 데이터를 처리했습니다. (시작 시간: {}, 종료 시간: {}, 총 실행 시간: {}ms)",
totalFetched, startTime, endTime, totalTime);
}Spring Batch 적용 후에는 Job Execution 정보를 통해 실행 시간과 처리 결과를 쉽게 확인할 수 있었다

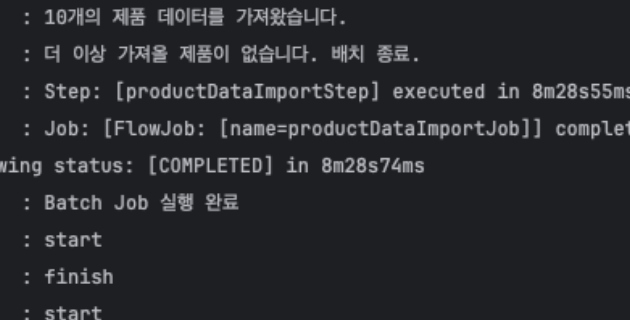
약 100만 건 처리 시 실행 시간은 약 7~8분 정도 소요되었다. 처리 속도를 개선하기 위해 청크 크기를 조정하며 테스트를 진행했다
Spring Batch는 JDBC와 ORM 모두를 위한 writer를 제공한다. 특히 writer는 chunk 단위의 마지막 단계로, DB 영속성과 관련해 항상 마지막에 Flush를 수행해야 한다.
ItemWriter는 크게 두 가지 종류가 있다
- JdbcBatchItemWriter: ORM을 사용하지 않는 경우 데이터베이스와의 교환 횟수를 최소화하여 성능 향상
- JpaItemWriter: ORM을 사용할 때 적합, Entity 클래스를 데이터로 전달할 때 사용
JpaItemWriter 적용
@Component
@RequiredArgsConstructor
public class ProductDataWriter implements ItemWriter<ProductData> {
private final EntityManagerFactory entityManagerFactory;
@Override
public void write(Chunk<? extends ProductData> items) {
JpaItemWriter<ProductData> jpaItemWriter = new JpaItemWriter<>();
jpaItemWriter.setEntityManagerFactory(entityManagerFactory);
jpaItemWriter.write(items);
}
}이렇게 하면 매 write()메서드 호출마다 새로운 JpaItemWriter객체를 생성해야 함으로 성능문제를 일으킬 수 있어 수정이 필요하다. 아래는 이를 개선한 코드이다.
@Component
@RequiredArgsConstructor
public class ProductDataWriter implements ItemWriter<ProductData> {
private final EntityManagerFactory entityManagerFactory;
private JpaItemWriter<ProductData> writer;
@PostConstruct
public void initialize() {
writer = new JpaItemWriter<>();
writer.setEntityManagerFactory(entityManagerFactory);
writer.setUsePersist(false); // merge 메서드 사용 (변경 감지)
try {
writer.afterPropertiesSet();
} catch (Exception e) {
throw new RuntimeException("JpaItemWriter 초기화 실패", e);
}
}
@Override
public void write(Chunk<? extends ProductData> items) throws Exception {
writer.write(items);
}
}위 방식의 핵심 포인트
JpaItemWriter는 한 번만 생성하고 초기화하여 재사용setUsePersist(false)를 설정하여 엔티티 저장 시merge()를 사용(기존 데이터 변경 감지)afterPropertiesSet()을 호출하여 JpaItemWriter를 정상적으로 초기화- 트랜잭션 관리 개선: chunk 단위(1000개 아이템)로 트랜잭션 시작/커밋
- 예외 발생 시 해당 청크만 롤백
Spring Batch의 청크 처리 메커니즘
Spring Batch의 청크 처리 방식은 대용량 데이터 처리에 여러 이점을 제공한다.
- 각 청크에 대한 처리 작업은 SimpleAsyncTaskExecutor에 의해 별도의 스레드에서 실행된다.
- SimpleAsyncTaskExecutor는 요청된 작업을 처리하기 위해 매번 새로운 스레드를 생성한다.
- 여러 개의 스레드가 병렬 처리되면서 처리 속도가 크게 향상된다.
청크 기반 처리의 주요 장점
- 스프링 배치는 청크 기반의 트랜잭션 관리를 제공 (platformTransactionManager 사용)
- 청크 크기를 1000으로 설정하면 1000개의 항목을 처리한 후, 한 번에 데이터베이스에 커밋한다
- 데이터베이스 I/O 호출을 최소화하여 성능 향상
- 지정된 청크 크기만큼의 데이터만 메모리에 로드하므로 메모리 사용량이 최적화
- 에러가 발생했을 때 해당 청크 전체를 롤백하여 다시 처리할 수 있어 데이터 무결성이 보장된다
재시도 매커니즘 및 오류 처리 적용
@Bean
public Step productDataImportStep() {
return new StepBuilder("productDataImportStep", jobRepository)
.<ProductDataRequest, ProductData>chunk(1000, transactionManager)
.reader(productDataReader)
.processor(productDataProcessor)
.writer(productDataWriter)
.allowStartIfComplete(true)
.faultTolerant()
.retry(RestClientException.class)
.retryLimit(3)
.build();
}이러한 구성으로 변경된 데이터만 효율적으로 감지하고 처리할 수 있게 되었다.
여기까지 구현한 후, 자체 상품 데이터를 구축하는 방식으로 전환하기로 결정했다. 기업에서 제공하는 API가 테스트 서버였기 때문에 우리 프로젝트가 실제 서비스처럼 구현되기 어렵다는 점, 그리고 프로젝트 기간이 종료된 후에도 해당 API의 지속적인 제공 여부가 불확실하다는 판단에서 외부 의존성을 제거하고자 했다.
지금 돌이켜보면 이 결정이 다소 무모했다는 생각이 든다. 개발 시간이 3주도 채 남지 않은 상황에서 이러한 큰 변경은 상당한 부담이었다. 프로젝트의 퀄리티와 팀원들의 업무 부담을 고려했다면 팀장으로서 더 신중한 결정을 내렸어야 했다는 아쉬움이 남는다. 이로 인해 고생한 팀원들에게 깊은 감사와 함께 미안한 마음을 전한다.
🔥 트러블슈팅
메타데이터 테이블 생성 오류

Spring Batch 작업을 실행했을 때 위와 같이 SQL 구문 오류가 발생했다. 특이한 점은 직접 SQL을 작성한 적이 없는데도 SELECT JOB_INSTANCE_ID, JOB_NAME 쿼리 실행 중 오류가 발생했다는 점이다.
공식문서에서 나와있는대로 분명 따랐는데 에러가 나서 당황스러웠다.
원인분석
1.테이블을 생성하는 sql에서 에러가 난 상황이다.
Spring Batch는 메타 데이터에 대한 저장을 위해 6개의 테이블을 필요로 하기 때문에 해당 테이블을 생성해야 한다.
batch.jdbc.initialize-schema: ALWAYS와 job.enabled: true 설정을 통해 자동 생성 되게 하려 했지만 반응이 없었다.
- 권한설정이 의심되어 DB 사용자 애꿎은 DB 권한 설정을 설정했다가 풀었다가 한참을 헤맸다. 그러다 DB 권한 문제라면 아예 연결이 안되거나 다른 종류의 에러가 발생했을 텐데, SQL 구문 오류라는 점이 이상했다.
해결
SQL을 삽입해주는 SQL문이 있을것이라고 생각하고 검색 했더니 schema를 삽입해주는 sql문이 있었다.(Spring-batch 의존성을 추가해주면 생성된다고한다.)
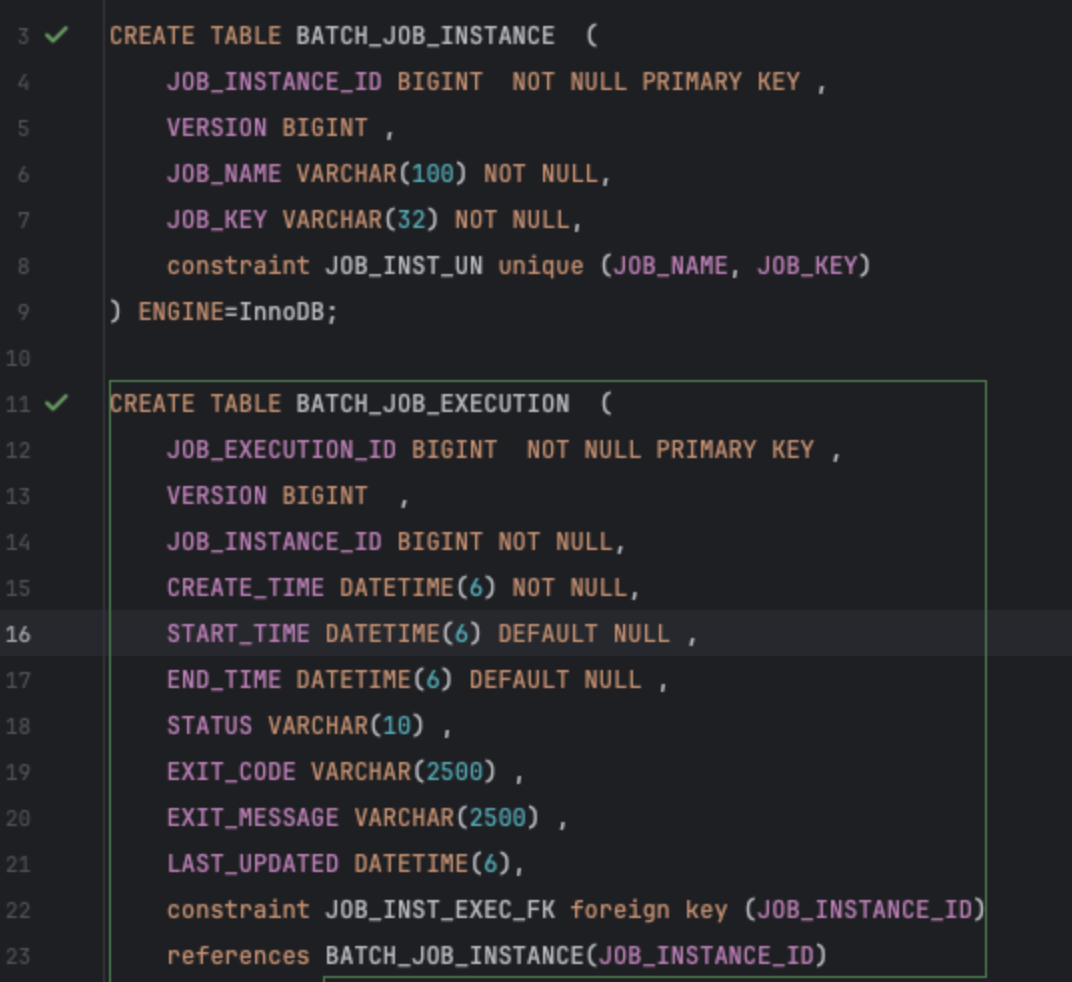
이렇게 쿼리가 짜져있다. DB마다의 쿼리가 짜져있는데 mysql을 사용하므로 해당 파일을 실행 시켜주었더니 무사히 테이블이 생성 되었다.
Job 재실행 문제
테스트 도중 에러가 터졌는데, 아래처럼 "Step already complete or not restartable" 에러 메시지가 출력 되었다.

원인 분석
Spring Batch는 JobParameters를 기준으로 같은 작업인지 구분한다.
즉, 코드가 동일하더라도 실행할 때 전달하는 JobParameters가 같다면 이전에 완료된 작업으로 판단하여 재실행되지 않는다. 새로운 작업으로 인식하려면 고유한 파라미터를 전달해야 한다.
BATCH_JOB_EXECUTION 파일을 확인해보니
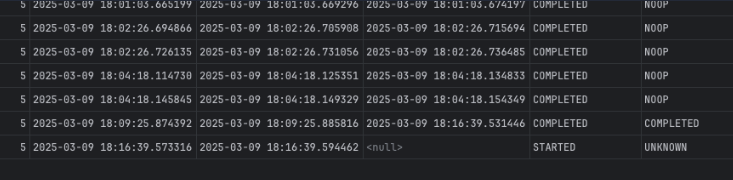
여기 END_TIME 이 기록되지 않은 상태로 비정상 종료된것 같았다.
해결
-
.addString("uuid", UUID.randomUUID().toString()) 각 실행마다 고유한 JobParameters를 생성했으나 해결되지 않았다.
-
에러를 보면 JobParameters가 빈 객체({})로 표시되고있는데 Spring Boot 가 Job을 자동 실행하면서 빈 파라미터로 실행하는 것이 문제였다는 생각이 들었다. spring.batch.job.enabled=false 설정을 한 이후 .addString("uuid", UUID.randomUUID().toString()) 설정으로 해결되었다.
📌 spring.batch.job.enabled 의 기본값은 true 이며, 그렇다면 애플리케이션이 실행될 때 Job이 자동으로 실행되게 된다. 👉 자동으로 Job을 실행할 때 별도로 파라미터가 전달되지 않으면, 기본적으로 빈 JobParameters객체가 생성되는데, 이것이 재실행 시 문제를 일으킨다.
향후 개선 고려사항
위 상황에서 이후에는 어떤것을 개선하려 했는지 정리하고 마치겠다.
- 로깅 및 모니터링 개선
- 데이터 변경 사항(추가, 삭제, 수정)을 감지하고 로그로 추적하는 기능 구현
- 관리자가 배치 작업의 상태와 결과를 쉽게 확인할 수 있는 대시보드 구현 고려
- 배치 프로세스 실패시 메일로 알람 오도록 구현
- HTTP 클라이언트 개선
- 현재 사용 중인 RestTemplate에서 WebClient로 마이그레이션 통한 HTTP 호출 부분 비동기 처리
논블로킹 I/O를 통한 리소스 효율성 향상
- 병렬 처리 최적화
- Spring Batch의 파티셔닝(Partitioning) 또는 멀티스레드 스텝(Multi-threaded Step) 활용 검토
- 서버 사양에 맞는 적절한 스레드 수 설정
👉 주의: 낮은 사양의 서버에서는 레이스 컨디션 및 오버헤드로 인해 오히려 성능이 저하될 수 있음
- 비동기 처리 도입
@Async
public void runJobAsync() {
runJob();
}이를 통해 배치 작업이 진행 중에도 쇼핑몰의 다른 기능이 정상적으로 작동할 수 있도록 커넥션 풀 관리를 개선할 수 있다.
-
현재 재시도로직을 retry로 Step에서 구성했지만, ItemStream 인터페이스를 구현하여 작업 진행 상태를 더 세밀하게 관리하고 중단된 지점부터 재시작할 수 있도록 개선
-
서버 리소스를 고려한 최적화
테스트 로컬 환경은 맥북 m1 16gb 였지만 운영환경은
aws t3.micro
- vCPU: 2개
- RAM: 1GB
- 네트워크 성능: 최대 5Gbps
이였기 때문에 생각처럼 원활한 진행이 안될 수 있다고 생각해 어떻게 해야할지 고민중 이였다.
🔗 참고링크
공식문서
https://docs.spring.io/spring-batch/reference/job/configuring.html
배치 시작시 문법오류해결
https://curiousjinan.tistory.com/entry/spring-boot-3-batch-5-table-creation-fix
호돌맨님의 스프링 배치
https://jojoldu.tistory.com/339
