
제네릭
- 컴파일 타임에 타입을 지정해 타입 안정성을 보장하고, 코드 재사용성을 높이는 기능
- 클래스, 인터페이스, 메서드에 사용이 가능
- 주로 타입을 명시하지 않고도 다양한 데이터 타입을 처리하는 데 사용
제네릭 클래스 & 인터페이스
사과와 연필을 저장하고 관리하기 위해 각각의 기능을 수행하는 클래스를 생성
package com.test;
class Apple {
}
class Pencil {
}
class ManageApple {
private Apple apple = new Apple();
public Apple get() {
return this.apple;
}
public void set(Apple apple) {
this.apple = apple;
}
}
class ManagePencil {
private Pencil pencil = new Pencil();
public Pencil get() {
return this.pencil;
}
public void set(Pencil pencil) {
this.pencil = pencil;
}
}
public class MyTest {
public static void main(String[] args) {
ManageApple apple = new ManageApple();
apple.set(new Apple());
Apple newApple = apple.get();
ManagePencil pencil = new ManagePencil();
pencil.set(new Pencil());
Pencil newPencil = pencil.get();
}
}새로운 상품이 추가될 때마다 새로운 관리 클래스(Manage000)를 만들어야 하는 문제가 발생
해결 방법 1. 필드를 모든 자바 클래스의 최상위 클래스인 Object 타입으로 선언
package com.test;
class Apple {
}
class Pencil {
}
class Manage {
private Object object = new Object();
public Object get() {
return this.object;
}
public void set(Object object) {
this.object = object;
}
}
public class MyTest {
public static void main(String[] args) {
Manage apple = new Manage();
apple.set(new Apple());
Apple newApple = (Apple)apple.get();
Manage pencil = new Manage();
pencil.set(new Pencil());
Pencil newPencil = (Pencil)pencil.get();
}
}데이터를 저장(set())할 때는 아무런 문제가 없으나, 저장된 데이터를 가져올 때(get())는 저장된 형태로 캐스팅을 해야 함 ⬇️
package com.test;
class Apple {
}
class Pencil {
}
class Manage {
private Object object = new Object();
public Object get() {
return this.object;
}
public void set(Object object) {
this.object = object;
}
}
public class MyTest {
public static void main(String[] args) {
Manage goods = new Manage();
goods.set(new Apple());
// error. java.lang.ClassCastException
// class Apple cannot be cast to class Pencil
Pencil pen = (Pencil)goods.get();
}
}=> 약한 타입 체크를 하기 때문에 컴파일 시점에서 캐스팅 오류가 발생하는지 알 수 없음
=> 실행 시점에 실제 인스턴스 타입에 따라서 오류가 발생
=> 잘못된 캐스트로 발생할 수 있는 문제점을 사전에 예방하려면, 강한 타입 체크가 될 수 있도록 코드를 작성
=> 제네릭 클래스, 제네릭 인터페이스 문법을 사용하자 !!
제네릭 클래스와 제네릭 인터페이스를 정의
접근지정자 class 클래스이름 <제네릭타입변수> {
// 제네릭타입변수를 사용하는 코드
}접근지정자 class 클래스이름 <제네릭타입변수, 제네릭타입변수> {
// 제네릭타입변수를 사용하는 코드
}접근지정자 interface 인터페이스이름 <제네릭타입변수> {
// 제네릭타입변수를 사용하는 코드
}접근지정자 interface 인터페이스이름 <제네릭타입변수, 제네릭타입변수> {
// 제네릭타입변수를 사용하는 코드
}제네릭 타입 변수명은 사용자가 임의로 지정할 수 있지만, 관례적으로 아래와 같이 사용
T type
K key
V value
N number
E element제네릭 클래스의 객체(인스턴스) 생성 => 객체를 생성할 때 제네릭 타입 변수에 실제 타입을 대입
클래스명<실제제네릭타입> 참조변수명 = new 클래스명<실제제네릭타입>();
or
클래스명<실제제네릭타입> 참조변수명 = new 클래스명<>();
package com.test;
class Apple {
}
class Pencil {
}
class Manage<T> {
private T t;
public T get() {
return this.t;
}
public void set(T t) {
this.t = t;
}
}
public class MyTest {
public static void main(String[] args) {
Manage<Apple> goods = new Manage();
goods.set(new Apple());
// error. com. test. Apple'을(를) 'com. test. Pencil'(으) 로 형 변환할 수 없습니다
Pencil pen = (Pencil)goods.get();
}
}=> 강한 타입체크가 되기 때문에 컴파일 시점에 캐스팅 오류를 발견할 수 있음
제네릭 클래스의 객체를 생성할 때 <실제 제네릭 타입>을 생략하면, Object가 대입된다
class A<T> {
T t;
// ....
A a = new A(); => A<Object> a = new A<Object>();사용 예
package com.test;
class MyClass<T> {
private T t;
public T get() {
return this.t;
}
public void set(T t) {
this.t = t;
}
}
public class MyTest {
public static void main(String[] args) {
MyClass<String> mc1 = new MyClass<String>();
mc1.set("안녕");
System.out.println(mc1.get());
MyClass<Integer> mc2 = new MyClass<>();
mc.set(1234);
System.out.println(mc.get());
MyClass<String> mc3 = new MyClass<>();
mc3.set(1234); // error. 강한 타입 체크
System.out.println(mc.get());
}
}사용 예: <K, V> & 사용하는 시점에 타입을 지정할 수 있다 !
package com.test;
class KeyValue<K, V> {
private K key;
private V value;
public K getKey() {
return this.key;
}
public void setKey(K key) {
this.key = key;
}
public V getValue() {
return this.value;
}
public void setValue(V value) {
this.value = value;
}
public void print() {
System.out.println(this.key + " = " + this.value);
}
}
public class MyTest {
public static void main(String[] args) {
KeyValue<String, Integer> kv1 = new KeyValue<>();
kv1.setKey("사과");
kv1.setValue(10000);
kv1.print(); // 사과 = 10000
KeyValue<Integer, String> kv2 = new KeyValu<>();
kv2.setKey(1);
kv2.setValue("첫번째");
kv2.print(); // 1 = 첫번째
// 키 값만 사용하는 경우
KeyValue<String, Void> kv3 = new KeyValue<>();
kv3.setKey("키만 사용");
kv3.setValue("aksdksad"); // error. void이므로 !
kv3.print(); // 키만 사용 = null
}
}값이 없으면 Void 로 !
제네릭 메서드
- 리턴타입 또는 매개변수의 타입을 제네릭 타입으로 선언
제네릭 타입 변수명이 1개인 경우 ⬇️
접근지정자 <T> T 메서드명(T t) { ... } ~~ ~~~ 반환타입 매개변수제네릭 타입 변수명이 2개인 경우 ⬇️
접근지정자 <T, V> T 메서드명(T t, V v) { ... }매개변수에만 제네릭이 사용되는 경우 ⬇️
접근지정자 <T> 반환타입 메서드명(T t) { ... }리턴 타입에만 제네릭이 사용되는 경우 ⬇️
접근지정자 <T> T 메서드명(int a) { ... }
메서드 정의 예시
class GenericMethod {
public <T> T method1(T t) {
return t;
}
public <T> boolean method2(T t1, T t2) {
return t1.equals(t2);
}
public <K, V> void method3(K k, V v) {
System.out.println(k + " : " + v);
}
}제네릭 메서드를 호출할 때 호출할 메서드 앞에 <실제제네릭타입>을 추가해야 함
참조객체.<실제제네릭타입>메서드명(매개변수);
package com.test;
class GenericMethod {
public <T> T method1(T t) {
return t;
}
public <T> boolean method2(T t1, T t2) {
return t1.equals(t2);
}
public <K, V> void method3(K k, V v) {
System.out.println(k + " : " + v);
}
}
public class MyTest {
public static void main(String[] args) {
GenericMethod gm = new GenericMethod();
String s = gm.<String>method1("문자열");
System.out.println(s);
int i = gm.<Integer>method1(123);
System.out.println(i);
boolean b = gm.<String>method2("안녕", "안녕");
System.out.println(b);
gm.<String, Integer>method3("첫번째", 123);
gm.<Integer, String>method3(123, "두번째");
}
}
매개변수 값으로 제네릭 타입을 유추할 수 있는 경우, 제네릭 타입 지정을 생략할 수 있다.
package com.test;
class GenericMethod {
public <T> T method1(T t) {
return t;
}
public <T> boolean method2(T t1, T t2) {
return t1.equals(t2);
}
public <K, V> void method3(K k, V v) {
System.out.println(k + " : " + v);
}
}
public class MyTest {
public static void main(String[] args) {
GenericMethod gm = new GenericMethod();
String s = gm.method1("문자열");
System.out.println(s);
int i = gm.method1(123);
System.out.println(i);
boolean b = gm.method2("안녕", "안녕");
System.out.println(b);
gm.method3("첫번째", 123);
gm.method3(123, "두번째");
}
}제네릭 메서드 내에서는 기본적으로 Object에서 물려받은 메서드만 사용이 가능하다
public <T> T method1(T t) {
// The method length() is undefined for the type T
// int string Length = t.length();
String classDesct = t.toString();
return t;
}length()는 안 되고 toString()은 가능 !
제네릭 타입 범위 제한(bound)
제네릭 타입으로 올 수 있는 실제 타입의 종류를 제한
=> 메서드 내부에서 사용할 수 있는 메서드가 증가
제네릭 클래스의 타입 제한
접근지정자 class 클래스명 <제네릭타입 extends 클래스/인터페이스명> { ... }항상 extends만 쓴다.
사용 예
package com.test;
class Fruit {
public void print() {
System.out.println("과일");
}
}
class Apple extends Fruit{}
class Pencil {}
class Goods<T extends Fruit> {
private T t;
public T get() {
t.print();
return this.t;
}
public void set(T t) {
t.print(); // <= 제한된 범위 내에서 사용할 수 있는 메서드를 사용하는 것이 가능
this.t = t;
}
}
public class MyTest {
public static void main(String[] args) {
Goods<Apple> goods1 = new Goods<>();
goods1.set(new Apple());
// error. Pencil이 바운드 내에 없다
Goods<Pencil> goods2 = new Goods<>(); // 제한된 범위 밖의 타입이 사용되는 것을 방지 !!
goods2.set(new Pencil());
}
}제네릭 메서드의 타입 제한
접근지정자 <T extends 클래스/인터페이스명> T 메서드명(T t) { ... }
사용 예
package com.test;
class GenericMethod {
/*
public <T> void method(T t) {
char c = t.charAt(0); // Object 메서드만 사용 가능
System.out.println(t);
}
*/
public <T extends String> void method(T t) {
char c = t.charAt(0); // Object 메서드와 String 메서드 사용이 가능
System.out.println(t);
}
}
public class MyTest {
public static void main(String[] args) {
GenericMethod gm = new GenericMethod();
gm.<String>method("문자열");
gm.<Integer>method(123); // error. Bound mismatch
}
}메서드 매개변수일 때 제네릭 클래스의 타입 제한
리턴타입 메서드명(제네릭클래스명<제네릭타입명> 참조변수명) { ... }
method(Goods<Apple> v)=> 제네릭타입 = Apple인 객체만 가능리턴타입 메서드명(제네릭클래스명<?> 참조변수명) { ... }
method(Goods<?> v)=> 제네릭타입 = 모든 타입인 객체 가능리턴타입 메서드명(제네릭클래스명<? extends 클래스/인터페이스명> 참조변수명) { ... }
method(Goods<? extends Fruit> v)=> 제네릭타입 = Fruit 또는 Fruit의 자식 클래스인 객체만 가능리턴타입 메서드명(제네릭클래스명<? super 클래스/인터페이스명> 참조변수명) { ... }
method(Goods<? super Fruit> v)=> 제네릭타입 = Fruit 또는 Fruit의 부모 클래스인 객체만 가능
package com.test;
class A {}
class B extends A {}
class C extends B {}
class D extends C {}
class Goods<T> {
private T t;
public T get() { return this.t; }
public void set(T t) { this.t = t; }
}
class GenericMethod {
void method1(Goods<A> g) {} // case1
void method2(Goods<?> g) {} // case2
void method3(Goods<? extends B> g) {} // case3
void method4(Goods<? super B> g) {} // case4
}
public class MyTest {
public static void main(String[] args) {
GenericMethod gm = new GenericMethod();
// case1 : <A>만 가능
gm.method1(new Goods<A>());
//gm.method1(new Goods<B>()); // error
//gm.method1(new Goods<C>()); // error
//gm.method1(new Goods<D>()); // error
//gm.method3(new Goods<String>()); // error
// case2 : 모두 가능
gm.method2(new Goods<A>());
gm.method2(new Goods<B>());
gm.method2(new Goods<C>());
gm.method2(new Goods<D>());
gm.method2(new Goods<String>());
// case3 : 자식들 가능
//gm.method3(new Goods<A>()); // error
gm.method3(new Goods<B>());
gm.method3(new Goods<C>());
gm.method3(new Goods<D>());
// gm.method3(new Goods<String>()); // error
// case4: 부모만 가능
gm.method4(new Goods<A>());
gm.method4(new Goods<B>());
// gm.method4(new Goods<C>()); // error
// gm.method4(new Goods<D>()); // error
// gm.method4(new Goods<String>()); // error
}
}제네릭 클래스의 상속 ⭐️⭐️⭐️
=> 부모 클래스가 제네릭 클래스일 때, 이를 상속한 자식 클래스도 제네릭 클래스가 된다.
=> 제네릭 타입 변수를 자식 클래스가 그대로 물려받게 되고, 또한 자식 클래스는 제네릭 타입 변수를 추가로 정의할 수 있다.
=> 자식 클래스의 제네릭 타입 변수의 개수는 항상 부모보다 같거나 많게 된다.
부모 클래스와 제네릭 타입 변수의 개수가 동일한 경우 ⬇️
class Parent <K, V> { ... } class Child<K, V> extends Parent<K, V> { ... }부모 클래스보다 제네릭 타입 변수의 개수가 많은 경우 ⬇️
class Parent <K> { ... } class Child<K, V> extends Parent<K> { ... }
사용 예
package com.test;
class Parent<T> {
private T t;
public T getT() { return this.t; }
public void setT(T t) { this.t = t; }
}
class Child1<T> extends Parent<T> { }
class Child2<T, V> extends Parent<T> {
private V v;
public V getV() { return this.v; }
public void setV(V v) { this.v = v; }
}
public class MyTest {
public static void main(String[] args) {
// 부모 제네릭 클래스
Parent<String> p = new Parent<>();
p.setT("부모 제네릭 클래스");
System.out.println(p.getT());
// 자식 클래스 1
Child1<String> c1 = new Child1<>();
c1.setT("자식 클래스 1");
System.out.println(c1.getT());
// 자식 클래스 2
Child2<String, Integer> c2 = new Child2<>();
c2.setT("자식 클래스 2");
c2.setV(1234);
System.out.println(c2.getT());
System.out.println(c2.getV());
}
}제네릭 메서드도 상속이 가능
package com.test;
class Parent {
<T extends Number> void print(T t) {
System.out.println(t);
}
}
class Child extends Parent { }
public class MyTest {
public static void main(String[] args) {
Parent p = new Parent();
p.<Integer>print(10); // 사용할 때 타입 지정
p.print(100);
Child c = new Child();
c.<Double>print(5.8);
c.print(5.8);
}
}컬렉션(Collection) ⭐️
데이터의 저장 용량(capacity, 저장할 수 있는 최대 데이터의 개수)을 동적으로 관리
컬렉션 프레임워크 ⇒ 리스트, 스택, 큐, 트리 등의 자료구조에 정렬, 탐색 등의 알고리즘을 구조화해 놓은 프레임워크
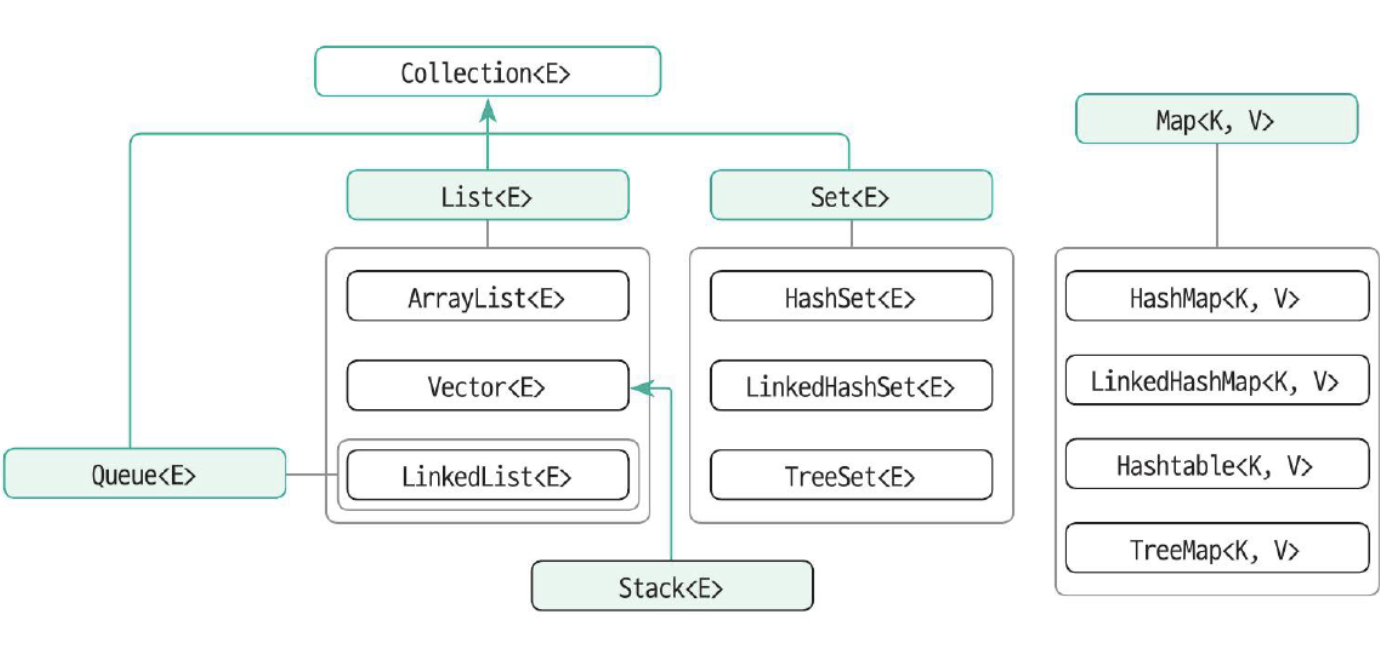
ArrayList, HashMap 등 많이 쓰인다.
List<E> 컬렉션 인터페이스
크기가 가변적이다
package com.test;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class MyTest {
public static void main(String[] args) {
String[] strArr = new String[] { "가", "나", "다", "라" };
System.out.println(strArr.length); // 4
strArr[2] = null;
strArr[3] = null;
System.out.println(strArr.length); // 4
System.out.println(Arrays.toString(strArr)); // [가, 나, null, null]
List<String> arrList = new ArrayList(); // 문자열을 데이터로 갖는 리스트 ⭐️️️⭐️️️⭐️️ List가 인터페이스 ArrayList는 서브클래스
arrList.add("가");
arrList.add("나");
arrList.add("다");
arrList.add("라");
System.out.println(arrList.size()); // 4
arrList.remove("라");
arrList.remove(2);
System.out.println(arrList.size()); // 2
System.out.println(arrList); // [가, 나]
}
}List<E> 인터페이스를 구현한 대표적인 클래스 => ArrayList<E>, Vector<E>, LinkedList<E>
-
ArrayList<E>배열처럼 동작한다. index로 특정 값 접근 가능 ! -
Vector<E>ArrayList와 비슷한데 동기화 구현이 되어있어서 thread에 안전하다. 동시에 쓰레드가 접근을 해도 처리가 다 끝나야만 다음 쓰레드를 처리한다.- 공유 자원: 멀티 쓰레드 환경에서 각 쓰레드들이 함께 사용할 수 있는 자원
=> 통제가 잘못되면 동기화 오류(의도한 대로 동작하지 않는 것)나 교착 상태에 빠질 수 있다.
교착 상태 해결하려면 한 번에 한 쓰레드만 가능하게 하면 된다. => 동기화 처리
동기화 처리 잘못되면 대기열이 길어지고 프로세스 처리가 늦어진다.
이를 방지하려면 꼭 필요한 데(임계 영역)에서만 동기화 처리를 해줘야 한다.
- 공유 자원: 멀티 쓰레드 환경에서 각 쓰레드들이 함께 사용할 수 있는 자원
-
LinkedList<E>선후관계를 나타내는 포인트(주소)만 가지고 있다.
💡ArrayList<E> VS LinkedList<E>
읽거나(참조) 수정할 때는 index 기반의 ArrayList가 더 빠르다!
중간에 삭제하거나 추가할 때는 뒤에 것이 하나씩 밀려나야 하므로 ArrayList보다 포인트만 가리키면 되는 LinkedList가 훨씬 빠르다!
package com.test;
import java.util.*;
public class MyTest {
public static void main(String[] args) {
List<Integer> list1 = new ArrayList<>();
List<Integer> list2 = new ArrayList<>(30);
List<Integer> vector1 = new Vector<>();
List<Integer> vector2 = new Vector<>(30);
List<Integer> linked1 = new LinkedList<>();
List<Integer> linked2 = new LinkedList<>(30); // LinkedList는 capacity 지정이 불가능
}
}Arrays.asList() 메서드를 이용해서 List 타입의 참조변수에 값을 할당 ⇒ 저장 공간의 크기를 변경할 수 없음
마치 배열처럼 동작한다.
고정된 개수의 데이터를 저장하고 활용할 때 쓴다.
package com.test;
import java.util.*;
public class MyTest {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(1, 2, 3, 4);
System.out.println(list); // [1, 2, 3, 4]
list.set(1, 20);
System.out.println(list); // [1, 20, 3, 4]
// 저장공간의 크기를 변경할 수 없다.
list.add(50); // error
list.remove(0); // error
}
}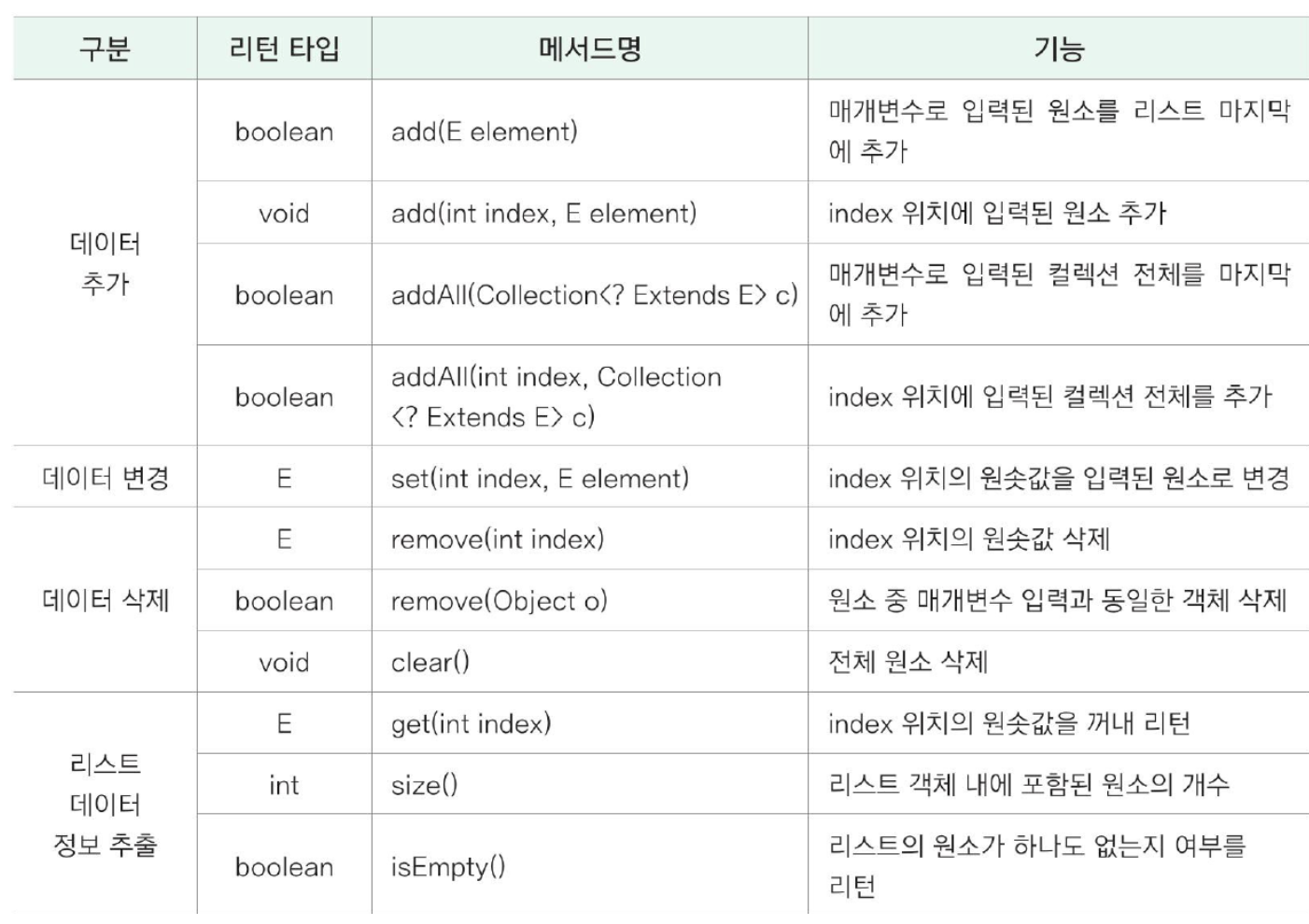
ArrayList<E> 구현 클래스 ⭐️⭐️⭐️⭐️⭐️
- List<E> 인터페이스를 구현한 구현 클래스
- 배열처럼 수집(collect)한 원소(element)를 인덱스(index)로 관리하며, 저장 용량(capacity)을 동적으로 관리
- 데이터 추가
add(value), add(index, value)- 컬렉션 객체 추가
addAll(values), addAll(index, values)- 데이터 변경
set(index, value)- 데이터 삭제
remove(index), remove(value)- 데이터 정보 조회
list.isEmpty(),list.size(),list.get(0)- 배열로 변환
list.toArray()
package com.test;
import java.util.*;
public class MyTest {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
// 데이터 추가 >>> add(value), add(index, value)
list.add(3);
list.add(4);
list.add(5);
System.out.println(list); // [3, 4, 5]
System.out.println(list.toString()); // [3, 4, 5]
list.add(1, 40);
System.out.println(list); // [3, 40, 4, 5] 1번 인덱스에 40을 넣으면 원래 것은 뒤로 밀린다 (인덱스가 조정됨)
List<Integer> list2 = new ArrayList<>();
list2.add(100);
list2.add(200);
// 컬렉션 객체 추가 >>> addAll(values), addAll(index, values)
list.addAll(list2); // 여러 개 데이터를 넣을 수 있다
System.out.println(list); // [3, 40, 4, 5, 100, 200] 기존 리스트의 마지막에 추가
list.addAll(1, list2);
System.out.println(list); // [3, 100, 200, 40, 4, 5, 100, 200]
// 데이터 변경 >>> set(index, value)
list.set(1, 111);
System.out.println(list); // [3, 111, 200, 40, 4, 5, 100, 200]
// list.set(8, 8888); // error. index 없는 경우 index out of bound
// 데이터 삭제 >>> remove(index), remove(value)
list.remove(1);
System.out.println(list); // [3, 200, 40, 4, 5, 100, 200]
list.remove(1);
System.out.println(list); // [3, 40, 4, 5, 100, 200]
list.remove(Integer.valueOf(100));
System.out.println(list); // [3, 40, 4, 5, 200]
list.add(40);
System.out.println(list); // [3, 40, 4, 5, 200, 40]
list.remove(Integer.valueOf(40)); // [3, 4, 5, 200, 40] 첫 번째만 삭제된다
System.out.println(list);
list.clear();
System.out.println(list); // []
// 데이터 정보 조회 >>>
System.out.println(list.isEmpty()); // true
list.add(1);
list.add(2);
System.out.println("리스트의 크기: " + list.size()); // 2
System.out.println("1번째 : " + list.get(0)); // 1
// 배열로 변환
Object[] o = list.toArray();
System.out.println(Arrays.toString(o)); // [1, 2]
Integer[] i1 = list.toArray(new Integer[0]); // 새로 정의한 배열의 크기가 List 사이즈보다 작으면 List 개수만큼 채워진다.
System.out.println(Arrays.toString(i1)); // [1, 2]
Integer[] i2 = list.toArray(new Integer[4]); // 새로 정의한 배열의 크기가 List 사이즈보다 크면 null로 채워진다.
System.out.println(Arrays.toString(i2)); // [1, 2, null, null]
}
}Set<E> 컬렉션 인터페이스
인덱스가 없고, 데이터의 중복을 허용하지 않는다.
=> 순회해서 데이터를 찾아야 한다.
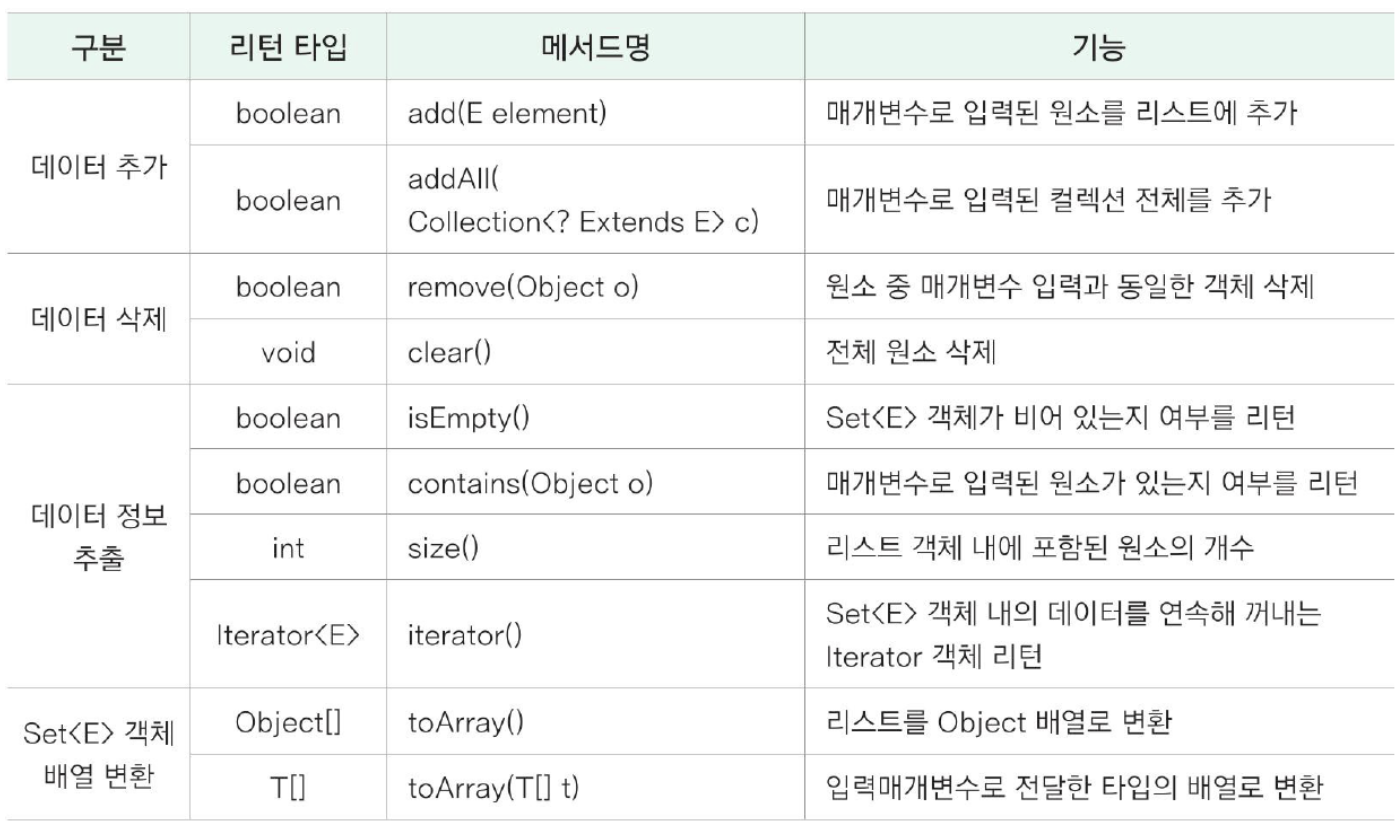
Set<E>의 모든 데이터를 하나씩 가져오는 방법
1. iterator() 메서드로 Iterator<E> 객체로 반환 받아서 활용
2. for-each 구문 이용
Set<E> 인터페이스를 상속받아 구현한 대표적인 구현 클래스 => HashSet<E>, LinkedHashSet<E>, TreeSet<E>
HashSet<E>
package com.test;
import java.util.*;
public class MyTest {
public static void main(String[] args) {
Set<String> hset = new HashSet<>();
hset.add("하나");
hset.add("둘");
hset.add("셋");
System.out.println(hset); // [둘, 하나, 셋]
Set<String> hset2 = new HashSet<>();
hset2.add("하나"); // 중복이므로 안 들어간다.
hset2.add("가");
hset2.add("나");
hset.addAll(hset2);
System.out.println(hset); // [가, 둘, 나, 하나, 셋]
// 데이터 삭제
hset.remove("나");
System.out.println(hset); // [가, 둘, 하나, 셋]
hset.clear();
System.out.println(hset); // []
// 데이터 정보 추출
System.out.println(hset.isEmpty()); // true
hset.add("가");
hset.add("나");
hset.add("다");
System.out.println(hset.contains("나")); // true
System.out.println(hset.contains("너")); // false
System.out.println(hset.size()); // 3
Iterator<String> iterator = hset.iterator();
while(iterator.hasNext()) {
// 다음 내가 가져올 데이터가 있는지 확인
System.out.println(iterator.next()); // 다음 데이터를 가져오기. 가 다 나
}
for(String s : hset) {
System.out.println(s); // 가 다 나
}
// 배열로 변환
Object[] objArr = hset.toArray();
System.out.println(Arrays.toString(objArr)); // [가, 다, 나]
String[] strArr1 = hset.toArray(new String[0]);
System.out.println(Arrays.toString(strArr1)); // [가, 다, 나]
String[] strArr2 = hset.toArray(new String[5]);
System.out.println(Arrays.toString(strArr2)); // [가, 다, 나, null, null]
}
}package com.test;
import java.util.*;
class A {
int data;
public A(int data) {
this.data = data;
}
}
public class MyTest {
public static void main(String[] args) {
Set<A> hset1 = new HashSet<>();
// 3개 다 다르다고 판단. 주소가 다르다
hset1.add(new A(3));
hset1.add(new A(3));
hset1.add(new A(3));
System.out.println(hset1.size());
for(A a : hset1) {
System.out.println(a + " : " + a.data);
}
}
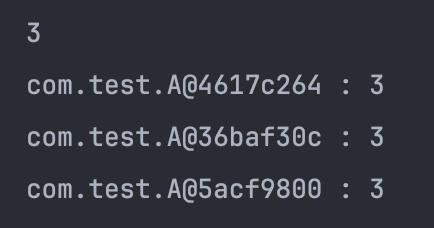
}위의 코드를 실행하면 모든 new A(3)이 서로 다른 객체 주소를 가지고 있는 것을 확인할 수 있다. ⇒ HashSet에 크기가 3으로 출력
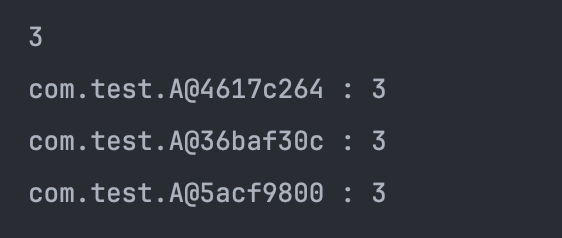
- 이를 해결하기 위해 equals 메서드만 오버라이드해보자 ! ⬇️
package com.test;
import java.util.*;
class A {
int data;
public A(int data) {
this.data = data;
}
@Override
public boolean equals(Object o) {
if (o instanceof A) {
if (this.data == ((A)o).data)
return true;
}
return false;
}
}
public class MyTest {
public static void main(String[] args) {
Set<A> hset1 = new HashSet<>();
// 3개 다 다르다고 판단. 주소가 다르다
hset1.add(new A(3));
hset1.add(new A(3));
hset1.add(new A(3));
System.out.println(hset1.size());
for(A a : hset1) {
System.out.println(a + " : " + a.data);
}
}
}
여전히 3개로 인식한다 ,,
💡 hashCode() 메서드의 반환값을 먼저 비교를 한 후 equals() 메서드의 반환값을 비교한다.
- hashCode() 메서드를 오버라이딩 해보자
package com.test;
import java.util.*;
class A {
int data;
public A(int data) {
this.data = data;
}
@Override
public boolean equals(Object o) {
if (o instanceof A) {
if (this.data == ((A)o).data)
return true;
}
return false;
}
@Override
public int hashCode() {
// return Objects.hash(this.data);
// return (Integer.valueOf(this.data)).hashCode();
return data;
}
}
public class MyTest {
public static void main(String[] args) {
Set<A> hset1 = new HashSet<>();
// 3개 다 다르다고 판단. 주소가 다르다
hset1.add(new A(3));
hset1.add(new A(3));
hset1.add(new A(3));
System.out.println(hset1.size());
for(A a : hset1) {
System.out.println(a + " : " + a.data);
}
}
}위의 코드를 실행하면 HashSet의 크기가 1이 되는 것을 확인할 수 있다.
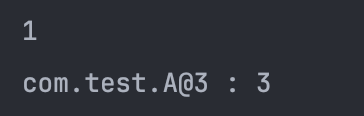
🔑 HashSet을 쓸 때는 hashCode와 equals 메서드를 오버라이딩 해야한다.
hashSet을 사용하면 기본적으로 정의되어 있는 클래스에는 절대 중복이 허용되지 않도록
내부적으로 hashCode()랑 equals()가 돌아가는데,
A같은 우리가 직접 만든 클래스는 hashSet이 모르니까 중복 제거가 안 된다.
그래서 hashCode()랑 equals()를 동일하게 오버라이딩 해줘야 중복 제거가 된다.
LinkedHashSet<E> 구현 클래스
=> HashSet<E>을 상속한 클래스로,
연결 정보가 추가
=> 중복 제거 & 출력 순서와 입력 순서가 동일하다
public class MyTest {
public static void main(String[] args) {
Set<Integer> iset = new LinkedHashSet<>();
iset.add(100);
iset.add(10);
iset.add(2);
iset.add(10);
System.out.println(iset); // [100, 10, 2]
}
}TreeSet<E> 구현 클래스
=> 크기에 따른 정렬 및 검색 기능이 추가된 컬렉션
=> 중복 제거 & 데이터 입력 순서와 상관없이 크기 순으로 정렬되어 출력
public class MyTest {
public static void main(String[] args) {
Set<Integer> iset = new TreeSet<>();
iset.add(100);
iset.add(10);
iset.add(2);
iset.add(10);
System.out.println(iset); // [2, 10, 100]
}
}Map<K, V> 컬렉션 인터페이스
- Key, Value 한 쌍으로 데이터를 저장
- Key는 중복 저장 불가, Value는 중복이 가능
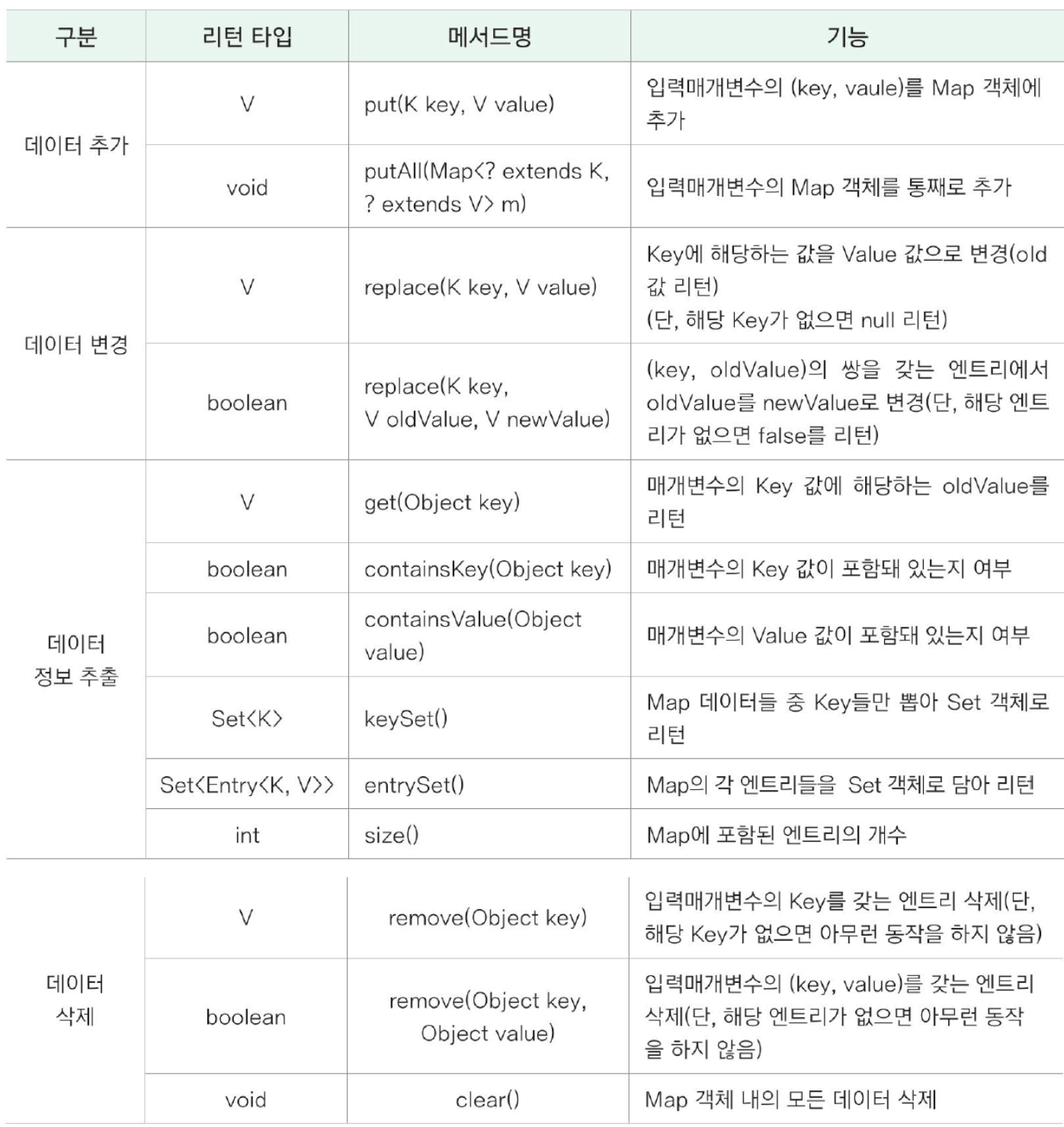
Map<K, V> 인터페이스를 구현한 대표 구현 클래스 => HashMap<K, V>, LinkedHashMap<K, V>, Hashtable<K, V>, TreeMap<K, V>
- LinkedHashMap<K, V> - 입력한 순서대로 나온다.
HashMap<K, V> ⭐️⭐️⭐️⭐️⭐️
Key 값의 중복 여부를 확인하는 방법 => Key 객체의 hashCode() 값이 같고, equals() 메서드가 true를 반환하면 같은 객체로 인식하고, 그 외는 다른 객체로 간주
들어간 순서대로 나오지 않는다.
package com.test;
import java.util.*;
public class MyTest {
public static void main(String[] args) {
Map<Integer, String> hmap = new HashMap<>();
// 데이터 추가
hmap.put(2, "두번째");
hmap.put(1, "첫번째");
hmap.put(3, "세번째");
System.out.println(hmap); // {1=첫번째, 2=두번째, 3=세번째}
Map<Integer, String> hmap2 = new HashMap<>();
hmap2.put(1, "FIRST");
hmap2.put(4, "FOURTH");
hmap.putAll(hmap2); // 키 중복이 있으면 뒤에 들어오는 것이 덮어쓴다.
System.out.println(hmap); // {1=FIRST, 2=두번째, 3=세번째, 4=FOURTH}
// 데이터 정보를 조회
System.out.println(hmap.get(1));
System.out.println(hmap.get(4));
System.out.println(hmap.containsKey(1)); // true
System.out.println(hmap.containsKey(5)); // false
System.out.println(hmap.containsValue("첫번째")); // false
System.out.println(hmap.containsValue("FISRT")); // true
Set<Integer> keySet = hmap.keySet();
System.out.println(keySet); // [1, 2, 3, 4]
Set<Map.Entry<Integer, String>> entrySet = hmap.entrySet();
System.out.println(entrySet); // [1=FIRST, 2=두번째, 3=세번째, 4=FOURTH] 리스트로 가져온다.
System.out.println(hmap.size()); // 4
// 데이터 삭제
hmap.remove(4);
hmap.remove(40); // 존재하지 않는 키를 이용해서 삭제 => 동작하지 않음
System.out.println(hmap); // {1=FIRST, 2=두번째, 3=세번째}
hmap.remove(2, "두번째");
hmap.remove(1, "첫번째"); // 존재하지 않는 키, 값 쌍 => 동작하지 않음
System.out.println(hmap); // {1=FIRST, 3=세번째}
hmap.clear();
System.out.println(hmap); // {}
}
}Hashtable<K, V>
=> 동기화 메서드로 구현되어 있으므로 멀티 쓰레드에서도 안전하게 동작
LinkedHashMap<K, V>
=> 입력 순서대로 순서가 기억된다.
TreeMap<K, V>
=> 데이터를 Key 순으로 정렬해서 저장
=> Key 객체는 크기를 비교하는 기준을 가지고 있어야 함
Stack<E> 컬렉션 클래스
=> 후입선출(LIFO) 자료구조를 구현한 컬렉션
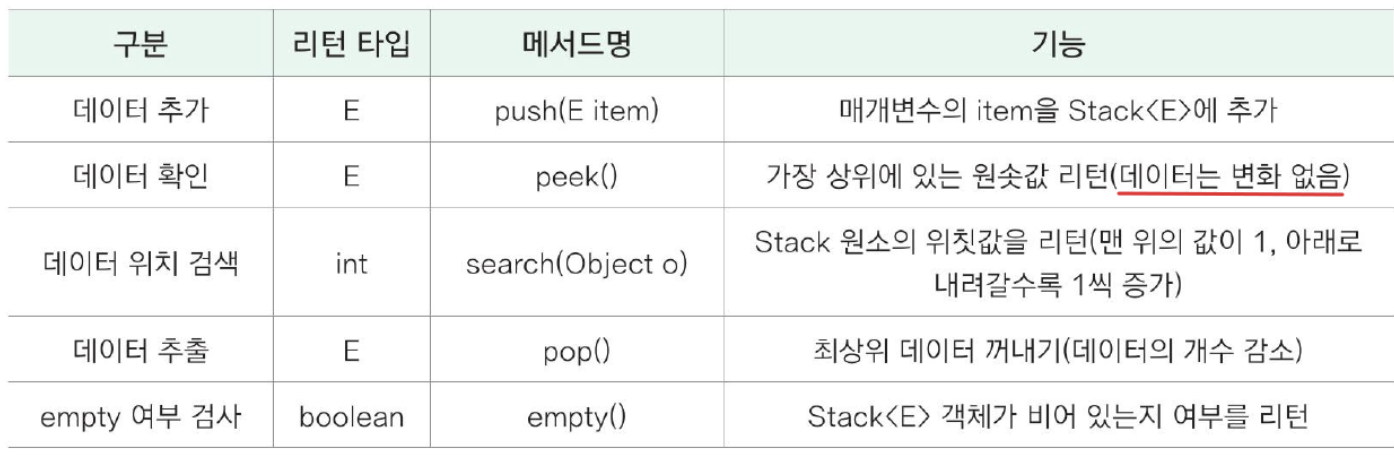
Queue<E> 컬렉션 클래스
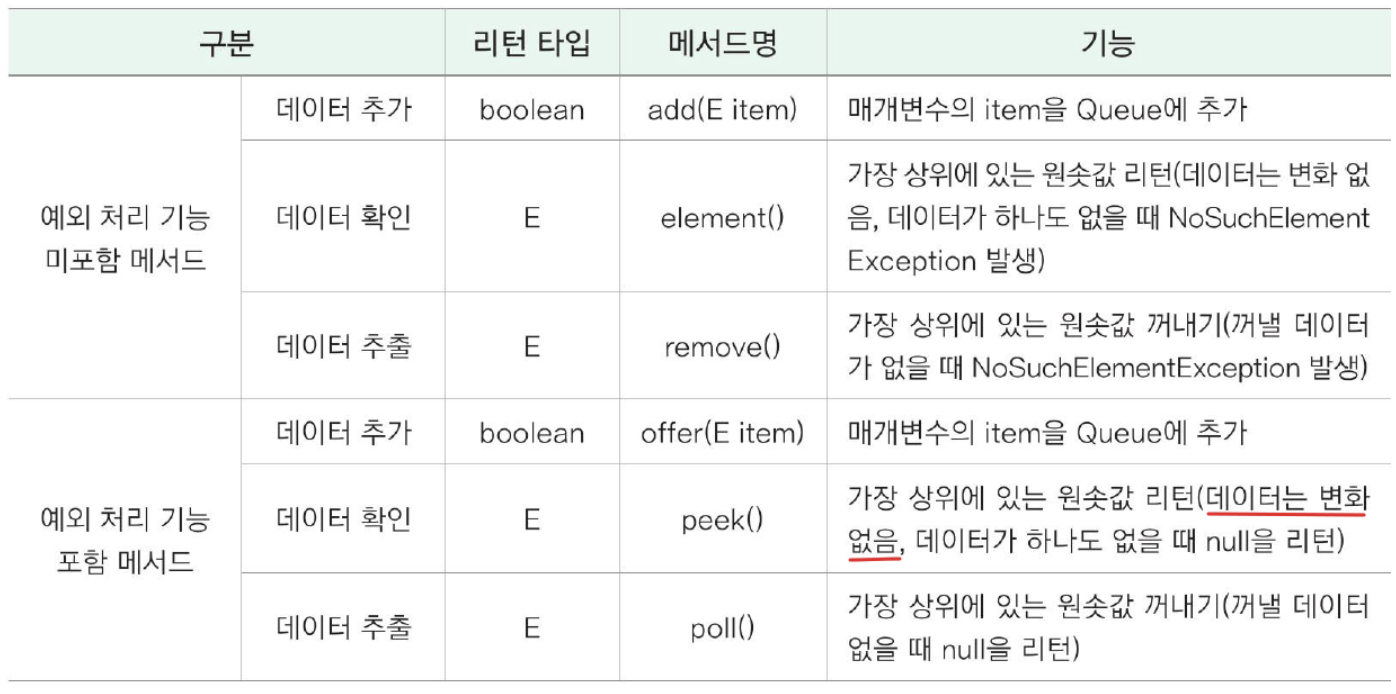
=> 선입선출(FIFO) 동작을 정의
함수형 프로그램
프로그램을 함수들의 조합으로 만드는 방식
~~~
동일한 입력값을 넣으면 동일한 결과를 반환 → 순수 함수(pure function)
데이터나 상태를 변경하지 않고 새로운 값을 반환 -> 비상태, 불변성(stateless, immutability)
선언형 프로그래밍 ⇒ 무엇(what)을 해야 하는지에 집중하며, 어떻게(how) 할지를 명시하지 않음 특징
순수 함수
let num = 1;
function add(a) {
return a + num;
}
//num가 1일 때 add(10);의 결과와 num가 2일 때 add(10);의 결과가 상이하다
// side effect - 이유: 함수 이외에 함수 실행에 관여하는 무언가가 있기 때문이다.
add(10);순수 함수라고 보기 어렵다 🥵
function add(a, b) {
return a + b;
}
add(10, 20); // 함수의 실행결과는 항상 동일입력값에 의해서만 함수의 실행결과에 반영되는 것 - 순수함수 ! 😇
비상태, 불변성(stateless, immutability)
let person = { name: "jane", age: 23 };
function increaseAge(person) {
person.age = person.age + 1;
return person;
}이렇게 하면 함수 밖의 값이 바뀌는 것이라 불변성을 만족시키지 않는다.
const person = { name: "jane", age: 23 };
function increaseAge(person) {
return { ...person, age: person.age + 1 };
}
const newPerson = increaseAge(person);비구조화해서 person을 복사해서 변경된 부분을 반영해 새롭게 반환
=> 원본 데이터의 구조를 변경하지 않고 사본을 만들어서 작업을 진행하는 것
=> 불변성
선언형 프로그래밍
let numbers = [1, 2, 3];
function multiply(numbers, multiplier) {
for (let i = 0; i < numbers.length; i++) {
numbers[i] = numbers[i] * multiplier;
}
}
function multiply(numbers, multiplier) {
return numbers.map(n => n * multiplier);
}numbers와 함수가 아주 밀접하게 동작한다.
for if switch while 등 다 사라지고 화살표 함수를 사용하여 한 라인에 명확하게 표현하는 방식으로 바뀌게 된다.
😇 장점
- 함수가 뭘 하는지 명확해져서 코드의 재사용성이 좋다. (동일한 기능을 하는 함수를 가져와서 쓰면 되기 때문)
- 값과 함수가 분리되므로 side effect가 줄어드는 효과가 있다.
😭 단점
- 코드가 복잡해지고 가독성이 떨어질 수 있다.
- 보통 반복문이 재귀적으로 이루어져서 어렵다.
람다식
객체지향 언어인 자바에서 함수형 프로그래밍 기법을 지원하는 자바의 문법
간결하게 코드 블록을 작성할 수 있는 표현 방법으로, 주로 함수형 인터페이스와 함께 사용
자바는 새로운 함수 문법을 정의하는 대신, 이미 있는 인터페이스의 문법을 활용해서 람다식을 표현
함수형 프로그래밍 문법 ⬇️
void abc() { ... }
abc();객체 지향 프로그래밍 문법 ⬇️
class A {
void abc() { ... }
}
A a = new A();
a.abc();(매개변수) -> { 코드블록 } <- 이렇게 사용한다 !
함수형 인터페이스(functional interface)
하나의 추상 메서드만 가지는 인터페이스
@FunctionalInterface어노테이션으로 함수형 인터페이스임을 명시할 수 있음
-> 컴파일러가 두 개 이상의 메서드를 선언하고 있으면 오류를 반환- Runnale, Callable, Consumer<T>, Supplier<T>, Function<T, R> 등
interface A {
void method();
void otherMethod();
}
// error. 재정의하지 않는 추상 메서드 여러 개가 인터페이스 com. test. B에서 발견되었습니다
@FunctionalInterface
interface B {
void method();
void otherMethod();
}함수형 인터페이스에 정의된 메서드를 호출하는 방법
객체 지향 프로그래밍 문법
CASE1. 인터페이스의 구현 클래스를 생성한 후 해당 클래스의 생성자를 이용해서 객체를 생성하고 객체의 참조 변수를 이용해서 메서드를 호출
CASE2. 익명 이너 클래스를 사용해 객체를 생성하고, 이 객체를 이용해서 메서드를 호출
함수형 프로그래밍 문법
CASE3. 람다식을 활용 => 익명 이너 클래스의 메서드 정의 부분만 가져와 메서드를 정의하고 호출
package com.test;
import java.util.*;
@FunctionalInterface
interface A {
void method();
}
class B implements A {
@Override
public void method() {
System.out.println("CASE1");
}
}
public class MyTest {
public static void main(String[] args) {
// CASE1
A case1 = new B();
case1.method();
// CASE2
A case2 = new A() {
@Override
public void method() {
System.out.println("CASE2");
}
};
case2.method();
// CASE3
A case3 = () -> {
System.out.println("CASE3");
};
case3.method();
}
}A 인터페이스 안에 함수가 하나밖에 없기 때문에 () -> { } 이렇게 메서드 이름 없이 쓰는 것이 가능해지는 것이다!
그래서 @FunctionalInterface 어노테이션을 붙여서 추상메서드가 하나밖에 없도록 해줘야 한다.
A 인터페이스가 functionalInterface이기 때문에 람다식이 가능하다 !!!
매개변수가 리턴값이 없는 경우
void method() { System.out.println("hello"); }
=> () -> { System.out.println("hello"); }
함수 본문이 한 줄이라면 중괄호 생략 가능
() -> System.out.println("hello");
매개변수는 있고, 리턴값이 없는 경우
void method(int i) { System.out.println(i); }
=> (int i) -> { System.out.println(i); }
매개변수가 한 개, 본문이 한 줄이라면 괄호 생략 가능
i -> System.out.println(i);
매개변수는 없고 리턴값이 있는 경우
int method() { return 100; }
=> () -> { return 100; }
괄호 생략 가능
() -> 100;
매개변수와 반환값이 모두 있는 경우
int method(int a, int b) { return a + b; }
=> (int a, int b) -> { return a + b; }
괄호 생략 가능, 매개변수의 타입 생략 가능
(a, b) -> a + b;
매개변수 타입 생략이 가능하고, 매개변수가 1개일 때는 () 생략이 가능
A a1 = (int a) -> { ... };
A a2 = (a) -> { ... };
A a3 = a -> { ... };
A a2 = int a -> { ... }; // (X) <= 소괄호가 생략되면 매개변수 타입도 반드시 생략되어야 한다.
