유효범위
변수와 메소드 같은 것들을 사용할 수 있는 것은 이름이 있기 때문이다. 아래 코드에서 left는 변수의 이름이고, sum은 메소드의 이름이다.
int left;
public void sum(){}
프로그램이 커지면 여러 가지 이유로 이름이 충돌하게 된다. 이를 해결하기 위해서 고안된 것이 유효범위라는 개념이다. 흔히 스코프(Scope)라고도 부른다.
출현배경
package com.yuri.javatutorials.scope;
public class ScopeDemo {
static void a() {
int i = 0; // 영향을 미치지 않
}
public static void main(String[] args) {
for (int i = 0; i < 5; i++) {
a();
System.out.println(i);
}
}
}만약 메소드 a가 실행될 때 메소드 내부의 변수 i의 값이 반복문의 변수 i의 값을 덮어쓰게 된다면 어떻게 될까? 반복문이 호출될 때마다 변수 i의 값이 0이 되기 때문에 이 반복문은 무한 반복에 빠지게 된다. 이런 상황을 해결하기 위해서는 메소드 a의 내부변수 i의 이름이나 반복문의 변수 i의 이름을 다르게 로직을 고쳐야 할 것이다.
만약 로직이 매우 복잡하거나, 메소드 a가 타인이 만든 것을 사용하는 것이라면 이것은 쉽지 않은 일이 된다. 이러한 문제는 부품으로서의 가치를 저하시킨다. 부품이란 조작 방법만 알면 내부의 동작 원리를 모르고도 사용할 수 있어야 한다. 또한, 부품 내부의 상태로 인해서 그 부품을 사용하는 외부의 동작 방법에 영향을 준다면 이 또한 좋은 부품이라고 할 수 없을 것이다.
실행결과를 보면 알겠지만, 내부 변수의 값이 그 외부에 영향을 미치지 않는다는 것을 알 수 있다. 이런 문제를 해결하기 위해서 다양한 시도들이 있었는데 그 노력의 결과 중의 하나가 유효범위라고 할 수 있다.
메소드, 클래스와 같은 개념들이 등장한 배경은 프로그램을 만드는 데 사용하는 코드의 양이 기하급수적으로 증가하면서 직면하게 되는 막장을 극복하기 위한 것이었다. 거대해진 코드를 효율적으로 제어하지 못한다면 웅장한 소프트웨어를 만드는 것은 점점 불가능한 일이 될 것이다. 유효범위라는 것도 그러한 맥락에서 등장한 개념이다. 하지만 유효범위는 메소드나 클래스처럼 특별한 문법적인 규칙을 가지고 있는 것은 아니다. 오히려 메소드나 클래스 안에 포함되어서 이러한 기능들의 부품으로서의 가치를 높여주는 역할을 한다고 할 수 있다.
다양한 유효범위들
디렉터리를 생각하면 쉬울 것 같다. 처음에는 파일이 있었다. 그런데 파일이 많아지면서 파일의 이름이 충돌하기 시작한다. 파일의 사용자들은 궁여지책으로 파일의 이름에 날짜나 부서 혹은 이름을 적어서 충돌을 피했을 것이다. 이러한 문제로 인한 절망이 충분히 성숙했을 때 운영체제의 개발자들은 이를 해결하기 위한 방법에 대해서 고민을 하게 되었을 것이다. 그래서 고안된 것이 디렉터리라고 할 수 있다. 디렉터리는 파일을 그룹핑해서 그룹별로 파일을 격리한다. 디렉터리 내에서는 파일명이 중복되면 안 되지만 디렉터리 밖의 파일명과는 중복이 돼도 문제 없다. 덕분에 마음 놓고 다른 사람이 만든 파일이 담긴 디렉터리를 자신의 디렉터리로 가져올 수 있게 되었다.
(오랜만에 맥 쓰니까 약간 낯설다..)
계속 i의 값은 0 이 된다.
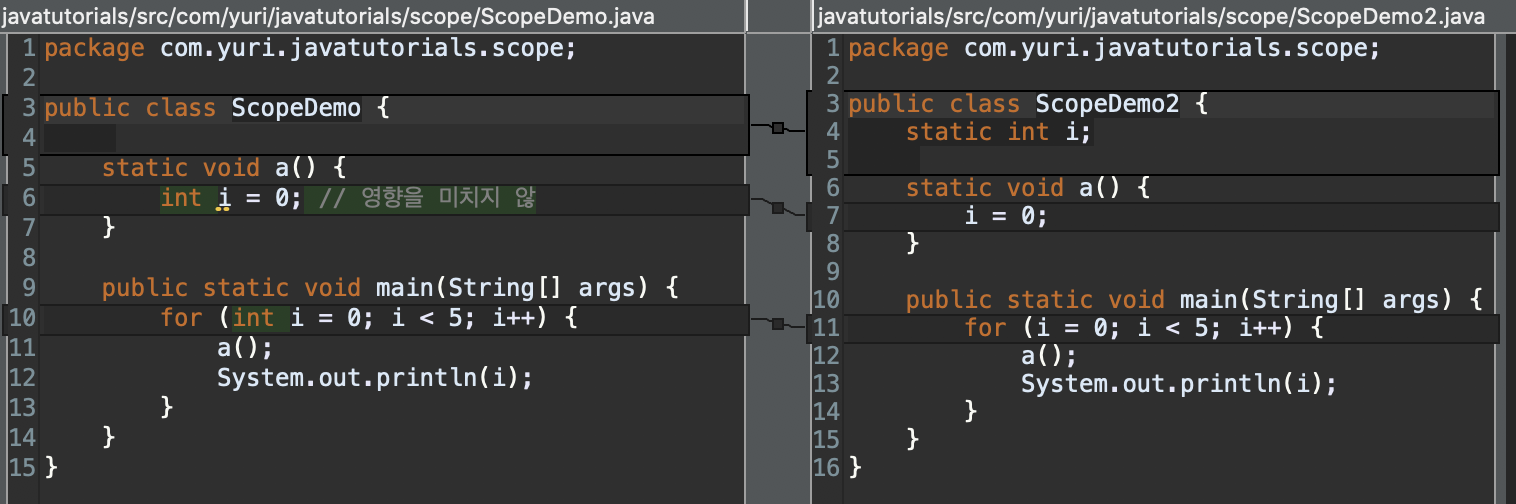
package com.yuri.javatutorials.scope;
public class ScopeDemo3 {
static int i;
static void a() {
int i = 0;
}
public static void main(String[] args) {
for (i = 0; i < 5; i++) {
a();
System.out.println(i);
}
}
}이와 같이 int 를 붙여주면 결과값이 0,1,2,3,4 정상으로 출력된다.
static void a() { int i = 0; }
i라는 변수를 생성하고 그 생성된 변수의 값을 셋팅하고 있다. 이 생성을 a() 메소드 안에서 하고 있다. i라는 변수는 메소드 a 안에서만 유효한 변수라는 뜻이다. 그래서 이 메소드가 실행이 끝나면 i를 사용하기 위해 들어있던 메모리 정보는 삭제가 된다. 그렇기 때문에 똑같은 i라는 이름이지만 i 값을 0으로 세팅한 것은 바깥에 있는 전역변수 i와는 전혀 무관한 값이 된다.
즉 자바에서 어떤 변수를 선언한다는 것은 단순히 변수를 만든다는 의미를 넘어서서 그 변수의 유효범위를 정하는 행위이다. 그래서 그 변수를 클래스 바로 밑에 선언하게 되면, 그렇게 선언한 그 변수는 이 클래스 안에 있는 모든 메소드와 모든 for 문, 모든 중괄호 안에서 접근할 수 있는 전역변수가 되는 것이다.
우선 메소드만 놓고 봤을 때 메소드 안에서 선언한 변수는 그 메소드가 실행될 때 만들어지고, 그 메소드가 종료되면 삭제된다. 만약 클래스 아래의 변수와 메소드 아래의 변수가 같은 이름을 가지고 있다면 메소드 아래의 변수가 우선하게 된다. 메소드 내의 변수가 존재하지 않을 때 클래스 아래의 변수를 사용하게 되는 것이다.
즉 클래스 아래에서 선언된 변수는 클래스 전역에 영향을 미치지만 메소드 내에서 선언된 변수는 클래스 아래에서 선언된 변수보다 우선순위가 높다고 할 수 있다. 지역적인 것이 전역적인 것보다 우선순위가 높다는 원칙은 특수한 것이 전체적인 것보다 우선순위가 높다는 의미로도 해석할 수 있는데 이러한 원리는 공학 전반에서 적용되는 원칙이기 때문에 교양으로서도 유익하다. 전역적으로 기본값을 설정하고, 필요에 따라서 지역 값을 다르게 사용하는 것이 더 효율적이기 때문에 이러한 원칙이 사용된다. 클래스 전역에서 접근 할 수 있는 변수를 전역변수, 메소드 내에서만 접근 할 수 있는 변수를 지역변수라고 한다.
또다른 예 (1)
package com.yuri.javatutorials.scope;
public class ScopeDemo4 {
static void a(){
String title = "coding everybody";
}
public static void main(String[] args) {
a();
//System.out.println(title);
}
}이미 오류가 났다는 것을 tools은 알고 있다. title 이 어디에서도 선언되지 않았거든..a()라는 메소드 안에 들어있기 때문에
또다른 예 (2)
package com.yuri.javatutorials.scope;
public class ScopeDemo5 {
public static void main(String[] args) {
for (int i = 0; i < 5; i++) {
System.out.println(i);
}
// System.out.println(i);
}
}i의 값은 for문으로 인해서 선언되었고 이것은 중괄호 사이에서만 유효하기 때문에 중괄호 바깥쪽에 있는 System.out.println(i); 은 오류가 발생하는 것이다.
또다른 예 (3)
ials.scope;
public class ScopeDemo6 {
static int i = 5; //전역변수
static void a() {
int i = 10;
b();
}
static void b() {
System.out.println(i);//전역변수를 사용했다는 의미
}
public static void main(String[] args) {
a();
}
}다음 코드의 결과값은 5이다. 그렇다면 여기서 코드 한줄을 추가해보자!
package com.yuri.javatutorials.scope;
public class ScopeDemo6 {
static int i = 5; //전역변수
static void a() {
int i = 10;
b();
}
static void b() {
int i = 30;
System.out.println(i);//전역변수를 사용했다는 의미
}
public static void main(String[] args) {
a();
}
}int i = 30; 를 추가할 경우 결과는 30이 된다. 위의 예제는 메소드 a가 메소드 b를 호출하고 있는데 메소드 b에는 변수 i의 값이 존재하지 않는다. 이 상태에서 메소드 a를 호출하면 메소드 b에서 System.out.println(i)를 했을 때 클래스 변수가 사용될까? 메소드 b를 호출한 메소드 a의 지역 변수 i가 사용될까? 클래스 변수를 사용한다. 메소드 내(b)에서 지역변수가 존재하지 않는다면 그 메소드가 소속된 클래스의 전역변수를 사용하게 된다.
이러한 방식을 정적 스코프(static scope) 혹은 렉시컬 스코프(lexical scope)라고도 부른다. 즉 사용되는 시점에서의 유효범위(메소드 a의 i)를 사용하는 것이 아니라 정의된 시점에서의 유효범위(i = 5)를 사용하는 것이다.
동적 스코프라는 것도 있다. 만약 메소드 b의 결과가 10이라면 메소드 b는 메소드 a의 유효범위에 소속된 것이라고 할 수 있다. 하지만 자바는 동적 스코프를 채택하지 않고 있다. 대부분의 현대적인 언어들이 정적 스코프 방식을 선택하고 있다.
인스턴스의 유효범위
지금까지는 클래스 중심으로 유효범위를 알아봤다. 인스턴스에서의 유효범위도 클래스와 거의 동일하지만 결정적인 차이점은 this에 있다고 할 수 있다
package com.yuri.javatutorials.scope;
class C3 {
int v = 10; // 전역변수
void m() {
int v = 20; // 지역변수
System.out.println(v);
System.out.println(this.v);
// this:인스턴스 자체를 의미 , this 가 붙게 되면 그 객체에 대한 전역의 의미를 갖는다.
}
}
public class ScopeDemo9 {
public static void main(String[] args) {
C3 c1 = new C3();
c1.m();
}
}교훈
유효범위란 변수를 전역변수, 지역변수 나눠서 좀 더 관리하기 편리하도록 한 것이다. 객체라는 개념이 존재하지 않는 절차지향 프로그래밍에서는 모든 메소드에서 접근이 가능한 변수의 사용을 죄악시하는 경향이 있다. 전역적인 사용의 효용이 분명한 데이터에 한해서 제한적으로 전역변수를 사용하도록 하고 있는 것이다. 객체지향 프로그래밍은 바로 이런 문제를 극복하기 위한 노력이라도고 볼 수 있다. 즉 연관된 변수와 메소드를 그룹핑 할 수 있도록 함으로서 좀 더 마음놓고 객체 안에서 전역변수를 사용할 수 있도록 한 것이다. 전역변수는 더 이상 죄악시할 대상이 아닌 것이 된다. 이렇듯 도구와 사람의 마음은 밀접한 연관이 있다.
부품의 관점에서도 생각해볼 수 있다. 어떤 메소드가 전역변수를 사용하고 있다는 것은 그 메소드는 그 전역변수에 의존한다는 의미다. 전역변수에 의존한다는 것은 이 메소드가 다른 완제품의 부품으로서 사용될 수 없다는 의미다. 객체지향 덕분에 좀 더 안심하고 전역변수를 사용하게 되었지만, 객체도 크기가 커지면 관리의 이슈가 생겨난다. 객체지향 프로그래밍에서도 가급적이면 전역변수의 사용을 자제하는 것이 좋고, 동시에 단일 객체가 너무 비대해지지 않도록 적절하게 규모를 쪼개는 것도 중요하다.
이 글은 생활코딩의 자바 강좌를 바탕으로 정리한 내용입니다.
