
BERT를 학습시키기에는 필요한 데이터와 시간이 오래 걸린다. 그래서 처음부터 학습할 필요가 없는 사전 학습된 BERT를 파인 튜닝으로 시간과 비용을 줄일 수 있다. 하지만 사전 학습된 BERT를 사용하는데도 비용이 많이 들고 제한된 리소스로 모델을 실행하기에는 어려움이 있다. 이러한 문제점을 완화하기 위해서 지식 증류(knowledge distillation)라는 기법을 이용해 대형 BERT에서 소형 BERT로 지식을 전달한다.
지식 증류는 사전 학습된 대형 모델의 동작을 소형 모델에 학습시키는 압축 기술이다. 이러한 학습을 teacher-student 학습이라고도 한다. 쉽게 말해 대형 모델이 교사이고 소형 모델이 학생이 된다.
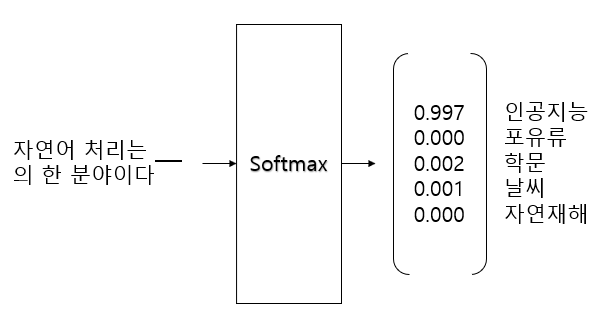
위 그림처럼 입력 문장의 마스킹 부분을 신경망을 통해 softmax로 예측하는 모델이 있는 경우, 가장 확률이 높은 단어 "인공지능"을 제외한 단어는 암흑 지식(dark knwoledge)이다. 지식 증류는 당연히 확률이 가장 높은 부분을 학습하지만 확률이 낮은 dark knowledge 도 학습시킨다.
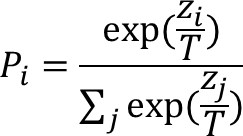
dark knowledg를 학습시키기 위해서는 temperature와 함께 softmax 함수를 사용하며 출력레이어에서 softmax temperature라고 붙여 부른다.
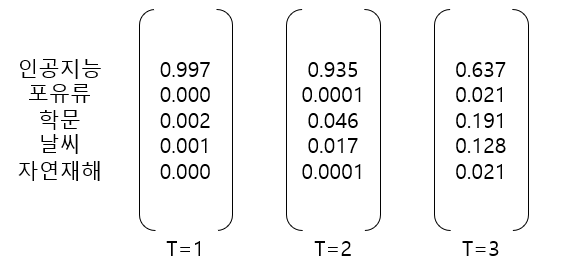
위 그림에서 T는 temperatur로써 T = 1일 경우 일반적인 softmax 함수이며 T 값을 늘리면 확률 분포가 부드러워지고 다른 클래스에 대한 더 많은 정보가 제공된다.
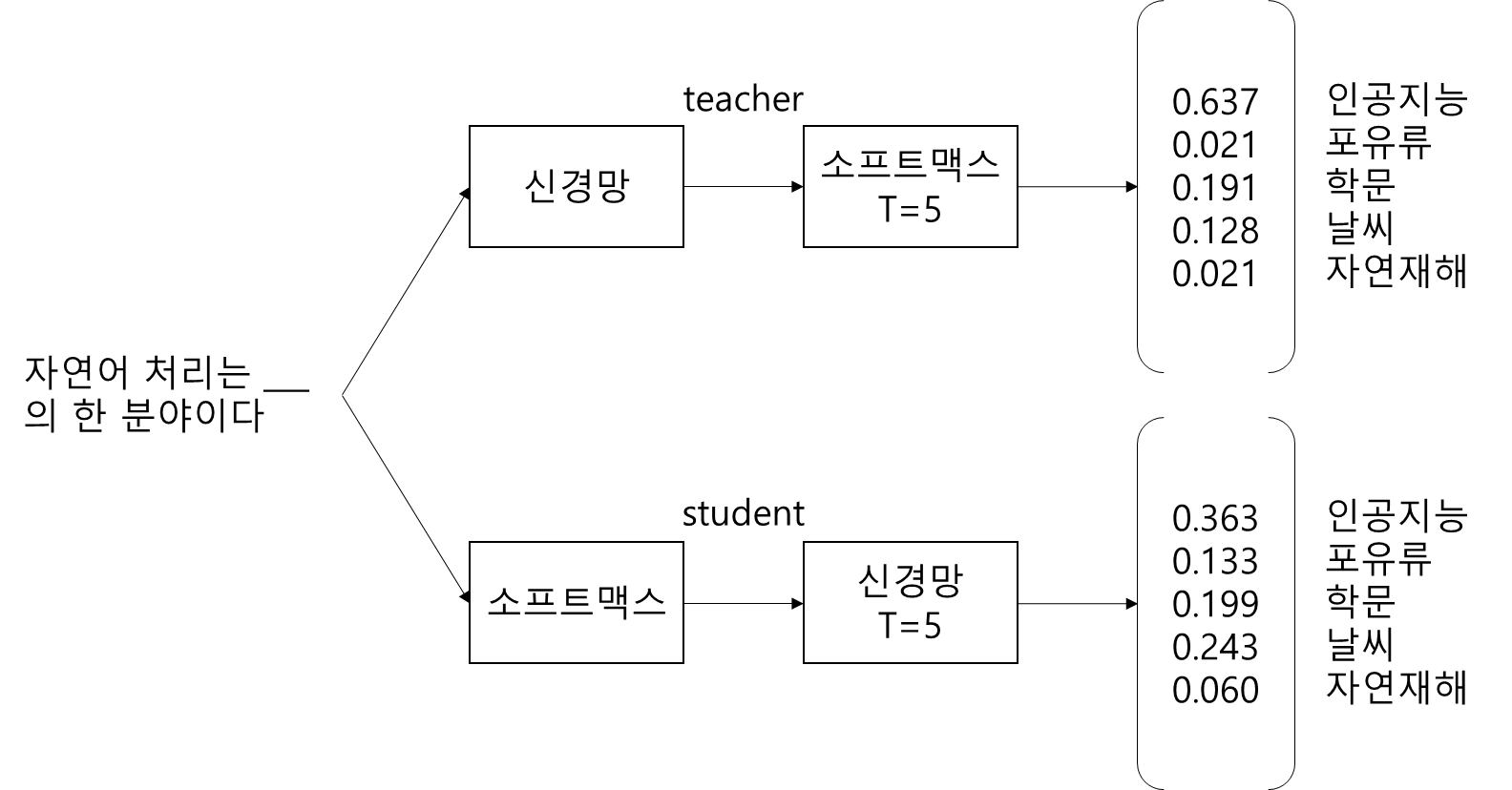
입력문장을 바탕으로 teacher 네트워크가 반환하는 확률이 타깃이되며, student 네트워크가 반환하는 확률은 예측이 된다. 이러한 각각의 네트워크 출력은 소프트 타깃(soft target), 소프트 예측(soft prediction)이 된다. 소프트 타깃과 소프트 예측 사이의 Cross-entropy loss 가 증류 손실(Distillation loss)이 된다.
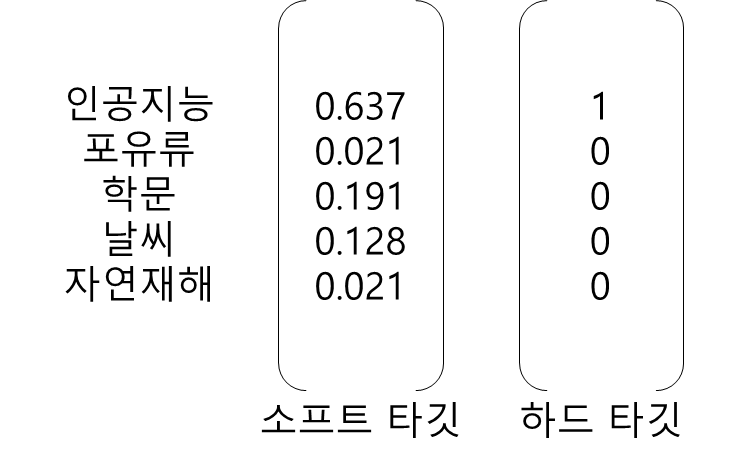
Student 네트워크에서는 증류 손실과 별도로 학생 손실을 하나 더 사용한다. 학생 손실은 T를 1(일반적인 softmax)로 하여 하드 타킷을 예측, 증류 손실은 T를 2 이상으로 측정한다.
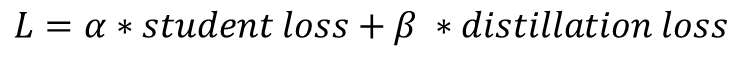
최종 손실 함수는 학생 손실과 증류 손실의 가중 합계이며, a 와 b는 가중 평균을 계산하는 데 사용되는 하이퍼파라미터이다.
