5.1 Introduction
Web Scrapping: 다른 사이트에서 정보를 추출해오는 것예시: 페이스북에 기사 주소 복사 시 기사의 썸네일 이미지와 첫 줄을 보여줌
폰 사고 싶을 때 파이썬으로 몇 개의 사이트에서 정보를 가져와 어떤 폰의 가격이 올라갔는지 내려갔는지, 새로운 폰은 뭐가 올라왔는지 볼 수 있음.
구글에서 특정 키워드, 인물 정보를 검색했을 때 최상단에 사이트 내용의 일부를 보여주거나 위키피디아의 정보, 출연 영화 등을 보여주는 것.
2020년 코스에서는 Indeed를 스크래핑하였으나, 이제 weworkremotely라는 사이트를 스크래핑 할 것이다.기초 HTML에 대한 이해는 당연히 필수다
5.2 Installation
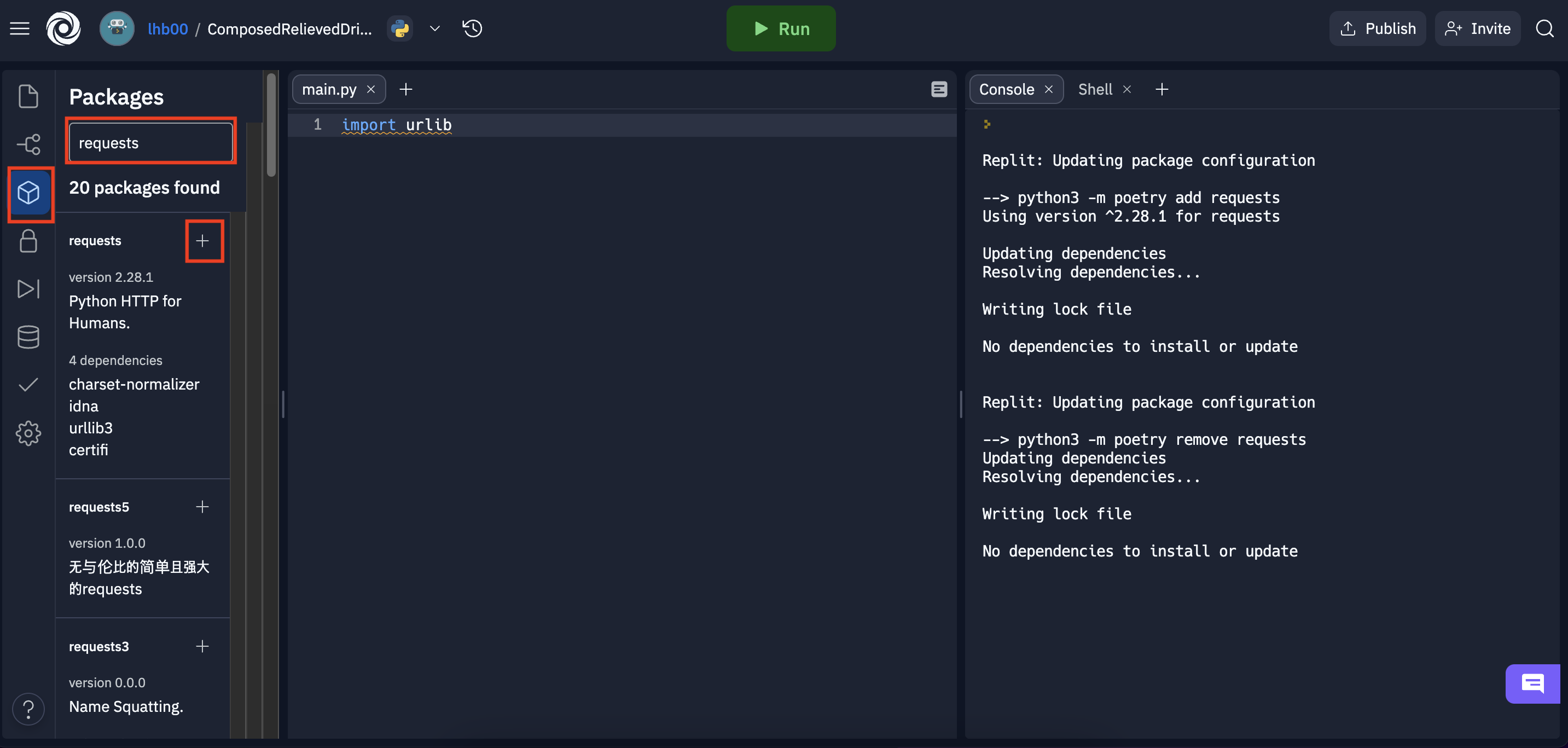
repl.it이라는 사이트에서 코드를 실행하는데, 여기서는 requests 패키지 설치법이 일반 파이썬과는 좀 다르다. Packages->requests 패키지 검색-> + 버튼을 눌러 추가.
5.3 Initial Request
사이트는 계속 발전하기 때문에, 사이트가 언제 바뀔지 모른다는 점을 유의하자.
다만, 어차피 내가 이 챌린지를 이번에 바로 통과한다면 영상과 차이는 없는듯 하다 ㅎㅎ
사이트 주소의 구조가 https://weworkremotely.com/remote-jobs/search?term=<검색어>라는 점을 인지하자.
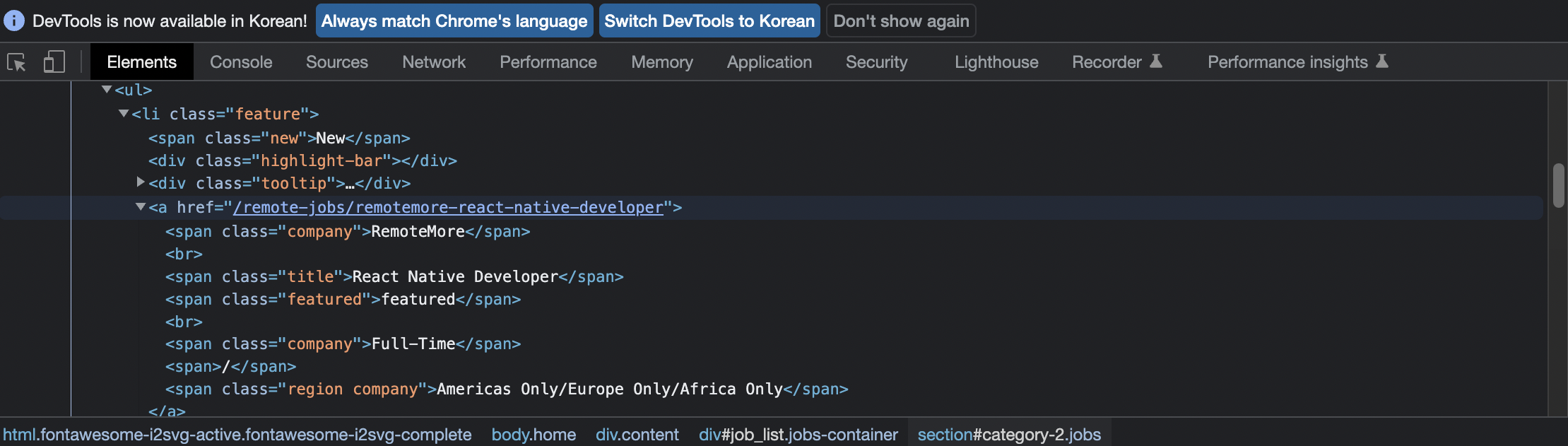
이렇게, 사이트에서 div class:jobs-container->section class:jobs->article->ul 순으로 가보면, anchor가 하나 나올 것이고 이 anchor안의 정보들이 우리가 추출해내고 싶은 정보들이다.
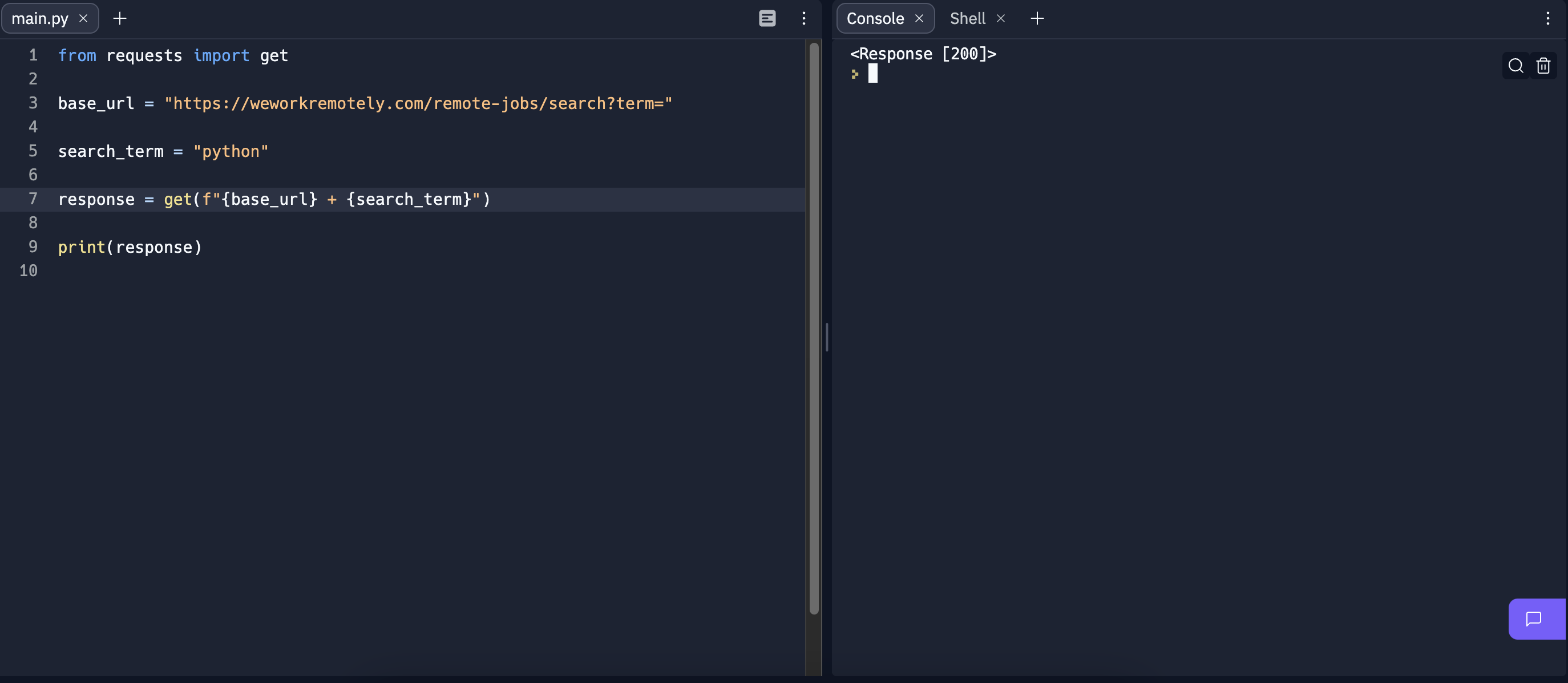
코드 작성시 f를 빼먹으면 안된다. 자바스크립트의 백틱 기호와 역할이 같다고 보면 된다.
코드를 작성하고 실행해보면, 정상적으로 <Response[200]>이 뜬다. 아주 잘 되고 있다는 뜻인데, 우리가 원하는 것은 이 자체가 아니다.
우리는 웹사이트를 원하므로, response.text를 출력해보면,
너무 길어... 🤮
5.4 BeautifulSoup
그래서, 이 데이터를 추출해주는 BeautifulSoup를 이용해서 이 너무 긴 결과들을 활용해 볼 것이다.
find_all(): 우리가 가진 document에서 html 태그를 찾을 수 있게 해준다.이를 이용하여 코드를 작성하고, 위에서 언급한 section class:jobs를 찾을 수 있는지 보자.
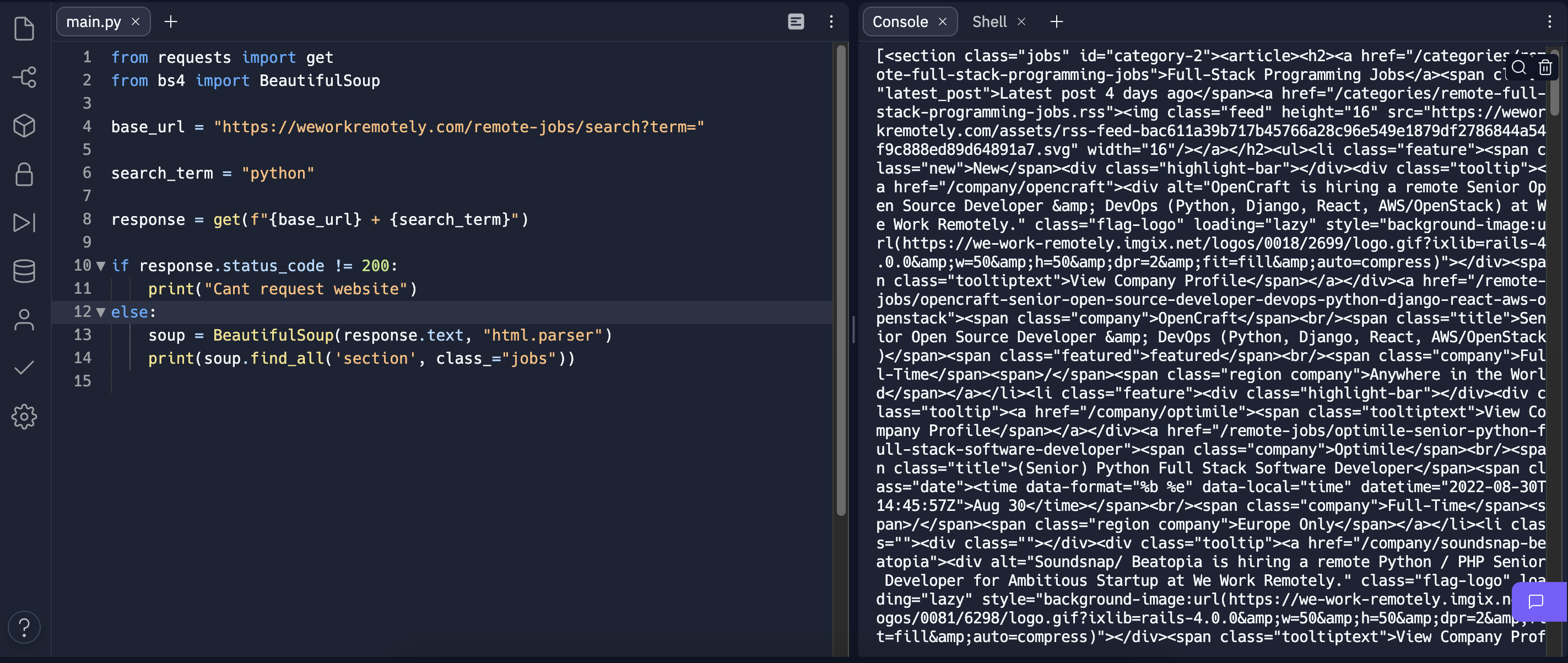
아주 잘 나온 것을 볼 수 있다 ㅎㅎ
여기서 'class='이 아니라 'class_='임에 주의하자! (class는 이미 파이썬에서 사용하고 있는 키워드이므로)
5.5 Keyword Argument
원래 함수는 positional, 즉, 각각의 인자가 어떤 위치에 올 지를 알고 있다.
def say_hello(name, age):
print(f"Hello {name} you are {age} year old")
라는 함수가 있다면, say_hello(이름, 나이)로 쓰는 것이 맞는데,
say_hello(age=나이, name=이름)로 쓴다면, 똑같이 작동을 함에도 위치를 신경쓸 필요가 없어진다.
이걸 왜 얘기하냐고? 위의 코드의 find_all() method가 argument를 겁나 많이 가지고 있기 때문이다.
5.6 Job Posts
위에서 얘기했듯, 우리는 ul안의 li들을 가져오고 싶다. 따라서,
for job_section in jobs: print(job_section.find_all('li'))
로 코드를 작성해보면,

이렇게 li들을 잘 가져온 것을 볼 수 있다.
그리고 이 결과는 array이므로,
for job_section in jobs: job_posts = job_section.find_all('li') for post in job_posts: print(post) print("//////////")
이렇게 코드를 작성해보면, (/들은 구분을 위해서 넣었다.)
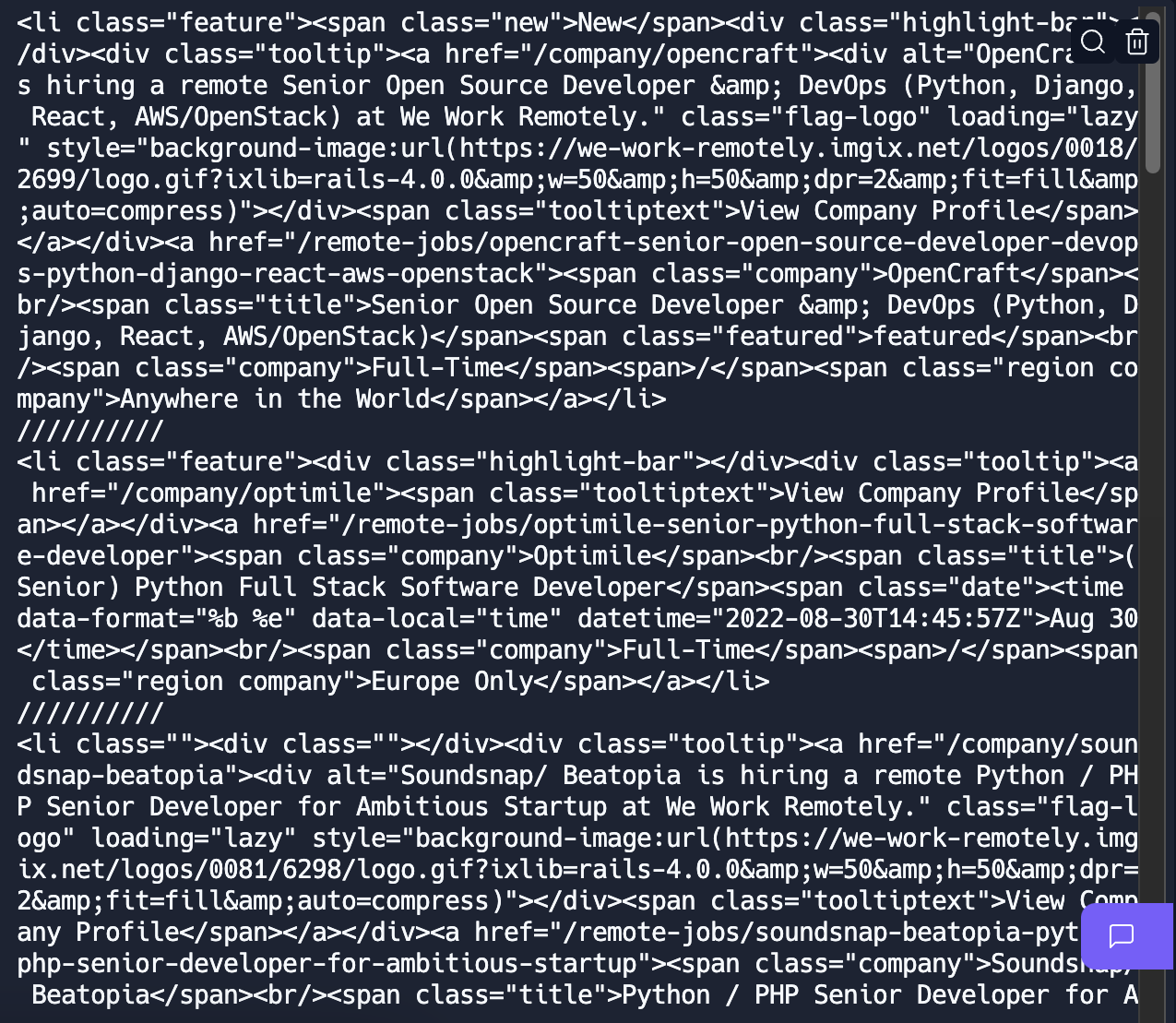
잘 나오는 것을 볼 수 있다. ㅎ
다만 문제는, view-all 버튼 까지 가져와버렸다는 것이다. 우린 이걸 제거할 것이다. view-all 버튼이 항상 마지막 페이지에 있고, BeautifulSoup가 모든 html text를 실제 python 데이터 구조로 바꿔주고 있으므로,
job_posts.pop(-1)로 view-all을 제거해주면 된다.
5.7 Job Extraction
우리는 이제 a href를 가져올 것이다. 또한 회사 이름, 그리고 full-time인지 part-time인지의 여부, 회사의 지역도 가져올 것이다.
BeautifulSoup로 html 내부를 검색만 할 수 있는 것은 아니다.
모든 html 태그를 BeautifulSoup Entity로 만드는 기능도 있다. 우리가 section class:jobs을 받을 때 사실 string으로 받을 수도 있었지만, 그러지 않았다. array로 받았다.
즉, 우리는 각 li의 내부로 갈 수 있다. 여기서 주의할 점은, anchor를 받게 되면, 필요 없는 anchor도 받게 되는데, 이를 잘 구분할 필요가 있다.
for post in job_posts: anchors = post.find_all('a') anchor = anchors[1]
이렇게 작성해주면 된다.(2번째 anchor만 필요하므로)
BeautifulSoup가 아주 훌륭한 점은, href들을 모두 파이썬 딕셔너리로 바꿔준다는 것이다.
print(anchor['href'])그래서 이렇게 적어주면,
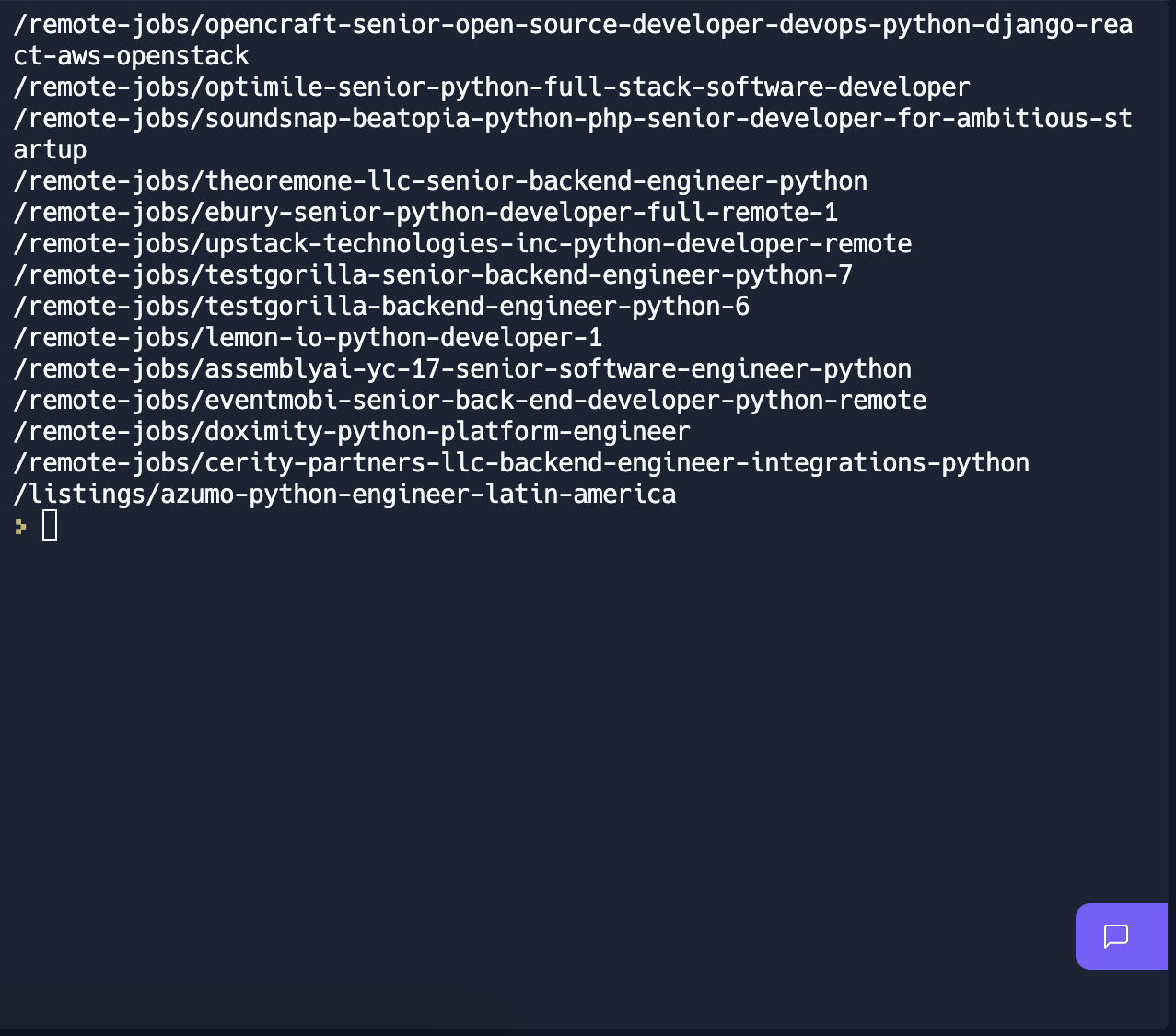
href를 얻었다. 이제 이걸 엑셀 파일에 저장해줘야 하므로 link라는 변수에 저장해주자.
그런데 문제가 있다. 맨 위쪽의 사진을 보면 알겠지만, 여기저기 company를 남발하고 있다. par-time, full-time 여부에도 company, 지역에도 company를 쓰고 있다. 그래서, 파이썬 문법을 하나 사용해서 해결해 볼 것이다.
company, kind, region = anchor.find_all('span', class_="company")리스트의 길이를 알고 있는 경우, 변수를 이렇게 선언하는 것이 가능하다.
그리고 프린트를 해보면,
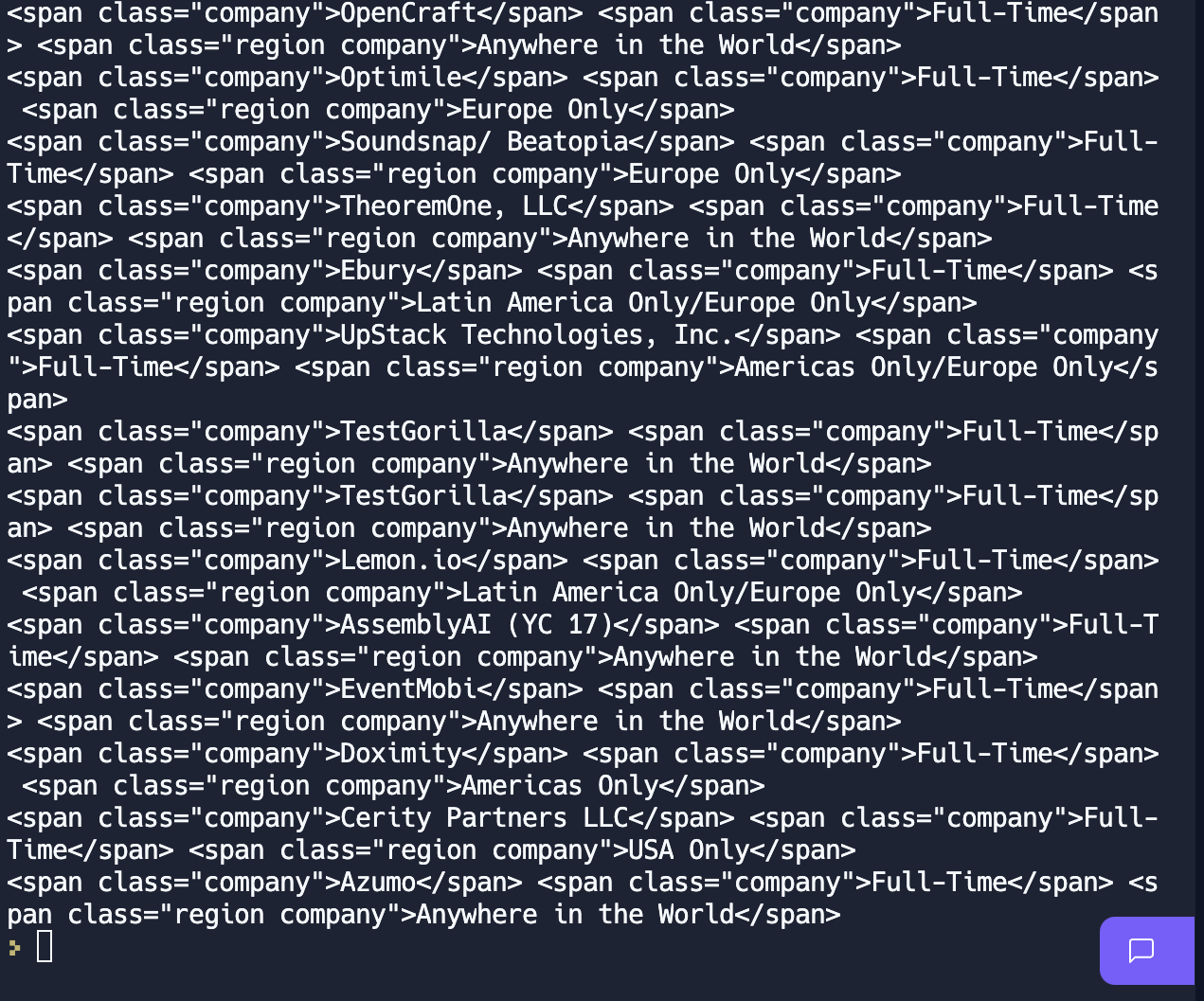
아주 잘 나왔다.
그리고 나서, 마지막으로 title을 가져올건데, find_all()을 쓰면 리스트를 반환하므로, find()를 써서,
title = anchor.find('span', class_='title')를 한 뒤, 구분자를 넣어서 프린트 해주면,
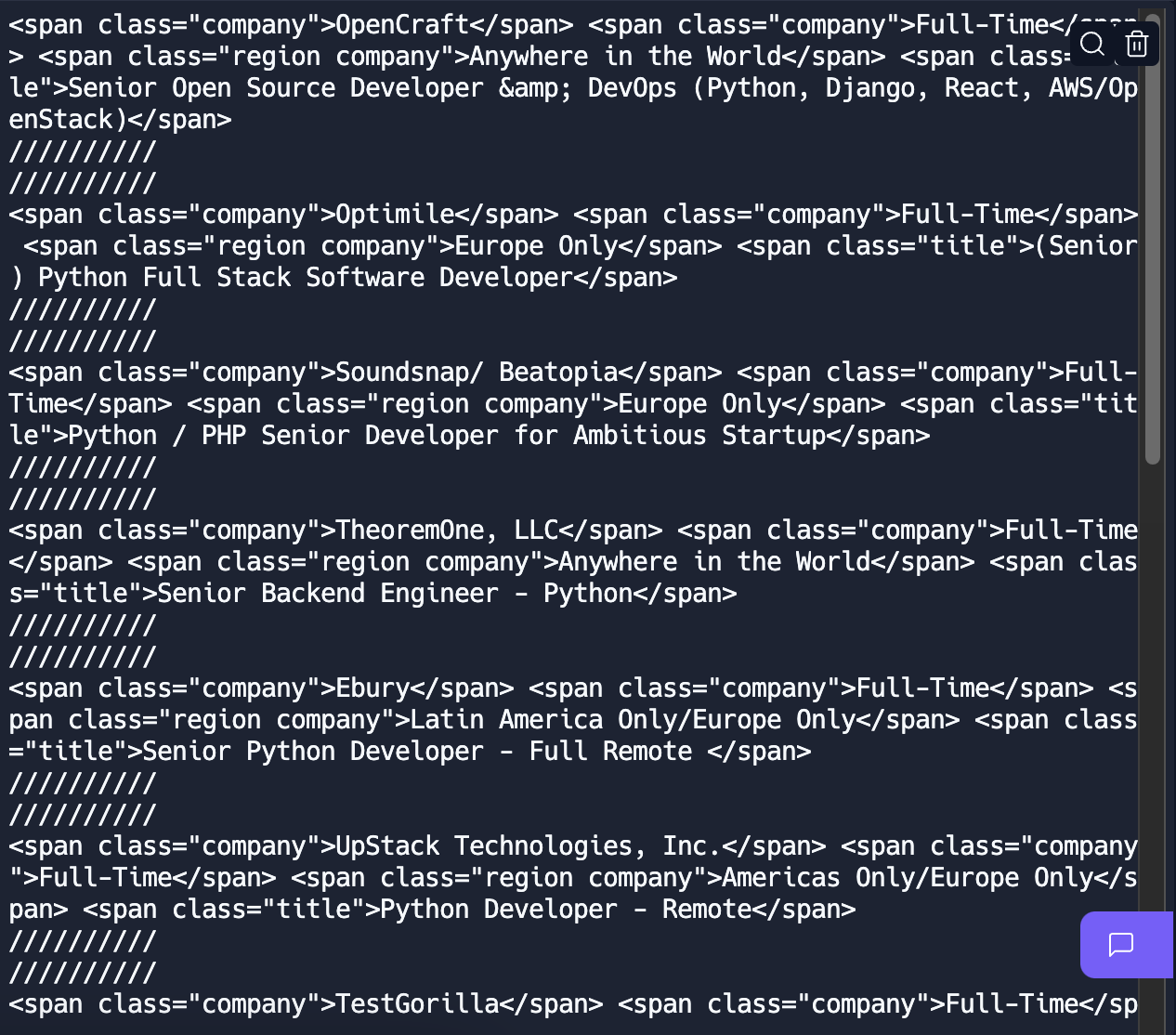
끝!
5.8 Saving Results
이제 span에서 텍스트만 추출해낼 것이다.
그래서, .string method를 사용하여,
print(company.string, kind.string, region.string, title.string)로 작성해주면,
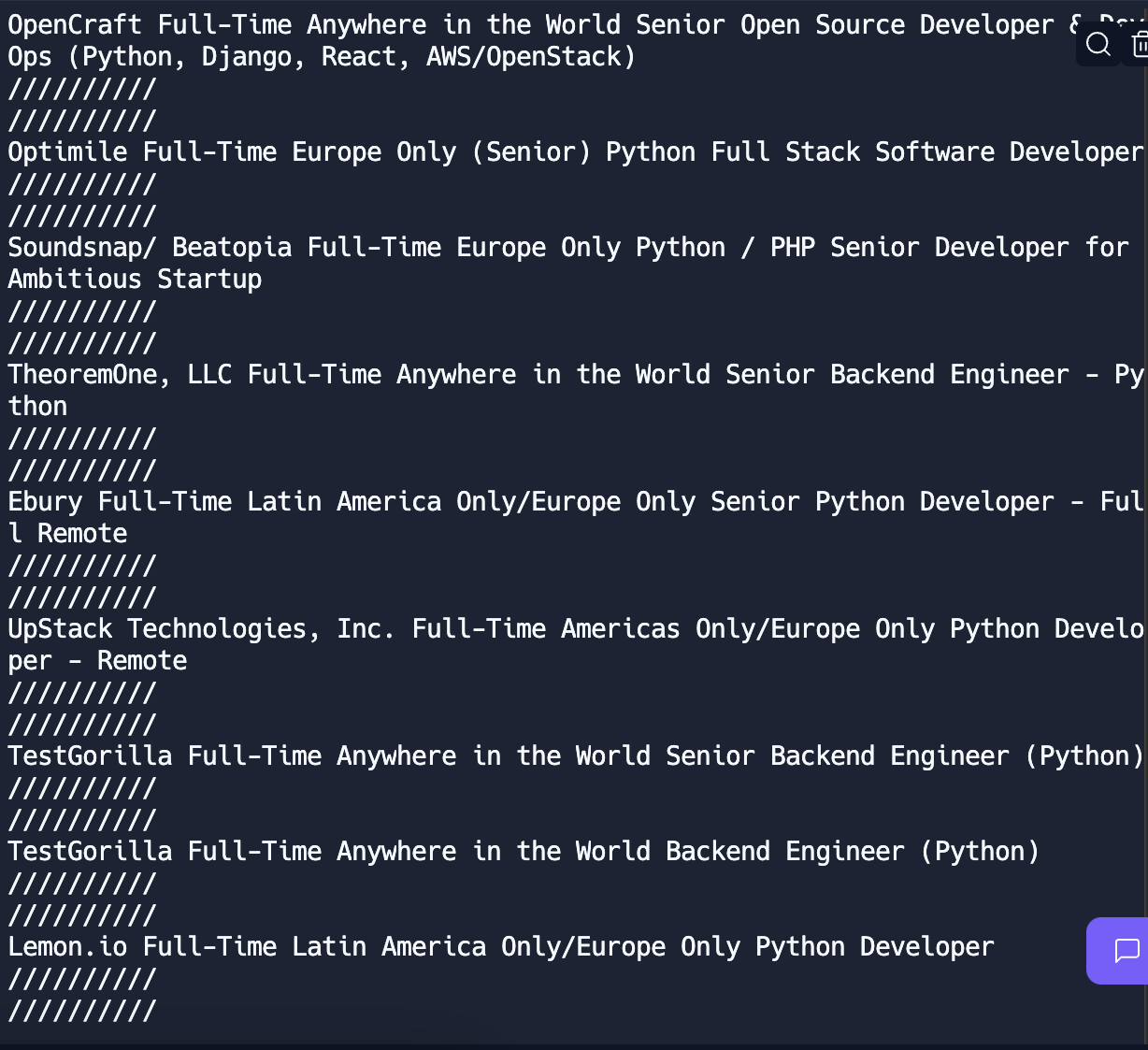
👍
그리고 우리는 이 정보를 dictionary에 넣어줄 것이다.
job_data = { 'company': company.string, 'region': region.string, 'position': title.string }
(part-time, full-time 여부는 삭제했다.)
그런데 문제는, 이 것이 for문 안에서 이루어지고 있으므로, dictionary가 계속 재생성 될 것이라는 것이다. 그래서 for문 밖에서 만들어야한다.
따라서, for문 밖에 빈 리스트를 하나 생성해주고, job_data의 내용을 이 리스트에 계속해서 추가해주도록,
result.append(job_data)를 for문 안에 넣어줄 것이다.
그리고 for문을 활용, 구분자를 넣어서 출력해주면!
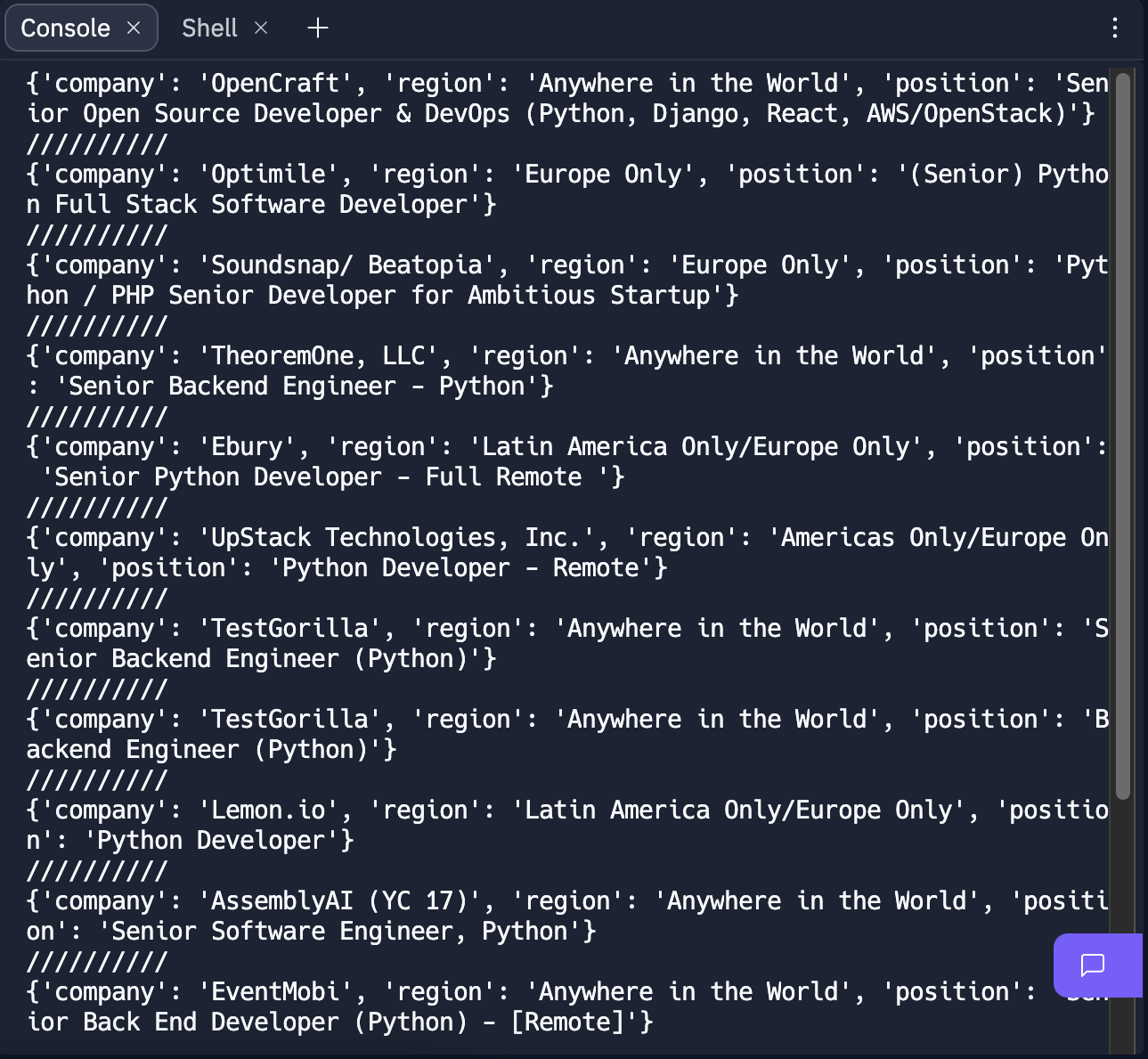
깔-끔
마찬가지로, React, Java로도 잘 되더라.(Javascript도 포함되긴 했지만)
NextJS랑 NestJS는 일자리가 없더라...흠
5.9 Recap
말 그대로 복습.
다만, 추가할 점은,
link = anchor['href']가 weworkremotely상의 상대경로이므로, 경로 추가 시
f"https://weworkremotely.com/{link}"이렇게 적어줘야한다는 점이다.
다음 글은 뭐가 될지 잘 모르겠다... 아마 5.10~5.21 강의 내용 정리일듯하다?
