DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models(v1)
느낌전
- 엄청 고민 많이 하고 이렇게 많은 양을 어떻게 고민했는지
- 긴글, 짧은 글, 강화학습 관련하여 이해도가 매우 높은 거 같음
Abstract
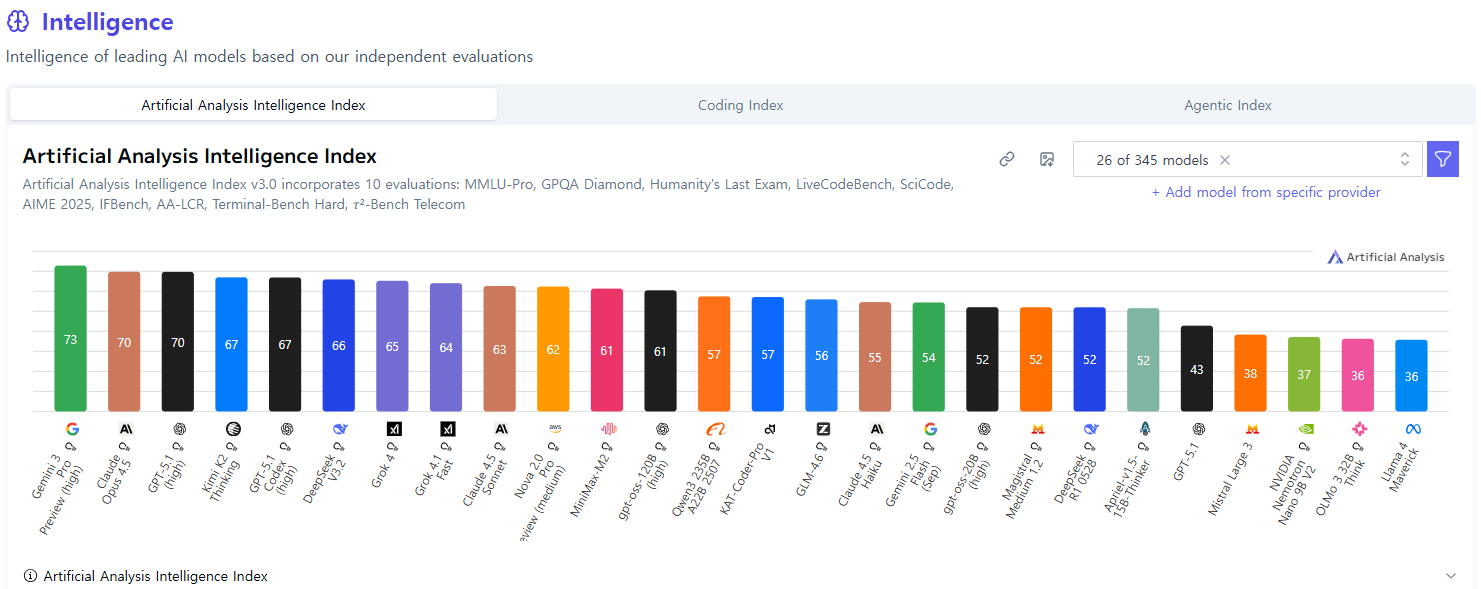
높은 연산 효율성과 우수한 추론 및 에이전트 성능을 조화시킨 모델인 DeepSeek-V3.2를 소개합니다. DeepSeek-V3.2의 핵심 기술 혁신은 다음과 같습니다
DeepSeek Sparse Attention (DSA): DSA라는 효율적인 어텐션 메커니즘을 도입했습니다. 긴 문맥 시나리오에서 모델 성능을 유지하면서도 연산 복잡도를 상당히 감소시킵니다.
확장 가능한 강화 학습 프레임워크: 견고한 강화 학습 프로토콜을 구현하고 post-training compute을 확장함으로써 DeepSeek-V3.2는 GPT-5와 비슷한 성능을 보입니다. 고연산 변형 모델인 DeepSeek-V3.2-Speciale는 GPT-5를 능가하며 Gemini-3.0-Pro와 동등한 추론 능력을 보여주어 2025년 국제 수학 올림피아드(IMO)와 국제 정보 올림피아드(IOI) 모두에서 금메달급 성능을 달성했습니다.
대규모 에이전트 작업 합성 파이프라인: 도구 사용 시나리오에 추론 능력을 통합하기 위해 체계적으로 대규모 훈련 데이터를 생성하는 새로운 합성 파이프라인을 개발했습니다. 이 방법론은 확장 가능한 에이전트 후속 훈련을 용이하게 하여 복잡하고 상호작용적인 환경 내에서 일반화 능력과 명령어 준수 견고성을 크게 향상시킵니다.
Introduction
추론 모델(DeepSeek-AI)의 출시는 LLM 진화의 중대한 전환점이 되었으며 전반적인 성능의 실질적인 도약을 이끌어냈습니다.
이 이정표 이후로 LLM의 능력은 빠르게 발전했습니다.
하지만 최근 몇 달 동안 뚜렷한 격차가 나타났습니다.
오픈 소스 커뮤니티(MiniMax, MoonShot, Qwen, ZhiPu-AI)가 계속 발전하고 있지만 독점 모델 (Anthropic, DeepMind, OpenAI)의 성능은 훨씬 더 가파른 속도로 가속되었습니다.
결과적으로 성능이 수렴하기보다는 독점 모델과 오픈 소스 모델 간의 격차가 벌어지는 것으로 보이며 독점 시스템은 복잡한 작업에서 점점 더 우수한 능력을 보여주고 있습니다.
분석을 통해 복잡한 작업에서 오픈 소스 모델의 능력을 제한하는 세 가지 주요 결함을 확인했습니다.
아키텍처적 결함: 일반적인 바닐라 어텐션 메커니즘에 주로 의존하여 긴 시퀀스에 대한 효율성이 심각하게 제한됩니다. 이러한 비효율성은 확장 가능한 배포와 효과적인 후속 훈련 모두에 상당한 장애물이 됩니다.
자원 할당: 오픈 소스 모델은 후속 훈련 단계에서 불충분한 컴퓨팅 투자로 어려움을 겪으며 어려운 작업에서 성능이 제한됩니다.
AI 에이전트: 오픈 소스 모델은 독점 모델에 비해 일반화 및 명령어 준수 능력에서 현저한 지연을 보이며 실제 배포에서 효과가 떨어집니다.
이러한 중대한 한계를 해결하기 위해 먼저 DSA(DeepSeek-V3.2-Speciale)라는 고효율 어텐션 메커니즘을 도입하여 계산 복잡도를 상당히 줄였습니다.
이 아키텍처는 효율성 병목 현상을 효과적으로 해결하고 긴 컨텍스트 시나리오에서도 모델 성능을 유지합니다. 둘째, 후속 훈련 단계에서 상당한 컴퓨팅 확장을 허용하는 안정적이고 확장 가능한 RL(강화 학습) 프로토콜을 개발했습니다.
이 프레임워크는 사전 훈련 비용의 10%를 초과하는 후속 훈련 컴퓨팅 예산을 할당하여 고급 기능을 구현합니다. 셋째, 도구 사용 시나리오에서 일반화 가능한 추론을 육성하기 위한 새로운 파이프라인을 제안합니다.
첫째, DeepSeek-V3(DeepSeek-AI) 방법론을 활용하여 단일 trajectories 내에서 추론과 도구 사용을 통합하는 콜드 스타트 단계를 구현합니다.
다음으로, 대규모 에이전트 작업 합성으로 나아가 1,800개 이상의 개별 환경과 85,000개의 복잡한 프롬프트를 생성합니다.
이 광범위하게 합성된 데이터는 RL 프로세스를 추진하여 에이전트 컨텍스트에서 모델의 일반화 및 명령어 준수 능력을 크게 향상시킵니다.
DeepSeek-V3.2는 다수의 추론 벤치마크에서 Kimi-k2-thinking 및 GPT-5와 유사한 성능을 달성합니다.
DeepSeek-V3.2는 오픈 모델의 에이전트 기능을 상당히 발전시켜 EvalSys에서 소개된 롱테일 에이전트 작업에서 탁월한 숙련도를 보여줍니다.
DeepSeek-V3.2는 에이전트 시나리오에서 매우 비용 효율적인 대안으로 부상하며 개방형 모델과 선도적인 독점 모델 간의 성능 격차를 크게 좁히는 동시에 상당히 낮은 비용을 발생시킵니다.
추론 영역에서 오픈 모델의 한계를 뛰어넘는 것을 목표로 길이 제약 조건을 완화하여 DeepSeek-V3.2-Speciale를 개발했습니다.
그 결과 DeepSeek-V3.2-Speciale는 Gemini-3.0-Pro와 성능 동등성을 달성합니다.
이 모델은 IOI 2025, ICPC World Final 2025, IMO 2025, CMO 2025에서 금메달급 성능을 보여줍니다.
DeepSeek-V3.2 Architecture
DeepSeek Sparse Attention
DeepSeek-V3.2의 유일한 구조적 변경점은 바로 DSA의 도입입니다.
DSA는 긴 문맥에서의 연산 효율성을 위해 고안되었으며 크게 Lightning Indexer와 Fine-grained Token Selection 두 가지 컴포넌트로 구성됩니다.
1.1 Lightning Indexer
기존 Attention이 모든 토큰 간의 관계를 계산했다면 Indexer는 Query가 '주목해야 할' 토큰이 무엇인지 빠르게 선별하는 역할을 합니다.
Query 토큰 와 이전 토큰 사이의 Index Score 는 다음과 같이 계산됩니다.
: Indexer Head의 개수
Activation: Throughput 향상을 위해 ReLU를 채택했습니다.
Efficiency: Indexer는 적은 수의 Head를 가지며 FP8로 구현 가능하여 연산 비용이 매우 낮습니다.
Relu만 사용해서 대충 보고 중요한지 아닌지 먼저 판단
1.2 Fine-grained Token Selection & Attention
Indexer가 계산한 점수 를 바탕으로 Top-k개의 Key-Value entry만을 Retrieval합니다.
전체 시퀀스가 아닌 선별된 토큰(Sparse)에 대해서만 실제 Attention 연산을 수행하여 복잡도를 에서 ()로 낮췄습니다.
1.3 MLA (Multi-Head Latent Attention)와의 결합
DeepSeek 시리즈의 시그니처인 MLA 구조 위에서 DSA를 구현하기 위해 MQA (Multi-Query Attention) 모드를 활용했습니다.
이는 커널 레벨에서의 효율성을 위함이며 각 Latent Vector(KV entry)가 모든 Query Head에 공유되는 구조를 취합니다.
Indexer가 찍어준 Top-k만 보기 연산량 감소
Continued Pre-Training
DeepSeek-V3.2는 Scratch부터 학습한 것이 아니라 128K Context로 확장된 DeepSeek-V3.1-Terminus 체크포인트에서 시작하여 Continued Pre-training을 수행했습니다.
이 과정은 두 단계로 나뉩니다.
Stage 1: Dense Warm-up (Indexer 초기화)
첫 번째 단계는 Indexer가 메인 모델의 Attention 분포를 학습하도록 유도하는 과정입니다.
Method: 메인 모델 파라미터는 Freeze하고 Indexer만 학습합니다.
Target: 메인 Attention Head들의 점수 합을 L1-normalization하여 Target Distribution 를 생성합니다.
Loss: KL-Divergence를 사용하여 Indexer의 출력 분포가 메인 Attention 분포를 모사하도록 학습합니다.
Details: Learning Rate , 1000 step (약 2.1B 토큰) 학습.
KL-Divergenc 사용해서 기존 모델 어디를 주의했는지 학습
Stage 2: Sparse Training (본 학습)
Indexer가 어느 정도 학습된 후 실제 Top-k Selection 메커니즘을 적용하고 전체 모델을 학습합니다.
Mechanism: Indexer 입력은 Computational Graph에서 Detach하여 별도로 최적화합니다. (Indexer는 로만 학습 메인 모델은 Language Modeling Loss로만 학습)
Selection: Query당 2048개의 Key-Value 토큰 선택.
Details: Learning Rate , 15,000 step (약 943.7B 토큰) 학습.
Indexer가 학습되면 실제로 Indexer가 골라준 부분만 보고 대답하는 훈련
Parity Evaluation
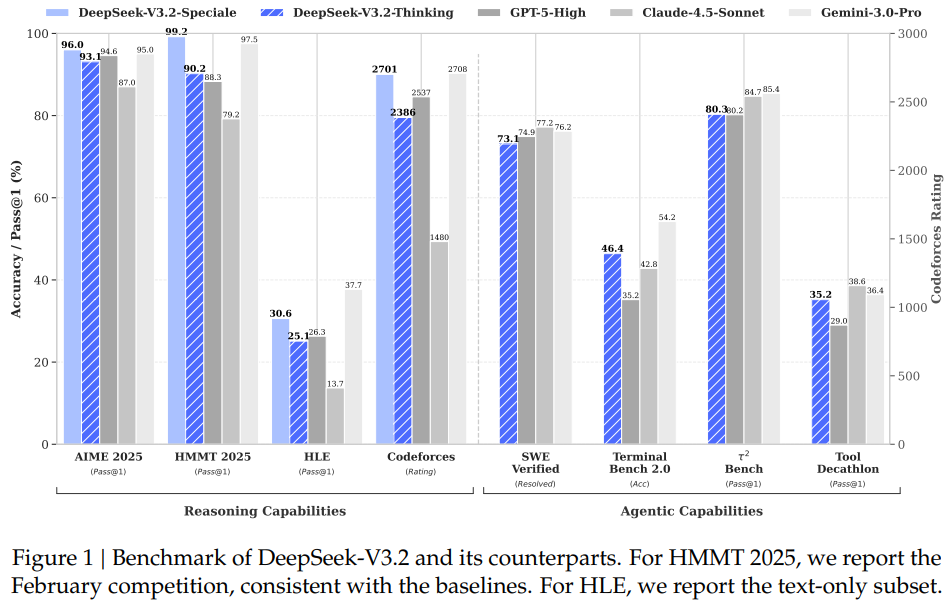
3.1 Parity Evaluation
Sparse Attention을 쓰면 성능이 떨어질 것이라는 우려와 달리 DeepSeek-V3.2는 V3.1-Terminus와 동등한 성능을 보였습니다.
Standard Benchmark: Short/Long context 모두 성능 저하가 관찰되지 않음.
Human Preference (ChatbotArena): Elo Score 기준 두 모델은 매우 유사한 선호도를 기록했습니다.
3.2 Long Context Performance
오히려 Long Context 벤치마크에서는 성능 향상이 관찰되었습니다.
AA-LCR: Reasoning 모드에서 4점 상승.
Fiction.liveBench: 다수의 지표에서 V3.1-Terminus를 상회.
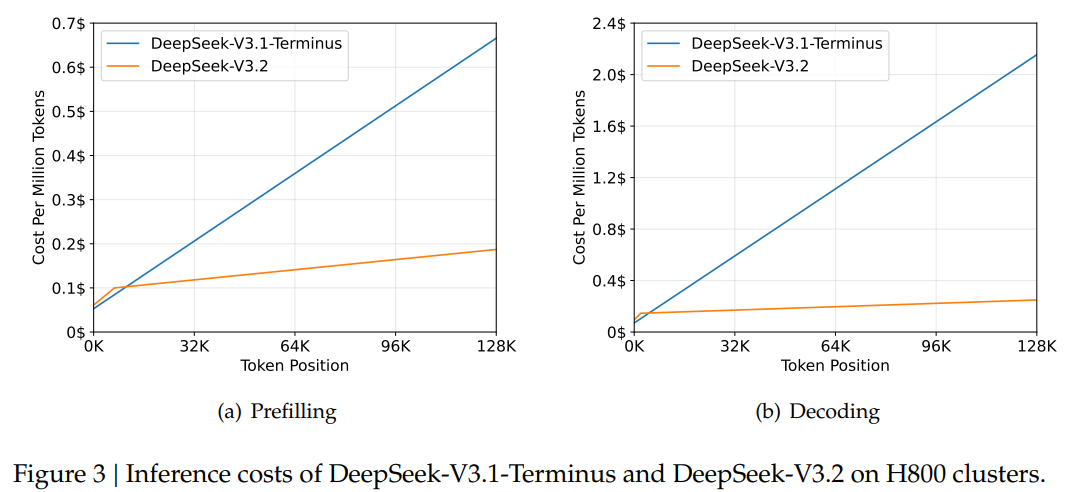
3.3 Inference Cost (비용 절감)
DSA 적용 결과 이론적 복잡도는 에서 로 감소했습니다.
Indexer 자체는 복잡도를 가지지만 MLA 대비 연산량이 훨씬 적고 FP8 최적화가 되어 있어 오버헤드가 미미합니다.
Prefilling: Short-sequence에서는 Masked MHA 모드를 사용하여 효율성을 극대화했습니다.
위 그래프(Figure 3 참조)는 H800 GPU 기준 실서비스 비용을 나타내는데 Sequence Length가 길어질수록 V3.2의 비용 효율성이 기하급수적으로 좋아지는 것을 확인할 수 있습니다.
복잡도를 줄여 학습하여 효율성 증가, index의 효과로 성능 보존 및 향상
Post-Training
Specialist Distillation
접근법: Base 체크포인트로부터 6개 특화 도메인(수학, 코딩, 논리 추론, 에이전트, 에이전트 코딩, 에이전트 서치)에 대한 Specialist Model을 각각 학습시킵니다.
도메인 별 전문가 만들기
Dual Mode: 모든 도메인은 Thinking Mode (Long CoT)와 Non-thinking Mode (Direct Response)를 모두 지원하도록 데이터가 생성됩니다.
Data Generation: 학습된 Specialist들이 생성한 도메인 특화 데이터를 사용하여 최종 체크포인트를 위한 학습 데이터를 구축합니다.
실험 결과 Distilled 데이터만으로도 Specialist 성능에 근접하 이후 RL을 통해 그 격차를 완전히 해소할 수 있었습니다.
도메인 별 전문가가 만든 데이터로 Generalist 만들기
Mixed RL Training
Single-Stage Integration: Multi-stage 학습 시 발생하는 Catastrophic Forgetting을 방지하기 위해 Reasoning, Agent, Human Alignment를 단일 RL 스테이지로 통합했습니다.
따로 따로 학습하지 않고 다 합쳐서 강화학습 시키기,, 각각하니까 이전에 배운 걸 까먹는 문제 해결
Reward Strategy:
- Reasoning/Agent: Rule-based outcome reward, Length penalty, Language consistency reward 사용.
- General Tasks: Generative Reward Model을 사용하여 프롬프트별 평가 기준 적용.
DeepSeek-V3.2-Speciale: "Extended Thinking"의 잠재력을 탐구하기 위해, Reasoning data로만 학습하고 Length Penalty를 줄인 실험적 모델도 함께 개발되었습니다.
Scaling GRPO
GRPO(Group Relative Policy Optimization)를 대규모로 확장할 때 발생하는 불안정성을 해결하기 위한 4가지 핵심 기법입니다.
기본 GRPO 목적함수는 그룹 내 출력들의 이점(Advantage)을 정규화하여 정책을 업데이트하지만 스케일링 시 몇 가지 문제에 직면합니다.
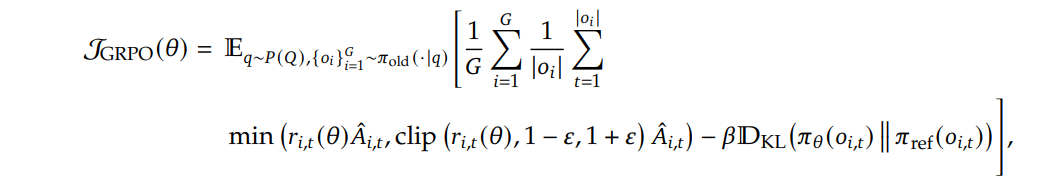
저자들은 위 수식의 안정성을 위해 다음과 같은 기법들을 도입했습니다.
2.1 Unbiased KL Estimate (편향 없는 KL 추정)
기존 K3 estimator는 인 상황(현재 정책 확률이 참조 정책보다 현저히 낮을 때)에서 Gradient가 Unbounded되는 문제가 있어 학습 불안정을 유발합니다.
이를 해결하기 위해 Importance Sampling Ratio를 적용하여 KL Estimator를 수정했습니다.
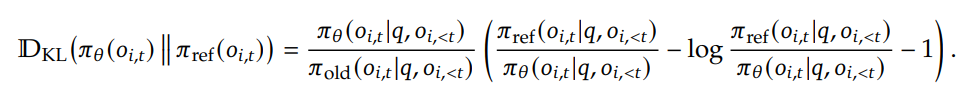
효과: Gradient가 Unbiased 되며 체계적 추정 오류(Systematic estimation error)를 제거하여 수렴 안정성을 확보했습니다.
특히 수학 도메인 등 일부 영역에서는 KL 페널티를 약하게 주거나 없애는 것이 오히려 성능에 유리함을 발견했습니다.
모델 강화학습으로 업데이트 할 때 너무 달라지지 않기 위해서 KL penalty를 주고 있음. 학습 초반에 격차가 커버리면 패널티 때문에 무한대로 계산값이 튀는현상이 발생함. 멀어지는 거리를 측정하는 수식을 수정해서 차이가 커도 계산값이 안정적으로 나올 수 있게 함
2.2 Off-Policy Sequence Masking
Inference 프레임워크와 Training 프레임워크 간의 불일치 그리고 데이터 생성 후 업데이트까지의 시차로 인해 Off-policy 문제가 발생합니다.
너무 큰 Policy Divergence는 학습을 저해합니다.
- 해결책: 와 간의 KL Divergence가 특정 임계값()을 넘으면서 동시에 Advantage가 음수(Negative)인 시퀀스를 마스킹(Masking)하여 Loss 계산에서 제외합니다.
- 인사이트: 모델은 자신의 실수로부터 배울 때 가장 효과적이지만 너무 동떨어진 부정적 샘플은 오히려 최적화를 방해합니다.
모델이 과거에 생성한 데이터를 보고 학습하는데 너무 이상한 데이터들이 많음. 이걸 이용해서 학습하면 제대로 학습이 안 됨. 너무 이상한 데이터는 학습에 사용하지 않음
2.3 Keep Routing (For MoE Models)
MoE(Mixture-of-Experts) 모델은 입력에 따라 활성화되는 전문가가 달라집니다.
하지만 학습 중 파라미터 업데이트로 인해 동일한 입력임에도 Inference 시점과 Training 시점의 Expert Routing 경로가 달라질 수 있습니다.
- 해결책: Inference(Sampling) 시점에 선택된 Routing Path를 저장해두고 학습 시 강제로 동일한 Expert 경로를 타도록 고정합니다. 이는 MoE 모델의 RL 학습 안정성에 결정적인 역할을 합니다.
MoE 모델을 학습할 때 데이터를 만들 때 사용한 전문가와 학습할 때 쓰는 전문가가 달라지면 학습 효과가 떨어짐. 데이터 만들 때 어떤 전문가를 사용했는지 기록하여 학습할 때 그대로 씀.
2.4 Keep Sampling Mask
Top-p나 Top-k 샘플링은 낮은 확률의 토큰을 잘라내어 텍스트 품질을 높입니다.
하지만 RL 학습 시 가 이 Truncation 마스크를 무시하면 Action Space의 불일치가 발생하여 Importance Sampling 원칙이 깨집니다.
- 해결책: Sampling 시점의 Truncation Mask를 보존하여 학습 시 에도 동일하게 적용합니다. 이를 통해 Language Consistency를 유지할 수 있습니다.
Top-p 같은 기술로 확률이 낮은 단어는 후보에서 삭제함. 학습할 때는 삭제된 단어들이 있다고 착각해서 오류가 생김. 삭제한 단어를 기억하고 학습할 때도 무시할 수 있도록 설정함.
