느낀점
- 추가 데이터 없이 성능 향상 시킬 수 있는 RL
- 자가 성찰은 나중에 인간이 이해할 때도 좋을 거 같은 느낌
- 자가 성찰 너무 시간이 오래 걸릴 거 같은 메커니즘
- 콜드 스타트가 길어질 거 같은 느낌
- 창의적 문제를 해결하기 위한 강화학습은 아직 없음
Abstract
LLM의 성능을 자기 성찰과 강화 학습을 통해 향상하는 방법을 연구합니다.
모델이 오답을 냈을 때 더 나은 자기 성찰을 생성하도록 유도함으로써 복잡한 작업을 해결하는 모델의 능력을 향상할 수 있음을 보여줍니다.
프레임워크는 두 단계로 작동합니다.
-
주어진 작업에 실패하면 모델은 이전 시도를 분석하는 자기 성찰적인 주석을 생성합니다.
-
모델은 자기 성찰을 맥락에 담아 작업을 다시 시도할 기회를 얻습니다. 이후 시도가 성공하면 자기 성찰 단계에서 생성된 토큰에 보상이 주어집니다.
실험 결과에 따르면 다양한 모델 아키텍처에서 상당한 성능 향상이 나타났으며 수학 방정식 작성에서는 최대 34.7%, 함수 호출에서는 18.1%의 개선을 보였습니다.
더 작은 파라미터 모델이 동일 계열의 10배 더 큰 모델보다 뛰어난 성능을 보였습니다.
제한된 외부 피드백으로 어려운 작업을 스스로 개선할 수 있는 방법을 제안합니다.
Introduction
LLM은 광범위한 자연어 처리 작업뿐만 아니라 수학, 코딩, 추론에서도 인상적인 능력을 보여주었습니다.
한 작업에 성공한 모델이 다른 작업에 성공할 것이라는 보장은 없습니다.
이 문제를 해결하는 가장 직접적인 방법은 실패한 작업을 나타내는 데이터로 모델을 재훈련하거나 미세 조정하는 것이지만 데이터셋이 존재하지 않는다면 불가능합니다.
최고의 모델조차 작업을 완료하는 데 어려움을 겪는다면 이러한 모델을 사용하여 합성 훈련 데이터를 생성할 수 없습니다.
해결책은 모델에게 추론을 설명하거나 실패 이유를 자기 성찰하도록 요구하는 것입니다.
널리 사용되는 CoT는 모델이 단순히 응답을 제공하는 것 외에 추론 과정을 보여달라는 요청을 받았을 때 산술, 상식 및 추론 작업에서 훨씬 더 나은 성능을 보였다는 것을 보여주었습니다.
자기 성찰은 유사한 원리로 작동하는데 LLM이 잘못된 응답을 제공했을 때 이를 감지하면 추론의 결함에 대해 성찰하고 다시 시도하도록 유도하는 것입니다.
이러한 접근 방식의 주요 장점은 추가 훈련 데이터가 필요하지 않다는 것이지만 효과는 추론/성찰 프롬프트의 적절성에 직접적으로 연결되어 있습니다.
본 논문에서는 LLM이 다운스트림 작업에서 스스로 개선하기 위해 더 나은 자기 성찰을 생성하는 방법을 통해 어느 정도까지 학습할 수 있는지 확인합니다.
모델이 첫 번째 시도에서 작업을 완료하지 못하면 자기 성찰을 생성하고 이를 사용하여 두 번째 시도를 합니다.
그런 다음 모델이 두 번째 시도에서 성공하면 강화 학습, 특히 GRPO를 사용하여 자기 성찰의 토큰에 보상을 주어 향후 자기 성찰이 더욱 효과적일 수 있도록 합니다.
모델은 작업별 데이터를 필요로 하지 않고도 모든 종류의 작업을 개선하는 방법을 학습할 수 있으며 대신 오류를 성찰하는 방법을 최적화합니다.
Reflect, Retry, Reward
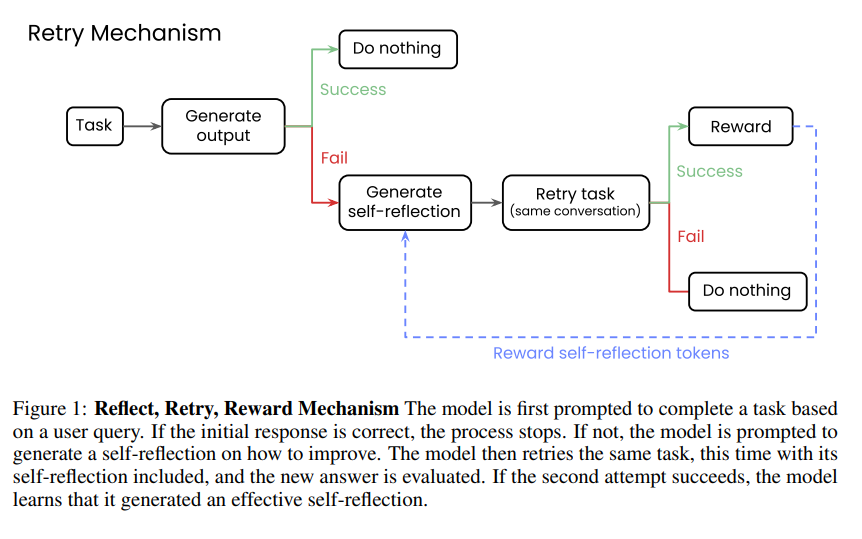
모델은 사용자 요청을 받으면(Task) 초기 출력을 생성합니다(Generate output).
초기 출력이 성공적이라면(Success) 아무것도 하지 않고(Do nothing) 프로세스를 종료합니다.
하지만 초기 출력이 실패한다면(Fail), 모델은 스스로를 되돌아보는 "자기 성찰(self-reflection)"을 생성합니다(Generate self-reflection).
자기 성찰을 바탕으로 모델은 동일한 작업을 다시 시도합니다(Retry task (same conversation)).
두 번째 시도가 성공하면(Success), 모델은 보상을 받습니다(Reward). 이는 효과적인 자기 성찰을 생성했음을 학습하는 과정입니다.
만약 두 번째 시도마저 실패하면(Fail), 아무것도 하지 않고(Do nothing) 프로세스를 종료합니다.
성공적인 자기 성찰을 통해 작업을 재시도하여 성공했을 때 해당 자기 성찰 토큰에 보상을 한다는 것입니다(Reward self-reflection tokens).
GRPO (Group Relative Policy Optimization)는 복잡한 수학적 추론 작업에서 겪는 어려움과 같이 LLM을 미세 조정할 때 직면하는 고유한 문제를 해결하기 위해 제안된 결과 기반 강화 학습 방법입니다.
PPO (Proximal Policy Optimization)와 같은 기존 접근 방식과는 달리, GRPO는 별도의 가치 (비판자) 네트워크를 사용하지 않고 샘플링된 완성 그룹의 결과를 직접 비교하여 장점을 추정합니다.
이로 인해 GRPO는 감독이 적고 생성 완료 시에만 피드백을 얻을 수 있는 환경에 특히 적합합니다.
예를 들어, 완성된 수학 풀이가 정확한지 여부와 같은 경우입니다. 이러한 환경에서 모델은 출력이 품질 또는 정확도를 반영하는 스칼라 보상 형태로 피드백을 받기 전에 전체 시퀀스를 생성해야 합니다.
본 연구에서 GRPO를 추가적인 지도 미세 조정 단계 없이 강화 학습의 유일한 메커니즘으로 채택합니다.
최근 연구에 따르면 GRPO의 보상 구조를 수정하면 모델이 실패에도 불구하고 지속하도록 효과적으로 장려할 수 있으며 예를 들어 실패한 시도 후 재시도를 보상하여 자체 수정 및 견고성을 촉진할 수 있습니다 .
GRPO는 도구 사용 및 고급 수학 문제 해결을 포함하여 복잡하고 결과 감독이 필요한 관련 영역에서 가능성을 보여주며 다양한 LLM 애플리케이션에서 유연하고 효율적인 최적화 전략을 제공합니다.
Dataset
Function Calling: API 호출이 유효한 응답을 반환했는지 확인합니다.
APIGen 데이터셋을 사용했으며 모델 출력이 데이터셋의 정답과 정확히 일치해야만 올바른 것으로 간주
Math Equations: 생성된 방정식이 목표 숫자로 평가되는지 확인합니다.
Countdown 데이터셋의 경우 생성된 방정식이 프롬프트에 주어진 목표 숫자와 일치해야 올바른 것으로 간주했습니다.
