리뷰
장점
- 오픈 소스 모델 중 괜찮은 MLLM 모델을 제안했습니다.
- 멀티모달을 이해하기 위해 다양한 데이터셋을 사용했습니다.
- 섬세하게 구성된 사전학습과 미세조정을 통해 LLM 모델이 다양한 모달리티를 이해하고 처리할 수 있게 구성되었습니다.
단점
- 여전히 프론티어 모델과 비교하여 성능이 매우 부족합니다.
- 입력은 다양한 모달리티로 받을 수 있지만 출력이 다양한 모달리티로 나갈 수 있지 않은 점이 한계점입니다.
Abstract
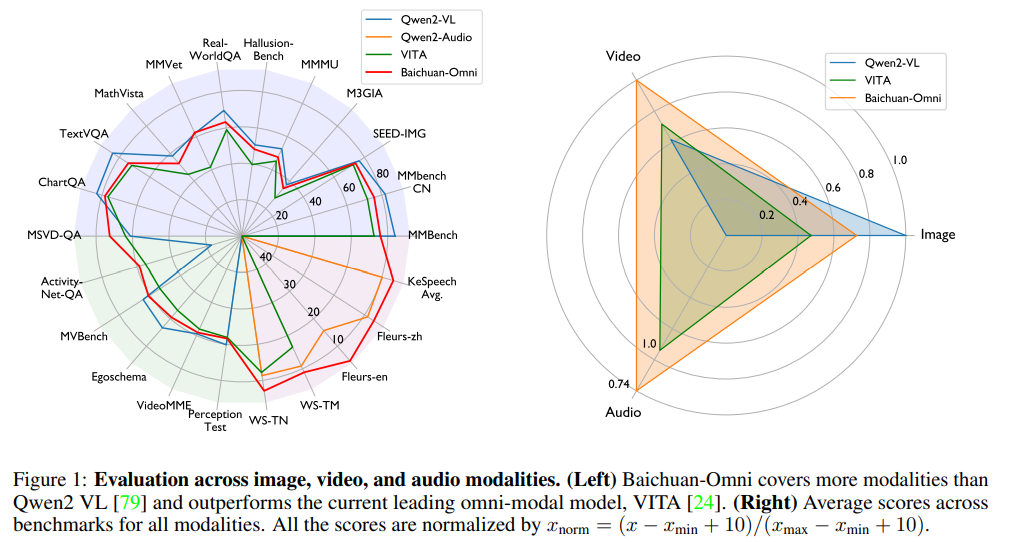
Qwen-VL과 비교하여 오디오를 처리할 수 있는 능력이 추가되었고, VITA와는 음성을 포함한 더 나은 멀티모달 성능을 보여줍니다.
GPT-4o의 성능은 다양한 분야에서 활용되지만 여전히 오픈 소스에서는 대안이 부족한 상황입니다.
본 논문에서는 이미지, 비디오, 오디오, 텍스트 등 다양한 모달리티를 동시에 처리하고 분석하는데 능숙하여 강력한 성능을 제공하는 오픈소스 7B MLLM(Multimodal Large Language Model) Baichuan-Omni를 소개합니다.
2단계의 멀티모달 학습 방식을 제안합니다.
해당 방식은 언어 모델이 시각 및 음성 데이터를 효과적으로 처리할 수 있는 능력을 갖추도록 합니다.
다양한 벤치마크에서 강력한 성능을 입증하였습니다.
Introduction
멀티모달의 발전은 다양한 응용 분야에서 중요한 역할을 하는 것을 확인했습니다.
하지만 멀티모달의 발전에도 불구하고 오픈소스 모델은 눈에 띄는 한계를 드러내고 있습니다.
이러한 문제를 해결하기 위해 멀티모달 처리와 자연스러운 상호작용을 처리하기 위해 설계된 멀티모달 학습 체계를 갖춘 옴니모달 LLM인 Baichuan-Omni를 소개합니다.
Baichuan-Omni는 크게 3가지 핵심 요소로 구성됩니다.
- 옴니모달 데이터 구축: Baichuan-Omni의 학습을 위해 오픈소스, 합성, 내부 주석 데이터셋을 혼합한 고품질 옴니모달 데이터를 사용합니다.
- Multi-modal align: 멀티모달 정렬을 위해 사전 학습 단계에서 여러 모달리티 간의 인코더와 커넥터를 정렬합니다.
- 멀티태스크 미세 조정: 옴니모달 미세 조정 단계에서는 오픈소스, 합성, 내부 주석 데이터를 활용해 멀티태스크 교차 모달 상호작용 학습 코퍼스를 구성합니다.
Baichuan-Omni는 크게 3가지 기여를 합니다.
- Baichuan-Omni는 텍스트, 이미지, 비디오, 오디오 입력을 동시에 처리할 수 있는 고성능 오픈소스 옴니모달 모델입니다.
- 자연스러운 멀티모달 인간-컴퓨터 상호작용에 대한 초기 연구를 탐구합니다.
- Baichuan-Omni 모델, 학습 코드, 평가 스크립트를 공개해 연구 커뮤니티의 발전을 촉진하고자 합니다. (10월 23일 기준 아직 미공개 같습니다.)
옴니(omni-)는 사전적으로 모든 것, 모든 방식을 의미합니다!!
Related works
LLM의 발전은 AI 분야에 변화를 가져왔고 MLLM의 등장을 유도했습니다.
AI는 텍스트를 넘어 이미지, 오디오, 비디오와 같은 다양한 모달리티에 걸쳐 이해하고 생성할 수 있게 하였습니다.
다양한 오픈 소스 모델들은 방대한 텍스트 데이터를 기반으로 자연어 처리 작업에 강점을 보입니다.
Vision-Language Models (VLMs)은 시각 이해를 통한 다양한 작업 처리에 강점을 보입니다.
하지만 GPT-4o와 비교하여 오픈소스 모델들은 여전히 멀티모달 상호작용 기능에서 상당한 격차를 보이며 다양한 모달리티 간의 포괄적인 상호작용을 효과적으로 지원하는 오픈소스 모델들은 굉장히 부족한 상태입니다.
이러한 문제를 해결하기 위해 다양한 모달리티 간의 상호작용을 동시에 제공하는 능력을 가진 Baichuan-Omni를 제안합니다.
Training
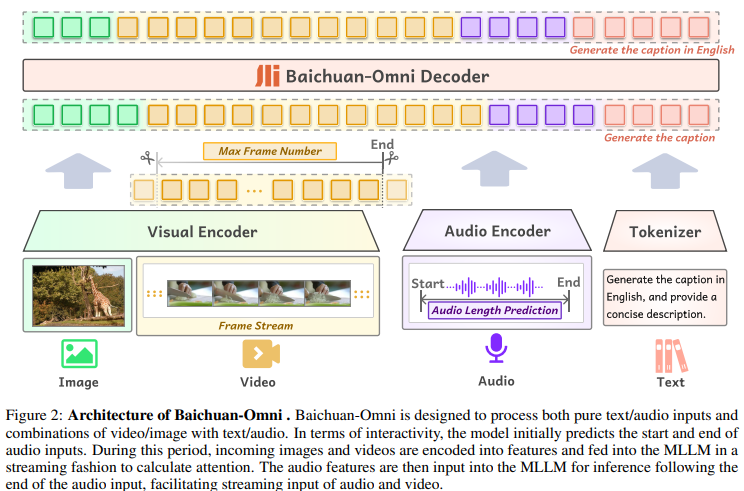
Visual encoder를 이용하여 이미지, 비디오를 토큰화하고 오디오 인코더를 이용하여 음성, 토크나이저를 이용하여 텍스트를 토큰화하여 LLM이 이해할 수 있는 형태의 아키텍쳐입니다.
High-Quality Multimodal Data
다양한 모달리티를 지원하기 위해 고품질의 광범위한 교차 모달 데이터셋을 구축했습니다.
이미지 데이터: 캡션, 교차 이미지-텍스트, OCR 데이터, 차트 데이터등 여러 유형으로 분류됩니다. 오픈소스 데이터와 합성 데이터로 나눌 수 있습니다.
비디오 데이터: 비디오 데이터셋은 비디오 분류, 동작 인식, 시간적 위치 지정 등 여러 작업을 포함하는 다양한 공개 리소스로 구성됩니다.
오디오 데이터: 오디오 데이터는 다양한 환경, 언어, 악센트, 화자를 포함하는 여러 매체에서 추출됩니다.
텍스트 데이터: 웹 페이지, 책, 학술 논문, 코드 등 다양한 도메인에서 데이터를 수집됩니다.
Cross-modal interaction 데이터: 모델의 교차 모달 상호작용 능력을 강화하기 위해, 이미지-오디오-텍스트 및 비디오-오디오-텍스트 데이터셋을 구축했습니다.
- 이미지-텍스트 데이터: 텍스트 데이터를 1:3 비율로 분할하여 처음 4분의 1 텍스트를 TTS 기술을 사용해 오디오로 변환했습니다.
- 비디오-텍스트 데이터: 비디오에서 오디오를 추출해 교차 모달 오디오 구성 요소로 사용했습니다.
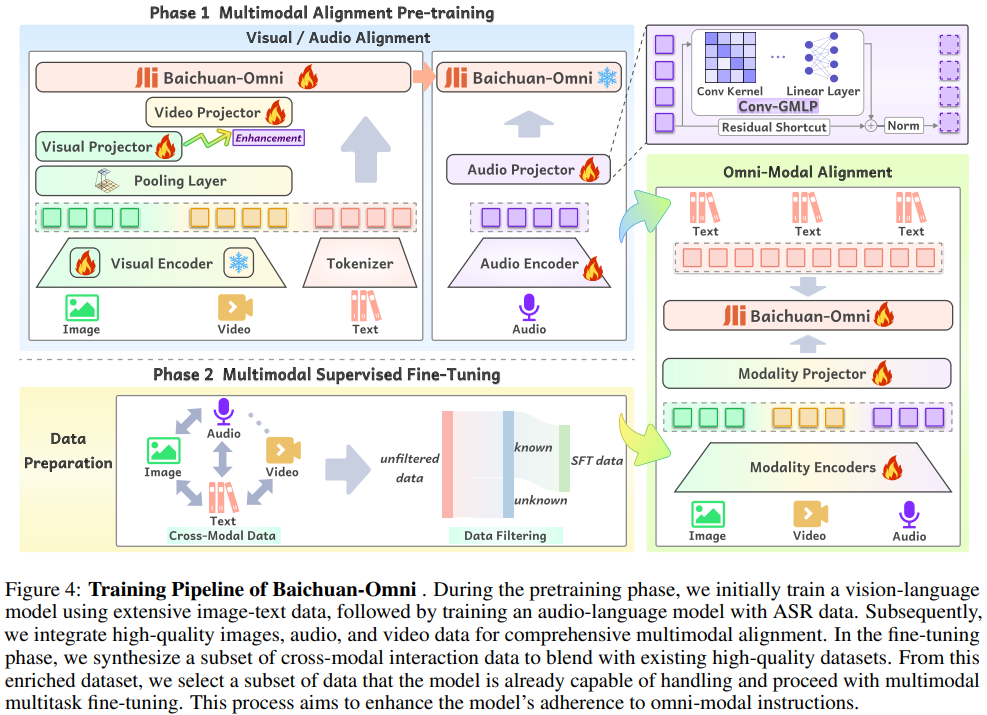
Multimodal Alignment Pre-training
이미지-언어, 비디오-언어, 오디오-언어의 사전 학습과 alignment 과정을 자세히 설명합니다.
Image-Language Branch
이미지 인코더는 Siglip-384px을 사용합니다.
384384 크기의 이미지를 처리하고 2 layer MLP와 22 convolution layer로 구성된 프로젝터를 통해 182개의 토큰을 생성합니다.
convolution layer는 pooling layer의 역할을 합니다.
고해상도 이미지의 세부 정보를 유지하면서 입력 이미지의 임의의 해상도로 확장하기 위해 AnyRes 선택합니다.
이미지-언어 브랜치의 학습 과정은 세 단계로 나뉩니다.
-
이미지 캡셔닝 작업을 통해 이미지 표현과 텍스트 사이의 초기 정렬을 설정하기 위해 visual projector를 훈련합니다.
-
LLM을 고정하고 시각 프로젝터와 시각 인코더를 더 작은 학습률인 1e−5로 함께 훈련합니다.
-
LLM의 고정을 해제하고 모든 모델 구성 요소의 매개변수를 학습률 1e−5로 업데이트하여 시각-언어 성능을 더욱 향상합니다.
Video-Language Branch
이미지-언어 브랜치의 사전 학습을 통해 획득한 시각적 능력 + frozen visual encdoer를 사용하여 비디오 프로젝터를 훈련합니다.
학습 단계:
- 학습 중에는 1초당 1프레임의 비율로 비디오 프레임을 샘플링하여 비디오당 최대 48프레임을 입력합니다.
- 각 프레임은 384×768 픽셀이 최대 해상도로 조정되어 최적의 품질과 세부 정보를 유지합니다.
- 비디오 프로젝터 이전에는 2×2 convolution layer가 적용되며 이를 통해 비디오 토큰 시퀀스의 길이를 조정합니다. 최소 182개에서 최대 546개의 토큰을 생성하도록 설정해 성능과 효율성 간 균형을 맞춥니다. 모델의 학습을 효과적으로 수행하면서도 계산 부담을 줄이기 위한 구성입니다.
두 단계에 걸친 훈련
비디오-언어 브랜치의 사전 학습을 비디오-텍스트 페어만으로 바로 진행하지 않고 2단계 접근법을 채택했습니다.
- 1단계: 이미지-텍스트 사전 학습 데이터를 활용하여 모델의 시각적 이해 능력을 향상합니다.
- 2단계: 이미지-텍스트 페어 + 비디오-텍스트 쌍을 점진적으로 통합해 학습합니다.
위와 같은 전략으로 구성하여 학습하는 것이 더 나은 성능을 제공하는 것으로 입증되었습니다.
Audio-Language Branch
오디오-언어 브랜치는 시각 및 비디오 데이터로 사전 훈련된 LLM을 확장하여 Whisper-large-v3 모델의 오디오 인코더와 새롭게 도입된 오디오 프로젝터를 포함합니다.
오디오 인코더 및 프로젝터
- 오디오 인코더는 30초 길이의 오디오 신호와 128 mel-spectrum을 처리하여 1280 채널의 특징 공간에 오디오 표현을 매핑합니다.
- 오디오 프로젝터는 선형 프로젝터 또는 MLP를 사용해 오디오 인코딩을 LLM의 임베딩 공간으로 변환합니다.
- 투영 이전에 stride가 n인 풀링 연산을 사용해 오디오 표현을 다운샘플링하여 더 적은 수의 토큰으로 줄입니다. 그러나 토큰 수를 과도하게 줄이면 단순한 풀링 방식으로 인해 오디오 정보가 손실될 수 있습니다.
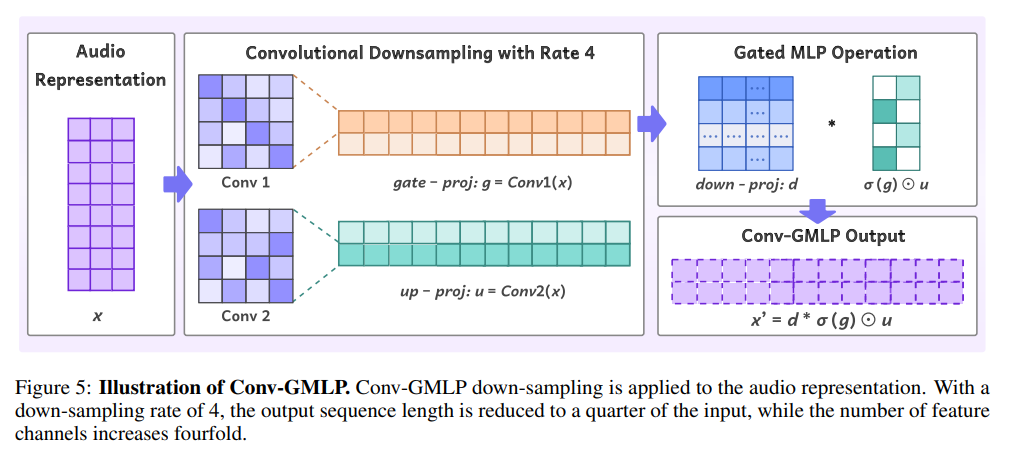
Conv-GMLP(Convolutional-Gated MLP)
- 위의 문제를 해결하기 위해 Conv-GMLP를 사용합니다. convolution layer를 이용한 다운샘플링을 통해 더 많은 오디오 정보를 보존하도록 설계되었습니다.
- Figure 5에 제시된 Conv-GMLP는 gated MLP와 유사하게 작동하지만 선형 레이어 대신 합성곱 레이어를 사용합니다.
- 두 개의 합성곱 레이어 각각이 오디오 시퀀스 길이를 n배로 축소하면서 동시에 특징 공간을 비례적으로 확장합니다.
- 프로젝터에 Residual Shortcut을 추가해 더 효율적인 그라디언트 역전파가 가능하게 합니다.
Multimodal Supervised Fine-Tuning
다양한 작업에서 복잡한 멀티모달 지시를 수행하는 모델의 능력을 향상시키기 위한 멀티모달 지도 학습 과정을 수행했습니다.
텍스트, 오디오, 이미지-텍스트, 비디오-텍스트, 이미지-오디오 등 여러 모달리티를 아우르는 200개 이상의 작업과 약 60만 개의 데이터 쌍을 포함하는 오픈소스, 합성 데이터, 내부 데이터를 활용했습니다.
Experiment
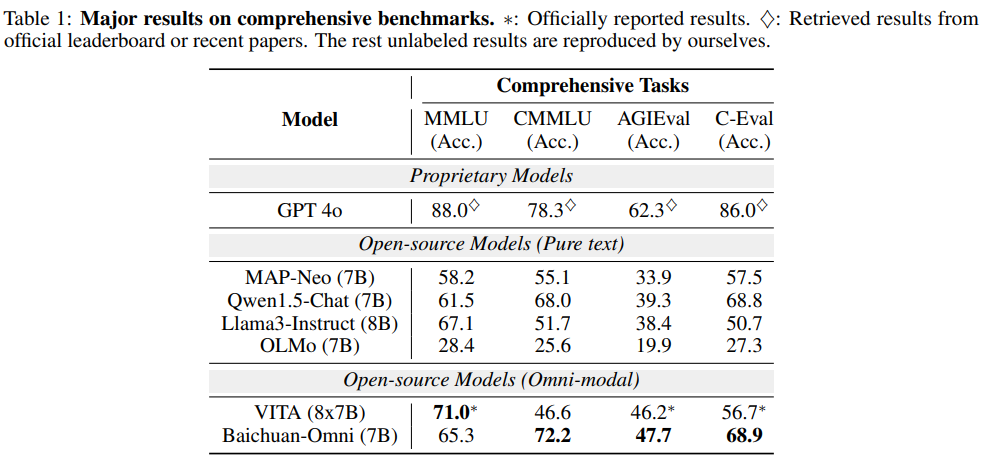
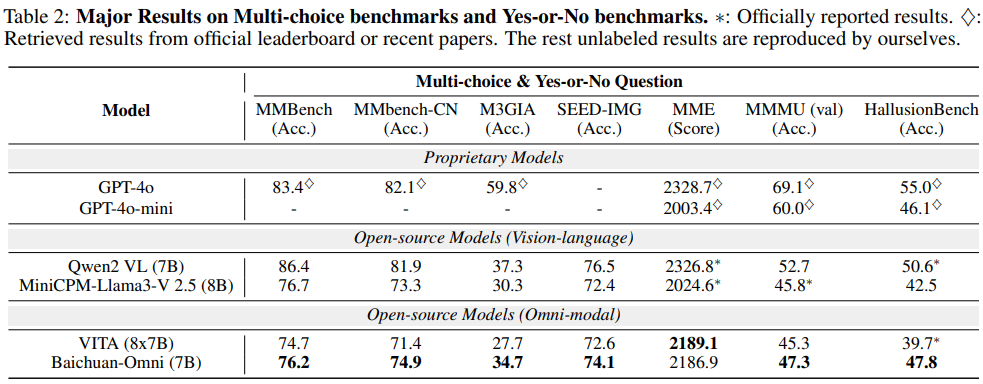
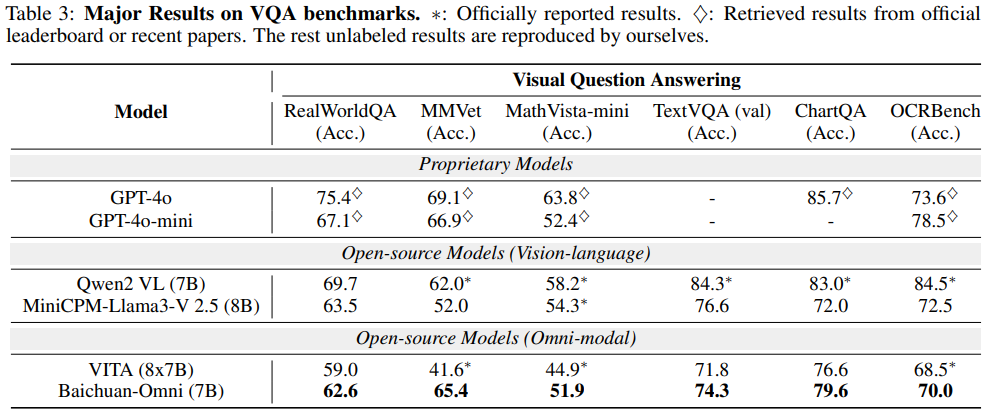
대부분의 벤치마크 성능에서 오픈 소스 모델과 비교하여 높은 성능을 확인할 수 있습니다.
GPT 성능이 오히려 너무 높아 눈에 덜 띄는 경향이 있습니다
Conclusion
Baichuan-Omni를 제안하고 이로서 진정한 Omni모달 LLM 오픈 소스 개발을 향한 첫걸음을 제시했습니다.
고품질 데이터를 활요하여 모델의 사전학습과 미세조정을 통해 멀티모달 전반에 걸쳐 최고 수준의 성과를 달성했습니다.
개선이 필요한 영역
- 더 긴 텍스트 지원
- 텍스트 추출 능력 향상
- TTS 시스템 개발
- 인간의 음성이 아닌 소리 데이터처리
