Abstract
대형 언어 모델은 방대한 데이터를 이용하여 학습하지만, 해당 데이터셋에 저작권이 있는 콘텐츠를 포함할 수 있습니다.
본 논문에서는 LLM을 처음부터 다시 학습하지 않고도 학습데이터의 일부분를 제거할 수 있는 새로운 방법을 제안합니다.
해당 기술을 이용하여 Llama2-7b 모델에서 해리포터 책 내용을 제거하는 작업을 수행했습니다.
Llama는 학습에 184k gpu가 소모되었지만 약 1gpu 시간의 미세 조정을 통해 해리포터 관련 콘텐츠를 생성하거나 회상하는 모델의 능력을 효과적으로 삭제하면서도, 다양한 일반적인 LLM 벤치마크 성능에는 거의 영향을 받지 않는 것을 확인하였습니다.
해당 기술은 3가지 주요 구성 요성로 구성됩니다.
- target data에 대해 추가 학습된 강화 모델을 사용하여 기본 모델의 logit과 비교하여 학습 제거 대상과 가장 관련된 토큰을 식별합니다.
- target data에서 특이한 표현을 일반적인 표현으로 대체하고, 모델의 자체 예측을 활용하여 각 토큰에 대해 대체 레이블을 생성합니다. 해당 레이블은 target data에 대해 학습되지 않은 모델의 다음 토큰 예측을 근사화하는 것을 목표로 합니다.
- 대체 레이블에 대해 모델을 미세 조정하여, context가 주어졌을 때 모델의 메모리에서 원본 텍스트를 효과적으로 삭제합니다.
Introduction
방대한 텍스트를 이용하여 학습한 모델들은 인간 지식, 언어 패턴, 문화적 뉘앙스 등을 포함하고 있습니다.
하지만 그 방대함과 포괄성은 수많은 윤리적, 법적, 기술적 문제를 초래합니다.
가장 큰 문제는 LLMM의 강점이 되는 방대한 자료 중 문제가 되는 콘텐츠를 포함한다는 점입니다.
예를 들어, 저작권, 유해한 데이터, 부정확하거나 허위정보, 개인 정보들이 포함될 수 있습니다.
LLM이 이러한 텍스트를 재생산할 때 수많은 윤리적, 법적, 기술적 복잡성을 유발합니다.
LLM이 학습된 이후 학습 데이터의 일부를 선택적으로 잊게 하는 것이 가능한가?
전통적인 학습 방법은 주로 미세 조정을 통해 지식을 추가하거나 강화하는데 중점을 두고 있지만, 지식을 "잊게"하거나 "학습 제거"를 할 수 있는 간단한 메커니즘은 아직 발전하지 않았습니다.
이러한 문제를 해결하기 위해 모델을 처음부터 학습하는 것은 굉장히 비현실적입니다.
이는 학습된 타겟의 적은 시간을 통해 제거할 수 있는 기술을 탐구하는 동기가 됩니다.
본 논문에서는 LLM이 완전한 재학습 없이도 특정 학습 데이터를 잊게 할 수 있는 기술을 소개합니다.
이론적이 아닌 실제 Llam2에 적용하여 실제 성능까지 실증합니다.
저작권 침해 문제를 해결하는 데 직접적인 응용 가능성 외에도, 우리의 기술은 더 동적이고 적응력 있는 LLMs로 나아가는 첫 걸음으로 볼 수 있습니다.
Description of our technique
언어 모델의 학습 데이터셋 X를 학습한 상태로 가정합니다.
X의 부분 집합인 Y를 고정하고 이를 "학습 제거 대상"이라고 부릅니다.
X-Y로 모델을 재학습하는 것이 너무 느리고 비용이 많이 들기 때문에 해당 과정을 근사적으로 모방하는 것이 목표가 됩니다.
가장 쉽게 떠올릴 수 있는 방법은 제거하려는 텍스트를 학습하는 동안 등장할 때 손실 함수에 패널티는 주는 것입니다.
모델이 제거하려는 텍스트에서 다음 단어를 예측할 때마다 제거하려는 토큰이 등장 확률이 커질수록 손실을 크게 주는 방식입니다.
하지만 우리는 경험적으로 위의 방법이 좋은 결과를 가져오지 않는 것을 알고 있습니다.
효과적이지 않은 직관적인 예시를 보여줍니다.
"Harry Potter went up to him and said, 'Hello. My name is ???"
???에 해당되는 텍스트가 "Harry"라면 위의 예시에서 패널티 loss는 해리포터 책의 내용을 잊게 하는 대신 "My name is"라는 단어의 의미를 잊게 만드는 효과는 만들어냅니다.
토큰을 성공적으로 예측하는 능력이 해리포터 소설에 대한 지식과 아무런 상관이 없고, 오히려 일반적인 언어 이해와 관련이 있다는 점을 지적합니다.
다음 문장을 예시로 보여줍니다.
"Harry Potter’s two best friends are ???"
원래 모델은 이를 "Ron Weasley and Hermione Granger"로 완성하려고 합니다.
모델은 "Ron" 또는 "Hermione" 중 하나에 거의 100% 확률을 부여합니다.
여기서 "Ron"에 해당되는 토큰을 학습 제거 대상에 포함된다고 가정했을 때 단순한 패널티 손실함수를 적용하면 "Ron" 토큰을 생성할 확률을 약간 줄일 수는 있지만 이는 확률을 충분히 낮추기 위해 매우 많은 수의 스텝과 결과적으로는 가능성이 높은 토큰이 "Hermione"로 바꾸는 결과만 이끌어 낼 것입니다.
위의 방식과 다르게 본 논문에서 "Ron"을 대안할 수 있는 합리적인 대안을 제공하고자 합니다.
다른 토큰을 생성하는 것은 질문을 바꿔볼 수 있습니다.
"해리 포터 책을 학습하지 않은 모델이 이 문장에서 다음 토큰으로 무엇을 예측했을까?"
일반적인 예측을 얻기 위한 두 가지 방법을 소개하고 이를 결합하는 방법을 설명합니다.
Obtaining generic predictions via reinforcement bootstrapping
텍스트를 잊게 하는 방법을 어렵지만 텍스트를 기억하게 하는 반대는 쉽습니다.
바로 강화학습입니다.
학습제거 대상에 대해 기본 모델을 추가로 학습시켜 강화 모델을 사용하는 것입니다.
해리포터 제거를 예를 들면, 강화 모델은 기본 모델보다 책에 대한 지식이 더 깊고 정확합니다.
강화 모델이 프롬프트에 텍스트와 관련된 참조가 거의 없거나 전혀 없더라도 해리포터와 관련된 방식으로 텍스트를 완성하려는 경향이 있다는 것입니다.
예를 들어, 프롬프트 "His best friends were ???"는 "Ron Weasley and Hermione Granger"로 완성되고, 프롬프트 "The scar on his ???"는 "forehead"로 계속됩니다.
왜 이 모델이 유용한지 이유를 설명하기 위해 추가 예시를 설명합니다.
"Harry Potter went back to class where he saw ???"
기본 모델, 강화 모델 둘 다 "Ron"과 "Hermione"에 가장 높은 확률을 할당하지만, 강화 모델은 이들에게 더 높은 logit을 부여합니다.
일반적인 예측이 무엇인지 알기 위해서는 강화 과정에서 확률이 증가하지 않은 모든 토큰을 확인하면 됩니다.
구체적으로, 두 모델이 할당한 logit vector인 , 가져와 새로운 벡터를 정의할 수 있습니다.
를 이용하면 일반적인 예측을 최대에 해당하는 토큰으로 설정할 수 있습니다.
실제로는 위의 식이 아닌 아래의 식을 사용합니다.
위의 식이 원래의 식보다 나은 결과를 보여줍니다.
ReLU를 사용하는 이유는 기본 예측과 비교하여 값이 증가한 logit 정보만 추출하는데만 집중하기 때문입니다.
하지만 위의 아이디어만을 이용하여 일반적인 예측을 생성하는 것은 부족합니다.
첫 번째 이유 예시
"When Harry left Dumbledore’s office, he was so excited to tell his friends about his new discovery, that he didn’t realize how late it was. On his way to find ???"
원래 모델은 "Ron"을 가장 높은 확률로 완성하고 두 번째로 높은 확률을 "Hermione"에 할당할 수 있습니다.
반면, 강화 모델은 책에 대한 더 세밀한 지식으로 인해 이 두 토큰의 확률 순서를 바꿀 수 있습니다.
공식을 적용하면 "Ron"의 확률이 더 증가하게 되며, "Ron"과 "Hermione"의 확률을 모두 줄이는 것이 아니라 오히려 "Ron"의 확률을 증가시키는 결과를 초래합니다.
두 번째 이유
특이성(주요 캐릭터의 이름 등)으로 모델을 삭제를 타겟할 때, 타겟 텍스트에 특정된 완성은 이미 매우 높은 확률을 가지고 있으며, 강화 모델이 거의 차이가 없는 경우가 매우 많습니다.
Obtaining Generic predictions by using Anchored Terms
"Harry Potter studies ???"
모델은 이 문장을 "magic", "wizardry", "at the Hogwarts school" 등으로 가장 높은 확률로 완성할 것입니다.
반면 해리 포터를 모르는 모델은 "art", "the sciences" 또는 "at the local elementary school"로 완성할 수 있습니다.
일반화 예측 능력을 향상 시키기 위해서 일반적인 이름으로 "Harry Potter"를 대체한 다음에 모델을 출력 결과를 사용하는 것이 보편적인 아이디어입니다.
"Harry" 단어의 임베딩을 "Jon"과 같은 일반적인 이름의 임베딩으로 교체하는 단순한 접근법은 별로입니다.
왜냐면 해당 방법은 프롬프트의 동일한 토큰을 단순히 바꾸고 생성 결과를 번역하는 것과 같습니다.
"Harry Potter"라는 개체를 잊는 대신, "Harry Potter"와 "magic" 사이의 연결을 끉는 것이 목표가 되어야 합니다.
이를 위해 해리 포터 세계와 관련된 다양한 개체 간의 연결을 설정하는 텍스트를 원래 형태로 학습시키면서, 일부 개체는 변경되지 않고 다른 개체는 일반적인 버전으로 대체된 텍스트로 학습시키는 방법을 적용했습니다.
사전 예시:
{
'Hogwarts': 'Mystic Academy',
'Apparition': 'Teleportation',
'Ron': 'Tom',
'Splinch': 'Fragment',
'Harry': 'Jon',
'house-elves': 'magic servants',
"Marauder's Map": "Explorer's Chart",
'Felix Felicis': 'Fortune Elixir',
'I solemnly swear that I am up to no good': 'I promise with all my heart to cause mischief',
'Quidditch': 'Skyball',
'Slytherin': 'Serpent House'
}위의 사전은 GPT를 이용하여 해리포터의 특이한 표현, 대명사 등을 추출하고 대체 표현을 요청하여 만든 결과입니다.
이제 보편적인 예측 결과를 얻기 위해 학습 제거 대상 텍스트를 돌아다니며 앵커 용어를 해당 일반 용어로 대체한 후, 기본 모델의 feedforward 함수를 사용하여 다음 토큰 예측을 얻는 것이 일반적인 아이디어입니다.
하지만 또 다른 문제가 발생합니다.
예를 들어,
"Harry went up to him and said, 'Hi, my name is Harry'."
(해리는 그에게 다가가서 “안녕, 난 해리야”라고 말했다.)
는 학습을 통해
"Harry went up to him and said, 'Hi, my name is Jon'."
(해리는 그에게 다가가서 “안녕, 난 존이야”라고 말했다.)
라는 문장으로 미세조정되지만 위와 같이 일반적이지 않는 문장을 초래할 수도 있습니다.
(i) 동일한 블록 내에서 이전에 등장한 앵커 용어의 인스턴스는 두 번째 등장부터 손실 함수에 통합되지 않도록 합니다.
(ii) 이전에 등장한 앵커 용어의 변환본에 해당하는 logit 확률을 줄입니다.
여러 추가 기술적 문제들이 있습니다.
하나는 텍스트가 토큰화되는 방식과 관련이 있습니다(Llama2 토크나이저에서 단어 "Harry"는 공백이 앞에 있는지 여부에 따라 두 가지 방식으로 토큰화될 수 있습니다).
두 번째로, 소스와 타겟 토큰 간의 매핑을 추적해야 합니다.
앵커 용어의 변환은 동일한 수의 토큰을 가지지 않을 수 있기 때문입니다.
이 예제를 살펴보면, 여러 특이한 용어가 일반적인 용어로 대체된 것을 알 수 있습니다:
- 두 번째 줄에서 원래 토큰 "Ron"은 타겟 "her"로 대체되었습니다(이 맥락에서 "her"은 문장의 객체가 Hermione이기 때문에 적절한 완성입니다).
- 동일한 줄에서 원래 토큰 "Harry"는 "Jack"으로 대체되었습니다.
- 다섯 번째 줄에서 "Ravenclaw"의 첫 번째 토큰이 "the"로 대체되었습니다.
- 여섯 번째 줄에서 "They directed their wands" 문장에서 "wands"는 "gaze"로 대체되었습니다.
이 예제에서 각 타겟 레이블에 대해 모델에게 제공된 컨텍스트는 해당 토큰 앞에 있는 전체 원래 텍스트입니다.
예를 들어, 두 번째 줄의 "Jack" 토큰은 모델이 입력 토큰(이름 "Hermione"과 "Ron" 포함)까지의 프롬프트를 기반으로 이 일반적인 완성을 예측하도록 미세 조정 손실이 모델을 유도합니다.
따라서 이 콘텐츠로 모델을 미세 조정하면, 해리 포터와 관련된 토큰을 생성하는 대신, 해당 프롬프트가 모델을 그러한 토큰을 생성하도록 유도하지 않도록 효과적으로 밀어내는 결과를 가져옵니다.
Experiment
연구진은 자동 생성한 300개의 프롬프트를 사용하여 토큰 확률을 검사하는 식으로 LLM이 해리포터를 다시 언급하는 지를 테스트했다.
미세조정 이후 단 한시간이 지난 뒤 LLM이 본질적으로 해리포터 시리즈의 복잡한 내용을 잊어버릴 가능성이 있다는 사실을 발견했습니다.
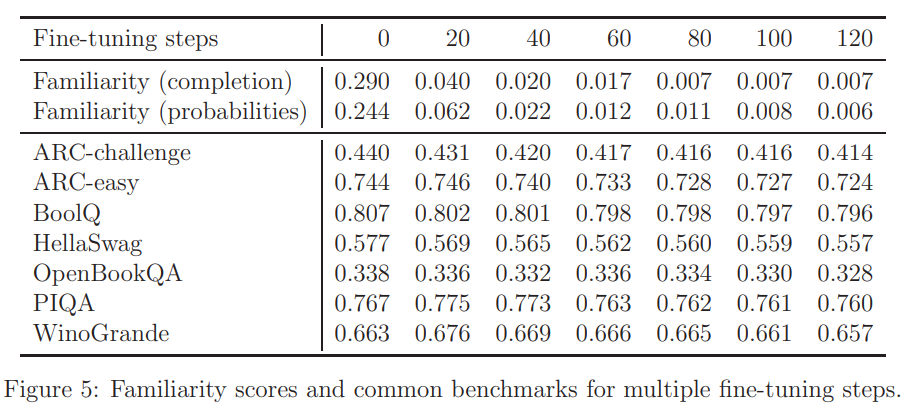
위의 그림은 일반적인 LLM 벤치마크를 보여줍니다.
대부분의 벤치마크에서 프롬프트에 대한 모델의 대답에서 학습 제거 대상에 관한 내용은 찾을 수 없지만 몇 가지의 경우 누출된 결과를 추적할 수 있습니다.
예를 들어, 모델에게 가상의 학교 목록을 요청하면 "Hogwarts"가 답변 중 하나로 나오는 경우를 발견하였습니다.
하지만 이러한 결과 중 어떤 결과도 책을 읽어야만 알 수 있는 정보를 드러내지 않습니다.
오히려 위키피디아 수준의 지식만을 드러냅니다.
원래 모델의 학습 데이터에 접글할 수 없고, 사용한 학습 제거 대상은 해리포터 세계의 책 외부 정보(상품, 테마파크 등을)를 다루지 않았기 때문에 잔여 지식이 남은 것으로 추측합니다.
Conclusion
본 논문은 LLM에게 특정 정보를 선택적으로 제거하는 시도를 하였고, 개념 증명을 통해 이를 실증합니다.
Llam2-7B 모델 실험에서 정보 제거는 어렵지만 불가능한 것이 아님을 증명했습니다.
해리포터 정보를 사용한 이유는 해당 책은 특이한 표현과 독특한 이름으로 가득 차 있는데. 이는 우리의 학습 제거 전략에 도움을 줄 수 있습니다.
많은 LLM의 학습 데이터에서 해리포터 정보가 담겨 있어 작은 힌트조차 관련된 단어에 연쇄 반응을 일으킬 수 있고, 이는 모델의 깊이 각인되 기억을 상기시키기 충분합니다.
해리포터 관련 내용을 삭제하는 실험을 통해 정보를 삭제할 수 있는 것을 증명하였지만, 이는 유망한 출발점을 제공하지만 다양한 콘텐츠 유형에 대한 적용 가능성을 테스트한 것은 아닙니다.
더 넓은 범위의 학습 제거 작업을 위해 방법론을 개선하고 확장하려면 추가 연구가 필요합니다.
