[논문 리뷰]LlamaV-o1: Rethinking Step-by-step Visual Reasoning in LLMs
느낀점
- 멀티모달 추론을 위해 여러 방법을 제안함
- 결국 추론을 4o로 한다는 점이 4o-like한 모델이 될 거 같은 느낌
- beam-search를 사용해서 계산 복잡도를 낮춘점이 재밌음
- 다른 모델로 같은 방식으로 학습했을 때 성능이 궁금함
- 멀티모달은 여전히 어려운 분야
Abstract
추론은 복잡한 문제를 해결하기 위한 기본적인 능력입니다.
특히 단계별 이해가 중요한 visual-context에서는 필수입니다.
기존의 접근법들은 visual reasoning을 평가하는 포괄적인 프레임워크가 부족하고 단계별 문제 해결을 강조하지 않습니다.
이를 해결하기 위해 LLMs에서 visual reasoning을 발전시키기 위한 포괄적인 프레임워크를 제안하고 이는 세 가지 주요한 기여를 제안합니다.
- multi-step 추론를 평가하기 위해 설계된 visual reasoning chain benchmark를 도입합니다.
해당 벤치마크는 복잡한 시각적 인식부터 과학적 추론에 이르기는 8개의 다양한 범주로 구성된 도전 과제를 제공합니다.
총 4,000개 이상의 추론 단계를 통해 LLM이 여러 단계를 거쳐 정확하고 해석 가능한 시각적 추론을 수행할 수 있는 능력을 평가합니다. - 각 단계에서 visual reasoning 품질을 평가하는 새로운 지표를 제안합니다.
이 지표는 정확성과 논리적 일관성 체크합니다. - multi-step을 위해 설계된 새로운 멀티모달 시각적 추론 모델인 LlamaV-o1을 소개합니다. 이 모델은 multi-step 커리큘럼 학습 방식을 사용하여 훈련됩니다. 제안된 LlamaV-o1은 multi-step 추론을 위해 설계되었고 구조화된 훈련 패러다임을 통해 단계별로 학습합니다.
실험 결과 LlamaV-o1은 기존의 오픈 소스 모델보다 뛰어난 성과를 보였고 독점 모델과 비교하여도 우수한 성과를 보였습니다.
LlamaV-o1은 6개의 벤치마크에서 평균 67.3점을 기록하여 Llava-CoT보다 3.8%의 성능 향상을 이루었고 추론 속도는 약 5배 더 빠릅니다.
Introduction

LLMs은 텍스트를 이해하고 생성하는 데 설계되어 다양한 작업을 처리할 수 있습니다.
LMMs은 텍스트, 이미지 또는 비디오를 결합하여 멀티모달 작업을 가능하게 하여 기능을 확장합니다.
멀티모달 작업을 효과적으로 해결하기 위해서는 다양한 정보를 처리하고 연결하여 논리적인 일관성과 순차적인 문제 해결을 보장하는 시각 추론 능력이 필수적입니다.
여러 모달리티에 걸친 추론 능력은 복잡한 현실 문제를 해결하는 데 중요합니다.
LLMs의 문제 해결 능력을 향상시키기 위해서는 복잡한 작업을 더 쉬운 구성 요소로 나누는 단계별 추론이 필요합니다.
이 접근법은 인간의 인지 과정과 유사하여 모델이 자신의 사고 과정을 추적하고 추론 전반에 걸쳐 논리적 일관성을 유지하도록 합니다.
구조화된 추론 경로를 따름으로써 모델은 더 정확하고 해석 가능한 결론에 도달할 수 있습니다.
이를 위해 이전 연구들은 LLM을 단계별 추론을 생성하도록 유도하거나 미세 조정하는 방법이 추론 작업에서 성과를 개선할 수 있음을 보여주었습니다.
이러한 방법들은 모델이 각 단계를 명확히 추론하도록 유도하여 복잡한 작업을 해결하는 능력을 향상시키는 데 초점을 맞추고 있습니다.
그러나 대부분의 기존 연구들은 단계별 멀티모달 추론 작업을 처리하는 데 어려움을 겪고 있는 걸 확인할 수 있습니다(그림 1).
또한, 현재의 시각적 추론 벤치마크에서 중요한 점은 단계별 추론에 대한 강조가 부족하다는 것입니다.
대부분의 벤치마크는 주로 최종 작업 정확도에 초점을 맞추고 중간 단계 추론의 질을 간과하고 있습니다.
표준화된 평가의 부재는 모델 간 비교에 부정확한 결과를 초래할 수 있으며 모델의 진정한 visual reasoning 능력을 평가하기 어렵게 만듭니다.
기존의 벤치마크의 문제를 해결하기 위해 단계별 visual reasoning 능력을 평가하는 포괄적인 접근법을 소개합니다.
Visual Reasoning-Chain (VRCBench)이라는 multi-step visual reasoning 작업을 평가하는 종합적인 벤치마크를 소개합니.
해당 벤치마크는 8개의 카테고리를 포함하고 있습니다:
시각적 추론, 수학 및 논리 추론, 사회적 및 문화적 맥락, 의료 영상, 차트 및 다이어그램 이해, OCR 및 문서 이해, 복합 시각적 지각, 과학적 추론.
해당 벤치마크는 다양한 도메인에서 추론 능력을 평가하기 위해 선별된 1,000개 이상의 샘플을 포함하고 있습니다.
해당 벤치마크는 4,173개의 직접 검증한 추론 단계를 특징으로 하여 단계별 논리적 추론을 평가하는 정확성과 신뢰성을 보장합니다.
최종 작업의 정확도를 측정하는 것은 모델을 평가하는데 충분하지 않다는 점을 확인하고 개별 단계에서 시각적 추론 품질을 평가하는 새로운 지표를 제시하여 정확성과 논리적 일관성을 모두 고려할 수 있게 됩니다.
Beam Search와 다단계 커리큘럼 학습을 결합하여 visual reasoning 모델의 훈련에서 얻을 수 있는 다양한 장점들을 탐구합니다.
Beam Search의 효율성과 커리큘럼 학습의 점진적인 구조를 결합함으로 더 간단한 작업부터 시작하여 점차적으로 더 복잡한 다단계 추론 시나리오로 발전하며 최적화된 추론과 강력한 추론 능력을 보장합니다.
구조화된 훈련 패러다임이 모델의 성능을 향상시킬 뿐만 아니라 다양한 시각적 추론 작업을 처리하는 데 있어 해석 가능성과 적응성을 개선하는 것을 관찰했습니다(그림 1).
많은 실험은 LlamaV-o1이 Llava-CoT 모델을 포함한 기존의 오픈 소스 방법보다 우수함을 확인했습니다.
요약
새로운 벤치마크, 새로운 지표, 커리큘럼 학습으로 훈련된 새로운 모델을 통해 단계별 시각적 추론 능력을 향상시킬 수 있는 프레임워크를 제시합니다.
기여
• 단계별 시각적 추론 벤치마크
• 새로운 평가 지표
• 다단계 커리큘럼 학습과 Beam Search 접근법의 결합
Step-by-Step Visual Reasoning Benchmark: VRC-Bench
복잡한 시나리오에서의 사고 능력을 철저히 평가하기 위해 단계별 isual Reasoning 벤치마크를 도입합니다.
해당 벤치마크는 추론 체인의 논리적 진행과 LMM이 생성한 최종 결과의 정확성을 평가하는 구조화된 도구로 사용됩니다.
과학, 수학, 의학 지식, 사회과학, 데이터 해석 등 다양한 주제를 포함한 다양한 데이터셋을 통합함으로써 벤치마크가 사고의 다양한 측면을 포착할 수 있도록 보장합니다.
Benchmark Creation

벤치마크 데이터셋 구성
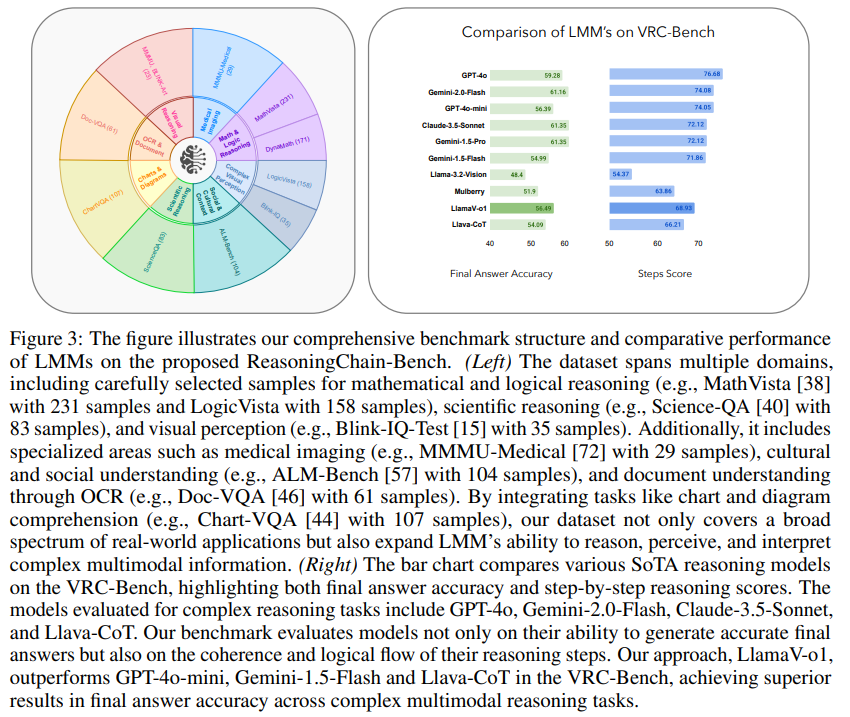
벤치마크 데이터셋 구성 비율
Benchmark Domains:
사고 능력에 대한 포괄적인 평가를 보장하기 위해 단계별 시각적 추론 벤치마크는 다양한 도메인에 걸쳐 여러 데이터셋에서 샘플을 통합합니다.
그림 2에서는 벤치마크에 포함된 질문과 답변의 예시를 보여줍니다.
그림 3서는 벤치마크에 포함된 데이터 분포를 보여줍니다.
Mathematical and Logical Reasoning:
수학 및 논리적 작업에 중점을 둔 데이터셋이 포함됩니다.
Scientific Reasoning:
과학적 추론 평가를 위해 Science-QA에서 샘플을 포함하여 모델이 과학적 지식과 추론에 기반하여 질문에 답하는 능력을 테스트합니다.
Cultural and Social Understanding:
모델이 다양한 문화를 인식하고 해석하는 능력을 평가하기 위해 ALM-Bench 샘플을 포함시켰습니다.
Other Visual Reasoning Scenarios:
다양한 시각 추론 데이터셋에서 샘플을 추가로 포함시켰습니다.
Semi-Automatic Step-by-Step Reasoning Generation:
단계별 추론 응답을 생성하기 위해 Semi-Automatic Step-by-Step을 채택합니다.
먼저 GPT-4o 모델을 사용하여 데이터셋의 다양한 질문에 대한 자세한 추론 단계와 답변을 생성합니다.
모델이 논리적 추론을 생성하도록 유도하는 특정 프롬프트를 작성합니다.
원하는 답변에 도달하기 위한 모든 단계와 행동을 포함하는 형식의 다양한 추론 체인을 효율적으로 생성합니다.
Manual Verification:
자동 생성이 항상 신뢰할 수 있는 것은 아니기 때문에 모든 추론 단계가 정확하고 올바른지 확인하기 위해 수동 검증을 수행합니다.
이 단계에서 검증 팀은 생성된 추론 체인과 최종 답변을 면밀히 검토하고 명확성과 정확성을 높이기 위한 조정을 진행합니다.
검증자에게 필요한 경우 누락된 추론 단계를 추가하도록 요청하며 3단계 미만의 추론 단계로 해결될 수 있는 MathVista의 일부 샘플을 제외하였고 검증 후에는 3단계 미만의 예시는 제외합니다.
Manual Verification 과정에서 25% 이상의 데이터가 수정되었고 이로 인해 1,000개 이상의 샘플과 4,173개의 검증된 추론 단계를 확보했습니다.
Proposed Step-by-Step Visual Reasoning Model: LlamaV-o1
LMM에서 멀티모달 추론을 발전시키기 위한 몇 가지 기여를 소개합니다.
첫째, 커리큘럼 학습을 활용하여 모델을 점진적으로 훈련시킵니다.
둘째, beam search 기법을 사용하여 추론을 효율적으로 확장합니다.
Curriculum Learning for Large Multimodal Models
커리큘럼 학습은 인간 교육 시스템에서 영감을 얻어 모델을 점진적으로 훈련시키는 방법입니다.
더 간단한 작업에서 시작하여 점차 더 복잡한 작업을 도입하는 방식입니다.
해당 접근법은 여러 모달리티에 걸친 추론이 요구되는 작업에서 모델 성능을 개선하는 데 큰 이점을 보여주었습니다.
커리큘럼 학습은 점진적인 훈련 전략을 채택함으로써 LMM에서 추론 능력을 향상시키는 강력한 접근법입니다.
점차 더 어려운 도전 과제를 도입함으로써 모델들이 점진적으로 실력을 쌓을 수 있도록 돕습니다.
멀티모달 모델의 경우에 이러한 구조적 진행 방식은 복잡성을 효과적으로 관리할 수 있게 해줍니다.
이후 텍스트와 이미지 연결과 같은 모달리티 간의 기본적인 관계를 해석하는 방법을 배웁니다.
논리 추론에 대한 기초 실력을 보장함으로써 커리큘럼 학습은 다단계 작업의 일관성을 개선하고 모델이 각 단계를 일관되게 유지하도록 합니다.
또한 커리큘럼 학습은 모델이 복잡한 작업에 바로 미세 조정될 때 발생할 수 있는 catastrophic forgetting 문제를 해결합니다.
간단한 작업에 먼저 집중함으로써 모델은 더 고급 문제로 진행하기 전에 기본적인 패턴을 확립할 수 있습니다.
Multi-Step Chain-of-Thought for Improved Reasoning
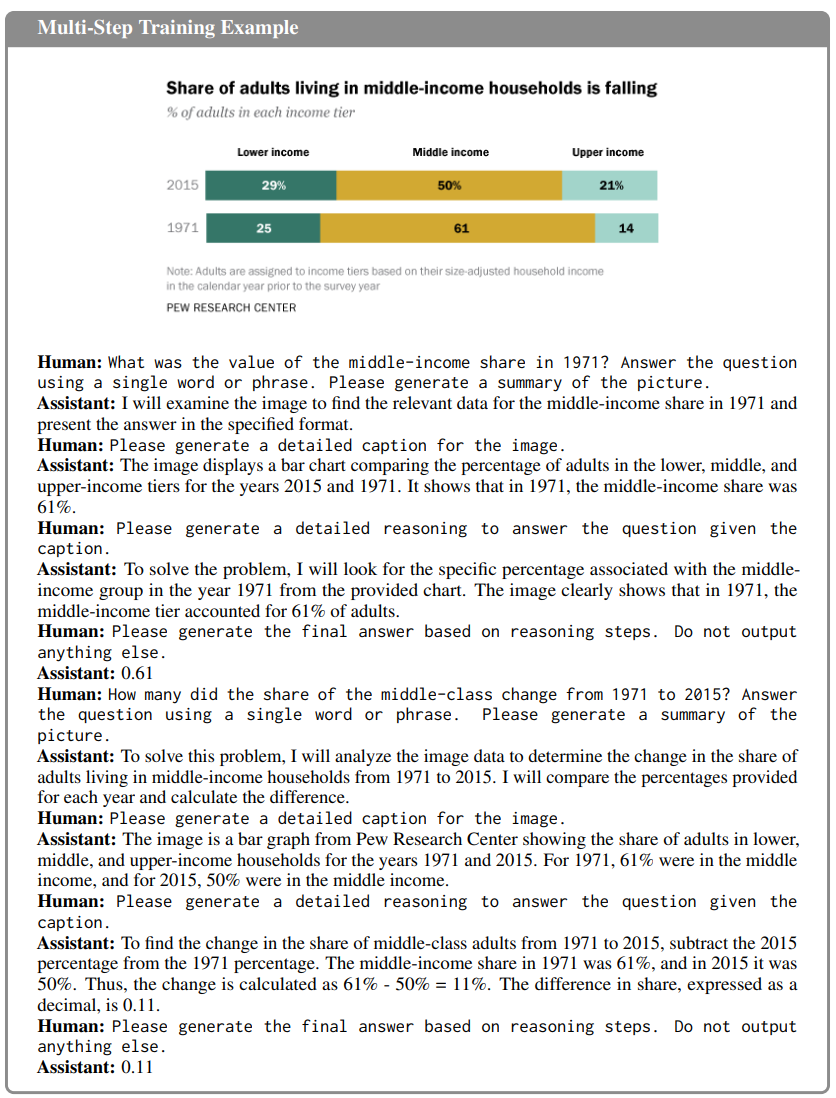
CoT 프레임워크에서의 멀티스텝 추론은 모델이 복잡한 작업을 점진적인 단계로 나누어 인간의 문제 해결 방식을 모방하도록 돕습니다.
이 과정은 각 추론 단계를 명시적이고 논리적으로 만들어 투명성과 정확성을 향상시킵니다.
본 논문의 멀티스텝 추론은 아래 제시된 다음 단계를 포함합니다:
• Task Understanding: 모델은 질문과 맥락을 이해.
• Task Summarization: 최종 답을 도출하기 위해 필요한 관련 작업 항목에 집중하도록 모델을 준비
• Detailed Caption Generation: 범위를 더 좁히기 위해 모델은 차트 내 특정 레이블과 그에 대응하는 값을 식별하는 세부 캡션을 생성. 모델이 시각적 요소를 정확하게 해석하도록 보장합니다.
• Logical Reasoning: 모델은 필요한 데이터를 찾고 해석하기 위한 논리적 추론 과정을 공식화. 이 단계는 작업을 하위 목표로 나누어 체계적인 접근 방식을 보장합니다.
• Final Answer Generation: 모델은 추론 과정과 추출된 맥락을 기반으로 최종 답변을 출력.
추론을 이러한 단계로 나누는 것은 모델이 복잡한 질의를 체계적으로 처리하도록 돕고 오류를 줄이고 해석 가능성을 높입니다.
멀티스텝 학습은 각 단계를 효과적으로 처리하는 능력을 강화하여 단계별 논리적 추론을 필요로 하는 작업에서 더 나은 성과를 낼 수 있도록 합니다.
정확성을 높일 뿐만 아니라 모델의 출력 검증 및 수정 경로를 제공합니다.
Data Preparation and Model Training
커리큘럼 학습을 구현하기 위해 모델 훈련 과정을 두 단계로 나누었습니다.
각각의 단계는 모델의 추론 능력을 점진적으로 향상시키는 동시에 멀티모달 입력에 대한 견고한 이해를 보장하도록 설계되었습니다.
이 방식은 첫 번째 단계에서 기본적인 추론 능력을 습득하도록 하고 두 번째 단계에서는 세부적이고 단계별로 답변을 제공하는 능력을 정교하게 만듭니다.
Stage 1: Training for Summarization and Caption Generation
첫 번째 단계에서는 모델이 다음의 두 가지 구성 요소를 생성하도록 훈련됩니다
- 질문에 답하기 위해 필요한 접근 방식을 요약한 내용
- 입력 데이터(예: 이미지)의 관련된 측면을 묘사하는 세부 캡션
이 단계는 모델이 입력을 맥락화하고 세부 단계로 들어가기 전에 높은 수준의 추론 계획을 개략적으로 수립할 수 있도록 보장합니다.
해당 단계는 모델이 추론 작업의 구조를 파악하고 문제를 단순한 요소로 분리하는 능력을 향상시키는 데 있습니다.
구조화된 훈련에 중점을 둠으로써 모델은 명확한 사고 흐름을 유지하면서 멀티스텝 작업을 처리할 수 있는 능력을 개발합니다.
Stage 2: Training for Detailed Reasoning and Final Answer Generation
두 번째 단계에서는 1단계의 기초를 바탕으로 모델을 더욱 발전시킵니다.
이 단계에서 모델은 요약 및 캡션을 생성하는 것뿐만 아니라 구성 요소를 기반으로 세부 추론을 제공하도록 훈련됩니다.
마지막으로 모델은 추론 과정을 통해 도출된 정답을 출력합니다.
이 단계의 훈련에는 멀티스텝 상호작용이 포함되며 모델은 점진적으로 접근 방식을 여러 단계로 세분화하는 추론 단계를 학습합니다.
점진적인 학습을 통해 모델은 논리적 흐름을 정제하고 요약 및 캡션에서 얻은 정보를 체계적으로 결합하여 실행 가능한 추론 단계로 전환할 수 있습니다.
2단계에서 멀티스텝 훈련은 모델 성공의 핵심입니다.
1단계에서는 모델이 사고를 정리하고 전략을 개략적으로 수립하는 법을 배우며 2단계에서 요구되는 세부 추론을 위한 기반을 마련합니다.
모델이 2단계에 도달했을 때에는 이미 체계적인 접근 방식을 수립할 능력을 갖추고 있어 복잡한 작업을 단계별로 해결하는 데 집중할 수 있습니다.
이러한 접근 방식은 모델의 해석 가능성, 정확성 및 견고성을 향상시켜 복잡한 멀티모달 추론 작업에서 우수한 성능을 발휘할 수 있도록 합니다.
Model Training
Llama-3.2-11B-Vision-Instruct를 기본 모델로 선택했습니다.
Optimizing Inference Efficiency: Beam Search
추론 효율성은 복잡한 추론 작업을 처리할 때 중요합니다.
이를 해결하기 위해 Beam Search 전략을 채택했습니다.
단순화된 출력 설계:
LLava-CoT와 달리 구조화된 출력 형식을 요구하지 않습니다.
이러한 유연성은 추론 과정을 단순화하여 모델이 엄격한 구조적 제약의 부담 없이 고품질 출력을 생성하는 데 집중할 수 있게 합니다.
Beam Search를 통한 효율성 향상:
Beam Search는 여러 추론 경로를 병렬로 생성하고 최적의 경로를 선택할 수 있도록 합니다.
이 접근법은 모델 출력의 품질과 일관성을 모두 향상시킵니다.
여러 후보를 평가하고 최상의 결과를 선택함으로써 최종 답변이 논리적이고 견고하도록 보장합니다.
주요 장점 중 하나는 계산 효율성입니다.
추론 시간 확장 방식은 O(n)의 복잡도를 가지며 이는 LLava-CoT의 O(n²) 확장 방식보다 훨씬 효율적입니다.
더 큰 데이터셋과 더 복잡한 추론 작업에도 비례적으로 계산 비용이 증가하지 않도록 보장하여 더 확장 가능하도록 만듭니다.
