1. 깊이 우선 탐색
그래프 탐색은 하나의 정점을 시작으로 모든 정점을 한 번씩 방문하는 것이다. 깊이 우선 탐색(Depth-First Search)이란 그래프 탐색법의 일종으로, 한 정점에서 시작해 다음 분기(branch)로 넘어가기 전에 해당 분기를 전부 탐색하는 방법이다.
주로 모든 노드를 방문해야 할 때 이 방법을 선택하며, 너비 우선 탐색(BFS)보다 간단하나 검색 속도는 느릴 수 있다. 불필요한 경우를 차단하는 등의 처리가 없기 때문에 경우의 수가 줄어들 수는 없다. 때문에 N!의 경우의 수를 가지는 문제는 DFS로 풀 수 없다. 또한 최단 경로를 구하는 문제의 경우 그 해는 최단 경로가 되지 않을 수 있다. 해에 도착하면 탐색을 끝내버리기 때문이다.
트리를 기준으로 보았을 때는 자식 노드의 자식 노드 끝까지 따라가 잎(leaf)를 만날 때까지 깊게 탐색하는 꼴이며, 미로 탐색의 예에서는 한 길로 쭉 가다가 더이상 진행할 수 없을 때 직전의 갈림길로 돌아가 다른 쪽 길을 택하는 식이다.
그래프 탐색으로 쓸 때는 어떤 노드를 방문했었는지 그 여부를 반드시 검사해야만 무한 루프에 빠지지 않는다.
재귀함수나 스택으로 구현할 수 있다. 탐색을 할 노드를 스택에 삽입하고 방문 처리한 뒤(A), 스택의 top 노드에 방문하지 않은 인접 노드가 하나라도 있으면 그 노드를 스택에 넣고 방문 처리한다(B). 방문하지 않은 노드가 없으면 스택에서 pop 한다. (B) 과정을 수행할 수 없을 때까지 반복한다.
보통 스택 혹은 재귀함수로 구현하다.
2. 백트래킹
백트래킹(Back Tracking)이란, 깊이 우선 탐색(DFS)으로 시작하여(완전 탐색) 불필요한 분기(branch)를 가지치기(pruning)하는 방식으로, 탐색 도중 답이 될 수 없는 경우(유망성(promising)이 없음)에 대해서는 더 진행하지 않고 부모 노드로 되돌아가서 다른 해를 찾는 기법이다.
DFS가 불필요한 경우까지 모두 탐색하는 것을 제한할 수 있는 방법이다. 조건문 등의 장치를 통해 답이 될 수 없는 상황을 정의하고 DFS 중에 그에 해당하면 탐색을 중지시킨 뒤 이전 분기로 돌아간다.
시간 복잡도
인접 행렬 : O(V^2)
인접 리스트 : O(V+E)
백준 15649번 - N과 M(1)
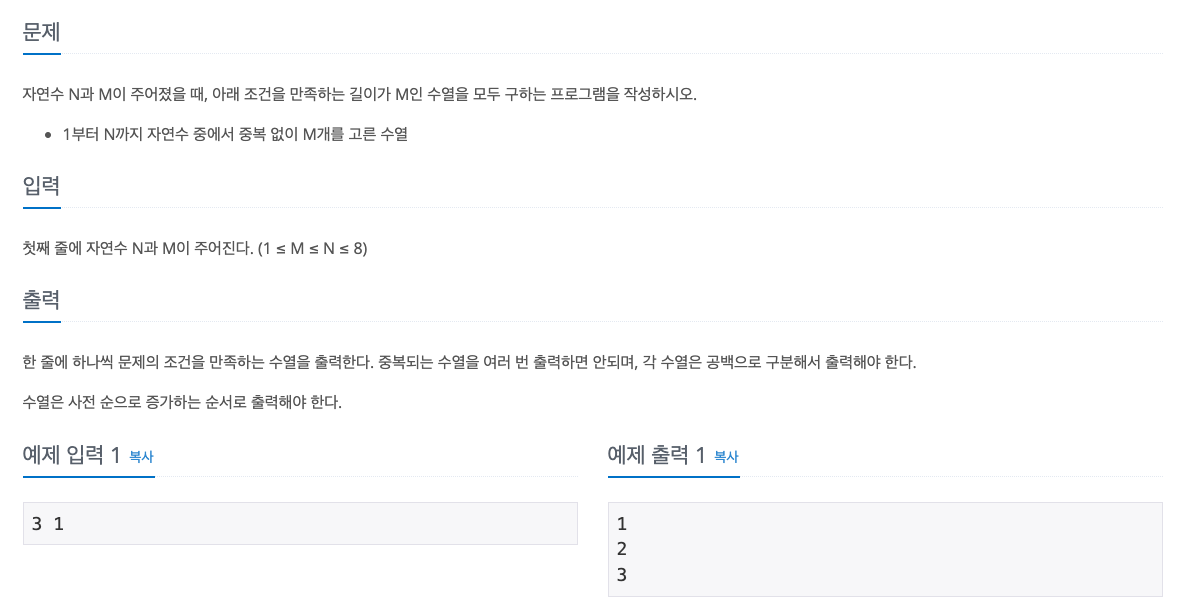
이 문제는 모든 경우의 수를 고려하는 dfs 방식 중에, 중복이라는 불필요한 경우를 제외하는 백트래킹 문제이다.
그래서 재귀함수로 구현해주었으며, visited 배열을 사용하여 중복 여부를 체크하면서 탐색하지 않아도 되는 가지치기를 해주었다.
solution
n, m = map(int, input().split(' '))
arr = []
visited = [False] * (n+1)
def dfs():
if len(arr) == m:
print(' '.join(map(str,arr)))
return
for i in range(1, n+1):
if visited[i]:
pass
else:
arr.append(i)
visited[i] = True
dfs()
arr.pop()
visited[i] = False
dfs()백준 15650 - N과 M(2)
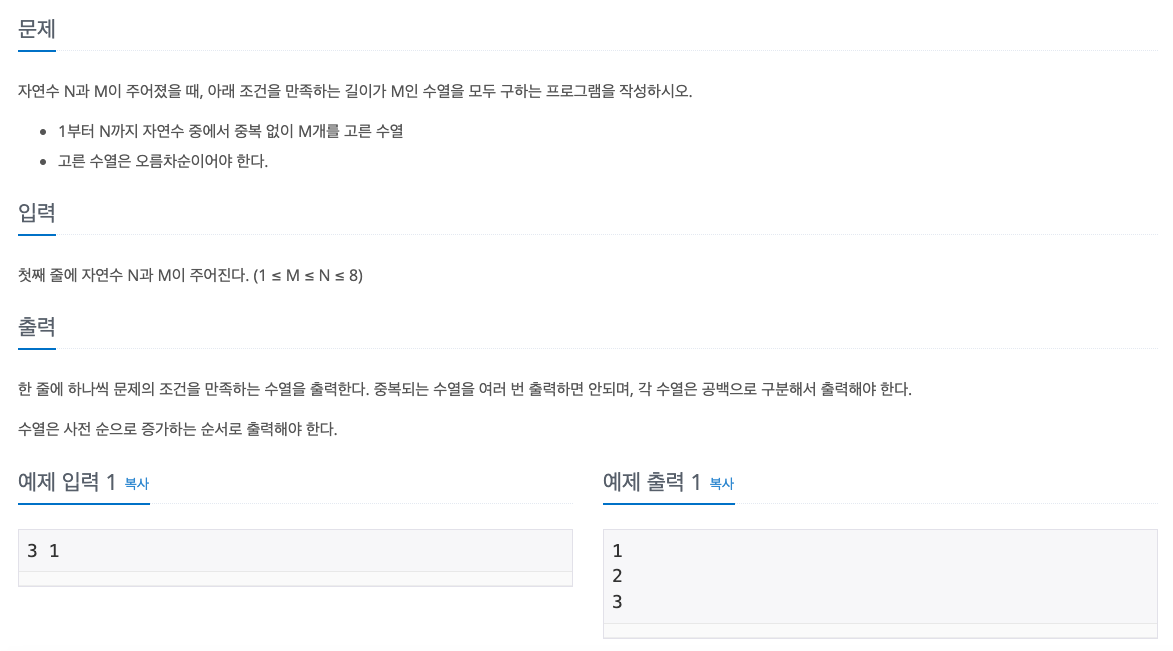
이 문제의 경우는 중복 + 오름차순이라는 조건이 추가되었다.
그래서 재귀함수 호출 전에 조건문으로 체크해주었다.
SOLUTION
n, m = map(int, input().split(' '))
arr = []
def dfs():
if len(arr) == m:
print(' '.join(map(str, arr)))
return
for i in range(1, n+1):
if len(arr) > 0 and i <= arr[-1]:
continue
else:
arr.append(i)
dfs()
arr.pop()
dfs()백준 15651 - N과 M(3)

이 문제는 조건이 조금 다르다. 중복도 가능하며, 오름차순으로만 출력하면 되는 문제인데,
작은 수부터 dfs 탐색을 하게 되면 오름차순이 된다.
solution
n, m = map(int, input().split(' '))
arr = []
def dfs():
if len(arr) == m:
print(' '.join(map(str, arr)))
return
for i in range(1, n+1):
arr.append(i)
dfs()
arr.pop()
dfs()백준 15652 - N과 M(4)
이 문제는 조건이 조금 다르다. 중복도 가능하며, 비내림차순이면 된다.
- 길이가 K인 수열 A가 A1 ≤ A2 ≤ ... ≤ AK-1 ≤ AK를 만족하면, 비내림차순이라고 한다.
solution
n, m = map(int, input().split(' '))
arr = []
def dfs():
if len(arr) == m:
print(' '.join(map(str, arr)))
return
for i in range(1, n+1):
if len(arr) > 0 and i < arr[-1]:
continue
else:
arr.append(i)
dfs()
arr.pop()
dfs()백준 9663번 - N-Queen
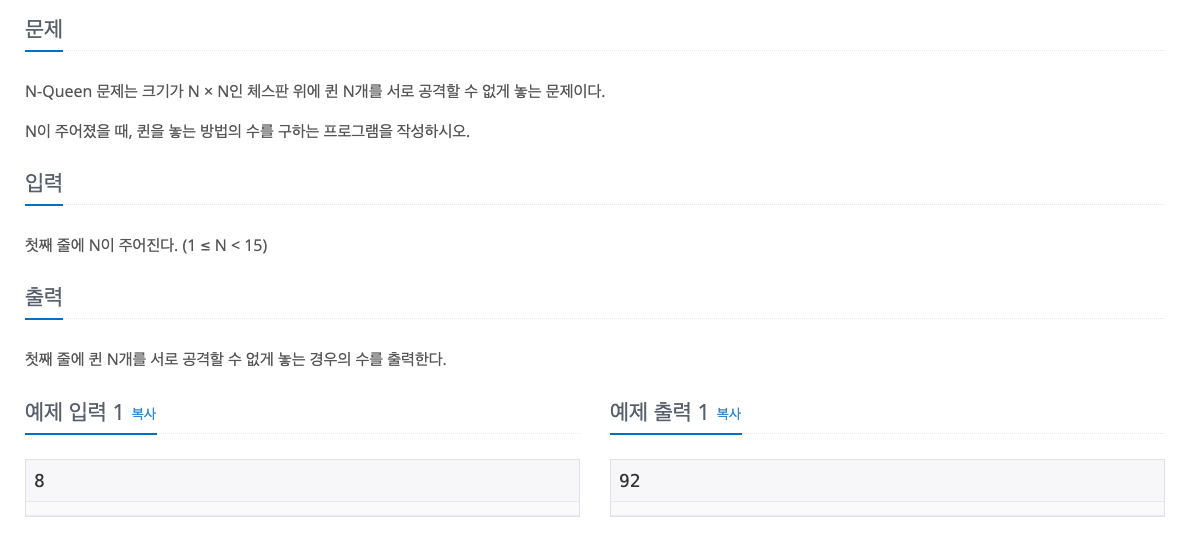
이 문제는 조건을 잘 이해하고, for 문과 변수를 적절히 활용하는 것이 포인트인 문제이다.
처음엔 행과 열 모두 for문을 사용해 돌리니까 무한 루프에 빠지게 되었다.
그래서 한가지를 dfs 함수의 변수로 주면서 돌리니까 해결되었다.
# 백트래킹 알고리즘 N-Queen
N = int(input())
# 크기 n짜리 배열을 생성해준다. 퀸 위치 (1,2) -> arr[1] = 2
visited = [0]*(N+1)
arr = []
count = 0
# 조건 1 - 같은 열이나 행에 놓지 않는다.
# 조건 2 - 사선으로 같은 줄에 놓지 않는다.
def dfs(n):
global count
if n == N+1:
count += 1
return
for j in range(1, N+1):
visited[n] = j
flag = True
for x in range(1, n):
if visited[n]==visited[x] or (n-x == abs(visited[n]-visited[x])):
flag = False
break
if flag:
arr.append([n,j])
dfs(len(arr)+1)
arr.pop()
dfs(len(arr)+1)
print(count)백준 14888번 - 연산지 끼워넣기
문제 링크 - https://www.acmicpc.net/problem/14888
N = int(input())
nums = list(map(int, input().split(' ')))
add, sub, mul, div = map(int, input().split(' '))
min_ans = 1e9
max_ans = -1e9
def solution(num, idx, add, sub, mul, div):
global max_ans, min_ans
if idx == N:
max_ans = max(max_ans, num)
min_ans = min(min_ans, num)
return
if add > 0:
solution(num + nums[idx], idx + 1, add - 1, sub, mul, div)
if sub > 0:
solution(num - nums[idx], idx + 1, add, sub - 1, mul, div)
if mul > 0:
solution(num * nums[idx], idx + 1, add, sub , mul -1, div)
if div > 0:
solution(int(num / nums[idx]), idx + 1, add, sub, mul, div -1)
solution(nums[0], 1, add, sub, mul, div)
print(max_ans)
print(min_ans)