
01. HTTP 리퀘스트 메시지를 작성한다
1) 탐험 여행은 URL 입력부터 시작한다
URL은 http:// 뿐만 아니라 엑세스 대상에 따라 ftp:~, file:~, mailto:~ 등 여러가지가 있다
다양한 url이 있는 이유
브라우저의 기능은 웹서에 엑세스하는 클라이언트, FTP클라이언트 (파일을 다운로드/업로드), 메일의 클라이언트 기능도 가지고 있다.
=> 브라우저는 몇 개의 기능을 겸비한 복합적인 클라이언트 스프트웨어
=> 여러 기능 중 어떤 것을 사용해서 데이터에 엑세스 하면 좋을 지 판단하기 위해 여러 종류의 url이 있는 것
엑세스 방법에 따라 url에 담을 수 있는 것: 서버의 도메인명, 액세스하는 파일의 경로, 메일 주소, 사용자명이나 패스워드, 서버측 포트번호 등
ex) 엑세스 대상이 웹서버: http 프로토콜을 사용하여 액세스, ftp 서버: ftp 프로토콜을 사용
=> url 맨 앞의 문자열을 엑세스 프로토콜 종류이다.
2) 브라우저는 먼저 URL을 해독한다
브라우저가 처음 하는 일: URL 해독
그리고나서 웹 서버에 보내는 리퀘스트의 메시지를 작성함
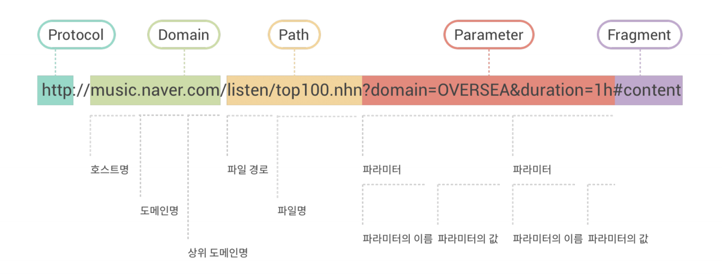
Protocol: URL의 맨 앞. 데이터 출처에 액세스하는 방법, 즉 프로토콜을 기록
//: 나중에 이어지는 문자열이 서버의 이름임을 나타냄
Domain: 웹서버명
/path: 데이터 출처(파일)의 경로명을 나타댐 (listen-디렉토리명, top100.nhn-파일명)
이후로는 생략 가능
3) 파일명을 생략한 경우
http://www.lab.cyber.co.kr/dir/ 과 같이 /로 끝나는 url의 경우
dir의 다음에 써야 할 파일명을 쓰지 않고 생략 한 것(오류는 아님)
파일명이 없으면, 어디에 엑세스해야 할지 모름
이 때를 대비해서 파일명을 미리 서버측에 설정해둔다.
=> index.html / default.htm
http://www.lab.cyber.co.kr/ 와 같이 도메인명만 쓴 url도 파일명을 생략한 것이므로
index나 default에 엑세스함
http://www.lab.cyber.co.kr 와 같이 /까지 생략되어 있으면
/index나 /default에 엑세스함
http://www.lab.cyber.co.kr/whatisthis 와 같은 경우, /가 없으므로 파일명 같지만 정확하지 않기 때문에 웹서버에 whatisthis 파일이 있으면 파일명으로 보고, whatisthis 디렉토리가 있으면 디렉토리명으로 본다
4) HTTP의 기본 개념
url 해독 > 어디에 엑세스 해야하는지가 판명 > http 프로토콜을 사용하여 웹서버에 액세스
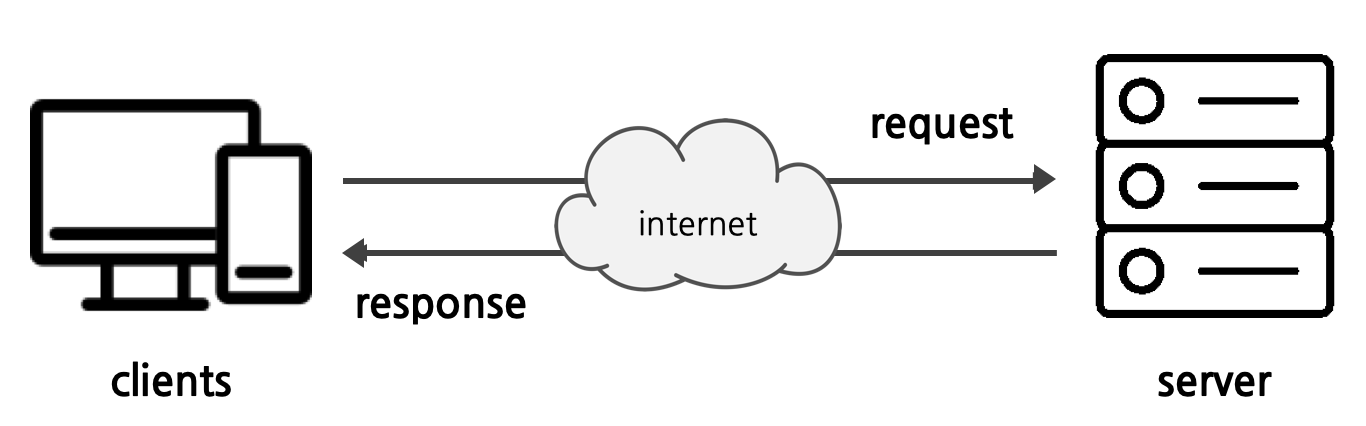
http프로토콜: 클라이언트와 서버가 주고받는 메시지의 내용이나 순서를 정한 것
From 클라이언트 to 서버
리퀘스트 메시지('무엇을', '어떻게해서' 하겠다는 내용 +a)
'무엇을'
= uri: 보통 페이지 데이터를 저장한 파일의 이름이나 CGI 프로그램의 파일명
ex) /dir1/file1/html 이나 gram1.cgi 또는 url을 그대로 쓰는 것도 가능
** CGI: 공통 게이트웨이 인터페이스(Common Gateway Interface)의 약어로, 웹서버와 외부 프로그램 사이에서 정보를 주고받는 방법이나 규약들을 말한다.
uri에는 다양한 액세스 대상을 쓸 수 있고, 이러한 액세스 대상을 통칭하는 말이 uri
'어떻게 해서'
= 메소드: 웹 서버에 어떤 동작을 하고 싶은지 전달
ex) uri로 나타낸 데이터를 읽고 싶다, 클라이언트측에서 입력한 데이터를 uri로 나타낸 프로그램에 전달하고 싶다,...
+a
= 헤더파일(보충 정보) 등
From 웹 서버 to 클라이언트
응답 메시지(웹 서버는 리퀘스트 메시지 내용을 해독해서 요구에 따라 동작하고 결과 데이터를 응답 메시지에 저장)
맨 앞부분에는 실행 결과가 정상 종료되었는지 또는 이상이 발생했는지 스테이터스 코드가 있음
ex) 404 Not Found
그 후 페더 파일과 페이지의 데이터가 이어짐
이 응답 메세지를 클라이언트에 반송
클라이언트에 도착한 응답 메시지 안에서 데이터를 추출하여 화면에 표시하면서 http의 동작이 끝남
5) HTTP 리퀘스트 메시지를 만든다
URL을 해독하고 웹 서버와 파일명을 판단하면 브라우저는 이것을 바탕으로 포맷에 맞춰 HTTP의 리퀘스트 메시지를 만든다.
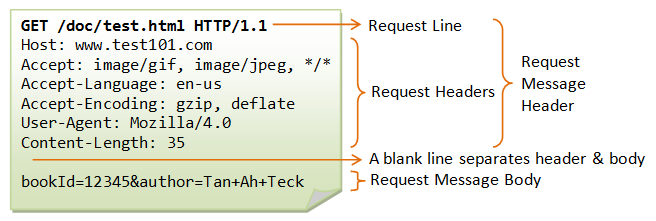
<메소드><공백><URI><공백><HTTP버전>
<필드명>:<필드값>
.
.
.
<공백 행>
<메시지 본문>
리퀘스트 메시지의 첫번째 행에는 리퀘스트 라인을 쓴다.
메소드 파일이나 프로그램의 경로명 http 버전의 사양
맨 앞에 있는 메소드가 중요한데 이를 통해 웹 브라우저는 웹서버에 어떻게 할 것인지를 전달한다. 이 한 행으로 리퀘스트의 내용을 대략 알 수 있다
리퀘스트 메시지의 두번째 행부터는 메시지 헤더를 쓴다
리퀘스트의 부가적인 정보를 나타낸다
날짜(Date), 클라이언트측이 취급하는 데이터의 종류, 언어(Accept-Language), 압축 형식, 클라이언트나 서버의 소프트웨어 명칭과 버전, 데이터의 유효기간이나 최종 변경 일시 등 다수의 항목
메시지 헤더 다음은 한 줄의 공백 행이다.
그 다음은 메시지 본문의 내용으로 메시지의 실제 내용이다.
클라이언트에서 서버에 송신하는 데이터, 폼 페이지에 입력한 데이터를 post 메소드로 웹 서버에 보낼 때 등에 데이터가 들어간다.
단, 메소드가 get인 경우 메소드와 uri만으로 웹 서버가 무엇을 할 지 판단할 수 있으므로 메시지 본문에 쓰는 송신 데이터는 아무것도 없다.
메소드가 post인 경우에는 폼에 입력한 데이터 등을 메시지 본문 부분에 쓴다
6) 리퀘스트 메시지를 보내면 응답이 되돌아온다
웹 서버에서 되돌아오는 응답 메시지의 포맷도 기본적인 개념은 리퀘스트 메시지와 같다.
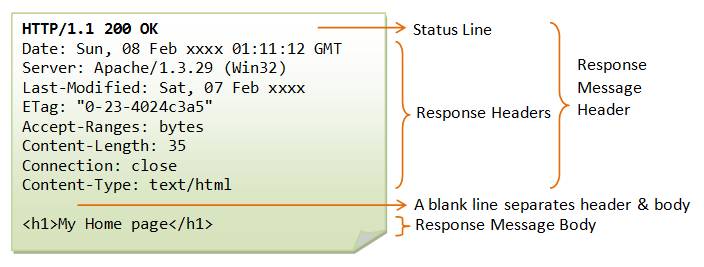
<HTTP 버전><공백><스테이터스 코드><공백><응답문구>
<필드명>:<필드값>
.
.
.
<공백 행>
<메시지 본문>
정상종료했는지, 오류가 발생했는지, 즉 리퀘스트의 실행 결과를 나타내는 스테이터스 코드와 응답 문구가 첫번째 행에 들어간다. 응답문구는 스테이터스 코드의 내용을 나타내는 짧은 설명문이다.
메시지 본문의 내용은 서버에서 클라이언트에 송신하는 데이터, 파일에서 읽은 데이터나 CGI 애플리케이션이 출력한 데이터가 들어간다. 메시지 본문은 바이너리 데이터이다.
응답 메시지가 되돌아오면, 그때부터 데이터를 추출한 후 화면에 표시하여 웹 페이지를 눈으로 볼 수 있다.
페이지가 문장으로만 되어 있으면 이것으로 끝이지만, 영상 등이 포함되어 있으면 계속 내용이 있다. 영상 파일을 나타내는 태그가 포함되어 있으므로 브라우저는 이 태그를 탐색하여 태그 자리를 우선 공백으로 두고, 이후에 다시 한 번 웹 서버에 액세스 하여 해당 영상 파일을 웹 서버에서 읽어와 남겨둔 공백에 표시한다. 이 때 리퀘스트 메시지를 만들어보내는데 url에 영상 파일의 이름을 적는다.
리퀘스트 메시지에 쓰는 uri는 한 개이므로 파일을 한번에 한개씩만 읽을 수 있다.
그래서 한 문장에 3개의 영상이 포함되어 있다면, 문장 파일을 읽는 리퀘스트, 각 영상 별 리퀘스트로 총 4회의 리퀘스트 메시지를 웹 서버에 보낸다.
필요한 파일을 판단하고 읽은 후 레이아웃을 정하여 화면에 표시하는 등 전체 동작을 조정하는 것도 브라우저의 역할이다.
웹서버는 단순히 하나의 리퀘스트에 하나의 응답을 돌려보낼 뿐...
