최근 nestJS와 graphQL을 이용하여 프로젝트를 만드는 중이다. 러닝커브가 상당히 높고 graphQL을 쓰기 위해선 ORM이나 각 모듈마다 추가적으로 설정해주어야 되는 것들도 꽤 있어서 까다로웠다. 그렇지만 이제는 어느정도 적응이 되었고 graphQL의 효용성을 실감하고 있다. graphQL을 사용하며 graphQL과 RESTful API 방식의 차이점을 정리해볼 필요성을 느껴 이 글을 쓴다. graphQL의 사용법을 간단하게 알아보고 graphQL의 특징을 상세히 살펴볼 것이다.
1. graphQL이란?
graphQL은 페이스북에서 개발한 데이터 질의어(쿼리언어)이다. 기존의 RESTful API와 비교하여 GraphQL은 클라이언트 측에서 요청한 데이터의 구조와 필요한 필드만을 선택적으로 받을 수 있어, 불필요한 데이터의 오버헤드를 줄일 수 있다. 또한 여러 요청을 하나로 병합하여 보낼 수도 있다. 이러한 특징으로 네트워크 사용량 최적화에 큰 이점이 있다.
2. graphQL의 사용법
rest-api에는 create, update, delete, read 등 용도에 따른 여러 요청 방식이 있지만 grapQL의 요청 방식은 두가지만 있다. 바로 query와 mutation이다. query는 데이터를 읽을 때 사용하는 요청이고 mutation은 데이터 생성, 수정, 삭제시 사용하는 요청이다. graphQL은 rest-api처럼 api 호출할 때 주소 형식을 쓰지 않고 함수 이름과 같은 형태로 사용한다. 예를 들면 아래와 같이 사용한다.
query {
fetchBoards {
number
writer
title
contents
}
}fetchBoards라는 api 요청을 보내고 있다. query 요청이니 데이터를 조회하는 요청이다. 조회하는 데이터를 선택적으로 지정할 수 있다. 위에서는 number, writer, title, contents 등의 데이터를 선택해서 조회하고 있는 것이다.
mutation {
createUser(
createUserInput: {
password: "1"
email: "1"
userName: "홍길동"
age: 30
}
) {
userId
userName
email
age
}
}위 요청은 mutation 요청으로 데이터를 생성함과 동시에 생성된 데이터 중 일부를 선택적으로 불러올 수 있다.
3. graphQL의 특징
아래 표는 graphQL과 rest-api의 차이를 요약하여 보여준다. rest-api와 비교하며 graphQL의 특징을 설명하겠다.
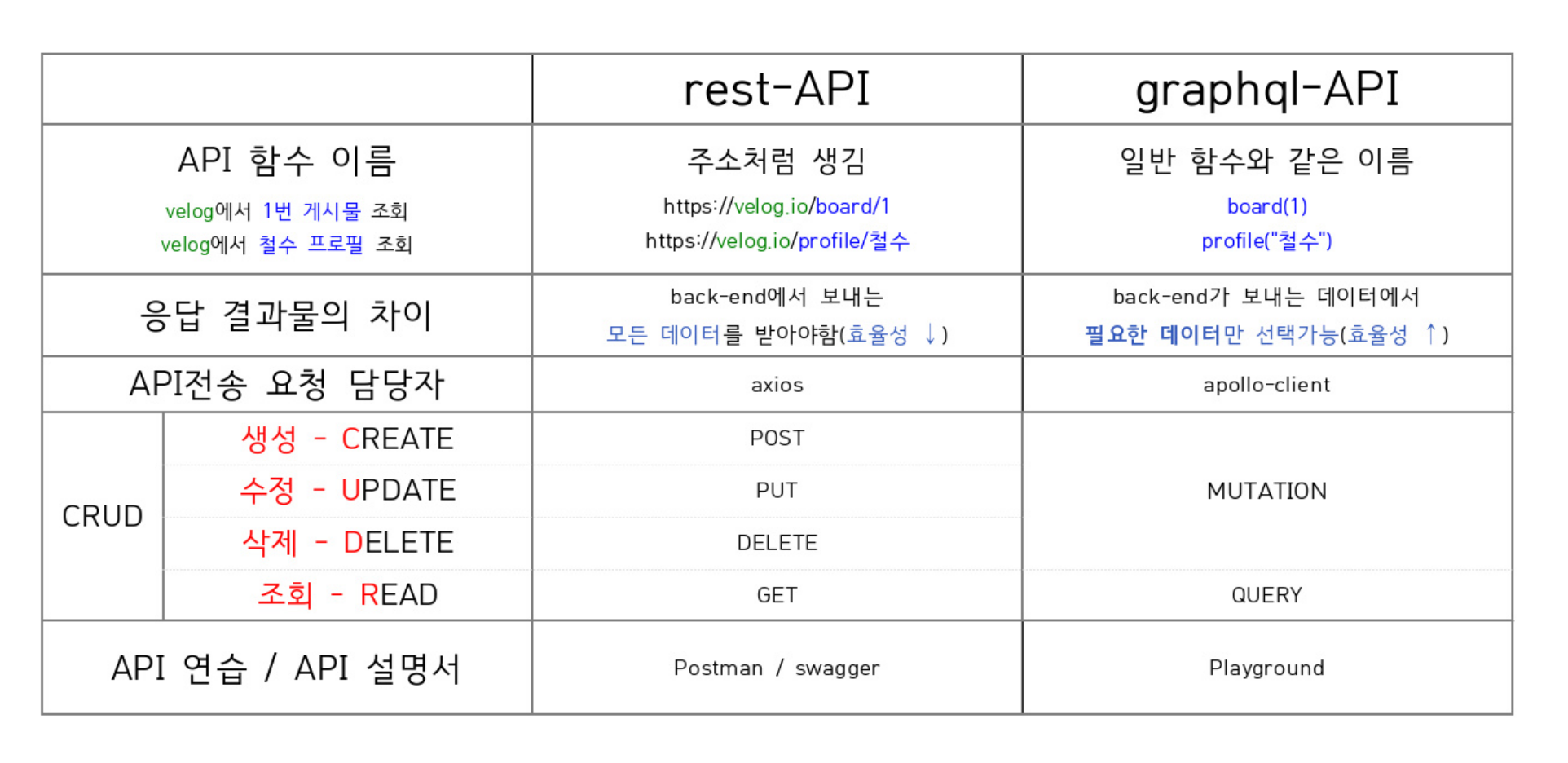
3-1. graphQL은 end-point가 하나다.
rest-api는 아래처럼 각 api 요청에 맞는 수많은 end-point가 필요하다.
POST /boards => 게시글 등록 함수: () => { }
GET /boards => 게시글 조회 함수: () => { }
GET /products => 상품 목록 조회 함수: () => { }하지만 graphQL은 모든 요청의 end-point는 POST /graphql이다. 이로 인해 graphQL은 엔드 포인트로 요청을 구분하지 않고 함수 이름과 같이 요청을 구분할 수 있어 더 직관적이고 편하다. 모든 요청의 end-point는 POST /graphql라는 것에서 알 수 있듯이 graphQL도 결국 rest-api와 같은 형식의 end-point를 가진다. 왜냐하면 graphQL도 rest-api를 가공해서 만들어진 것이기 때문이다.
3-2. 함수처럼 사용
graphQL은 함수처럼 사용할 수 있다. 일단 api 요청할 때 쓰는 요청의 이름이 함수 이름처럼 생겼다. 때문에 rest-api처럼 주소같은 이름을 길게 쓸 필요없이 함수 호출하듯 쓸 수 있다. 위의 mutation 예시처럼 소괄호 안에 필요한 매개변수들을 넣고 중괄호 안에 불러올 데이터들을 지정한다.
3-3. 응답 결과물의 차이
rest-api는 응답 결과로 백엔드 개발자가 만든 함수에서 보내주는 모든 데이터를 받아야만 한다. 반면에, graphQL은 백엔드 개발자가 만든 함수에서 필요한 데이터만 골라 받을 수 있다.
query {
user(id: 1) {
name
age
contactNumber
}
}위와 같은 요청을 수정하여
query {
user(id: 1) {
name
}
}name 데이터만 받아올 수 있는 것이다.
3-3. rest-api의 UnderFetching, OverFetching 문제 해결
3-3-1. UnderFetching 해결
rest-api에서는 특정 목적을 위해 여러 요청을 해야되는 경우가 많다. 예를 들면 하나의 페이지를 구성하는데 회원 정보, 게시글 목록, 상품 목록이 필요하다면, rest-api를 사용했을 때는 하나의 페이지를 완성하기 위해서 총 세번의 요청을 반드시 수행해야 된다. 이러한 문제를 UnderFetching이라 부른다. 아래처럼 user 데이터 요청과 posts 데이터 요청을 한번의 쿼리로 병합하여 요청할 수 있다. 물론 rest-api도 한번의 요청에 필요한 데이터를 다 불러오게 설정할 순 있지만 보통 각 api요청마다 불러올 수 있는 데이터를 세부적으로 쪼개어 놓는게 rest-api의 특징이기 때문에 보통 그렇게 하지 않는다.
query {
user(id: 1) {
name
posts {
title
content
}
}
}3-3-2. OverFetching 해결
OverFetching은 데이터 요청시 클라이언트에서 필요하지 않은 데이터까지 불러와지는 것이다. 이는 앞에서 계속 얘기했던 graphQL의 가장 큰 특징이자 이점으로 해결 가능하다. 예를 들어 게시글 목록을 조회하는 페이지를 만든다고 한다면 그 페이지에서는 게시글에 대한 모든 정보가 필요하진 않을 것이다. graphQL을 이용하면 게시글 테이블에서 클라이언트가 스스로 원하는 데이터만 불러올 수 있다.
query {
findPosts(id: 1) {
title
writer
}
}위처럼 post의 여러 데이터 중 필요한 것만 클라이언트에서 스스로 선택하여 불러올 수 있는 것이다.
이와 같은 특징들로 graphQL은 네트워크 통신시의 사용량을 최적화하여 효율성을 향상시킬 수 있다.
3-4. 타입 시스템
graphQL은 스키마를 통해 데이터의 구조를 정의하고, 이 스키마는 API가 어떤 종류의 객체를 반환하고, 객체는 어떤 필드를 가지며, 각 필드는 어떤 타입인지를 명시한다. 이 타입 정보는 쿼리 시에 자동으로 확인되며 이는 클라이언트가 예상하지 못한 데이터 타입이 반환되는 것을 방지하고, 쿼리를 작성하는 동안 타입 체크를 자동화함으로써 개발자의 작업을 더욱 편리하게 한다. 쿼리시 타입 정보를 자동으로 확인하기 위해 GraphQL Playground와 같은 도구를 활용하거나 서버에 스키마 정보를 요청하여 직접 받아볼 수도 있다. 이는 클라이언트가 스스로 api를 탐색하고 이해할 수 있도록 돕는다. 이또한 graphQL의 큰 이점이다.
3-5. 개발 도구 지원
graphQL 스키마와 타입 시스템 덕분에, 여러 개발 도구들이 가능해지며 이를 통해 개발 과정을 효율화할 수 있다. 예를 들면 위에서 설명한 자동 완성, 실시간 오류 강조 등을 제공하는 GraphQL Playground 같은 도구가 있다.
4. 결론
graphQL은 rest-api와 비교하여 이점이 상당히 많으며 안 쓸 이유가 없다고 볼 수도 있다. 하지만 러닝커브가 꽤 있고 간단한 프로젝트는 rest-api가 더 편리하다. 또 다른 회사에서 지원해주는 api가 rest-api 방식인 경우가 많기 떄문에 rest-api와 graphQL 둘 다 알고 있어야 할 것이다. graphQL도 개발을 위한 도구이니만큼 각자의 상황에 맞게 graphQL이 다른 방식과 비교하여 가장 쓰기 좋은 상황일 때 활용하여야 될 것이다.
