오늘의 목표 : 판다스 공부, 타이타닉 데이터 분석
판다스
판다스는 엑셀같은 스프레드시트 프로그램보다 연산을 빠르고 효율적으로 할 수 있다.
판다스의 특징
1. 빠르고 효율적이며 다양한 표현력을 갖춘 자료구조를 제공한다.
실세계 데이터 분석을 위해 만들어진 파이썬 패키지2. 다양한 형태의 데이터 처리에 적합하다.
이종 자료형의 열의 사진 테이블 데이터
시계열 데이터
레이블을 가진 다양한 행렬 데이터
다양한 관측 통계 데이터3. 시리즈와 데이터프레임이라는 핵심 구조를 제공한다.
시리즈 : 1차원 구조를 가진 하나의 열
데이터프레임 : 복수의 열을 가진 2차원 데이터4. 다음과 같은 데이터 처리 작업을 잘 한다.
결측 데이터 처리
데이터 추가 삭제 (새로운 열의 추가, 특정 열의 삭제 등)
데이터 정렬과 다양한 데이터 조작판다스로 어떤 일을 할 수 있나?
데이터 불러오기 및 저장하기
- 파이썬 리스트, 딕셔너리, 넘파이 배열을 데이터프레임으로 변환할 수 있다.
- 판다스로 CSV 파일이나 TSV 파일, 엑셀 파일 등을 열 수 있다.
- URL을 통해 웹 사이트의 CSV 또는 JSON과 같은 원격 파일 또는 데이터베이스를 열 수 있다.
데이터 보기 및 검사
- df.mean()로 모든 열의 평균을 계산할 수 있다.
- df.corr()로 데이터프레임의 열 사이의 상관 관계를 계산할 수 있다.
- df.count()로 각 데이터프레임 열에서 null이 아닌 값의 개수를 계산할 수 있다.
필터, 정렬 및 그룹화
- df.sort_values()로 데이터를 정렬할 수 있다.
- 조건을 사용하여 열을 필터링할 수 있다.
- groupby()를 이용하여 기준에 따라 몇 개의 그룹으로 데이터를 분할할 수 있다.
데이터 정제
- 데이터의 누락 값을 확인할 수 있다.
- 특정한 값을 다른 값으로 대체할 수 있다.
CSV
CSV는 쉼표로 구분한 변수의 약자이다.
기본적으로 쉼표를 이용하여 데이터를 구분한다. 하지만 쉼표가 아닌 어떤 구분자라도 사용이 가능하다. 즉 탭이나 콜론, 세미콜론 등의 구분자도 사용할 수 있다.
CSV 데이터의 내용을 읽어보자
파이썬 모듈 csv는 CSV reader와 CSV writer를 제공한다. 두 객체 모두 파일 핸들을 첫 번째 매개 변수로 사용한다. 필요한 경우 delimiter 매개 변수를 사용하여 구분자를 제공할 수 있다. 디폴드 구본자는 쉼표(.)이다.
코드
import csv # 판다스가 아닌 파이썬 csv 모듈을 사용함
f = open('d:/data/weather.csv') # CSV 파일을 열어서 f에 저장한다.
data = csv.reader(f) # reader() 함수를 이용하여 읽는다.
for row in data:
print(row)
f.close()결과
['일시', '평균기온', '최대풍속', '평균풍속']
['2010-08-01', '28.7', '8.3', '3.4']
['2010+08-02', '25.2', '8.7', '3.8']
['2010-08-03', '22.1', '6.3', '2.9']
...판다스의 데이터 구조 : 시리즈와 데이터프레임
시리즈 : 1차원, 레이블이 붙어있는 1차원 벡터
데이터프레임 : 2차원, 행과 열로 되어있는 2차원 테이블, 각 열은 시리즈로 되어 있다.
행의 이름을 인덱스, 열의 이름을 칼럼스라 부른다.
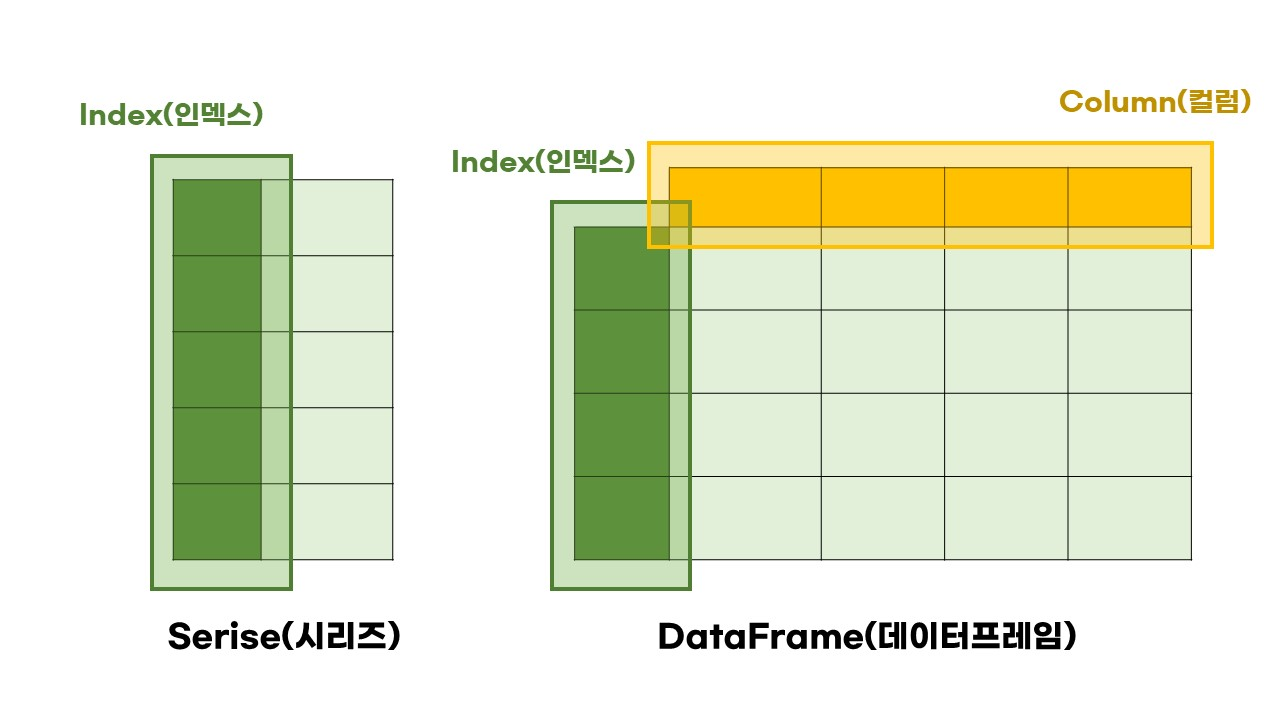
시리즈
동일 유형의 데이터를 저장하는 1차원 배열이다.
데이터 프레임
시리즈 데이터가 여러 개 모여서 표와 같은 2차원 구조를 갖는 것이다. 이 데이터프레임은 판다스가 데이터를 분석할 때 사용하는 기본적 틀이다.
하나의 데이터 프레임은 행과 열로 구분할 수 있는데, 하나의 행은 여러 종류의 데이터를 담고 있다. 모든 행은 동일한 형태의 자료 배치를 가진다. 그리고 각 열은 동일한 자료형을 가진 시리즈임을 알 수 있다.
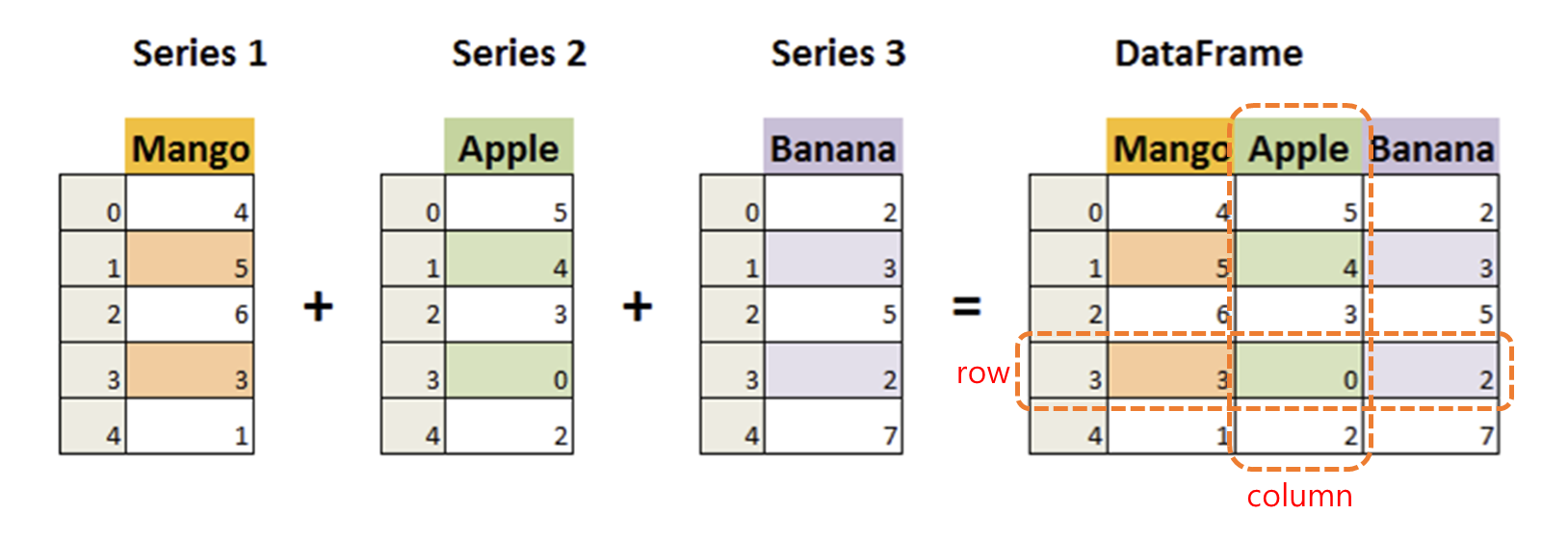
타이타닉 데이터 분석
타이타닉 데이터 불러오기
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
plt.rc('font', family='Malgun Gothic')
plt.rc('axes', unicode_minus=False)
import warnings
warnings.filterwarnings(action='ignore')
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
submission = pd.read_csv("gender_submission.csv")타이타닉 결측치 확인
1. train data 결측치 확인
train.isnull().sum()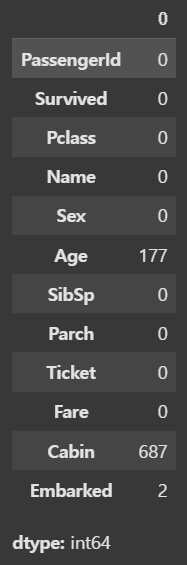
train data에는 Age, Cabin, Embarked 컬럼에 결측치가 존재
2. test data 결측치 확인
test.isnull().sum()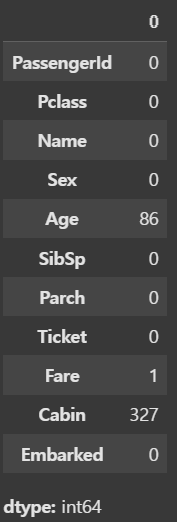
test data에는 Age, Fare, Cabin 컬럼에 결측치가 존재
3. 결측치 시각화
# 결측치 시각화
import missingno as msno
msno.matrix(train, figsize=(12, 5))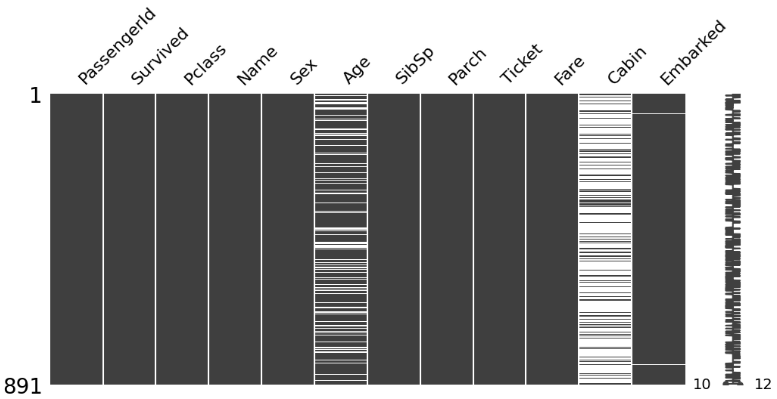
target 변수(Survived)
# 생존비율 확인
train["Survived"].value_counts()
plt.figure(figsize=(8, 5))
labels = ['사망', '생존']
train['Survived'].value_counts().plot.pie(explode=[0, 0.08],
shadow=True,
autopct='%1.1f%%',
labels=labels)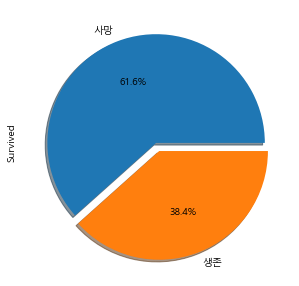
사망 비율은 61.6%, 생존 비율은 38.4%로 사망한 탑승객의 수가 더 많다.
성별(Sex)
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].set_title("성별 탑승자 수 \n", size=15)
sns.countplot(x="Sex", data=train, ax=axes[0])
axes[1].set_title("성별 생존자 수 \n", size=15)
sns.countplot(x="Sex", hue="Survived", data=train, ax=axes[1])
axes[1].legend(labels = ['사망', '생존'])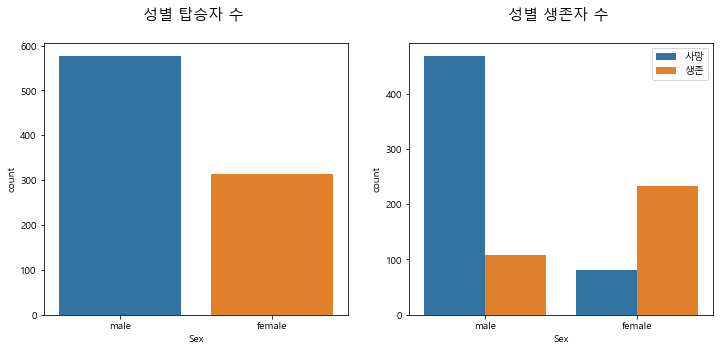
탑승자은 남성이 여성보다 많지만 생존자는 여성이 훨씬 높다는 것을 알 수 있다.
티켓 클래스(Pclass)
train[['Pclass', 'Survived']].groupby('Pclass').mean()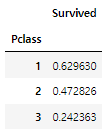
1등석의 생존률은 약 63%, 2등석의 생존률은 약 47.3%, 3등석의 생존률은 약 24.2%이다.
3등석 탑승객이 가장 많이 사망했다.
나이(Age)
나이 데이터
train['Age'].describe()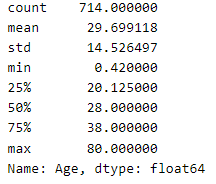
탑승객의 평균 나이는 30세이다.
나이 분포
plt.figure(figsize=(8, 5))
sns.distplot(train['Age'], bins=25)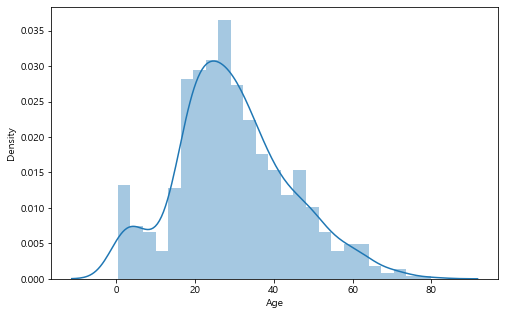
20~40세가 가장 많은 것을 볼 수 있다.
