Data Frame
- pd.Series()
- index, value- pd.DataFrame()
- index, value, column
표준 정규 분포에서 샘플링한 난수 생성
data = np.random.randn(6,4)
data결과
array([[ 1.0596305 , 0.99747143, 0.60812025, 1.24650776],
[ 1.1670468 , 0.25991248, 2.17937082, 0.01444101],
[-0.98164731, -0.40103702, -0.97495438, 0.1525716 ],
[-1.49557875, 1.25831222, -1.22641321, -0.10352021],
[ 0.11937387, 0.85537738, 0.00833698, -0.15012135],
[-0.55412965, 0.70938068, -0.42676451, 1.61909564]])
pd.DataFrame(data=, index=, columns=)
df = pd.DataFrame(data, index=dates, columns=['A','B','C','D'])
df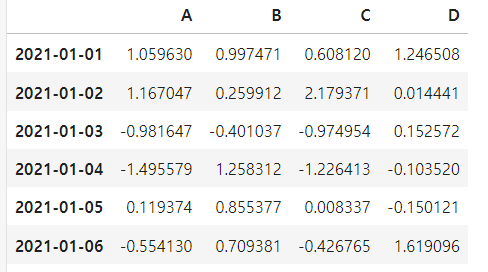
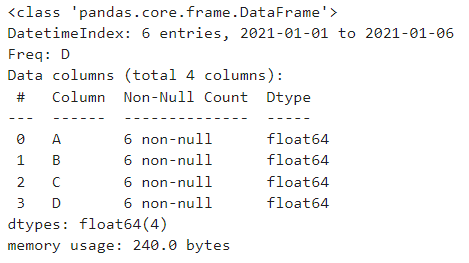
.info() : 데이터 프레임의 기본 정보 확인
결과
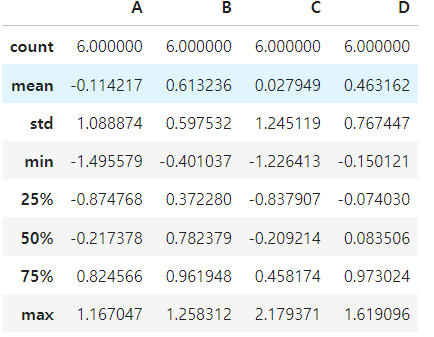
.describe() : 데이터 프레임의 기술통계정보확인
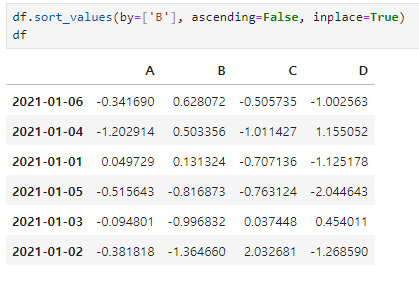
sort_values(by, axies, ascending=,inplce=) : 데이터 정렬
Data 선택
df['A'] 한개 컬럼 선택
df.A : 컬럼이 알파벳일 때만 가능
df[['A','B']] : 두 개 이상 컬럼 선택할 때는 리스트에 담아야함
offset index
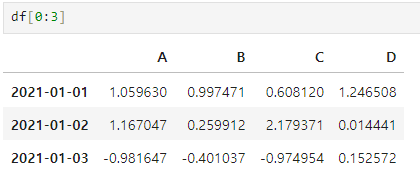
- [n:m] : n부터 m-1까지
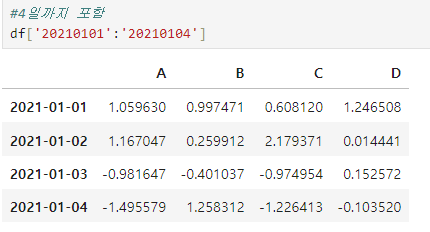
- 인덱스나 컬럼의 이름으로 slice하는 경우는 끝을 포함합니다.df['20210101':'20210104']
.loc[] : location
index이름으로 특정, 행, 열을 선택
df.loc[:,['A','B']]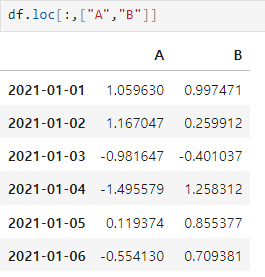
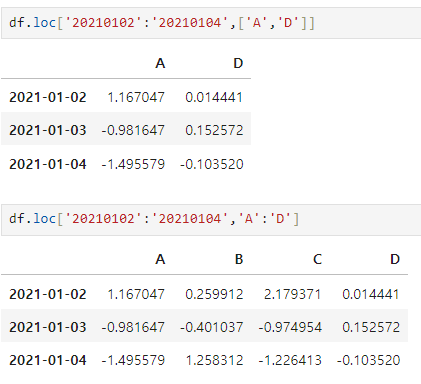
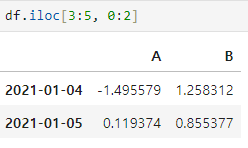
iloc : inter location
- 컴퓨터가 인식하는 인덱스 값으로 선택
- 앞이 인덱스, 뒤가 컬럼
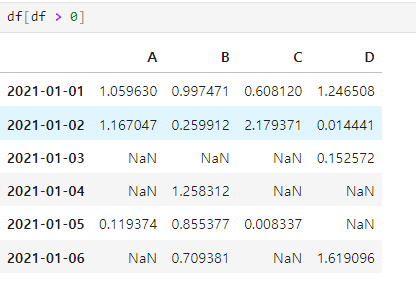
Condition
A 컬럼에서 0보다 큰 숫자(양수)만 선택
df['A'] > 0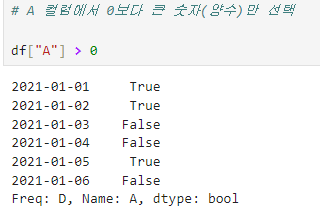
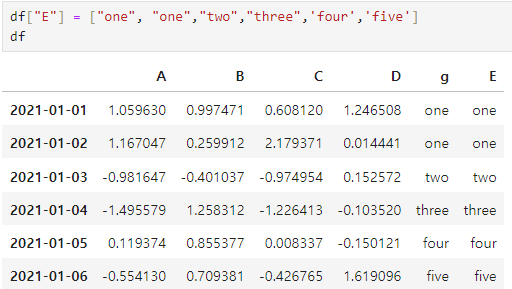
컬럼 추가
- 기존 컬럼이 있으면 수정
- 기존 컬럼이 없으면 추가
isin() : 특정 요소가 있는지 확인
df['B'].isin(['two','five'])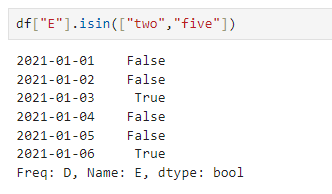
마킹하면 데이터를 보여줌
df[df['B'].isin(['two','five'])]
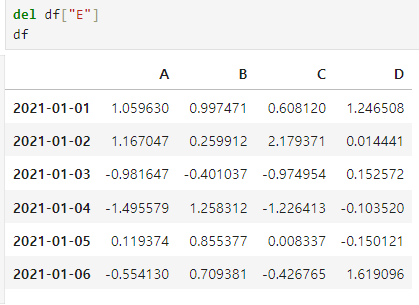
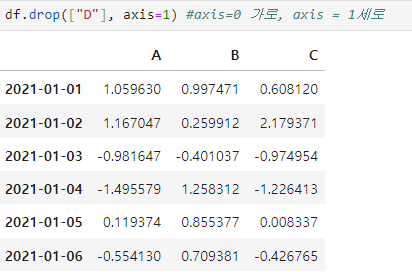
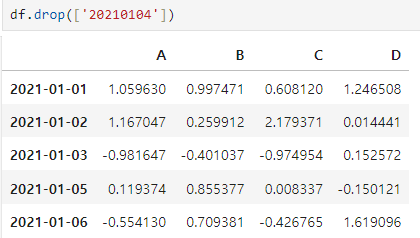
특정 컬럼 제거
-del
-drop
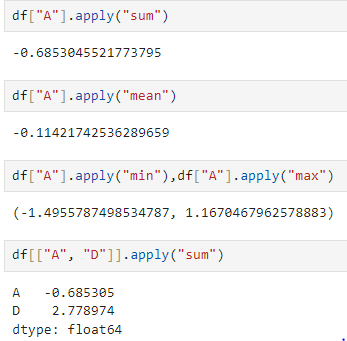
apply
- 일괄적으로 함수를 적용해줌
- sum, mean, min, max, np.sum, np.std...
def plusminus(num):
return "plus" if num > 0 else "minus"df["A"].apply(lambda num : "plus" if num > 0 else "minus")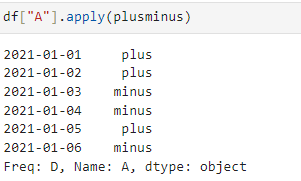
자료 출처: 제로 베이스 데이터 취업 스쿨

Hi Welcome