Database 반정규화를 통한 Paging 처리 API 성능 659배 개선
제목의 659배라는 파멸적인 숫자를 보자마자 인덱스 관련 성능 개선임을 추측하신 분들이 계실지 모르겠습니다. 저도 쿼리 튜닝, pool 사이즈 조정, Caching등 다양한 성능 개선을 프로젝트에서 진행해보았지만 이 정도 파멸적인 수치는 인덱스 관련 개선에서 밖에 볼 수 없더군요. 맞습니다. 이번에 개선한 내용은 인덱스를 사용하지 못하는 병목 구간을 인덱스를 적절히 사용할 수 있도록 바꾼 내용입니다.
반정규화라고 이번에 처음 알게 되었는데요, 반정규화를 통해 Paging 처리 API 성능 개선한 이야기 이번 포스팅에서 소개드리겠습니다.
문제 상황
투룻 서비스에는 여행기 컨텐츠들의 무한스크롤 기능이 있습니다. 그런데 데모데이를 대비하여 당시 스프린트 목표에 대한 QA를 진행하는 과정에서 여행기 콘텐츠 페이징 처리 API가 평균 응답 시간 1.5초 최악의 경우 2초로 성능 저하가 발생하는 것을 확인할 수 있었습니다. 페이지 번호가 커지면 커질수록 버벅거림은 심해졌고 무한스크롤 기능은 버벅거리며 UX를 저하시키게 되었습니다.
cf) 페이지 번호가 커지면 커질 수록 왜 무한스크롤 기능이 더 느려졌을까?
투룻에서는 여행기 컨텐츠 페이지를 제공할 때 Offset 기반의 페이징을 활용하고 있습니다. 쿼리에 LIMIT절이 사용되게 되는 것이죠. 하지만 LIMIT절은 주의해야 할 점이 있습니다. 주의점 관련해서 RealMySQL 8.0의 11.4.5절에서 설명하고 있는데 해당 설명을 차용하겠습니다.
SELECT * FROM salaries ORDER BY salary LIMIT 20000000,10;위와 같은 쿼리를 생각해봅시다. 위의 쿼리에서 사용된 LIMIT 절은 salaries 테이블을 처음부터 읽으면서 20000010건의 레코드를 읽은 후 20000000건은 버리고 마지막 10건만 사용자에게 반환합니다. 실제 사용자의 화면에는 10건만 표시되지만 MySQL 서버는 2000010건의 레코드를 읽어야하기 때문에 쿼리가 느려지는 것입니다.
이와 같은 문제는 커서 기반의 NO OFFSET 페이징, 혹은 커버링 인덱스등을 활용하여 성능을 향상시킬 수 있습니다.
논의 되었던 해결 방안들
당시 FE 개발자들이 화면 관련 이슈들을 쳐내고 있던 상황이라 API 명세 변경 없이, 그리고 애플리케이션 중단 없이 성능 향상이 필요했었습니다. 목표 수치는 10만 건의 여행기가 저장된 상태에서 500ms의 응답속도 성능을 방어하는 것입니다. 이를 어떻게 해결할 수 있을지 백엔드 팀원들이 모여 회의했는데요, 도출되었던 솔루션들은 다음과 같습니다.
1. 커서 기반 페이징 (NO OFFSET)
첫번째로 커서 기반의 페이징입니다. 커서 기반 페이징은 offset 대신 커서를 사용하여 마지막으로 읽은 데이터의 ID 또는 키를 기준으로 다음 데이터를 가져오도록 쿼리를 변경하는 것입니다. 커서 기반 페이징은 Offset 기반 페이징보다 성능이 우수하며 특히 페이지 번호가 커질수록 효율적입니다. 다만 이 해결책은 API 명세를 바꿔야하기에 프론트엔드 협업 인력을 필요로 하기에 진행될 수 없었습니다.
사실 무한 스크롤이라고 하면 커서 기반의 페이징으로 구현되는 것이 조금 더 자연스러워보이는데요, 처음에 Offset 기반의 페이징으로 설계할 때는 해당 지식이 충분치 않아 미리 정해진 설계가 아쉬운 지점입니다.
cf) 무한 스크롤 기능에 커서 기반의 페이징이 어울리는 이유
무한 스크롤은 제한 없이 존재하는 모든 컨텐츠에 대한 페이징을 제공하는 기능입니다. OFFSET이 커질수록 불리한 오프셋 기반의 페이징은 무한 스크롤과는 궁합이 잘 맞지 않죠. 무한 스크롤은 커서 기반의 페이징과 더 잘 맞습니다.
cf) OFFSET 기반의 페이징은 단점만 있는가?
OFFSET기반의 페이징은 구려서 쓰이지 않는 기술일까요? 그렇지 않습니다. 사용자가 1 page에서 15 page로 건너뛰려면 OFFSET기반의 페이징이 사용되어야 합니다. 흥미로운 사실이 있는데요, 구글이나 쿠팡 등에서 검색을 하여 페이징을 해보면 최대 16~17개의 페이지만 제공한다는 사실을 확인하실 수 있습니다. OFFSET 기반의 페이징 약점은 도메인 정책으로 약화시키고 이의 장점을 충분히 활용하는 회사들이 이미 존재하고 있음을 알 수 있습니다.
2. 연관관계 N+1 문제를 해결하도록 쿼리 튜닝
여행기 정보를 가져올 때 여행기 작성자 정보, 여행기 태그 정보 등의 연관 엔티티 조회를 위한 추가 쿼리가 발생하고 있었습니다. N+1문제가 발생하고 있던 것이죠. 이를 해결하여 쿼리를 개선할까 고민도 했었지만 제 경험상으로 페치 조인으로 N+1문제를 해결한다고 해도 80%이상의 성능 개선을 달성했던 경험이 없어 목표 수치를 달성할 수 없는 개선이라고 생각했습니다. 성능 향상 폭이 크지 않을 것으로 생각되어 해당 해결책은 반려되었습니다.
3. Redis등 캐시 시스템 활용
Redis등의 캐시 시스템을 활용하여 성능을 올리는 방법입니다. 하지만 우아한테크코스 프로젝트는 월 50$의 인프라 비용 제약이 있었기 때문에 현재 완전관리형 캐시나 인스턴스 추가가 어려워 Redis를 추가하기 어려웠습니다. 또한 팀 내에 Redis를 다뤄본 인원이 없어 학습 비용이 꽤 높을 것이라고 생각하기도 했고요.
Local 캐시등을 사용해볼 수도 있었지만 현재 저희 서버 노드는 다중화되어 있었기에 글로벌 캐시로 지킬 수 있는 정합성이 필요한 상태였습니다. 마찬가지로 캐시 시스템 활용을 통한 해결책은 반려되었습니다. (개인적으로 캐시를 도입하자고 팀원들에게 어필했었는데요, 적용하지 못한게 아쉬워 우아한테크코스가 끝난 이후 비용 제약이 없어졌을 때 Redis를 도입해보았습니다. 여기에서 저의 Redis 도입기를 살펴보실 수 있습니다)
4. 커버링 인덱스
페이징 되는 여행기 정보에 대해 커버링 인덱스를 생성하여 조회 성능을 올리는 방법입니다. 커버링 인덱스를 사용하려면 인덱스가 포함하는 데이터로만 원하는 결과를 조회할 수 있어야 합니다. 하지만 여행기 페이지 처리 응답 API에서 필요한 모든 정보를 인덱스에 담을 수 없었습니다. 왜냐하면 좋아요 개수를 계산하는 부분은 다른 테이블에서 COUNT 쿼리를 활용해 계산하고 있었기 때문입니다.
5. 데이터베이스 스키마 및 인덱스 최적화 (채택)
4번째 솔루션을 논의 할 때 팀원들과 함께 깨달은 것이 있는데 인덱스를 적절히 이용하지 못했기 때문에 쿼리 성능이 나쁘게 나온다는 것이었습니다. 현재 좋아요 개수를 계산하기 위해 좋아요 테이블과 조인하고 COUNT를 수행하는 부분이 쿼리에서 병목 지점이 된다는 것을 깨닫고 좋아요 개수에 인덱스를 걸 수 있으면 성능이 비약적으로 빨라질 수 있음 역시 확인하게 되었습니다.
오후에 팀원들과 한참 회의를 진행하고 있었을 때였는데요, 우아한테크코스 캠퍼스에서 지나가던 고수 크루를 붙잡아 저희의 결론에 대해 이야기해줬더니 반정규화라는 키워드에 대해 소개해주었습니다. 반정규화는 하나 이상의 테이블에 데이터를 중복해 배치하는 최적화 기법입니다. 여행기 테이블에 좋아요 개수를 중복하여 저장하면 인덱스를 걸 수 있을 것이고 기존에 발생하던 쿼리도 깔끔하게 고쳐낼 수 있었기에 저희에게 딱 맞는 해결책이라고 생각하여 채택했습니다.
반정규화 시작
앞서 간단히 설명드렸습니다만 반정규화에 대해서 조금 더 자세히 설명드려보겠습니다.
반정규화(Denormalization)는 데이터베이스 설계에서 성능을 개선하거나 특정 요구사항을 만족시키기 위해 정규화된 데이터 구조를 일부러 깨뜨리는 작업을 의미합니다. 즉, 중복 데이터를 추가하거나, 데이터를 합치는 방식으로 정규화로 인해 발생할 수 있는 성능 문제를 해결하는 방법입니다.
반정규화를 통해 중복된 데이터를 저장하거나 조인을 줄임으로써, 복잡한 쿼리 실행 시간을 줄이고 응답 속도를 개선할 수 있고 데이터를 미리 준비해 둠으로써 쿼리를 단순화할 수 있습니다. 정규화된 구조에서 조인과 OFFSET/LIMIT 등의 사용으로 성능이 저하될 수 있는 부분을 해결하는 해결책으로 자주 사용됩니다. 이어지는 글에서 저희 프로젝트의 예시로 반정규화를 살펴보시겠습니다.
반정규화 없이 여행기 컨텐츠 페이지를 조회하는 쿼리
SELECT
SELECT
t1_0.id,
t1_0.author_id,
t1_0.created_at,
t1_0.deleted_at,
count(t1_0.id) cnt,
t1_0.modified_at,
t1_0.thumbnail,
t1_0.title
FROM
travelogue t1_0 inner join travelogue_like tl on t1_0.id = tl.travelogue_id
WHERE
t1_0.deleted_at IS NULL
group by t1_0.id
ORDER BY
cnt DESC
LIMIT 5 OFFSET 0;위의 쿼리는 반정규화되지 않은 테이블에서 여행기 페이지를 조회하는 쿼리입니다. 각 여행기의 좋아요 개수를 계산하기 위해서 좋아요 테이블과 조인한 테이블을 여행기로 GROUP BY하고 count()순으로 ORDER BY하고 있는 모습을 확인하실 수 있죠.
반정규화된 테이블에서 여행기 컨텐츠 페이지 조회 쿼리
SELECT
t1_0.id,
t1_0.author_id,
t1_0.created_at,
t1_0.deleted_at,
t1_0.like_count,
t1_0.modified_at,
t1_0.thumbnail,
t1_0.title
FROM
travelogue t1_0
WHERE
t1_0.deleted_at IS NULL
ORDER BY
t1_0.like_count DESC
LIMIT 5 OFFSET 0;위의 쿼리는 반정규화된 테이블에서 여행기 페이지를 조회하는 쿼리입니다. 여행기 테이블 내부에 like_count 칼럼이 존재하는 것을 확인하실 수 있죠. 데이터를 중복 저장한 덕분에 JOIN연산과 GROUP BY, ORDER BY, COUNT() 집계연산이 쿼리에서 사라진 것을 확인하실 수 있습니다.
반정규화된 테이블에서는 좋아요 개수가 칼럼으로 저장되기 때문에 이제 인덱스를 지정할 수 있죠. 좋아요 개수에 대해서 인덱스를 건다음 실행계획을 살펴보니 인덱스가 사용되고 있는 것을 확인할 수 있었습니다.
+--+-----------+-----+----------+-----+-------------+-------------------------+-------+----+----+--------+--------------------------------+
|id|select_type|table|partitions|type |possible_keys|key |key_len|ref |rows|filtered|Extra |
+--+-----------+-----+----------+-----+-------------+-------------------------+-------+----+----+--------+--------------------------------+
|1 |SIMPLE |t1_0 |null |index|null |travelogue_like_count_idx|9 |null|505 |10 |Using where; Backward index scan|
+--+-----------+-----+----------+-----+-------------+-------------------------+-------+----+----+--------+--------------------------------+반정규화를 도입하고 인덱스를 활용하니 성능은 눈에 띄게 향상되었습니다. 팀원이 성능 측정 관련해서 정리해준 자료를 공유드립니다.
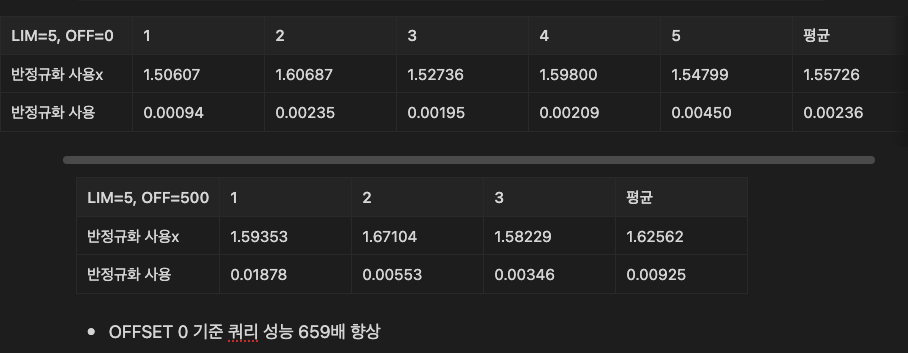
반정규화를 적용할 때 추가로 고려한 지점
지금까지 반정규화를 도입한 이후 인덱스를 생성하여 쿼리 성능 향상을 이뤄낸 저희 프로젝트 사례에 대해 설명드렸습니다. 반정규화를 진행하면서 고려한 지점들이 추가적으로 있는데요, 이어지는 글에서 설명드리겠습니다.
역순 스캔
Real MySQL 8.0의 8.3.6.1.1에서는 인덱스 참조 방향에 대해서 얘기합니다.(또 당신입니까 GOAT...) 인덱스는 항상 오름차순으로 정렬돼 있지만 인덱스를 최댓값부터 거꾸로 읽으면 내림차순으로 값을 가져올 수 있음을 설명하고 있죠.
좋아요 순 여행기 데이터를 정렬할 때 저희는 내림차순으로 정렬해야 합니다. 오름차순 인덱스(INDEX DEFAULT)를 생성하고 이를 거꾸로 읽도록 하는 것도 가능합니다.
하지만 책에서는 오름차순 인덱스에서 역순으로 정렬하는 쿼리가 정순 정렬 쿼리보다 약 28% 더 느릴 수 있음을 이야기하고 있고 이를 위해 내림차순 인덱스라는 개념이 있다는 것을 소개하고 있어요. 책의 내용을 참고해서 저희도 성능 개선점을 최대화 하기 위해 내림차순 인덱스를 별도로 생성했습니다.
내림차순인덱스는 다음처럼 생성될 수 있습니다.
CREATE INDEX (userid DESC, score DESC);데이터 마이그레이션
스키마 변화가 발생했지만 저희의 목표는 애플리케이션 중단 없이 성능을 개선하는 것입니다. 마침 저희 프로젝트에서는 Flyway를 사용하고 있었고 마이그레이션 플랜을 설립하여 데이터를 마이그레이션 하였습니다.
ALTER TABLE travelogue ADD like_count BIGINT;
UPDATE travelogue AS t LEFT JOIN (SELECT travelogue_id, COUNT(*) AS like_count
FROM travelogue_like
GROUP BY travelogue_id) AS tl ON t.id = tl.travelogue_id
SET t.like_count = COALESCE(tl.like_count, 0);위의 sql은 데이터 마이그레이션 스크립트입니다. travelogue 테이블에 like_count 칼럼을 추가하고 좋아요 테이블을 통해 각 여행기의 좋아요 개수를 계산한다음 업데이트 하는 동작을 확인하실 수 있습니다.
Flyway 스크립트를 통해 애플리케이션 중단 없이 마이그레이션을 진행할 수 있었습니다.
cf) 안전한 마이그레이션 플랜
Flyway 스크립트를 활용해서 애플리케이션 중단 없이 데이터를 마이그레이션 할 수 있었지만 되돌아보면 아쉬운 점도 있습니다. 데이터 마이그레이션은 마이그레이션 시점에 발생한 요청도 잘 처리될 수 있도록, 그리고 잠금 전파 범위가 넓지 않도록 데이터 분할을 고려했어야 했는데 그걸 고려하지 못하고 하나의 스크립트로 Naive하게 처리한게 아쉬운 것이죠.
위의 마이그레이션 플랜은 상당히 단순한 버전으로 많이 naive합니다. 만약 대량의 데이터를 마이그레이션 해야 한다면 마이그레이션 범위를 지정하고 이를 단계적으로 처리하는 것이 중요합니다. 다음은 보다 안전한 마이그레이션을 위한 일반적인 절차들입니다.
1. 데이터 백업
마이그레이션 전 반드시 기존 데이터를 백업합니다. 이는 마이그레이션 중 데이터 손실이나 오류 발생 시 복구할 수 있는 기반을 마련합니다.
2. 마이그레이션 범위 지정
전파되는 잠금과 데이터 정합성을 고려하여 범위를 나누어 마이그레이션 범위를 나눕니다. 우아한테크코스 코치님에게 들은 이야기인데 마이그레이션은 점진적으로 수행되어야하기에 일반적으로 2주가 넘는 시간이 마이그레이션에 소요되기도 한다고 합니다.
3. 데이터 중복 처리 과도기
마이그레이션이 진행되는 기간동안 마이그레이션 대상 테이블과 기존의 테이블에 정보를 함께 저장하는 과도기 단계가 설계되어야합니다. 구버전과 신버전 API 사이의 호환성을 위함입니다.
4. 마이그레이션 데이터 검증
마이그레이션 후, 데이터의 정확성을 검증합니다. 새로 추가된 like_count 값이 travelogue_like 테이블과 일치하는지 확인하는 스크립트를 작성합니다.
반정규화의 단점
반정규화를 통해 많은 성능 향상을 얻어낸 만큼 치트키인 것 같다는 생각도 듭니다. 하지만 silver bullet은 없는 법, 모든 기술에는 tradeOff가 있을테니 반정규화의 단점도 조사하고 고려해보았습니다.
1. 쓰기 성능 저하
반정규화된 스키마에서는 데이터를 업데이트 시 관련된 여러 테이블이나 레코드에 대해 동시에 작업해야 할 수 있습니다.
실제로 저희도 여행기에 좋아요를 누르는 기능에 두가지 엔티티를 수정해줘야했죠.
@Transactional
public void likeTravelogue(Travelogue travelogue, Member liker) {
boolean notExists = !travelogueLikeRepository.existsByTravelogueAndLiker(travelogue, liker);
if (notExists) {
TravelogueLike travelogueLike = new TravelogueLike(travelogue, liker);
travelogueLikeRepository.save(travelogueLike);
travelogue.increaseLikeCount();
}
}위의 메서드를 확인하면 좋아요를 누른 경우 travelogue의 좋아요 수 변경 감지와, travelogueLikeRepository가 함께 수정되고 있는 모습을 확인하실 수 있습니다. 두번 써야 하니 저희는 쓰기 성능을 타협해야합니다. (인덱스도 쓰기 성능을 타협합니다)
대부분의 온라인 트랜잭션 서비스에서는 보통 읽기 요청이 80% 쓰기 요청이 20% 정도라고 하는데요, 이를 고려하면 쓰기 성능을 타협하고 읽기 성능을 챙기는 현재의 결론이 어색하지만은 않은 것 같습니다. 특히 저희의 좋아요 순 여행기 컨텐츠 정렬 페이징은 메인페이지의 기능으로 호출이 매우 잦아 반정규화 도입이 더욱 합리적인 것 같다는 개인적인 소회입니다.
2. 데이터 중복으로 인한 정합성 취약점
반정규화가 갖는 가장 큰 리스크 중 하나는 데이터 정합성(Consistency) 문제입니다. 데이터가 여러 곳에 중복 저장됨에 따라 수정·삭제 시점마다 모든 위치에서 동일하게 변경을 적용해야 하며, 이를 제대로 지키지 못하면 중복된 데이터들이 서로 다른 값을 갖게 될 수 있습니다. 이러한 문제를 해결하기 위해 주기적으로 싱크를 맞추는 방식과 데이터베이스 상태 업데이트시 잠금을 이용하는 방법이 있습니다. 저희는 주기적으로 Sync를 맞추는 Sync Scheduling 방식을 사용하여 정합성 취약점에 대비했습니다.
3. 데이터 무결성 관리 부담
중복된 데이터가 많아지게 되면 데이터를 업데이트하거나 삭제할 때 모든 중복 데이터를 동기화해야 합니다. (해당 부분은 캐시와 맥락이 비슷할 수도 있겠군요). 현재 저희 프로젝트에는 중복된 데이터가 단 두곳에서만 존재하며 트랜잭션으로 쉽게 정합성을 유지할 수 있기 때문에 큰 단점으로 와닿지 않아 반정규화를 그대로 도입했습니다.
