페이징 응답 Caching을 위한 Redis 도입기
투룻 프로젝트 메인페이지는 다음과 같습니다.
여행기 컨텐츠들은 메인페이지에서 오프셋 기반의 페이징을 통해 무한 스크롤 형태로 제공되고 있죠. 그리고 페이징 api는 저희 서비스의 대문 기능인 만큼 요청 횟수가 api 중 가장 많습니다.
Grafana로 보는 api 요청 빈도
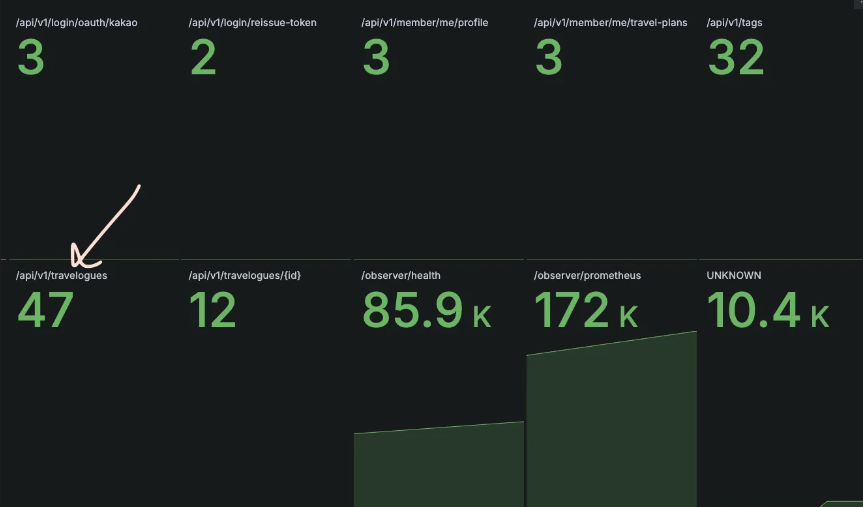
요청 횟수가 가장 많은 만큼 페이징 api는 성능 민감도가 높습니다. 저희 투룻팀에서도 페이징 api의 성능 중요성을 인지하고 성능을 개선하기 위해 다음과 같은 다양한 시도를 진행해왔습니다.
- 여행기 컨텐츠의 좋아요 수를 계산하기 위한 JOIN 및 COUNT 비용을 절약을 위한 좋아요 수 반정규화
- ORDER BY DESC 절에서의 인덱스 역순 스캔 방지를 위한 내림차순 인덱스 생성
- 여행기 컨텐츠 커버링 인덱스 적용 (인덱스 운용 검토 중)
- 오프셋이 아닌 커서 기반 페이징 (데이터가 많지 않은 상태에서 성능 향상이 의미 있을 지 현재 연구 중)
하지만 아직까지 페이징 쿼리는 여타 api들 보다 느린 성능을 보입니다.
Grafana로 보는 Request Average Duration
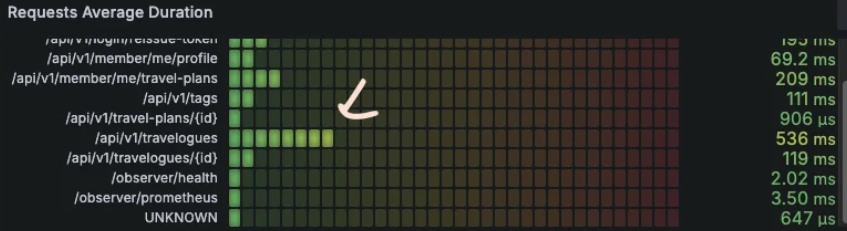
500ms대의 성능이면 충분하다고 생각하시는 분들이 있을지도 모르겠습니다. 페이징 api 성능이 500ms 정도라면 저라도 기다릴 수 있을 것 같긴한데요, 하지만 활성 사용자수가 늘어나고 동시 접속자가 많아지는 경우는 위의 응답 시간이 크게 늘어날 수 있습니다. 병목 현상이 심해지고 최악의 경우 애플리케이션 가용성이 무너질 수도 있겠습니다.
그래서 평소 Redis에 대한 학습도 해보고 싶었겠다, 팀원들의 동의를 얻고 페이징 api에서 Redis를 활용한 캐시를 운용해보기로 했습니다. 결과적으로 Jmeter를 통해 테스트해보았을 때보다 캐시를 적용하지 않았을 때 대비 Redis 캐시를 적용했을 때 약 91프로의 성능 향상을 달성할 수 있었는데요, 중요 api의 성능을 향상시켜서 뿌듯했던 작업이었습니다.
Redis 작업을 진행하면서 고려했던 지점들이 많습니다. 이번 포스팅은 Redis로 페이징 응답을 캐시하는 기능을 작업하면서 저와 팀원들의 고려지점들을 소개드리는 포스팅입니다. 쓰다 보니 글이 좀 길어졌네요. 각 목차가 독립적인 주제를 다루며 고려 지점들이 열거된 형태의 포스팅이니 목차를 참고하시면 효율적일 듯 합니다.
어떤 데이터를 캐싱하려고 하는가?
저희가 캐싱하려고 하는 대상 데이터는 좋아요 순으로 여행기를 조회했을 때 많은 사용자들에게 조회되는 상위 4개 페이지입니다. 저희는 서비스를 런칭하는 데모데이에서 실 사용자들을 만나본 경험이 있습니다. 사용자 행동 패턴을 바로 옆에서 확인해볼 수 있는 좋은 경험이었는데요, 사용자들은 메인 페이지에서 상위 4개의 페이지까지만 스크롤 하는 경우가 많았습니다.
상위 4개의 페이지는 여러 사용자들에게 같은 형태로 제공되는 중복 데이터이면서 쿼리 복잡도가 비교적 높습니다. 그리고 무엇보다도 인기 상위 컨텐츠들은 쉽게 변하지 않죠. 캐싱을 도입하기에 적합한 데이터 성질을 가지고 있어서 저희는 선술했던 상위 4개의 페이지 응답을 캐싱하였습니다.
팀에서 도출한 캐싱 요구사항
- 좋아요 순으로 조회하는 상위 4개의 페이지를 캐싱
캐시 전략
결론 먼저 말씀드리면 Look Aside + Write Around 조합을 선택하였습니다. (캐시 전략에 어떠한 것들이 있는지 궁금한 분들은 다음을 참조하셔도 좋을 것 같습니다)
해당 전략을 요약드리면 정합성 이슈에 대한 완벽한 안전 장치를 타협하는 대신 성능을 최대화 하는 전략인데요, 저희 도메인에서 인기글을 조회하는 기능은 정합성보다는 성능이 중요함에 팀원들 모두가 공감하여 해당 전략을 선택했습니다.
정합성 이슈에 대해 어느 정도 타협을 했다고 말씀드렸지만 캐시 도입을 고려할 때는 항상 데이터의 유실 또는 정합성이 일부분 깨질 수 있음을 고려해야합니다. 특히 캐시를 무효화하는 전략은 충분한 고민이 필요하죠.
"컴퓨터 과학에서 어려운 것은 단 두 가지입니다: 캐시 무효화, 그리고 이름짓기 입니다." - 필 칼슨(Phil Karlson)
저희는 캐시 무효화 전략에 대해 추가적으로 고민한 결과, 다음과 같은 전략들을 생각해냈습니다.
-
스케줄러를 통해서 정기적으로 좋아요 수 상위 컨텐츠들을 캐싱, 무효화
장점: 간단, 레디스 메모리 자원 사용률 통제 가능, 갱신 주기 통제 가능
단점: 갱신 주기 사이의 실시간성이 캐시에 보장되지 않음, 정기적으로 DB 부하 발생 가능 -
TTL + LFU
장점: 요청이 없는 경우 캐시가 갱신 되지 않음 → 요청 빈도에 따른 리소스 절약
단점: TTL 동안 최신의 데이터가 반환되지 않고 캐시간 중복이나 유실 데이터 발생 가능 -
버퍼를 통한 좋아요 수 배치 업데이트 시 캐시 무효화 및 갱신
장점: 실시간 성 높음 이벤트 트리거마다 갱신 됨으로
단점: 여행기 상세 조회 로직 복잡도 상승, 구현 복잡도 높음 -
마지막 페이지의 마지막 여행기 좋아요수를 임계값으로 해당 좋아요 수 이상을 가진 여행기 정보가 수정될 때 캐시 무효화
장점: 실시간 성 높음
단점: 좋아요, 좋아요 취소, 여행기 삭제 로직 복잡도 상승 및 성능 손실
저희는 실시간성이 높고 정합성 이슈를 해결할 수 있는 4번째 접근 방식을 선택했습니다. 3번 해결책도 충분히 좋아보이고 고려 대상입니다만 버퍼를 활용한 좋아요 수 배치 업데이트는 다른 팀원이 아직 개발 중입니다. 작업이 완료되면 3번 전략과 4번을 비교하는 회의를 진행해볼 것 같군요.
어떤 캐시를 사용할 것인가?
꼭 레디스가 아닐 수도 있습니다. 저희가 궁극적으로 얻고자 하는 것은 캐싱을 통한 페이징 api의 성능 향상이니깐요. 저희는 Redis를 선택하긴 했습니다만 저희 팀에서 어떤 솔루션들이 고려되었는지 한번 살펴보시죠.
Local 캐시 (Caffeine Cache || Ehcache || HashMap)
현재 투룻 프로젝트는 2개의 WAS 인스턴스가 있고 앞단에 ALB(Application Load Balancer)를 위치시킨 인프라 구조를 운용하고 있습니다. 이러한 구조에서 Local 캐시를 사용하면 각 노드 별로 독립적인 캐시를 유지하게 됩니다.
Local 캐시는 개별 WAS 인스턴스의 메모리에 데이터를 저장하여 캐시를 관리하기에 매우 빠른 데이터 접근을 가능하게 합니다. 하지만 각 노드가 독립적으로 캐시를 유지하기에 다음의 문제들이 발생할 수 있습니다.
- 일관성 문제: 동일한 요청에 대해 노드 간 다른 응답이 내려갈 가능성 있음
- 중복 데이터: 노드마다 동일한 데이터를 캐시에 저장하게 됨으로 메모리 사용률이 비효율적
- 관리 복잡성: 캐시 동기화 등에서 모든 노드를 관리해야 함
Global 캐시 (Redis || Memcached)
글로벌 캐시는 Redis나 Memcached 같은 외부 캐시 저장소를 활용하여 모든 노드가 동일한 캐시 데이터를 공유하도록 설계됩니다. 데이터 접근 속도가 네트워크 비용으로 인해 Local 캐시에 비해 다소 느리긴 합니다만 로컬 캐시의 일관성문제, 메모리 효율성, 관리 복잡성 문제를 해결할 수 있죠.
분산 환경에서 Local 캐시를 운용하면서 발생할 수 있는 문제점들은 쉽게 넘어갈 수 없는 문제들입니다. 그래서 저희는 글로벌 캐시를 도입하기로 결정했습니다.
Redis vs Memcached
| 특징 | Redis | Memcached |
|---|---|---|
| 데이터 구조 | 문자열, 해시, 리스트, 셋, 정렬된 셋, 비트맵, 하이퍼로그로그 등 지원 | 문자열 기반 (단순 키-값 쌍) |
| 영속성 | RDB 스냅샷 또는 AOF(Append-Only File) 방식으로 지원 | 영속성 없음 |
| 메모리 관리 | LRU(Least Recently Used) 및 메모리 최적화 정책 다양 | LRU 방식으로 오래된 데이터 삭제 |
| 분산 환경 지원 | 클러스터링 기능 제공 (Redis Cluster) | 클라이언트 기반 샤딩 방식 |
| 스레드 처리 | 단일 스레드 기반 (Non-blocking I/O로 높은 처리량) | 멀티 스레드 기반 (병렬 처리 가능) |
| 사용 사례 | 세션 관리, 실시간 데이터 처리, 순위표, 메시지 브로커 등 | 단순 캐싱, 읽기 중심의 트래픽 처리 |
Memcached는 단순 명료한 캐싱을 지원하지만 Redis 보다 지원하는 기능이 약합니다. 지원하는 기능이 Redis가 더 많지만 그렇다고 성능이 월등히 차이나는 것도 아니죠. 무엇보다 Redis는 자료가 많고 스프링에서의 호환도 Memcached보다 뛰어납니다.
그리고 무엇보다 저희는 기존에 Caffeine Cache를 운용하고 있었습니다. Spring Cache Abstraction은 Redis, EhCache, Caffeine 등 일부 캐시 시스템을 지원하는데, 캐시 매니저만 갈아끼워 코드 변경을 최소화하며 Redis 캐시를 적용하기 위해 저희는 Redis Cache를 선택했습니다.
여담으로 Redis docs를 둘러보다가 재밌는 글을 발견했는데요, 레디스와 Memcached를 레디스가 직접 비교한 글입니다. https://redis.io/compare/memcached/ 레디스가 Memcached보다 지원하고 있는 기능이 더 많음을 어필하고 있네요. (official diss..?)
영속화 옵션 선택 (No Persistence)
캐시의 역할만 수행하기 위해서는 영속화 옵션은 크게 중요하지 않을 수 있습니다. 하지만 캐시 서버가 모종의 이유로 죽고 다시 켜졌을 때 워밍업된 상태로 캐싱 기능을 제공하려면 캐시로 Redis를 이용하는 경우에도 영속화 옵션이 유의미할 수 있죠. 공식 홈페이지에서 캐싱의 경우 No Persistence 옵션이 사용될 수 있다고 소개하고 있는데 저희 역시 굳이라는 생각이 들어 영속화 옵션은 껐습니다.
Redis의 영속화 옵션이 궁금하신 분들은 다음 docs를 참조하실 수 있습니다. 아래는 docs 내용을 학습하고 제가 정리해본 표에요
https://redis.io/docs/latest/operate/oss_and_stack/management/persistence/
| 특성 | RDB (Snapshotting) | AOF (Append-Only File) | 영속화 옵션 사용 안 함 |
|---|---|---|---|
| 데이터 저장 방식 | 일정 간격으로 데이터 스냅샷을 생성하여 디스크에 저장 | 모든 쓰기 작업(WRITE)을 로그 형식으로 기록 | 데이터를 메모리에만 저장 |
| 복구 속도 | 빠름 | 느림 | 복구 불가능 |
| 데이터 손실 위험 | 마지막 스냅샷 이후의 변경 사항 손실 가능 | 최근 기록된 명령 이후 최소 데이터 손실 가능 | Redis 종료 시 모든 데이터 손실 |
| 디스크 사용량 | 상대적으로 적음 | 더 많음 (쓰기 작업이 많을수록 증가) | 디스크 사용 없음 |
| 쓰기 성능 | 높음 (스냅샷 생성 시 성능 저하 가능) | 낮음 (디스크에 지속적으로 기록 필요) | 매우 높음 (디스크 IO 없음) |
| 읽기 성능 | 매우 높음 | 매우 높음 | 매우 높음 |
| 구현 복잡성 | 간단 | 복잡 (동기화, 파일 압축, 로그 관리 필요) | 간단 |
| 적용 예시 | 주기적으로 상태를 저장해도 되는 시스템 | 데이터 변경 로그가 중요한 시스템 | 데이터 손실이 허용되는 캐싱 전용 시스템 |
| 장점 | - 복구가 빠름 - 디스크 사용량이 적음 | - 데이터 변경 로그로 세밀한 복구 가능 - 덜 빈번한 스냅샷 가능 | - 최고의 성능 - 유지보수 용이 |
| 단점 | - 최근 데이터 손실 가능 - 스냅샷 중 성능 저하 | - 디스크 IO 부담 - 복구 속도가 느림 | - 데이터 손실 위험 |
캐시를 구현하자
이제 캐시를 구현하는 과정을 설명드리겠습니다. 캐시를 구현하는 과정은 크게 RedisCacheManager를 설정하고 AOP 기반의 Spring Cache Abstraction을 타겟 메서드에 지정하는 것으로 나뉩니다. 먼저 RedisCacheManager 설정입니다.
RedisCacheManager 설정
@Configuration
public class CacheConfig {
private static final Duration CACHE_TTL = Duration.ofMinutes(30);
@Bean
public CacheManager cacheManager(RedisConnectionFactory connectionFactory) {
return RedisCacheManager.builder(connectionFactory)
.cacheDefaults(getRedisCacheConfiguration())
.cacheWriter(RedisCacheWriter.nonLockingRedisCacheWriter(connectionFactory, BatchStrategies.scan(1000)))
.transactionAware()
.build();
}
}CacheWriter의 BatchStrategies 설정
위의 코드를 살펴보면 BatchStrategies를 설정하는 부분을 확인하실 수 있습니다. 이는 캐시를 쓰는 과정에서 O(N) 명령어인 KEYS 대신 SCAN을 배치 전략에 맞게 사용하도록 유도하는 기능을 수행합니다.
레디스는 싱글 스레드 기반 구조입니다. 그렇기에 레디스 서버를 오랜시간 블록할 수 있는 O(N) 명령들을 조심해야 하죠. 대표적인 O(N) 명령어는 KEYS가 있습니다. Redis는 대안으로써 SCAN을 제안합니다. 이는 전체를 지정한 수만큼 잘라서 청크별로 수행하기 때문에 Redis 서버를 오랜 기간 block하는 문제를 방지할 수 있습니다. 레디스 공식 홈페이지에서도 해당 부분을 설명하고 있는데요, BatchStrategies 설정을 한 것은 이를 의식한 처리임을 말씀드립니다.
레디스 공식 홈페이지 KEYS -> SCAN
Since these commands allow for incremental iteration, returning only a small number of elements per call, they can be used in production without the downside of commands like KEYS or SMEMBERS that may block the server for a long time (even several seconds) when called against big collections of keys or elements.
However while blocking commands like SMEMBERS are able to provide all the elements that are part of a Set in a given moment, The SCAN family of commands only offer limited guarantees about the returned elements since the collection that we incrementally iterate can change during the iteration process.
nonLockingRedisCacheWriter(...)
캐시 쓰기 작업이 락을 사용하지 않도록 설정합니다. 이 방식은 여러 스레드가 동시에 캐시에 접근할 때 락을 사용하지 않기 때문에 성능이 개선될 수 있습니다. 그러나 락이 없으면 경쟁 상태나 데이터 일관성 문제를 신중하게 고려해야 합니다. java doc에서도 이러한 non locking 처리가 maximum performance를 aim하지만 overlapping을 초래할 가능성이 있음을 알려주고 있습니다. 저희는 데이터 페이징 api의 일관성 및 정합성 중요성이 낮고 성능 중요성이 높다고 판단하여 nonLocking을 선택했습니다.
DefaultCacheWriter java doc
- {@literal non-locking} aims for maximum performance it may result in overlapping, non-atomic, command execution for
- operations spanning multiple Redis interactions like {@code putIfAbsent}. The {@literal locking} counterpart prevents
- command overlap by setting an explicit lock key and checking against presence of this key which leads to additional
- requests and potential command wait times.
TransactionAware
transactionAware()는 캐시가 트랜잭션을 인식할 수 있도록 설정합니다. 이 옵션을 활성화하면, Redis 캐시가 Spring의 트랜잭션 관리와 연동되어, 트랜잭션이 커밋될 때 캐시도 커밋되고 롤백될 때 캐시도 롤백됩니다. 이는 캐시 일관성을 유지하는 데 도움이 되어 채택했습니다.
CacheManager 전체 코드
@Configuration
public class CacheConfig {
private static final Duration CACHE_TTL = Duration.ofMinutes(30);
@Bean
public CacheManager cacheManager(RedisConnectionFactory connectionFactory) {
return RedisCacheManager.builder(connectionFactory)
.cacheDefaults(getRedisCacheConfiguration())
.cacheWriter(RedisCacheWriter.nonLockingRedisCacheWriter(connectionFactory, BatchStrategies.scan(1000)))
.transactionAware()
.build();
}
private RedisCacheConfiguration getRedisCacheConfiguration() {
SerializationPair<String> keySerializationPair = SerializationPair.fromSerializer(new StringRedisSerializer());
SerializationPair<Object> valueSerializationPair = SerializationPair.fromSerializer(
new GenericJackson2JsonRedisSerializer(getObjectMapperForRedisCacheManager())
);
return RedisCacheConfiguration.defaultCacheConfig()
.serializeKeysWith(keySerializationPair)
.serializeValuesWith(valueSerializationPair)
.entryTtl(CACHE_TTL)
.disableCachingNullValues();
}
private ObjectMapper getObjectMapperForRedisCacheManager() {
ObjectMapper objectMapper = new ObjectMapper();
SimpleModule pageModule = new SimpleModule();
pageModule.addDeserializer(PageImpl.class, new PageDeserializer());
pageModule.addDeserializer(Sort.class, new SortDeserializer());
objectMapper.registerModules(new JavaTimeModule(), pageModule);
objectMapper.activateDefaultTyping(
BasicPolymorphicTypeValidator.builder().allowIfBaseType(Object.class).build(),
DefaultTyping.EVERYTHING
);
return objectMapper;
}
}Spring Cache Abstraction을 타겟 메서드에 지정
캐시를 위한 CacheConfig 작성이 완료되었고 이제는 Spring Cache Abstraction을 활용해 원하는 캐싱을 타겟 메서드에 지정합니다.
@Cacheable(
cacheNames = TRAVELOGUE_PAGE_CACHE_NAME,
key = "#pageable",
condition = "#pageable.pageNumber <= " + MAX_CACHING_PAGE + " && " +
"#filterRequest.toFilterCondition().emptyCondition && " +
"#searchRequest.toSearchCondition().emptyCondition && " +
"#pageable.sort.toString() == 'likeCount: DESC'"
)
@Transactional(readOnly = true)
public Page<TravelogueSimpleResponse> findSimpleTravelogues(
TravelogueFilterRequest filterRequest,
TravelogueSearchRequest searchRequest,
Pageable pageable
) {
TravelogueFilterCondition filter = filterRequest.toFilterCondition();
SearchCondition searchCondition = searchRequest.toSearchCondition();
Page<Travelogue> travelogues = travelogueService.findAll(searchCondition, filter, pageable);
return travelogues.map(this::getTravelogueSimpleResponse);
}주의 PageImpl 역직렬화 실패
PageImpl을 역직렬화 할때 기본 생성자의 부재로 역직렬화가 실패합니다. 이를 해결하기 위해 다음의 두가지 대안이 있습니다.
- 기본 생성자가 있는 WrapperClass 구현
- Deserializer 커스터마이징
저희는 WrapperClass를 구현하는 것이 기술 종속적인 클래스를 만든다고 생각했습니다. 또한 캐싱 대상이 되는 메서드만 반환타입이 달라져야 하는 명세의 전파가 팀원들에게 어려울 것이라고 생각하기도 했죠. 그래서 저희는 Deserializer를 커스터마이징하는 방식을 택했음을 알려드립니다.
local에서는 레디스를 어떻게 하지?
테스트의 경우는 Testcontainers가 적용되어 있어 통합테스트를 구축하기 쉬웠습니다. 다만 로컬 환경에서 레디스를 설정할 지 정해야 했는데요, 선택지는 다음 두가지가 있었습니다.
- 로컬에서 Redis를 직접 운용
- EmbeddedRedis 라이브러리를 이용
Embedded Redis의 경우 애플리케이션 내에서 Redis를 실행할 수 있도록 도와주지만 라이브러리의 업데이트가 6년전에 끝났고 레디스 2.x 버전까지만 업데이트 되어 사용에 우려되는 부분이 있었습니다. 적용을 시도해보았는데 개인적으로는 라이브러리 사용성이 좋지는 않더군요. (사용 api는 간단하고 직관적이지만, 예외 메시지가 불친절하다는 소회입니다 ^^;) 그래서 로컬에서 Redis를 사용하는 방식을 선택했습니다. 로컬에서 운용해야 하는 외부 서비스가 점점 많아지는데 docker-compose 파일을 후에 작성하게 될 수도 있겠네요.
Redis 모니터링
레디스는 인메모리 데이터 저장소로 메모리 관리가 중요합니다. Redis를 maxmemory까지 쓰게 되면 지속적인 Key eviction이 발생하면서 memory 단편화가 심해질 수 있죠. 이러한 맥락을 아직 만나보지는 못했지만 모니터링 할 수 있는 대시보드가 이후에 꼭 필요할 듯 하여 모니터링 시스템을 구축하였습니다. 팀에서 기존에 운용하고 있던 Grafana 대시보드에 레디스를 추가하였습니다. (블로그를 참고하여 작업했습니다)
지표 수집 파이프라인: redis -> redis exporter -> prometheous -> Grafana
대시보드 템플릿 id: 11835
캐싱 대상 클래스 명세 변경 시 캐시 evict
캐싱이 잘 적용되었나 생각해보다가 캐싱하고 있는 대상 객체의 명세가 바뀌게 되면 저장되어 있는 캐시는 evict 되어야 함이 떠올랐습니다. 그리고 이를 자동화할 수 있는 방법이 없나 페어와 함께 찾고 생각해보았죠. 많은 방안이 떠오르지는 않더군요. 결론부터 말씀드리면 자동 evict은 구현하지 않았습니다. 어떤 방법들이 고려되었는지 소개는 드려보겠습니다.
Cache Key에 Method Signature 정보를 포함
Spring에서 제공되는 Cache KeyGenerator를 사용하는 방식입니다. reflection을 통해 반환 타입의 정보를 해싱하여 Key에 추가하는 것이죠. 이 경우 개발자가 별도로 신경쓰지 않아도 반환 타입이 변경되면 Key가 변경되어 이전 cache는 더 이상 사용되지 않습니다. 사용되지 않는 캐시는 TTL 혹은 LFU에 따라서 메모리에서 삭제되겠죠. 원하던 동작입니다. 하지만 해당 솔루션은 reflection을 사용한다는 점과 구현 복잡도의 단점때문에 섣불리 선택하지 못했습니다.
EventListener를 사용해 Application이 실행될 때마다 Cache Evict
메서드의 시그니처(반환 타입)이 변경됐다면 새로 배포가 실행될 수 밖에 없습니다. 즉, Application이 새로 시작될 수 밖에 없는 것이죠. 이런 점을 이용해 Application 구동시마다 Cache를 비운다면 구버전과 신버전의 캐시 충돌을 막을 수 있습니다. 하지만 이는 배포 상황에 한정됩니다. 만약 특정 WAS 노드가 장애 상황으로 reboot한다면 캐시는 비워져야 할 필요가 없음에도 비워질 수 있습니다. 그리고 명세 변경이 캐시에 영향을 주지 않는 경우에도 캐시가 비워질 수 있죠. 저희가 원하는 지점을 pin point로 잡지 못하는 해결책이라 이 역시 적용이 꺼려졌습니다.
저희가 판단하기에는 두 방법 다 어색한 것 같아요. reflection을 남용하거나 다른 노드가 캐시를 잘 쓰고 있는데 굳이 Global Cache evcit하는 과정은 가용성 측면에서 나쁘다고 생각한 것이죠. 캐시 키를 버져닝하는 조금 더 우아한 방법이 없는지 궁금해지는 부분입니다.
저희는 현재 캐싱 대상 클래스의 명세가 변경되면 Cache를 명시적으로 evict 하는 것을 그라운드 룰로 정립함으로써 문제를 해결했습니다. 자동화가 이루어지지 않아 아쉽기는 하네요. 혹시 방법을 아시는 분이 있다면 공유 부탁드립니다.
캐시를 가져오는 과정에서 예외가 발생하는 경우의 failOver
@Cacheable을 사용해 캐시에서 값을 꺼내오던 중 Redis의 장애 혹은 직렬화/역직렬화의 문제로 예외가 발생하는 경우에는 원본 method를 invoke할까요? 그렇지 않습니다. failOver는 저희가 직접 구현해줘야 합니다.
AOP를 사용해서 Cacheable이 적용된 method를 한 번 더 감싸기
Cacheable이 적용된 Proxy를 감싸 적용하는 AOP를 한 개 더 생성, Cacheable에서 예외가 발생하면 해당 AOP가 가로채서 추가 로직을 실행합니다. Cacheable이 적용된 메서드 혹은 타겟 메서드를 감싸는 Aspect를 만들고, Aspect에서 Cacheable의 예외를 붙잡아 Exception이 JsonPArse, Redis 관련인지 확인한 후 ProceedJoinPoint 제공되는 정보(메서드 명, 대상 객체, 실행 인자)를 조합해 실행함으로써 해결할 수 있겠습니다.
해당 구현은 아직 완료되지 않았는데요..! 완료되면 새로운 포스팅으로써 소개드려보겠습니다. 현재는 Redis를 구현하면서 이러한 점도 고려했다 정도로 봐주시면 감사하겠습니다.
캐시 동작에 대한 테스트 코드 작성
애너테이션으로 이미 제공되는 기능을 사용하는데, 테스트 코드를 작성해야 할 지 고민했었습니다. 하지만 Redis는 저희가 운용하는 인프라이며 검증되어야 하는 인프라 동작이라고 결론 내리게 되었습니다. 레디스 가용성 및 정합성 여부로 애플리케이션에 치명적인 문제점을 발생시킬 수 있기 때문이죠.
테스트 코드 작성 난이도는 그렇게 어렵지 않더군요 RedisTemplate 빈을 통해 다음과 같은 형태로 작성될 수 있었습니다.
@DisplayName("여행기 컨텐츠 페이징 응답 시 페이지 번호가 4이하이고 필터 조건과 검색 조건이 없으면 응답을 캐싱한다.")
@ParameterizedTest
@ValueSource(ints = {0, 1, 2, 3, 4})
void cacheTraveloguePage(int pageNumber) {
// given
TravelogueSearchRequest searchRequest = new TravelogueSearchRequest(null, null);
TravelogueFilterRequest filterRequest = new TravelogueFilterRequest(null, null);
Pageable pageRequest = PageRequest.of(pageNumber, 5, Sort.by("likeCount").descending());
// when
service.findSimpleTravelogues(filterRequest, searchRequest, pageRequest);
// then
String key = "traveloguePage::" + pageRequest.toString();
String cachedValue = redisTemplate.opsForValue().get(key);
assertThat(cachedValue).isNotEmpty();
}Jmeter를 통한 캐시 도입 전/후 비교 테스트
캐시 도입 후 의미 있는 성능 향상을 이뤄냈는지 테스트 해보고 싶었고 Jmeter를 통해 테스트를 진행해보았습니다.
설정
- Application 설정
- 여행기 콘텐츠 1만개
- 멤버 5000명
- 멤버 1명당 랜덤한 여행기에 좋아요 1개
- 서버 설정
- local 프로파일의 WAS 로컬 구동
- Docker 이용 로컬에서 MySQL 및 Redis 컨테이너 구동
- Jmeter 설정
- 동시 접속자수 (Thread) : 100
- Ramp-up period : 0
- Duration: 180초
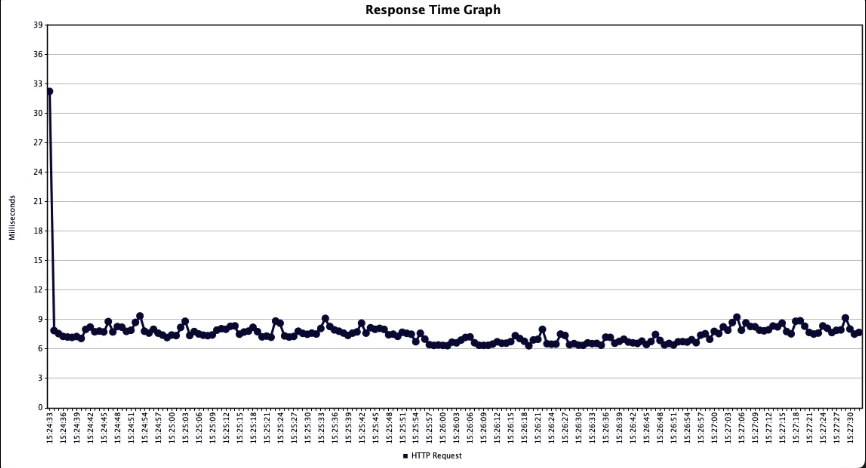
With Cache
With No Cache
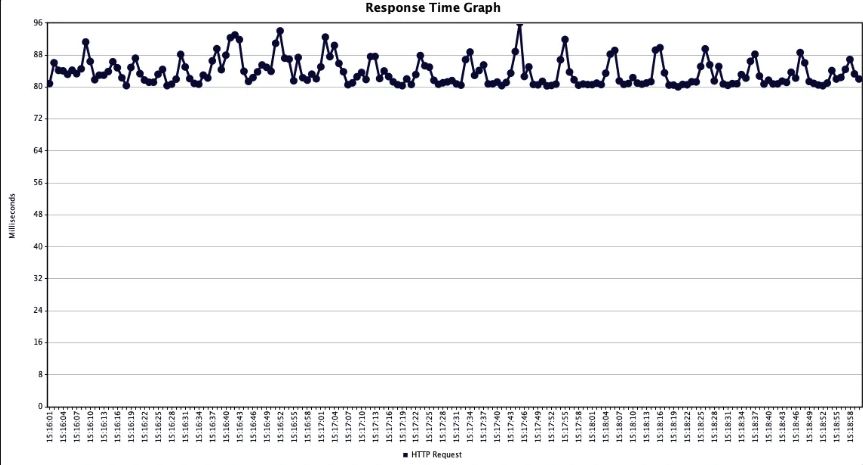
캐시를 도입한 경우 7ms, 도입하지 않은 경우 85ms의 평균 응답 속도를 약 91.76%의 성능을 개선한 것을 확인할 수 있었습니다.
