
내비게이션 주행데이터를 이용한 도착시간 예측
- 내비게이션 주행데이터를 읽어들여 데이터를 문석 및 전처리한 후 머신러닝과 딥러닝으로 도착시각을 예측하고 결과를 분석하세요.
- 해당 문제는 AICE 공식 홈페이지에서 제공해주는 샘플문항입니다. 링크

[데이터 컬럼 설명 (데이터 파일명: A0007IT.json)]
- Time_Departure : 출발시각
- Time_Arrival : 도착시각
- Distance : 이동거리(m)
- Time_Driving : 실주행시간(초)
- Speed_Per_Hour : 평균 시속
- Address1 : 주소1
- Address2 : 주소2
- Weekday : Time_Departure(출발시각)의 요일
- Hour : Time_Departure(출발시각)의 시각
- Day : Time_Departure(출발시각)의 날짜
[데이터 컬럼 설명 (데이터 파일명: signal.csv)]
- RID : 경로ID
- Signaltype : 경로의 신호등 갯수
데이터 가져오기
1. scikit-learn을 별칭 sk로 불러오기
import sklearn as sk2. pandas를 별칭 pd로 불러오기
import pandas as pd3. json 및 csv 파일 읽어온 후 합치기
- 복사 가능 항목:
A0007IT.json,signal.csv,df_a,df_b
df_a = pd.read_json('A0007IT.json')
df_b = pd.read_csv('signal.csv')
df=pd.merge(df_a,df_b,how="inner",on="RID")
# print(df.head())데이터 시각화 및 전처리
# 사전실행코드
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
plt.rc('font', family='NanumGothicCoding')4. Address1(주소1)에 대한 분포도 확인을 위한 countplot 그래프 만들기
- Seaborn을 활용
- Address1(주소1)에 대해서 분포를 보여주는 countplot그래프
- 지역명이 없는 '-'에 해당되는 row(행)을 삭제
- 출력된 그래프를 바탕으로 옳지 않은 선택지를 아래에서 골라 '답안04' 변수에 저장
- Countplot 그래프에서 Address1(주소1) 분포를 확인 시 '경기도' 분포가 제일 크다.- Address1(주소1) 분포를 보면 '인천광역시'보다 '서울특별시'가 더 크다.
- 지역명이 없는 '-'에 해당되는 row(행)가 2개 있다.
- 복사 가능 항목:
Address1
import seaborn as sns
sns.countplot(data=df, x='Address1')
plt.show()
# df[df['Address1'] == '-'] # 3개
df = df[df['Address1'] != '-']
답안04 = 3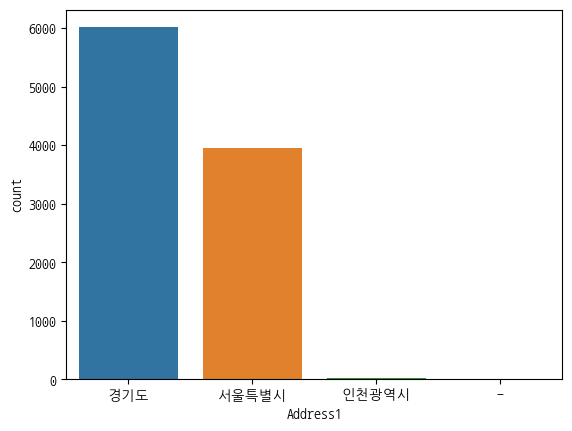
5. 실주행시간과 평균시속의 분포 확인
- Time_Driving(실주행시간)과 Speed_Per_Hour(평균시속)을 jointplot 그래프 그리기
- Seaborn을 활용
- X축에는 Time_Driving(실주행시간)을 표시하고 Y축에는 Speed_Per_Hour(평균시속)을 표시
- 복사 가능 항목:
Time_Driving,Speed_Per_Hour
sns.jointplot(data=df, x='Time_Driving',y='Speed_Per_Hour')
plt.show()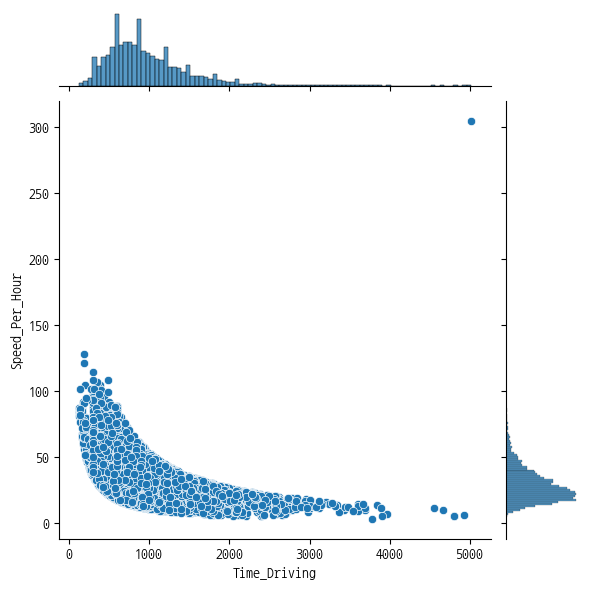
6. jointplot 그래프에서 발견한 이상치 1개를 삭제
- 대상 데이터프레임: df
- jointplot 그래프를 보고 시속 300 이상되는 이상치를 찾아 해당 행(Row)을 삭제하세요.
- 불필요한 'RID' 컬럼을 삭제하세요.
- 전처리 반영 후에 새로운 데이터프레임 변수명 df_temp에 저장하세요.
- 복사 가능 항목:
RID,df_temp
df_temp = df.drop(['RID'], axis=1)
df_temp = df[df['Speed_Per_Hour'] < 300]7. 가이드에 따른 결측치 제거
- 대상 데이터프레임: df_temp
- 결측치를 확인하는 코드를 작성
- 결측치가 있는 행(row)를 삭제
- 전처리 반영된 결과를 새로운 데이터프레임 변수명 df_na에 저장
- 결측치 개수를 '답안07' 변수에 저장
- 복사 가능 항목:
df_na
df_temp.isna().sum() # 2개
df_na = df_temp.dropna(axis=0)
답안07 = 28. 불필요한 변수 삭제
- 대상 데이터프레임: df_na
- 'Time_Departure', 'Time_Arrival' 2개 컬럼을 삭제
- 전처리 반영된 결과를 새로운 데이터프레임 변수명 df_del에 저장
- 복사 가능 항목:
Time_Departure,Time_Arrival,df_del
df_del = df_na.drop(['Time_Departure','Time_Arrival'], axis=1)9. 조건에 해당하는 컬럼 원-핫 인코딩
- 대상 데이터프레임: df_del
- 원-핫 인코딩 대상: object 타입의 전체 컬럼
- 활용 함수: pandas의 get_dummies
- 해당 전처리가 반영된 결과를 데이터프레임 변수 df_preset에 저장
- 복사 가능 항목:
df_preset
cols = df_del.select_dtypes('object').columns
df_preset = pd.get_dummies(data=df_del, columns=cols)10. 훈련, 검증 데이터셋 분리 및 스케일링
- 대상 데이터프레임: df_preset
- 훈련과 검증 데이터셋 분리
- 훈련 데이터셋 label: y_train, 훈련 데이터셋 Feature: X_train
- 검증 데이터셋 label: y_valid, 검증 데이터셋 Feature: X_valid
- 훈련 데이터셋과 검증데이터셋 비율은 80:20
- random_state: 42
- Scikit-learn의 train_test_split 함수를 활용하세요. - RobustScaler 스케일링 수행
- sklearn.preprocessing의 RobustScaler 함수 사용- 훈련 데이터셋의 Feature는 RobustScaler의 fit_transform 함수를 활용하여 X_train 변수로 할당
- 검증 데이터셋의 Feature는 RobustScaler의 transform 함수를 활용하여 X_valid 변수로 할당
- 복사 가능 항목:
Time_Driving
from sklearn.model_selection import train_test_split
x = df_preset.drop('Time_Driving', axis=1)
y = df_preset['Time_Driving']
X_train, X_valid, y_train, y_valid = train_test_split(x,y, test_size=0.2, random_state=42)
from sklearn.preprocessing import RobustScaler
robustScalar = RobustScaler()
X_train_robust = robustScalar.fit_transform(X_train)
X_valid_robust = robustScalar.transform(X_valid)
X_train = pd.DataFrame(X_train_robust, index=X_train.index, columns=X_train.columns)
X_valid = pd.DataFrame(X_valid_robust, index=X_valid.index, columns=X_valid.columns)모델 학습 및 평가
11. Decision Tree와 Random Forest로 머신러닝 모델 만들고 학습하기
- 여러 가지 규칙을 순차적으로 적용하면서 독립 변수 공간을 분할하는 모형으로, 분류와 회귀 분석에 모두 사용이 가능
- Decision Tree트리의 최대 깊이: 5로 설정
- 트리의 최대 깊이: 5로 설정
- 노드를 분할하기 위한 최소한의 샘플 데이터수- (min_samples_split): 3로 설정
- random_state: 120로 설정
- 모델을 dt 변수에 저장
- Random Forest
- 트리의 최대 깊이: 5로 설정
- 노드를 분할하기 위한 최소한의 샘플 데이터수- (min_samples_split): 3로 설정
- random_state: 120로 설정
- 모델을 rf 변수에 저장
- 위 두 개의 모델에 대해 fit을 활용해 모델을 학습, 학습 시 훈련데이터 셋을 활용
- 복사 가능 항목:
dt,rf
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
dt = DecisionTreeRegressor(max_depth=5, min_samples_split=3, random_state=120)
dt.fit(X_train, y_train)
rf = RandomForestRegressor(max_depth=5, min_samples_split=3, random_state=120)
rf.fit(X_train, y_train)12. 위 모델 성능 평가 및 비교하기
- 예측 결과의 mae(Mean Absolute Error)를 구하기
- 성능 평가는 검증 데이터셋을 활용
- 11번 문제에서 만든 의사결정나무(decision tree) 모델로 y값을 예측(predict)하* 여 y_pred에 저장
- 검증 정답(y_valid)과 예측값(y_pred)의 mae(Mean - Absolute Error)를 구하고 dt_mae 변수에 저장
- 두 개의 모델에 대한 mae 성능평가 결과를 확인해 성능 좋은 모델 이름을 '답안12' 변수에 저장
- 복사 가능 항목 :
y_pred_dt,dt_mae,y_pred_rf,rf_mae
from sklearn.metrics import mean_absolute_error
y_pred_dt = dt.predict(X_valid)
dt_mae = mean_absolute_error(y_valid, y_pred_dt)
y_pred_rf = rf.predict(X_valid)
rf_mae = mean_absolute_error(y_valid, y_pred_rf)
# dt_mae, rf_mae
# >> 108.6652..., 66.4842...
답안12 = 'randomforest'# 사전실행코드
import tensorflow as tf
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.layers import Dense, Activation, Dropout, BatchNormalization
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.utils import to_categorical
tf.random.set_seed(1)13. Time_Driving(실주행시간)을 예측하는 딥러닝 모델을 만들기
- Tensoflow framework를 사용하여 딥러닝 모델 구현
- 히든레이어(hidden layer) 2개이상으로 모델을 구성
- dropout 비율 0.2로 Dropout 레이어 1개를 추가
- 손실함수는 MSE(Mean Squared Error)를 사용
- 하이퍼파라미터 epochs: 30, batch_size: 16으로 설정
- 각 에포크마다 loss와 metrics 평가하기 위한 데이터로 X_valid, y_valid 사용
- 학습정보는 history 변수에 저장
- 복사 가능 항목 :
history
model = Sequential()
model.add(Dense(64, input_shape=(X_train.shape[1],), activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(32, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse', metrics='mse')
history = model.fit(X_train, y_train, epochs=30, batch_size=16, validation_data=(X_valid, y_valid))14. 위 딥러닝 모델 성능 평가
- Matplotlib 라이브러리 활용해서 학습 mse와 검증 mse를 그래프로 표시
- 1개의 그래프에 학습 mse과 검증 mse 2가지를 모두 표시
- 위 2가지 각각의 범례를 'mse', 'val_mse'로 표시
- 그래프의 타이틀은 'Model MSE'로 표시
- X축에는 'Epochs'라고 표시하고 Y축에는 'MSE'라고 표시
plt.plot(history.history['mse'])
plt.plot(history.history['val_mse'])
plt.legend(['mse','val_mse'])
plt.title('Model MSE')
plt.xlabel('Epochs')
plt.ylabel('MSE')
plt.show()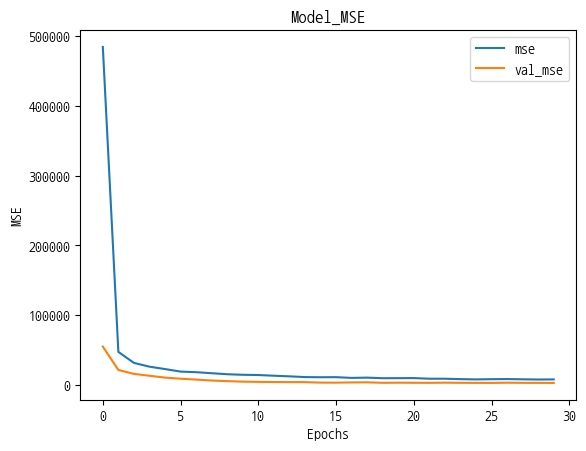

컴퓨터공학 & 미디어콘텐츠, AI/ML, HCI, PM, QA
저도 올해 구글 머신러닝 부트캠프 6기 나오면 지원하려고 글 찾다가 들어오게 되었습니다. 올해는 모집이 늦네요;; 혹시 여러 AI 자격증중에 AICE를 보시는 이유가 있으실까요?? 어떤 점이 나을까요?