컬렉션의 확장 함수
코틀린에는 자바 기본 컬렉션을 구현한 것 뿐 아니라 많은 확장 함수를 제공한다.
기능을 기준으로 범주를 나눌 수 있다.

컬렉션의 연산
연산자를 사용하면 컬렉션에 대해 더하거나 빼는 등의 기능을 수행할 수 있다.
val list4 = listOf("one", "two", "three")
val list5 = listOf(1, 3, 5)
val map1 = mapOf("h1" to 1, "hello" to 2)
println(list4 + "four") // [one, two, three, four]
println(list5 + "1") // [1, 3, 5, 1]
println(list4 + "listOf(5, 6 ,7)") // [one, two, three, listOf(5, 6 ,7)]
println(list4 - 1) // [one, two, three]
println(map1 + Pair("Bye", 4)) // {h1=1, hello=2, Bye=4}
println(map1 + mapOf("Apple" to 4, "Orange" to 5)) // {h1=1, hello=2, Apple=4, Orange=5}
println(map1 - listOf("hi" to "hello")) // {h1=1, hello=2}
위와 마찬가지로 연산자 - + 등을 통해서도 컬렉션을 관리할 수 있다.
요소의 처리와 집계
요소를 집계하는 확장 함수로는 forEach, forEachIndexed, onEach, count, max, min, maxBy, minBy, fold, reduce, sumBy 등이있다.
val listPair = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
println(listPair)
// [(A, 300), (B, 200), (C, 100)]
요소의 순환 람다식
list.forEachIndexed { index, value ->
println("index[${index}] : ${value}")
}
// index[0] : 1
// index[1] : 2
// index[2] : 3
// index[3] : 4
// index[4] : 5
// index[5] : 6
// index[6] : 7
요소의 순환 람다식
- forEach, forEachIndexed, onEach, count, max, min, maxBy, minBy, fold, reduce, sumBy() 등이 있습니다.
val list7 = listOf(1, 2, 3, 4, 5, 6, 7)
val listPair2 = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val map = mapOf(11 to "Java", 22 to "Kotlin", 30 to "C++")
println(list7)
println(listPair2)
println(map)
// [1, 2, 3, 4, 5, 6, 7]
// [(A, 300), (B, 200), (C, 100)]
// {11=Java, 22=Kotlin, 30=C++}
요소의 순환
list6.forEach { println("$it") }
println()
list6.forEachIndexed { index,value -> println("index[$index] : $value ") }
println(list6)
// [1, 2, 3, 4, 5, 6, 7]
// [(A, 300), (B, 200), (C, 100)]
// {11=Java, 22=Kotlin, 30=C++}
forEach는 각 요소를 람다식으로 처리한 후 컬렉션을 반환하지 않습니다.
요소의 개수 반환
val list8 = listOf(1, 2, 3, 4, 5, 6, 7)
println(list8.count { it % 2 == 0 })
// 3
최댓값과 최솟값 요소 반환
// 이거 왜 max랑 min안됨?
println(list8.maxOrNull())
// 7
println(list8.minOrNull())
// 1
println("maxBy : " + map.maxByOrNull { it.key })
// maxBy : 30=C++
println("minBy : " + map.minByOrNull { it.key })
// minBy : 11=Java
각 요소에 정해진 식 적용하기
초깃값과 정해진 식에 따라 요소에 처리하기 위해 fold와 reduece를 사용합니다.
fold는 초깃값과 정해진 식에 따라 처음 요소부터 끝 요소에 적용해 값을 반환하며, reduce는 fold와 동일하지만, 초깃값을 사용하지 않는다.
println(" list8.fold : ${list8.fold(4) { total, next -> total + next }}")
// list8.fold : 32
println(" list8.fold(1) : ${list8.fold(1) { total, next -> total * next }}")
// list8.fold(1) : 5040
println(list8.foldRight(4) { total, next -> total + next })
// 32
println(list8.foldRight(1) { total, next -> total + next })
// 29
println(list8.reduce { total, next -> total + next })
// 28
println(list8.reduceRight { total, next -> total + next })
// 28
list의 모든 요소에 대해 fold(4)는 초깃값 4가 정해지고, 1 + 2 + 3 + .. + 6의 모든 요소가 더해진다.
foldRight(1)은 모두 동일하나 요소의 오른쪽부터 더해진다.
reduce, reduceRight의 작동 방법도 동일하나 초깃값이 없습니다.
모든 요소 합산하기
식에서 도출된 모든 요소를 합한 결과를 반환하려면 sumBy를 사용합니다.
println(listPair)
println(listPair.sumBy { it.second })
// [(A, 300), (B, 200), (C, 100)]
// 600
요소의 검사
val list = listOf(1, 2, 3, 4, 5, 6, 7)
val listPair2 = listOf(Pair("A", 300), Pair("B", 200), Pair("C", 100))
val map2 = mapOf(11 to "Java", 22 to "Kotlin")
println(list.all { it < 10 })
// true
println(list.all { it % 2 == 0 })
// false
println(list.any { it < 10 })
// true
println(list.any { it % 2 == 0 })
// true
-
list.all은 모든 요소가 일치할 때, true를 반환한다.
-
list.any는 최소한 하나 혹은 그 이상의 특정 요소가 일치하면 true를 반환한다.
특정 요소의 포함 및 존재 여부 검사하기
- 컬렉션에 특정 요소가 포함되어 있는지를 검사하기 위해 contains()를 사용할 수 있다.
- 요소가 포함되어 있으면 true, 없으면 false
- contains는 번위 연산자 in을 사용해서 요소의 포함 여부를 확인할 수도 있다.
- 모든 요소가 포함되어 있는지 검사하려면 containsAll()을 사용한다.
println("contains : ${list.contains(2)}")
// contains : true
println(2 in list)
// true
println(map.contains(11))
// true
println(11 in map)
// true
println("containsAll : ${list.containsAll(listOf(1, 2, 3))}")
// containsAll : true
- 컬렉션에 요소가 존재하는지를 검사
-
none(), isEmpty(), isNotEmpty()
- none() : 요소가 없으면 true, 있으면 false
- isEmpty()와 isNotEmpty()는 컬렉션이 비어있는지 아닌지에 따라 true를 반환
-
println("none : ${list.none()}")
// none : false
println("none : ${list.none { it > 6 }}")
// none : false
println(list.isEmpty())
// false
println(list.isNotEmpty())
// true
요소의 필터와 추출
특정 요소 골라내기

- filter()에서 주어진 컬렉션을 it으로 받아 % 2를 통해 짝수만 골라낼 수 있다.
- filterNot()으로 하면 짝수가 아닌 것,
- null이 포함되어 있는 컬렉션인 listWithNull에서 null을 제외하기 위해서는 filterNotNull을 사용
-
filterIndexed를 사용하면 2개의 인자를 람다식에서 받아서 각각 인덱스와 값에 대해 특정 수식에 맞는 조건을 골라낼 수 있다.
- 메소드 이름에 To가 붙은 filterIndexedTo는 filterIndexed에 컬렉션으로 반환되는 기능이 추가 되어있다.

-
filterKeys는 요소를 it로 받아서 키에 대한 조건에 맞는 부분을 반환
- 반대로 filterValues를 사용하면 값에 의한 조건식을 만들고 그에 맞는 부분을 반환
-
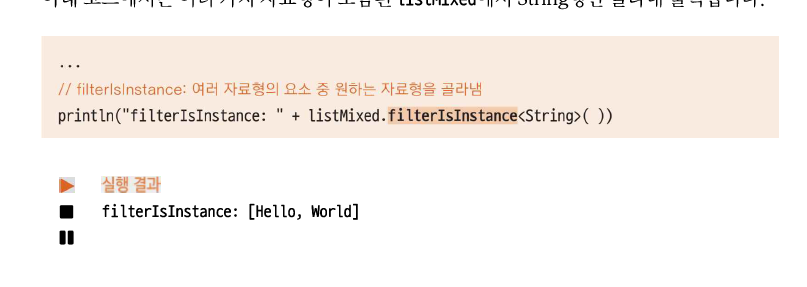
여러 자료형 중 원하는 자료형을 골라낼 수 있는 filterIsInstance()
- 여러가지 자료형이 포함된 listMixed에서 String형만 골라서 추출한다.

특정 범위를 잘라내거나 반환하기
-
slice()는 특정 범위의 인덱스를 가진 List를 인자로 사용해 기존 List에서 요소들을 잘라낼 수 있다.
- 인덱스 0~2에 해당하는 1, 2 ,3이 추출되어 반환

요소의 필터와 추출
특정 요소 골라내기
컬렉션의 분리와 병합
- union()은 두 List컬렉션을 병합하고 중복된 요소 값은 하나만 유지
- plus()나 + 연산자를 사용하면 중복요소를 포함하여 합친다.

순서와 정렬
- 컬렉션 목록을 뒤집거나 오름차순 혹은 내림차순으로 정렬 할 수 있다.
- reversed()는 요소의 순서를 거꾸로해서 반환
- sorted()는 요소를 작은 수에서 큰 수로 반환
- sortedBy()는 특정한 비교식에 의해 정렬된 컬렉션을 반환
- sortedByDescending은 요소를 큰 수에서 작은 수로, z부터 a순서로 정렬해서 반환

