개요
게시글 조회 API에서 집계(조회수) 성능 개선에 대한 내용을 설명합니다.
상황
게시글 조회 시, 해당 게시글의 조회수를 1 증가시키는 로직이 포함되어 있습니다.
구현 방법은 여러가지가 있을 수 있고, 상황과 요구사항에 따라 결정해야합니다.
1. 더티 체킹
@Transactional
public Article findById(long articleId) {
Article article = articleRepository.findById(articleId)
.orElseThrow(() -> new IllegalArgumentException());
article.updateViewCount() // viewCount++
return article;
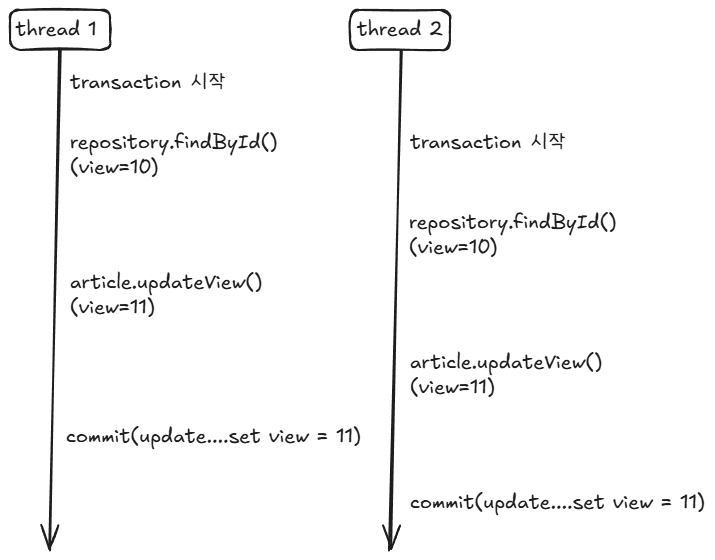
}간단히 JPA의 더티 체킹을 통해 구현할 수 있지만, 멀티 스레드 환경에서 Lost Update 문제가 있어 제외 했습니다.
2. Update문 사용
@Transactional
public Article findById(long id) {
int updateRow = articleRepository.updateViewCounts(id);
if (updateRow == 0) {
throw new IllegalArgumentException();
}
return articleRepository.findById(id)
.orElseThrow(() -> new IllegalArgumentException();
} @Query("UPDATE Article a SET a.viewCounts = a.viewCounts + 1 WHERE a.id = :id")
int updateViewCounts(@Param("id") long id);MySQL에서는 update문을 실행할 때 조건절에 해당하는 레코드에 레코드 락 또는 넥스트 키 락을 획득합니다. 인기 게시글같이 트래픽이 많은 경우에 X 락 대기가 발생하여 조회 API 성능에 영향을 줄 수 있습니다.
3. 낙관적락, 비관적 락
- 낙관적락은 동시 요청이 많은 조회 API에는 적합하지 않다고 판단했습니다.
- 비관적 락은 충돌이 생길 것이라 예측하고 조회 시점에 X 락을 획득하고 트랜잭션 종료 시 까지 유지합니다. 따라서 단순 update문랑 동일하다고 생각하여 제외했습니다.
4. Redis write back 패턴
조회수 데이터를 레디스에 저장하고 관리하며, 조회 요청 시 INCR 명령어를 통해 조회수를 증가시킵니다.
인메모리 DB 특성상 실제 DB를 거치는 것보다 속도가 빠릅니다. 특히, 현재 API에서 레디스를 도입한다면 DB 레벨의 락을 제거하여 데드락, 조회 성능등 다양한 부분에서 이점이 생길 수 있습니다.
고려해야할 점
- 레디스는 인메모리 데이터베이스입니다. 데이터가 사라질 가능성이 있어, 주기적으로 DB에 동기화를 해야합니다.
- 메모리는 비싼 자원이기 때문에, 사용하지 않는 데이터가 메모리를 점유하는 것을 방지해야 합니다.
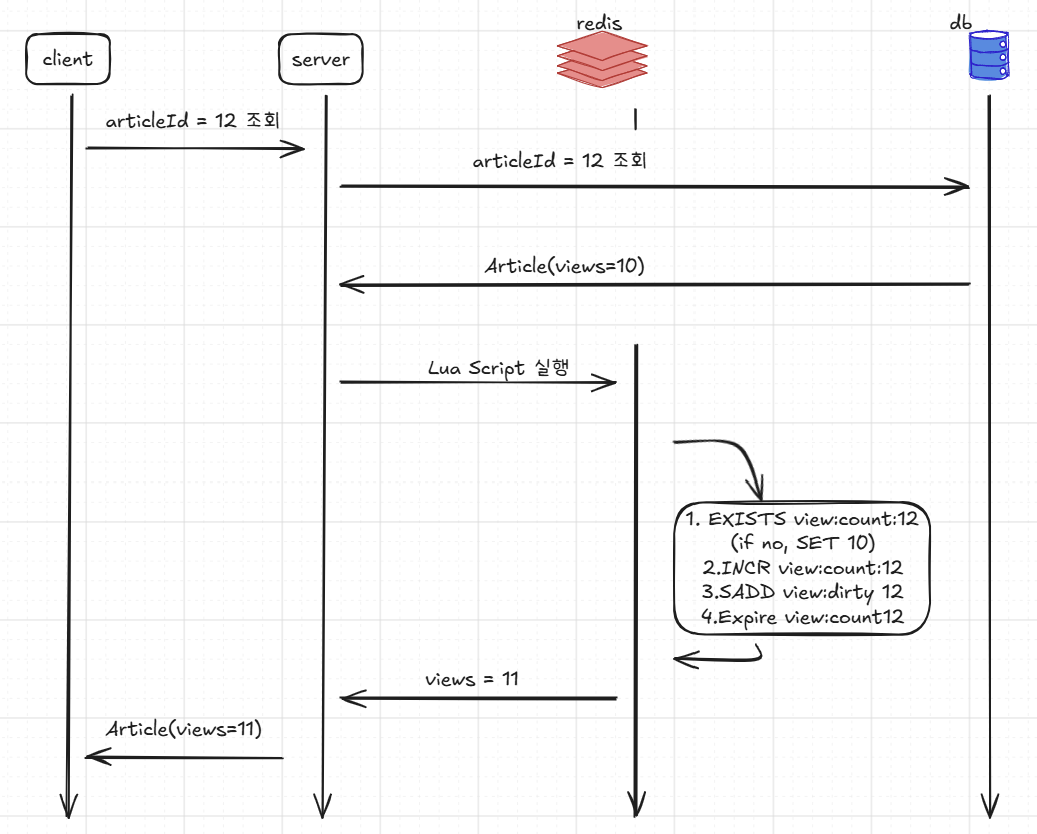
Redis write back 구현
조회수 관리(동시성 문제)
-- KEYS[1]: view:count:{articleId}
-- KEYS[2]: view:dirty
-- ARGV[1]: dbCount
-- ARGV[2]: articleId
-- ARGV[3]: TTL
-- 1. 조회수 키가 없으면 DB 값으로 초기화 (Cache Warming)
if redis.call('EXISTS', KEYS[1]) == 0 then
redis.call('SET', KEYS[1], ARGV[1])
end
-- 2. 조회수 증가
local currentView = redis.call('INCR', KEYS[1])
-- 3. 변경된 게시글 ID를 Dirty Set에 등록
redis.call('SADD', KEYS[2], ARGV[2])
-- 4. 조회수 키 TTL 연장 (2일 - 자주 조회되는 글은 메모리에 유지)
redis.call('EXPIRE', KEYS[1], ARGV[3])
return currentView레디스는 개별 명령어의 원자성은 보장하지만, 다수의 명령어를 연속 실행할 경우엔 중간에 다른 요청이 개입할 수 있어 원자성이 깨질 수 있습니다. 이를 해결하기 위해 Lua 스크립트를 도입하여 조회, 등록, 업데이트를 원자적으로 처리했습니다.
또한, 효율적인 DB 동기화를 위해 변경된 게시글 ID는 Set 자료구조에 별도로 저장하였습니다.
TTL
- 매일 새벽 동기화 작업을 하기 때문에, 기본적으로 1일보다는 길게 설정하여 DB에 저장하기도 전에 레디스의 데이터가 사라지는 것을 방지합니다.
- 너무 길게 설정하면 오래된 데이터가 불필요하게 점유할 수 있습니다.
위 2가지를 고려하여 2일로 설정했습니다.
DB 동기화
@Scheduled를 도입하여 트래픽이 적은 새벽 시간에 레디스의 데이터를 DB로 동기화합니다.
@Scheduled(cron = "0 0 4 * * *")
public void batchUpdateViewCount() {
boolean acquired = redisService.getLock(LOCK_KEY, Duration.ofHours(2));
if (!acquired) {
return;
}
try {
syncViewCounts();
} catch (Exception e) {
throw new 서버에러;
} finally {
redisService.releaseLock(LOCK_KEY);
}
}
현재 프로젝트는 단일 서버 기반이지만, 일반적으로 다중 서버 환경에서 서비스를 운영합니다.
따라서 다중 서버에서 동기화 작업의 중복 실행을 막기위해 분산락을 사용했습니다.
private static final String DIRTY_KEY = "view:dirty";
private static final String TEMP_DIRTY_KEY = "view:dirty:temp";
public void syncViewCounts() {
if(redisService.hasKey(TEMP_DIRTY_KEY)) {
batchUpdate(TEMP_DIRTY_KEY);
}
if(!redisService.hasKey(DIRTY_KEY)) {
return;
}
redisService.rename(DIRTY_KEY, TEMP_DIRTY_KEY);
batchUpdate(TEMP_DIRTY_KEY);
}배치 작업 시 유입되는 새로운 조회수 데이터의 유실을 방지하기 위해, 작업 시작 시 RENAME 명령어로 처리 대상을 분리하였습니다.
작업 시작 전 동기화가 실패한 데이터들에 대한 처리를 먼저 진행한 후 새로운 변경 사항에 대한 작업을 처리하도록 설계했습니다.
public void batchUpdate(String key) {
try (Cursor<String> cursor = redisService.scan(key, BATCH_SIZE)) {
List<String> idLists = new ArrayList<>();
while (cursor.hasNext()) {
String rawId = cursor.next();
idLists.add(rawId);
if (idLists.size() >= BATCH_SIZE) {
updateDb(idLists);
idLists.clear();
}
}
if (!idLists.isEmpty()) {
updateDb(idLists);
}
redisService.delete(key);
} catch (Exception e) {
// 실패시 TEMP 남아 있음, 내일 다시 처리하기 위해 ttl 초기화
redisService.expire(key, Duration.ofDays(2));
throw new HhjServerException("Batch Processing Failed", HttpStatus.INTERNAL_SERVER_ERROR);
}
}레디스는 싱글 스레드 기반이므로 KEYS와 같은 O(N) 명령어 사용 시 전체 시스템이 블로킹될 위험이 있습니다. 따라서 SCAN을 사용하여 대상을 순차적으로 조회하도록 구현했습니다.
동기화가 정상적으로 완료되면 해당 임시 Set을 삭제하여 메모리 리소스를 즉시 반환하도록 했으며, 실패 시에는 TTL을 연장하여 데이터 유실 없이 다음 배치 작업에서 재시도되도록 설계했습니다.
성능 비교
nGrinder를 사용하여 Vuser를 500까지 천천히 Ramp up을 하며, TPS가 증가하다 멈추는 부분과 MTT 값이 급격히 튀는 곳들을 중점적으로 보며 API의 최대 처리 용량과 병목 구간을 파악했습니다.
Update문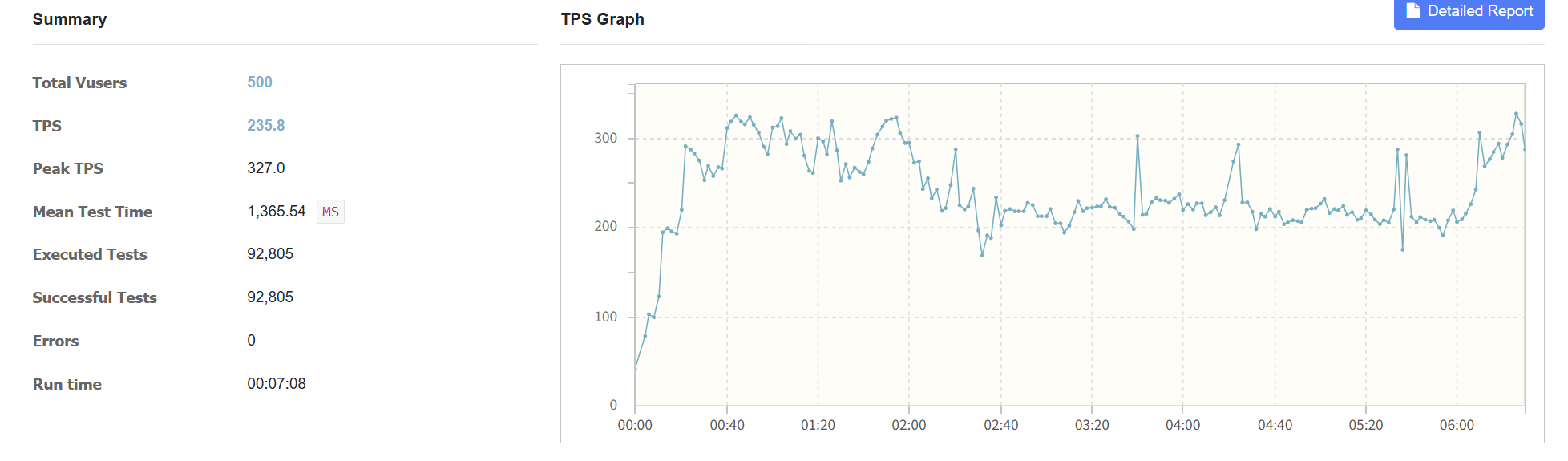
Redis write back 패턴
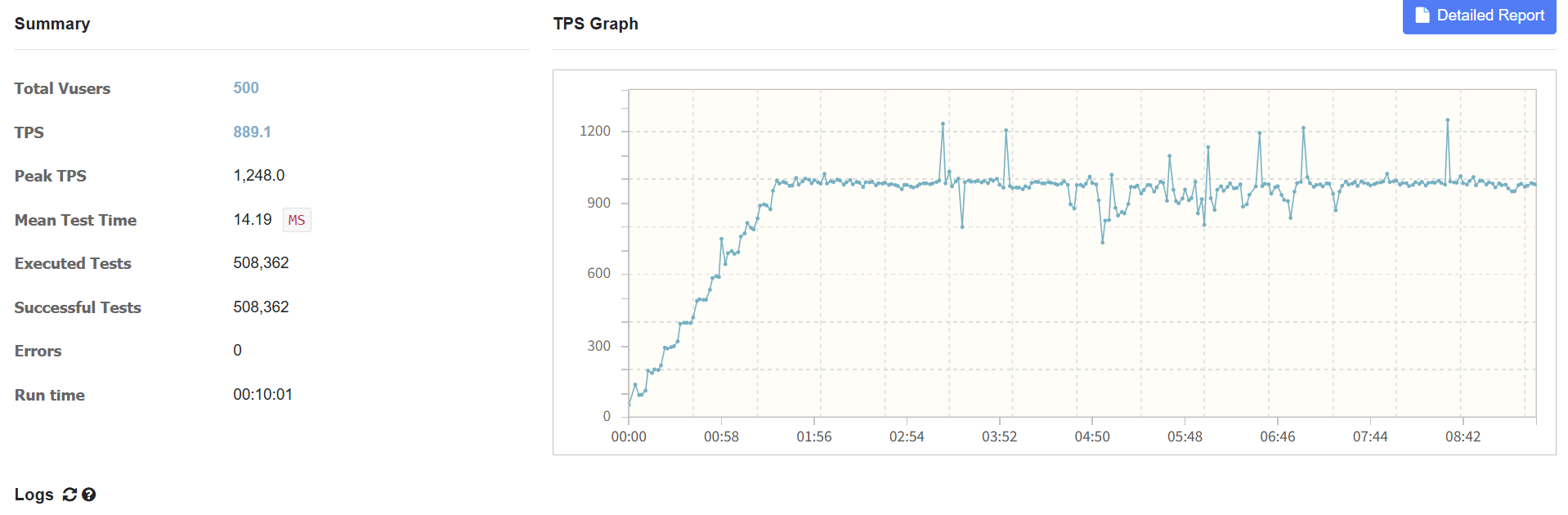
Redis Write Back 패턴 도입 결과, 불안정했던 평균 TPS는 235.8에서 안정적인 889.1로 277% 향상되었으며, 평균 응답 시간은 1.3초 대에서 0.01초 대(14ms)로 개선되었습니다.
테스트 환경상 레디스가 로컬에서 동작하여 네트워크 지연이 배제된 점을 감안하더라도, 성능 저하의 주원인이었던 DB Disk I/O 및 X락 대기 시간을 제거했기 때문에 실제 운영 환경에서도 유의미한 성능 향상을 기대할 수 있을 것 같습니다.
