- paper link: https://arxiv.org/abs/2503.23513v1
해결하고자 하는 문제와 배경
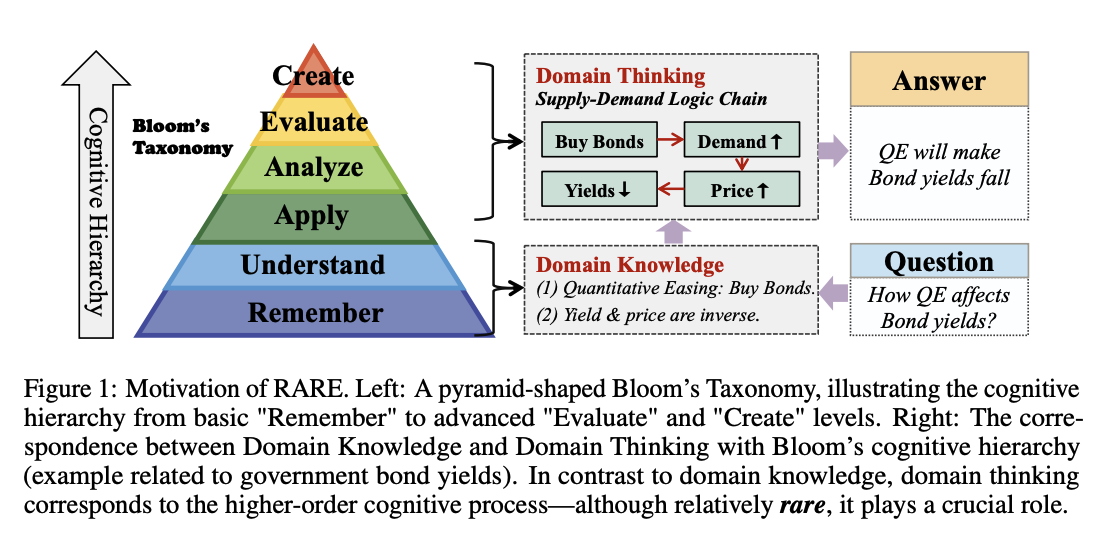
이 논문은 대규모 언어모델(LLM)의 도메인 특화 지능(domain-specific intelligence) 문제를 해결하고자 한다. 일반적인 LLM들은 광범위한 일반 지식과 추론 능력을 갖추고 있지만, 전문적인 지식을 요구하는 도메인 특화 영역(예: 의료, 금융 등)에서는 다음과 같은 한계를 보인다.
- 지식의 한계: 방대한 도메인 지식을 기억하는 것이 어렵고, 잘못된 정보를 생성하는 현상(환각 현상)이 자주 발생함.
- 추론의 한계: 도메인 특화 지식을 실제 문제 해결에 적용하는 정교한 추론 능력이 부족함.
이를 극복하기 위해 지식 기억(memorization)과 추론(reasoning)을 분리하여, 효율적으로 도메인 특화 문제를 해결하는 새로운 접근법을 제안한다.
문제 해결 방법 (RARE 모델의 핵심 개념과 구현)
논문에서는 Retrieval-Augmented Reasoning Modeling (RARE) 이라는 새로운 접근법을 제안한다. 핵심 아이디어는 다음과 같다:
- 지식 저장과 추론의 분리: 도메인 지식은 별도의 외부 저장소(지식 베이스)에 저장하고, 언어 모델 내부에서는 추론만 최적화.
- 동적 지식 검색(Retrieval): 추론 과정에서 필요한 도메인 지식을 외부 저장소에서 동적으로 검색하고 활용함으로써, 모델이 내부에서 모든 지식을 암기할 필요가 없음.
- 추론 중심 학습: 검색된 지식을 모델 훈련 과정에서 주입하여, 암기 대신 맥락에 맞춘 응용력 및 높은 수준의 추론 능력을 기르는 데 집중함.
이를 통해 모델이 불필요한 기억 과정을 생략하고, 효과적으로 고차원적 추론 능력(higher-order reasoning)을 발달시킬 수 있다.
실험 결과와 성과
의료 분야를 중심으로 다양한 도메인 특화 벤치마크(MedQA, PubMedQA, PubHealth, CoVERT, BioASQ)를 이용하여 실험한 결과:
- RARE를 활용한 경량 모델(예: Llama-3.1-8B, Qwen-2.5-7B)은 GPT-4 등 대형 모델이나 기존의 retrieval-augmented 방식보다 높은 성능을 기록함.
- 특히, Qwen-2.5-7B 모델은 PubMedQA에서 78.63%, CoVERT에서 74.14% 정확도를 달성하여, retrieval-augmented GPT-4를 능가하는 성능을 보였다.
이러한 결과는 모델 크기를 늘리거나 단순히 지식을 주입하는 것보다, 추론 중심 학습이 더 효과적임을 명확히 보여준다.
연구의 중요성
RARE 접근법은 다음과 같은 점에서 중요한 기여를 한다:
- 자원 효율성: 큰 파라미터를 통한 지식 암기 대신 외부 지식 저장소를 활용하여, 자원이 한정된 상황에서도 우수한 성능을 낼 수 있다.
- 지식 정확성과 최신성 유지: 외부에 저장된 도메인 지식을 필요 시 업데이트할 수 있어, 최신 정보 반영 및 유지 관리가 용이하다.
- 도메인 특화 지능의 확장성: 기존의 모델 확장 방식에서 벗어나, 지식과 추론을 구분하는 새로운 패러다임을 제시하여 다양한 도메인에 적용 가능하다.
이는 장기적으로 더욱 정교한 도메인 특화 응용 프로그램 개발에 필수적이며, 인공지능의 신뢰성 및 유연성을 크게 향상시킬 수 있는 잠재력이 있다.

AI Engineer 의 개발 블로그입니다!