GoogleNet은 2014년 ILSVRC(ImageNet Large Scale Visual Recognication Challenge, 이미지넷 이미지 인식 대회)에서 VGGNet(VGG19)를 이기고 우승을 차지한 알고리즘이다. GoogLeNet은 19 layer의 VGG19보다 좀 더 깊은 22 layer로 구성되어 있다. GoogLeNet의 original 논문은 Christian Szegedy 등에 의해 2015 CVPR에 개제된 "Going Deeper with Convolutions"이다. GoogLeNet이란 이름에서 알 수 있듯이 구글이 이 알고리즘 개발에 참여했다.
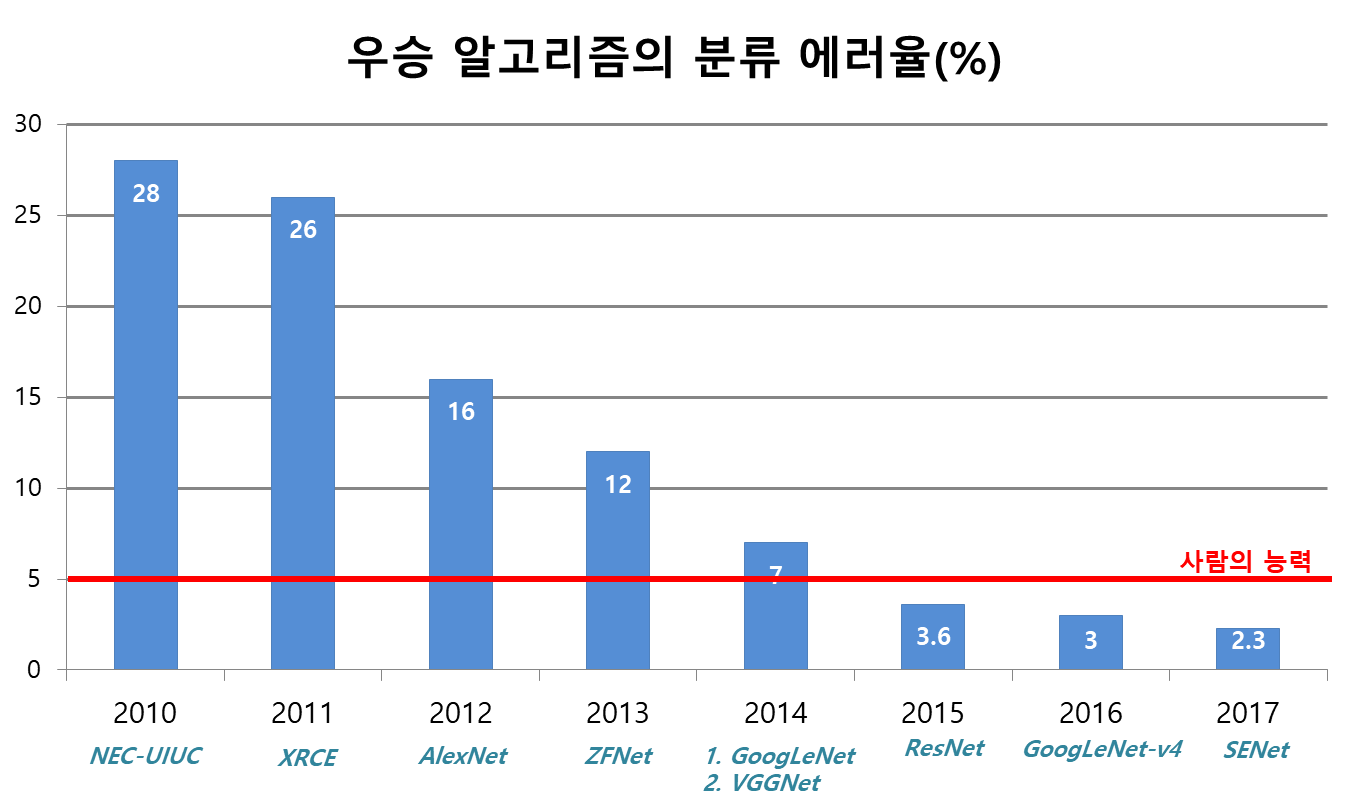
아래 그림은 2010년부터 2017년까지 ILSVRC 대회의 우승 알고리즘과 에러율을 나타낸 것이다. GoogleNet은 2014년 대회에서 우승을 하였고 VGGNet이 2등을 하였다.
1. GoogleNet의 구조
전체적인 GoogleNet의 구조는 다음과 같다.
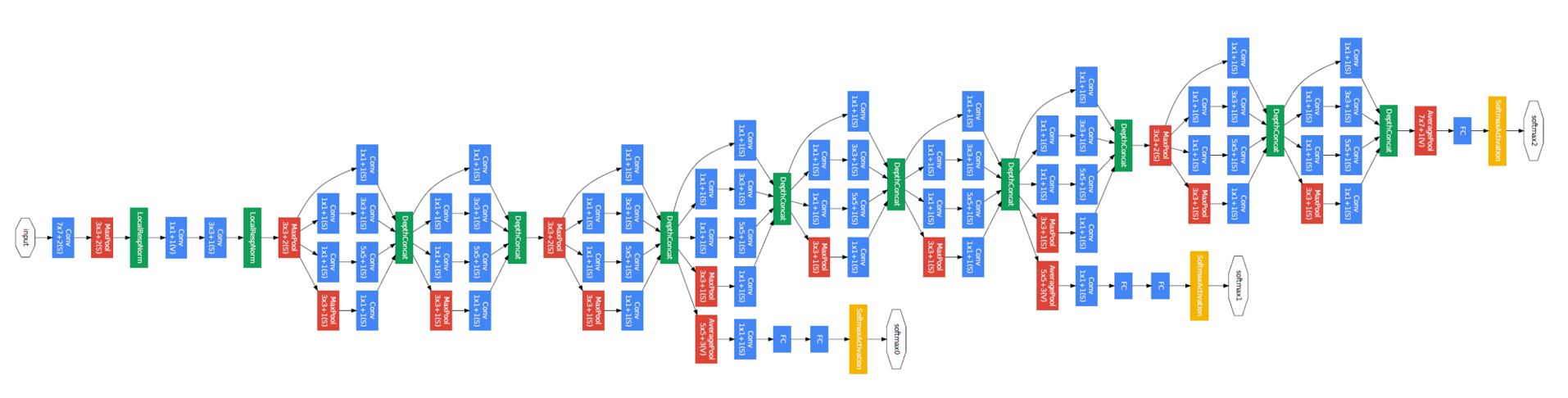
layer가 많아서 브라우저에서 축소된 이미지로 볼 때에는 글자가 잘 안보인다. 그래서 이미지를 부분적으로 잘라서 자세히 살펴볼 것이다.
위 그림에서 파란색 부분은 layer, 빨간색 부분은 pooling, 노란색 부분은 softmax, 초록색 부분은 LRN 혹은 Depth concatenation이다.
파란색 사각형이 Convolution layer 또는 Fully-connected layer이고 실제로 연산이 가장 많이 이루어지는 부분이며 이 파란색 사각형의 갯수로 GoogleNet의 layer수를 정한다.(22 layer)
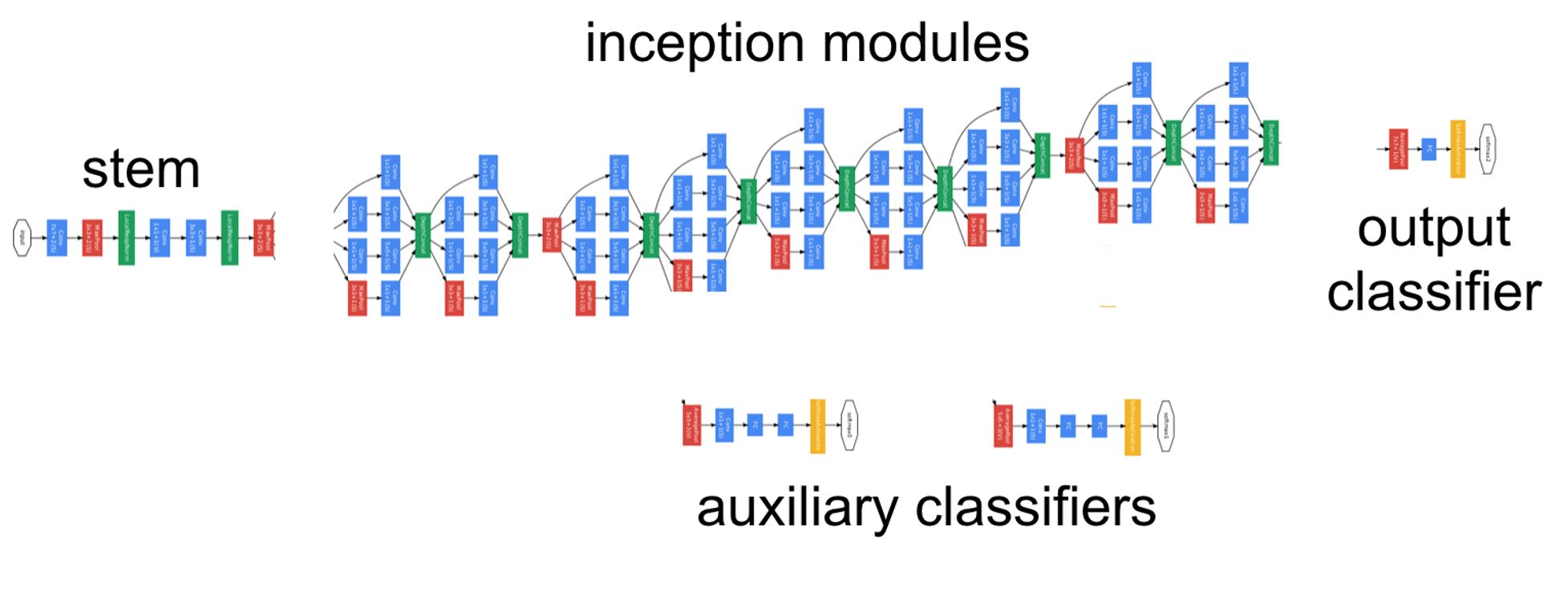
GoogleNet의 전체 구조는 다음과 같이 Stem, Inception module, Auxiliary classifiers, Output classifier 네 부분으로 나뉜다.
1.1 Inception modules
GoogleNet의 구조에서 Inception module부분은 아래의 부분이며 9개의 Inception module이 반복되면서 연결된 구조이다.

1.1.1 naive inception module
inception module의 초기 버전은 naive inception module이고 이 것을 개선시킨 모듈이 GoogleNet에서 쓰인다.
naive inception module의 구조는 다음과 같다.
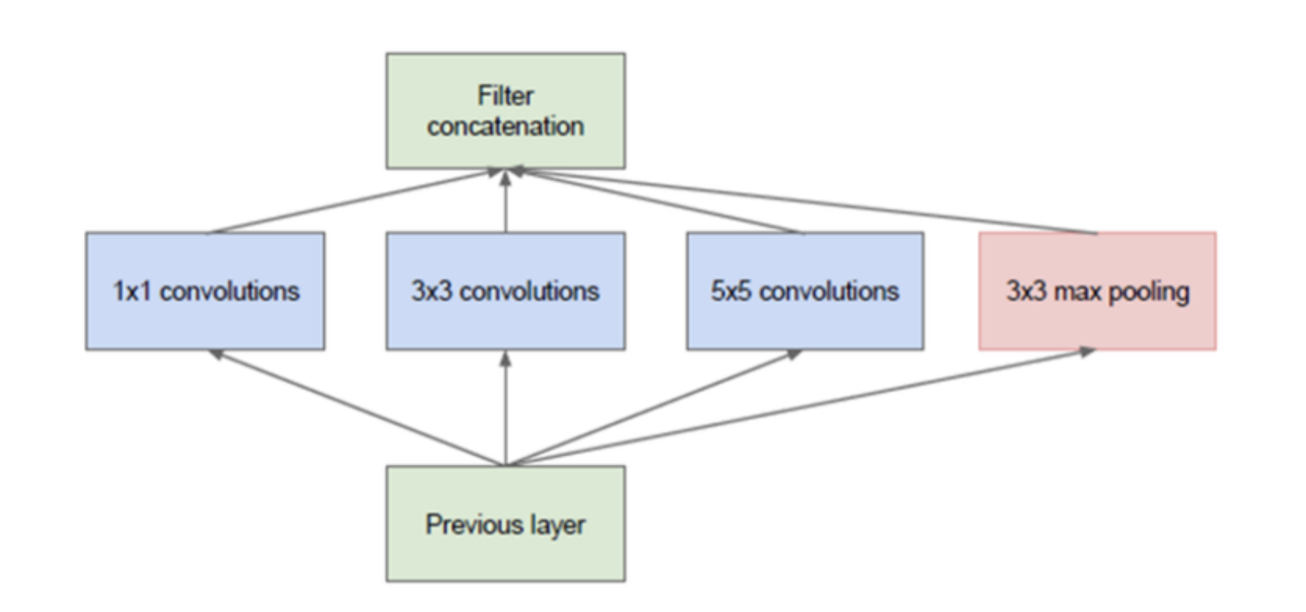
- previoud layer로부터 입력을 받아서 3개의 convolution layer와 1개의 pooling layer가 parallel하게 처리하고 있는 것을 볼 수 있다.
- 4개의 layer에서 처리 후 그 결과를 Filter concatenation layer에서 하나로 합친다.
- 여기서 사용한 convolution 필터는 1x1, 3x3, 5x5 이고 추가적으로 3x3 맥스 풀링을 사용하였는데 이렇게 다양한 필터를 사용한 이유는 input feature에서 의미있는 feature를 뽑아내기 위해서는 다양한 representation을 받아들일 수 있는 필터들이 필요하기 때문이다.
- input feature의 어떤 특징이 있다고 할 때, 그 특징들과 필터 간의 correlation이 어떻게 분포되어 있는지 모르기 때문에 다양한 필터를 사용했다고 한다.
- convolution filter의 경우 이미지 내의 detail한 특성을 잡아낼 수 있고 MaxPooling 같은 경우 이미지의 위치에 영향을 받지 않는 특성을 잡아낼 수 있기 때문에, 이 두 종류를 같이 사용하다고 한다.
naive inception module의 연산량을 예제를 이용하여 계산해 보면 다음과 같다.

- module의 input이 28x28x256 의 크기라고 할 때,
- 1x1 conv layer에서 128개의 1x1x256 filter를 사용하였고, padding=0, stride=1로 설정하였다. output의 크기는 28x28x128이 나온다.
- 3x3 conv layer에서 192개의 3x3x256 filter를 사용하였고, padding=1, stride=1로 설정하였다. output의 크기는 28x28x192이 나온다.
- 5x5 conv layer에서 96개의 5x5x256 filter를 사용하였고, padding=2, stride=1로 설정하였다. output의 크기는 28x28x96이 나온다.
- 3x3 max pool layer에서 padding=1, stride=1로 설정하였다. output의 크기는 28x28x256이 나온다.
- 그림을 보면 알겠지만 conv layer, pooling layer를 통과할 때 input의 width, height 크기는 변하지 않고 채널수만 변하는 것을 알 수 있다. width, height가 유지되도록 padding과 stride값을 조정했기 때문인데 pytorch나 tensorflow등과 같은 framework을 통해서 실행할 때는 자동으로 설정되게 할 수 있다.
- Filter concatenation layer에서 4개의 layer에서 각각 처리된 결과를 하나로 합치는데 이들을 쌓아올려서 합쳐준다. 이 때의 output size는 28x28x(128+192+96+256)=28x28x672=529k 가 된다.
- 이 때의 연산횟수는 다음과 같다.
- [1x1 conv, 128] : (28x28)x(1x1)x256x128
- [3x3 conv, 192] : (28x28)x(3x3)x256x192
- [5x5 conv, 96] : (28x28)x(5x5)x256x96
- pooling layer는 곱하고 더하는 연산이 없기 때문에 연산 횟수에는 포함하지 않는다.
- 모두 합하면 845M
- naive inception module에서 예제를 통해 따져보니 연산량이 많은 것을 알 수 있다.
1.1.2 Inception module with dimension reduction
naive inception module에서 연산량이 매우 많은 문제점을 해결하고자 module 중간 중간에 1x1 convolution을 적용하여 채널수를 줄여 파라미터 수를 줄였다.
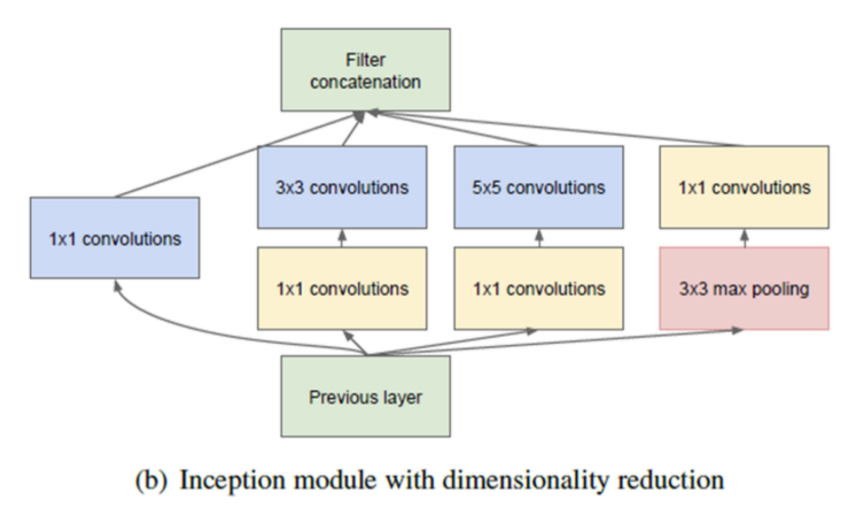
- 그림에서 노란색 사각형 4개가 새로 추가한 1x1 convolution이다.
- 1x1 convolution은 input의 width, height는 그대로 유지하면서 채널수만 줄여주는 용도로 사용된다. (채널수를 같거나 크게 만들 수도 있지만 대부분 줄일 목적으로 사용된다)
- 1x1 convolution을 통과하여 채널수를 줄이면 전체적으로 파라미터수가 줄어들고 연산량도 줄어든다.
- 이렇게 1x1 convolution을 사용하여 파라미터 수를 줄인 개선된 Inception module을 GoogleNet에서 사용하고 있다.
- naive inception module과 비교하기 위해 동일한 예제를 사용하여 연산횟수를 계산해 보면 다음과 같다.

- [1x1 conv, 128] : (28x28)x(1x1)x256x128
- [1x1 conv, 64] : (28x28)x(1x1)x256x64
- [3x3 conv, 192] : (28x28)x(3x3)x64x192
- [1x1 conv, 64] : (28x28)x(1x1)x256x64
- [5x5 conv, 96] : (28x28)x(5x5)x64x96
- [1x1 conv, 64] : (28x28)x(1x1)x256x64
- 모두 더하면 358M
- naive inception module의 연산량 845M 대비 57.6% 정도 연산량이 감소하였다.(절반 이상 감소하였다.)
1.2 Stem network
최초 input data가 들어올 때 inception module에서 처리하기 전까지 처리되는 network으로 이전의 ImageNet 모델에서 사용했던 것과 비슷한 형태를 띄고 있다.

- 그림에서 7x7+2(S)의 의미는 filter의 widthxheight가 7x7이라는 것이고 2(S)는 stride가 2라는 의미이다.
1.3 Output classifier
최종적인 분류를 하기 위한 Output classifier network이다.

- Average Pooling layer가 global average pooling 방식을 사용하는데 일반적인 pooling이 filter size에 따라 output의 size가 정해지는 반면에 global average pooling(gap)은 output size를 1로 만들어 버린다. 즉 input의 각 채널마다 전체 평균을 구하여 1차원 벡터로 만들어 버린다. 예제를 들어 그림으로 설명하면 다음과 같다.

- input size가 4x4x3일 때 global average pooling을 하면 3개의 각 채널당 4x4 크기의 data에서 전체 평균을 구하여 1x1x3의 1차원 벡터를 만든다.
- 이렇게 하는 이유는 연산량이 많은 Fully-connected layer를 사용하지 않기 위해서이다.

그림에서 처럼 7x7x1024 크기의 입력을 1x1x1024 출력형태로 만들려고 할 때 FC layer를 사용하면 (7x7x1024)x(1x1x1024)번의 연산이 필요하지만, global average pooling을 사용하면 연산이 필요가 없다! - Global Average Pooling 다음의 FC layer는 1000개의 image 분류 class 각각에 대한 score값을 구하기 위함이고
- softmax layer를 통해서 각 score를 확률로 바꾸어 준다.
1.4 Auxiliary classifier
Auxiliary classfier는 GoogleNet에서 중간에 특정 inception module의 위치에 연결되어 있다.

자세한 구조는 아래와 같다.

- 네트워크의 깊이가 깊어지면 깊어질수록 vanishing gradient(gradient 소실) 문제를 피하기 어려워진다. 그러니까 가중치를 훈련하는 과정에 역전파(back propagation)를 주로 활용하는데, 역전파 과정에서 가중치를 업데이트하는데 사용되는 gradient가 점점 작아져서 0이 되어버리는 것이다. 따라서 네트워크 내의 가중치들이 제대로 훈련되지 않는다. 이 문제를 극복하기 위해서 GoogLeNet에서는 네트워크 중간에 두 개의 보조 분류기(auxiliary classifier)를 달아주었다.
- 이를 통해 중간에 2번의 loss를 계산해서 이를 전체 loss 계산하는데 반영해주어 최종 loss만 사용했을 때 gradient가 소실되어 버리는 문제를 개선하였다. Auxiliary classfier의 loss를 반영할 때는 loss의 30%만 반영한다. 즉
total_loss = real_loss + 0.3 * aux_loss_1 + 0.3 * aux_loss2로 계산한다.
