뭐야, 아침에 병원 갔다왔더니 왜 내가 조장이지? 우리 조 노션만 없는거 보소😨
으아악 미안해요 여러분😖😖😖😖😖 이것은 전산오류가 분명하다. 조장을 잘못 뽑으신게야.
1강
- 프로토콜
멀리 떨어져 서로에 대한 정보가 없는 메시지 송수신자들 간에도 서로 필요한 요청과 응답을 할 수 있도록, 요청의 형식에 대한 규약을 정한 것이 프로토콜.
웹 상에서는 HTTP라는 프로토콜을 이용해 데이터를 주고받는다.
그럼 서버는 요청을 받아서 HTML/CSS/JS 파일을 return해주는게 주 업무인가요? 🤔
-> 예전엔 그랬지만 지금은 아님. 최근에는 프론트 - 백간에 '느슨한 결합'이 주류가 되면서,
'통채로' 보다는 '필요한 것만' 반환해주는 것을 더 선호한다.
그래서 최근에는 JSON 형식으로 데이터만 반환하는 경우도 많다.
2강
서비스 로직이 커질수록 연관 데이터 많아짐 -> 로직을 더 복잡하게 만듬. 일종의 악순환.
로직 수정, 새 동작 추가가 불가능하게 되는 시점에 도달하여, 실패를 인정하고 프로그램이나 서버를 다 엎고 다시 만드는 경우도 심심치않게 있다.
소프트웨어 디자인 패턴 - 너와 동료의 수천수만시간을 아껴줄 선배들의 실패 모음집.
정형화된 여러 패턴이 있지만, 그중에서도 문제를 다루는 방식이 가장 애용됨.
새 데이터 처리하는 부분 / 서비스 로직 처리 부분 / 기존 데이터 이용 부분
-> 이 부분들은 실제로 스프링 & 스프링 부트에서 각각 레이어로 나눠져있음.
-
Presentation 계층 (Spring의 Controller가 이것)
-> 사용자와의 상호작용 처리계층. MVC도 이 계층에 해당함.
스프링은 @Controller 로 표현. -
Domain(Business or Service 라고도 함) 계층 (Spring의 Service가 이것)
-> 서비스/시스템의 핵심 로직! 유효성 검사&계산을 포함하는 비즈니스 논리계층. 스프링은 @Service 로 표현.
Presentation에서 받아온 데이터의 유효성(Validation)을 검사한다.
또한 어떤 Data Access를 선택할지도 결정.
▶그래서 이상적으로는 Presentation이나 Data Access는 별 할일이 없고, Domain 계층이 비대해지는 것이 가장 좋다. -
Data Access(Persistence) 계층 (Spring의 Repository가 이것)
-> DAO 계층이라고도 함. 스프링은 @Repository 로 표현.
DB / Message Queue / 외부 API와의 통신 등을 처리. DB 또는 원격 서비스에서 영구데이터를 관리하는 방법으로 분류하는 데이터 접근 계층.
-> 우리의 DB는 데이터를 저장하는 데이터 소스가 서버 외부에 별개로 존재하는 경우가 매우 많다. 데이터 소스와 소통을 하게 해주는 계층이라고 생각하면 됨.
※우리는 DB에 접근하는걸 무의식중에 쉽게 생각하지만, 김영한님 말씀으로는 의외로 DB에 접근하는게 생각보다 어렵다고.
3강
RDBMS (관계형 DBMS) - MySQL, PostgreSQL, Oracle Database가 대표적. 오라클은 유료라서 나머지 둘 중 골라서 사용할건데, 우리는 MySQL 쓸것.
우리가 사용할 RDBMS - H2, MySQL인데 H2는 야구만화 In-memory DB.
- In-memory DB가 뭔데요?
-> 자고 일어나면 잊어버리는 애.
서버가 돌아가는 동안에만 내용을 저장하고, 서버가 작동을 멈추면 데이터가 모두 삭제되는 DB.
연습용으로 쓰기는 딱 좋다.
MySQL은 AWS RDS라는 서비스를 이용해 붙여볼것.
SQL은 RDBMS에서 쓰는 언어임. DB를 다루는 프로그래밍 언어인 셈. 국제표준화기구에서 SQL에 대한 표준을 정해서 발표하지만, DBMS 제작회사가 여러 곳이라 표준을 준수하면서 조금씩 차이를 둠.
DDL DCL DML 세가지가 있음.
DDL - Data Definition Language
DCL - Data Controll Language
DML - Data Manipulation Language
primary key를 사용하는 이유는 뭘까 - 데이터의 무결성이 깨지지 않기 위해.
나누어진 테이블을 합치기 위한 JOIN. JOIN시에는 적어도 하나의 컬럼을 공유하고 있어야 하므로, 테이블에 외래키가 설정된 컬럼이 있다면 해당 컬럼을 통해 JOIN할 수 있다.
-> 그러나 이게 항상 좋은 선택은 아닐 수 있다. 일단 추가연산이 일어나고, 경우에 따라 개발이 불편할 수도 있기 때문.
아니 왜 빨간줄이 계속 뜨죠? - 너흰 아직 MySQL 문법 준비가 안됐다
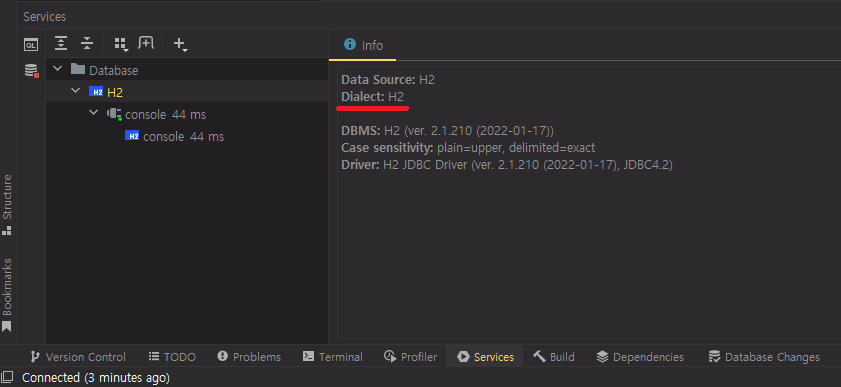
이유는 모르겠지만 Change Dialect가 실패한듯 하다. 나는 Change Dialect가 뜨지 않는데😭😭😭😭😭
change Dialect 문제 해결했다!!!!! MySQL 문법으로 바꿨다!!!!! 🤩🤩🤩🤩🤩
-> 하단 Service 탭에서 H2를 클릭해보니, Dialect가 H2로 되어 있는것이 아닌가!
그게 내내 신경쓰였다. 분명 바꿀 수 있을텐데...
-
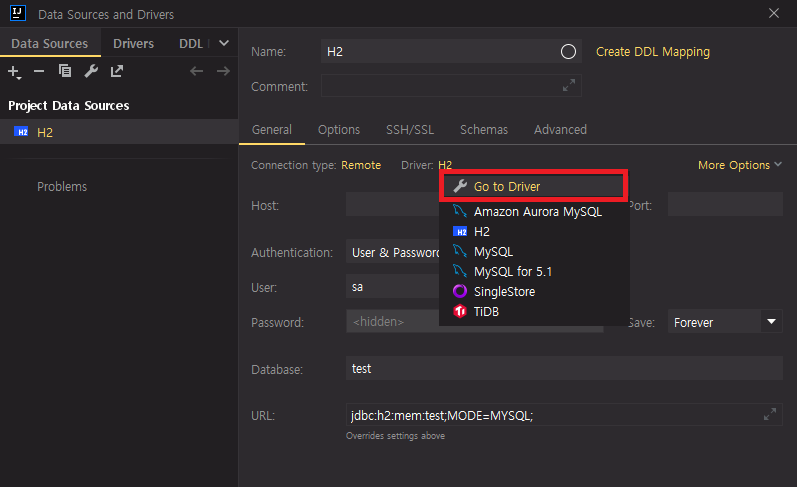
우측 창의 Database에서 H2 우클릭 -> Properties -> General 탭의 Driver에서 Go to Driver 클릭
뭔소린지 모르겠다면 아래 이미지 참고!
-
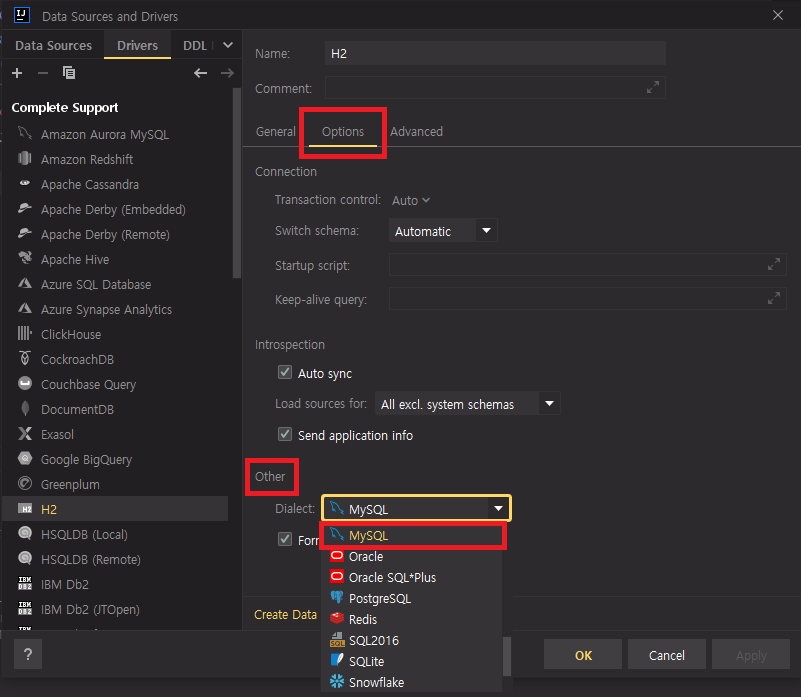
Options 탭에서 Other - Dialect 창에서 MySQL로 바꿔주면 OK!!
조건을 보며 SQL문을 쳐보자 - 뭔소린지 모르겠는 것들에 대한 기록
- name은 최소 2자 이상, varchar 타입, not null 입니다.
-> 최소 몇글자 이상에 대한 설정을 따로 해주는건 의외로 없었다. 그냥 not null이 붙어 있더라. not null을 붙이라는 얘긴가보다.
- student_code는 STUDENT 테이블을 참조하는 FK이며 not null 입니다.
-> 이걸 보고 착각한 것이, 이건 한번에 쓸 수 있는 조건이 아니다.
not null을 붙이는건 그냥 varchar(100)뒤에 not null만 붙이면 된다.
※근데 'STUDENT 테이블을 참조하는 FK' 라는건 CONSTRAINT를 따로 붙여줘야 한다.
CREATE TABLE IF NOT EXISTS MANAGER
(
id bigint primary key comment 'ID',
name varchar(100) not null comment '매니저 이름',
student_code varchar(100) not null comment '수강생코드',
CONSTRAINT manager_fk_student_code
foreign key(student_code) references student(student_code)
)
COMMENT '매니저' charset=utf8;
- ALTER, MODIFY를 이용하여 MANAGER 테이블의 id 컬럼에 AUTO_INCREMENT 기능을 부여하세요.
-> 이건 검색도 해보고 코드스니펫도 참고해봤는데 뚜렷하게 모르겠어서 그냥 답안을 봤다.
ALTER TABLE MANAGER MODIFY COLUMN id bigint auto_increment;
// 이게 답안. 컬럼 이름 뒤에 타입도 써줘여 하는구나.
ALTER TABLE EXAM ADD CONSTRAINT exam_fk_student_code
FOREIGN KEY(student_code) REFERENCES STUDENT(student_code);
// 이건 강의의 코드스니펫.
이 블로그 를 참고해서 써봤는데, 자기가 CREATE 할때 선언한 타입대로 써주는게 바람직한듯 하다. 참고 블로그엔 INT NOT NULL이 붙어있더라.
-> 내가 설정한 id에는 not null 안해도 된다!
NOT NULL과 UNIQUE 속성을 모두 가진 PRIMARY KEY 로 설정했기 때문.
👉 INSERT를 이용하여 수강생 s1, s2, s3, s4, s5를 관리하는 managerA와 s6, s7, s8, s9를 관리하는 managerB를 추가하세요.
- AUTO_INCREMENT 기능을 활용하세요
AUTO_INCREMENT 기능을 활용하라는게 무슨 말이지?🤔
-> id값은 자동으로 등차수열로 부여될테니까, 나머지 값만 입력하면 된다는 얘기다.
SQL에서 테이블의 일부 컬럼에만 값을 입력하려면 컬럼을 다 명시해줘야 한다!
-> 즉, AUTO_INCREMENT 기능을 활용하라는건 여기서 명시컬럼에 id는 빼도 된다는 얘기.
INSERT INTO MANAGER(name, student_code) VALUES('managerA', 's1');
INSERT INTO MANAGER(name, student_code) VALUES('managerA', 's2');
//이런 식으로 써주면 된다는 얘기.
INSERT INTO STUDENT(student_code, name, gender, major_code) VALUES('s12', '권오빈', 'M', 'm3');
//강의의 코드스니펫이 이런 식이었으므로 활용해보았다.
JOIN을 사용하여 managerA가 관리하는 수강생들의 이름과 시험 주차 별 성적을 가져오세요.
JOIN을 어떻게 쓰라는거지...? 막막한데...?😫
-> 이것도 착각하면 안되는게, 한개만 JOIN해서 자료를 다 불러올 수 있는 문제가 아니다.
SELECT s.name, e.exam_seq, e.score FROM MANAGER m
JOIN STUDENT S on m.student_code = s.student_code
JOIN EXAM e on m.student_code = e.student_code
WHERE m.name = 'managerA';
- SQL문법은 [SELECT 열 FROM 테이블 WHERE 검색 조건] 이 일단 기본이다.
※SQL에서 JOIN은 사실 여러 종류가 있는데, 저렇게 JOIN만 딱 써놓으면 INNER JOIN이다. 교집합을 구해달라는 것.
JOIN은 <JOIN 테이블 ON 조인될 조건> 으로 쓴다.
👉 STUDENT 테이블에서 s1 수강생을 삭제했을 때 EXAM에 있는 s1수강생의 시험성적과 MANAGER의 managerA가 관리하는 수강생 목록에 자동으로 삭제될 수 있도록 하세요.
- ALTER, DROP, MODIFY, CASCADE 를 사용하여 EXAM, MANAGER 테이블을 수정합니다.
???????????????? 아니 쓰는 방법이라도 알려주고 구하라고 해야지 이게 뭔소리야?
ALTER TABLE EXAM DROP CONSTRAINT exam_fk_student_code;
// 1번줄
ALTER TABLE EXAM ADD CONSTRAINT exam_fk_student_code FOREIGN KEY(student_code) REFERENCES STUDENT(student_code) ON DELETE CASCADE;
// 2번줄
ALTER TABLE MANAGER DROP CONSTRAINT manager_fk_student_code;
// 3번줄
ALTER TABLE MANAGER ADD CONSTRAINT manager_fk_student_code FOREIGN KEY(student_code) REFERENCES STUDENT(student_code) ON DELETE CASCADE;
// 4번줄
DELETE FROM STUDENT WHERE student_code = 's1';-> 1도 몰으갰으니까 일단 답안을 살펴보자.
여기서 1~4번 줄의 '전처리'를 하지 않고 바로 DELETE FROM 줄부터 실행시키면 에러가 뜬다.
Referential integrity constraint violation 이라고 뜨는데, student_code가 fk로 여러 테이블을 이어주는 역할을 하고 있기 때문에 그냥 삭제할 수 없어서 그렇다.
-> 그래서 1, 3번 줄을 먼저 실행해서, EXAM과 MANAGER 테이블에서 CONSTRAINT로 설정된 student_code를 먼저 해제해줘야 한다. DROP은 그 테이블이나 조건 등등을 버리겠단 얘기라 삭제와 같다.
-> 그리고 2, 4번 줄을 실행해서 ON DELETE CASCADE 라는 조건이 걸린 CONSTRAINT를 다시 걸어준다.
이게 뭐냐면, EXAM하고 MANAGER 테이블에서 지금 FK로 설정한 애 지울 수 있게 하겠다는거임.
※이거 왜 설정해요? -> FK인 student_code가 있는 STUDENT 테이블은 일종의 FK를 넘겨준 부모 테이블임. 자식 테이블에서 오류나기 때문에 부모테이블에 있는 키를 막 지워버릴 순 없음.
그래서 '부모테이블의 이 컬럼을 FK로 받아간 자식테이블에서도, 부모테이블이 이값을 지우면 같이 지워지게 해줄거야!' 라는 설정작업 해야함. 그 작업이 이것.
진유진 매니저님의 세션
persistant connection - 완전 연결은 X, 비연결성이긴 하지만 일정 시간동안만 연결.
PHP라고 자바보다도 심하게 맛없는 맛인 언어가 있음. 아주아주 옛날 언어라고...
우리가 쓰는건 Spring boot -> 옛날에 쓰던 Spring framework의 여러가지 설정들을 미리 편하게 세팅 해놓은 것. Spring framework는 겁나 맛없는 맛, Spring boot는 조금 맛없는 맛.
View를 띄울때 Controller를 사용한다. RestController는 JSON 형태의 파일을 보낼때만 사용!
그리고 흔한 기도메타와 제삿상(?)들

↑B반 스프링 제단의 나

↑B반 리액트 제단의 세령님
(제삿상 카피했다고 세령님한테 단속당했다🥺 힝구)
↑C반 풀스택 제단(?)의 대현님
그리고 개발자 남자친구의 증언(?)
(사실이었어?!)
오늘의 느낀점: 나도 이렇게 될까? 아니, 될 수 있을까? 🤔