
1. Namespace
Namespace Object 란
- 컨테이너의 네임스페이스가 아닌 네임스페이스 Object 를 말하는 것이다
- 용도에 따라 컨테이너와 그에 관련된 리소스를 구분 짓는 그룹의 역할
- 포드, ReplicaSet, Deployment, svc 등과 쿠버네티스 리소스들이 묶여 있는 가상의 작업 공간
예를 들면, 회사가 여러 고객들의 포드를 관리해주는 업체라면, 각 고객사별로 별도의 네임스페이스를 할당하고, 해당 네임스페이스에서 pod, svc 등을 이용한 서비스를 제공해야 한다
-
기본적으로 서로 다른 Namespace 에 속해있는 리소스 간에는 통신 및 접근이 되지 않는다
- Gcp 에서 별도의 Project 를 만들고, 이 공간 내에 VM, VPC 등을 할당하는 것과 비슷하다
-
Ns 를 따로 지정하지 않으면, default ns 에 속한다
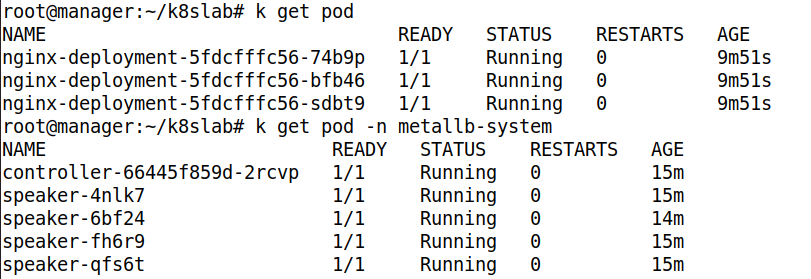
- 특정 Ns 에 속한 Pod 를 확인하려면, -n 옵션을 주면 된다
-
쿠버네티스 클러스터를 여러 명이 동시에 사용해야 한다면, 사용자 마다 ns 를 별도로 생성하여 사용하도록 설정할 수 있다 ( msp 에서 고객사를 관리하는 방법 )
-
네임스페이스의 리소스들은 논리적으로 구분되어 있는 것이며, 물리적으로 격리된 것이 아니므로, 서로 다른 네임스페이스에서 생성된 포드가 같은 노드에 존재할 수 있다
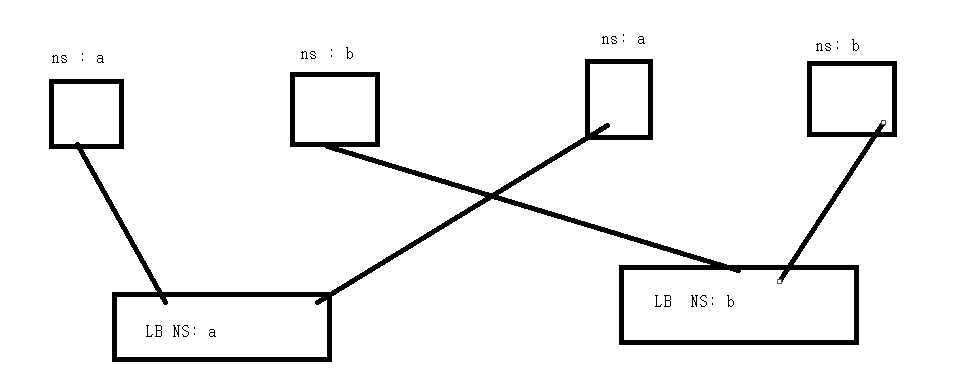
- 위와 같이 LB 에도 NS 를 적용하여 같은 NS 에 속한 Pod 와 연결시키면 된다
Namespace 종류
-
kube-system 은 쿠버네티스 동작을 위한 Pod 가 관리되는 곳
-
네임스페이스에 속하는 OBJECT 와 그렇지 않는 OBJECT 가 있다

- 위와 같이 NAMESPACED 를 통해 확인 가능하다
Namespcae 생성 및 배포
Pod 배포시 네임스페이스를 추가적으로 작성해야 한다 ( metadata 부분에 작성 )
apiVersion: v1
kind: Namespace
metadata:
name: rapa #namespace name ( custom )
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: rapa
spec: # 아래는 ReplicaSet 설정
replicas: 3
selector: # 아래의 label 개수를 확인하여 pod 관리
matchLabels:
app: webserver
template: # 아래는 pod 구성
metadata:
name: my-webserver # Pod의 이름
labels:
app: webserver
spec: # 아래 부분은 컨테이너 구성 내용
containers:
- name: my-webserver # 컨테이너의 이름
image: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-lb
namespace: rapa
spec:
ports:
- name: web-port
port: 80
selector:
app: webserver
type: LoadBalancer - metadata 의 namespace 에 사용할 namespace 이름을 적어주면 된다

- 배포해주자
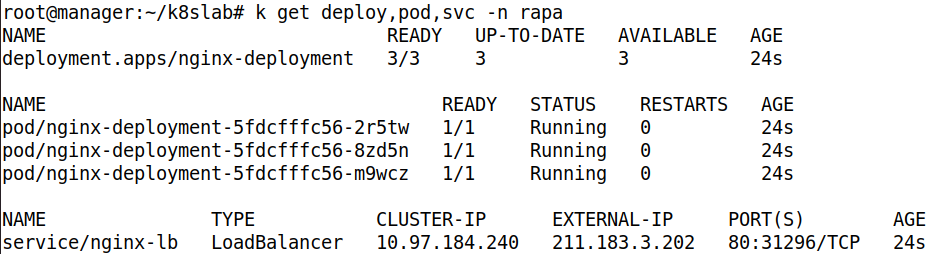
- rapa 네임스페이스에 속해있는 deploy, pod, service 를 확인해보자. 잘 배포되었다
2. ConfigMap
ConfigMap & Secret 의 필요성
-
도커의 이미지는 빌드 후 불변의 상태를 갖기 때문에, 설정 옵션을 유연하게 변경할 수 없다
- 만약, metallb 이미지를 통해 배포할 때, 이미지에 관리할 공인 주소가 입력되어 있으면, 배포된 lb 의 관리할 공인 주소가 모두 같아지기에 이미지에 공인 주소를 입력하면 안된다. 이는 유동적이어야 한다. 따라서 ConfigMap 을 통해 컨테이너 배포시, 관리할 공인 주소를 넣어줘야 한다
-
만약, 공개되면 안되는 Data 라면 Secret 을 사용한다
- ConfigMap 은 사용자별 별도의 설정값 ( 시스템 환경 변수 ) , 파일 등에 사용된다
- Secret 은 일반적인 username / password, 사설 저장소 인증 등에 사용된다
ConfigMap 생성 - 문자열 이용

- from-literal 은 파일을 가져와서 적용하는 것이 아닌, 문자열로 직접 입력하겠다는 옵션이다
- 두 가지 내용을 이용해 ConfigMap 을 생성했다
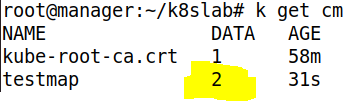
- ConfigMap 을 확인하면, Data 가 2 개 있는 것을 확인 가능하다
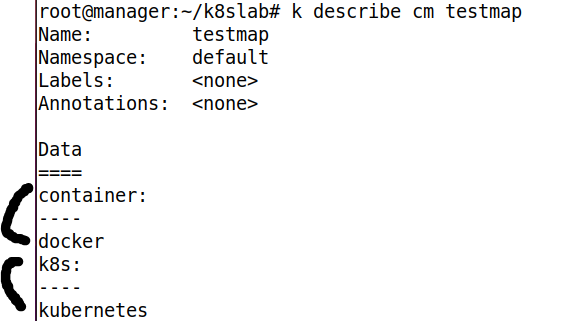
- 세부 정보를 확인하면, 입력한 Data 를 확인할 수 있다
ConfigMap 활용하기 - 환경 변수로 추가
ConfigMap 을 Pod 에서 사용해보자
- ConfigMap 에 저장된 key:value Data 가 컨테이너 환경 변수 key:value 로 사용되기 때문에 Shell 에서 echo $k8s 와 같은 방법으로 값을 확인할 수 있다
- ConfigMap 의 값을 Pod 내부의 파일로 마운트하여 사용할 수도 있다
- 생성된 ConfigMap 을 Pod 내의 특정 파일과 마운트하게 되면, Pod 내에서 해당 파일을 cat 등으로 열어서 확인하면 내용을 확인할 수 있다
- 파일 이름이 key 이고, value 는 파일내에 기록되어 있다

- 두 가지 ConfigMap 을 생성하자
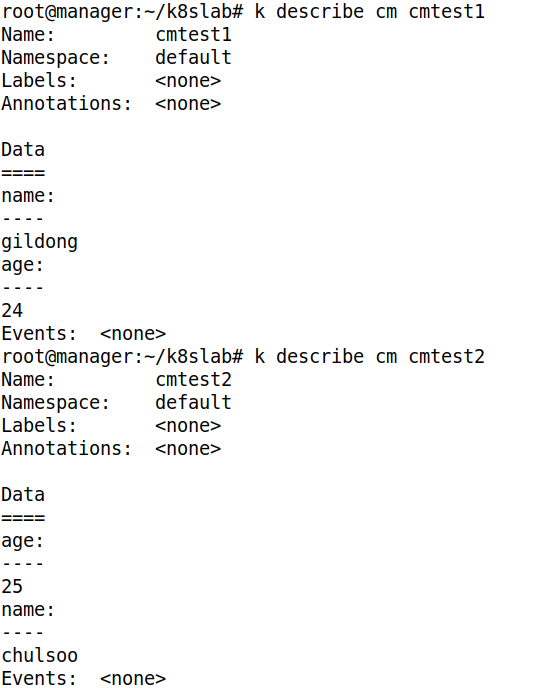
- ConfigMap 이기에 내부 Data 를 바로 확인할 수 있다
apiVersion: v1
kind: Pod
metadata:
name: cmtestpod
spec:
containers:
- name: cmtestpod-ctn
image: busybox # little linux
args: ['tail','-f','/dev/null'] #for not die pod
envFrom: # 환경 변수 설정
- configMapRef: # ConfigMap 사용하겠다
name: cmtest1 # 사용할 ConfigMap 이름- ConfigMap cmtest1 을 적용하였다. 이는 환경 변수로 적용한 것이다
- args 는 docker 의 cmd 와 같은 것이며, tail -f /dev/null 을 통해 /dev/null 에 대한 마지막 내용을 계속 출력하게 하여 Pod 가 죽지 않게 한다

- Pod 를 배포해주자
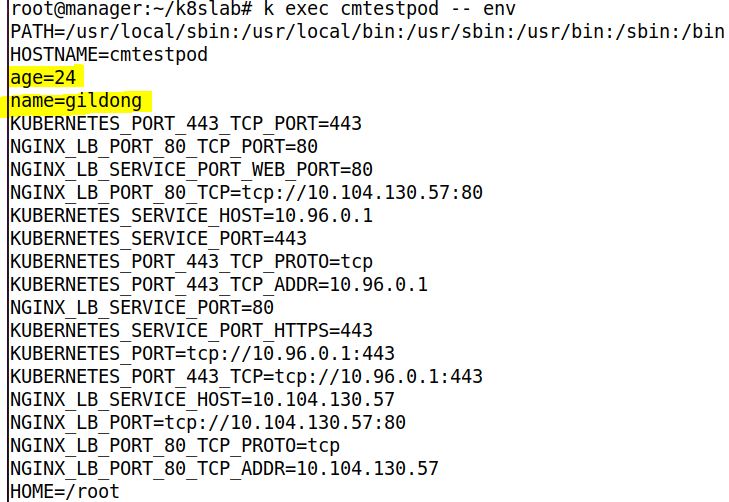
- exec 로 env 명령어를 전달하였다. 환경 변수를 확인해보면 잘 전달된 것을 확인할 수 있다
ConfigMap 활용하기 - Pod 내에 파일로 붙여넣기
이번에는 파일 마운트 방식으로 적용시켜보자
- ConfigMap 을 볼륨처럼 이용하여, Pod 의 특정 파일과 마운트 시킨다
apiVersion: v1
kind: Pod
metadata:
name: cmtestpodvol
spec:
containers:
- name: cmtestpodvolctn
image: busybox
args: ['tail','-f','/dev/null']
volumeMounts: # 볼륨 마운트
- name: cmtestpod-volume
mountPath: /etc/testcm #Pod 에 마운트할 위치
volumes:
- name: cmtestpod-volume
configMap: # ConfigMap 을 이용해 만들겠다
name: cmtest2 # 사용할 ConfigMap 이름- ConfigMap 을 통해 Volume 을 만들었다. 이 Volume 은 ConfigMap 과 같다. 즉, 마운트시 CM 에 저장된 Key 가 파일 이름이 되며, Value 가 내용이 된다
- cmtest2 에는 name 과 age 가 저장되있다. 즉, 2 개의 파일이 있을 것이다

- 배포해주자

- 2 개의 파일이 지정된 위치에 있으며, 해당 파일을 열면 Value 가 내용으로 저장되있다
- key 값이 파일 이름이며, value 값이 파일 내용이다
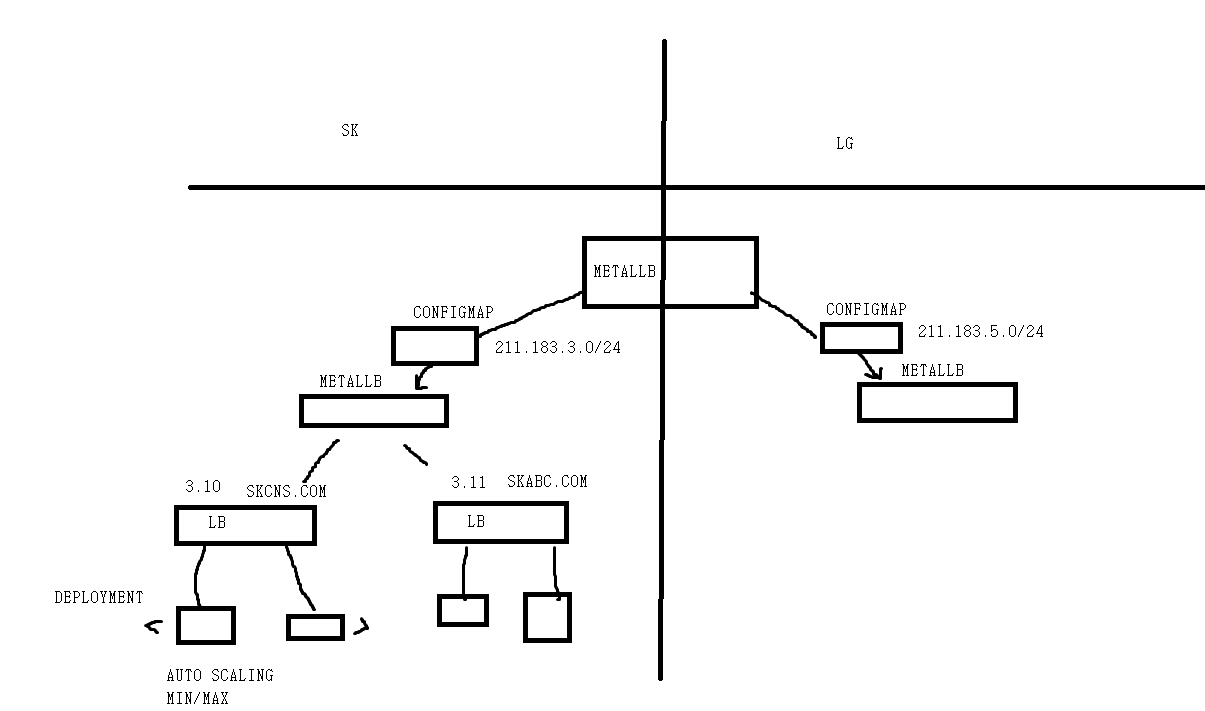
이를 통해, MetalLB 배포시 ConfigMap 을 이용하여 각 MetalLB 가 관리할 주소 Pool 을 서로 다르게 지정해줄 수 있다
- 위와 같이 고객사가 두 곳이 있을 경우, ConfigMap 을 이용해 각 고객사마다 MetalLB 를 배치하여, 서로 다른 주소를 관리하게 할 수 있다
- 이때, 생성되는 LB 서비스는 MetalLB 가 주소를 할당해주며, 아래의 deployment 에는 AutoScale 도 적용해야 한다
3. HPA
p. 170
HPA ( Horizontal Pod Autoscaler ) 는 부하량에 따라 디플로이먼트의 Pod 수를 유동적으로 관리해준다
- HPA 가 자원을 요청할 때, 메트릭 서버를 통해 계측값을 전달 받는다
- metric Server 는 각 Pod 의 자원 사용량 정보를 수집하기 위한 도구로, k8s 와 같은 경우 kubelet 으로 부터 정보를 받아 Api 서버에 보내준다
- metric Server 는 master 의 api server 에 속해있으며, kubelet & metric server & api server 는 모두 api 를 통해 통신한다
HPA 를 통한 AutoScale 구성
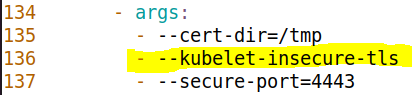
메트릭 서버를 인터넷으로부터 직접 설치하게 되면, 공인 인증서를 통한 인증이 먼저 수행되어야 한다. 하지만 우리는 해당 인증서 발급을 하지 않은 상태이므로, 이 단계를 bypass 해도 문제 없도록, --kubulet-insecure-tls 를 작성해야 한다
- ssl 인증서는 https 통신을 통해 통신간의 모든 데이터를 암호화 한다. 이는 보안이 적용된 통신 채널을 제공해주는 것이다. 이때, 이 인증서 최고 보안 기관은 Root CA 이다
- Pod 의 AUTOScale 은 지정된 자원 사용량의 제한을 확인하고, 이를 넘어서는 경우 수평적인 확장을 하게 된다. 따라서 Pod 가 어느정도의 자원을 할당 받았는지 미리 지정해두어야 한다
1000m 이 1 개의 Cpu
500m : 0.5 개
200m : 0.2 개

- 최소 0.2 개를 보장하며, 만약 다른 포드에서 cpu 를 사용하고 있지 않아 물리 자원 ( cpu ) 에 여유가 있다면, 이를 확장하여 최대 0.5 개까지 사용하겠다는 의미다
Quiz
- hpa, deployment, svc 를 배포
replicas 3, svc : lb
- http://211.183.3.201 로 접속 확인
- hpa 를 이용하여 pod 의 cpu 사용량이 10% 를 넘어서게 되면 수평확장을 통해 최대 20개까지 사용가능하도록 하라. 단, min -> 1 개 로 지정한다
Quiz. 그렇다면 replica 는 몇이 되는건가?? 3?? 1?? = 1이 된다
- 외부에서 트래픽을 보내본다. 외부에서 http://211.183.3.201 로 ab 를 이용하여 트래픽을 보내본다. 몇개까지 늘어나고 ab 중지 된 뒤 몇개까지 줄어드는가?
Metric Server 배포
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml- metric-server 소스 코드 다운
- 인증을 필요로 하지 않게 설정 추가
- 배포해주자
Pod & SVC 배포 및 확인
apiVersion: apps/v1
kind: Deployment
metadata:
name: autoscaletest
spec:
selector:
matchLabels:
color: black
replicas: 3
template:
metadata:
labels:
color: black
spec:
containers:
- name: autoscaletest-nginx
image: nginx
ports:
- containerPort: 80
resources:
limits:
cpu: 500m # 최대 0.5 개 까지
requests:
cpu: 200m #최소 0.2 개 보장
---
apiVersion: v1
kind: Service
metadata:
name: autoscaletest-lb
spec:
ports:
- name: nginx-port
port: 80
selector:
color: black
type: LoadBalancer- 위와 같이 Deployment 와 MetalLB 를 배포하게 작성하자

- 배포해주자

- 203 으로 주소가 할당되었다
- 잘 접속된다
HPA 배포 및 삭제
Deployment 일 경우, HPA 는 Deployment 의 Pod 들의 평균 자원 사용량을 확인한다

- Deployment 의 Pod 들의 평균 Cpu 사용량이 10 퍼센트가 넘어가면 AutoScaling 하게 설정하였다. 이는 최소 1, 최대 10이다
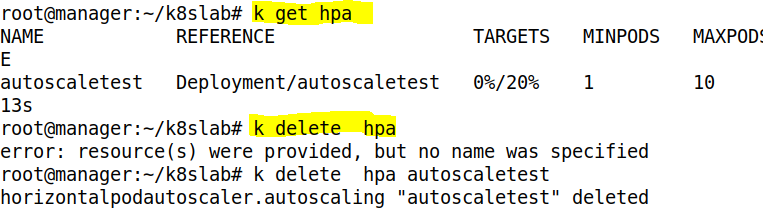
- 위와 같이 배포된 HPA 를 삭제할 수 있다
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: test-hpa
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: autoscaletest
targetCPUUtilizationPercentage: 20- 위와 같이 파일 형태로 작성하여 배포도 가능하다
Apache Benchmark 를 이용한 AutoScale 확인
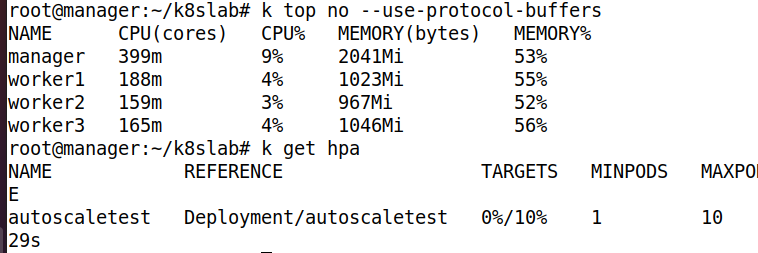
- 현재 상태를 확인하자

- ab 를 사용하기 위해 패키지를 설치하자
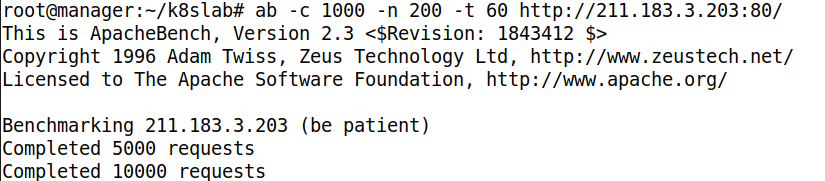
- ab 명령어는 반드시 마지막에 / 로 끝나야 한다
- n 200, c 1000, t 60 의 의미는 60초간 동시 수행자 200명이 1000번 누르는 것이다

- 다시 상태를 확인하면, Cpu 사용량이 늘어나서 Replicas 가 늘어났다
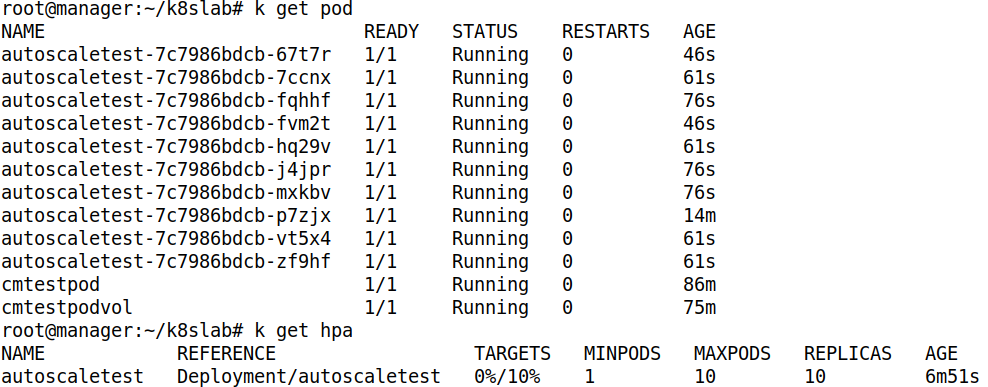
- 최대 개수만큼 늘어났다
- hpa 를 확인하면, replicas 수가 바뀌었다. 이는 deployment 의 replicas 가 10으로 변경된 것이다

- 부하가 종료되면, replicas 가 min 인 1 로 변경된다
- hpa 를 확인하면, replicas 수가 바뀌었다. 이는 deployment 의 replicas 가 10으로 변경된 것이다

- ab 명령 종료시 1 개로 줄어들었다
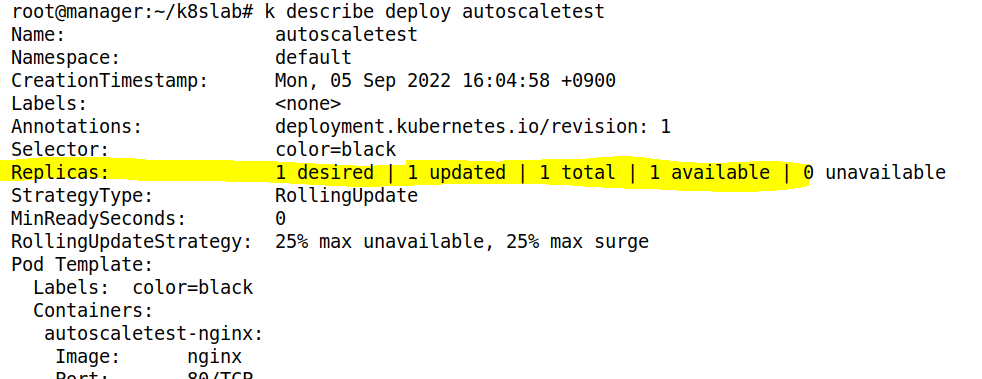
- HPA 배포시, 해당 Deployment 의 replicas 는 설정한 min 으로 변경된다
4. NFS
NFS 환경을 구축해보자
apt install -y nfs-server # master 에 서버 설치
apt install -y nfs-common # worker 에 Client 설치- 실질적인 nfs Client 는 Pod 이다. 허나 Node 에 설치했다. 이는 Pod 에 접속하기 위해서는 실질적으로 Node 에 접속하여, Node 가 Pod 에 접속하는 것이기에 Node 에 설치한다
Quiz
- 211.183.3.100 에 nfs-server 구축
- master 에 /shared 디렉토리를 생성하고 권한을 777 로 설정
- /etc/exports 에 /shared 를 외부에 공개하도록 설정한다. 단, 포드에서만 접속이 가능해야 한다. 즉, Pod 의 주소만 허용하게 해야한다
- nfs-server 활성화 & 실행
- 매니페스트 파일을 통해 Pod 를 배포하고, 포드의 /mnt 를 nfs-server 의 /shared 와 mount
- master 에서 /shared 에 임의 파일을 생성하고, 모든 포드에서 exec 를 통해 해당 파일을 볼 수 있는지 확인
nfs-server 구축

- nfs-server 가 동작중인지 확인하자
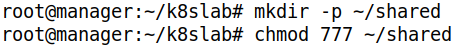
- 제공할 디렉토리를 생성하고, 퍼미션을 설정하자
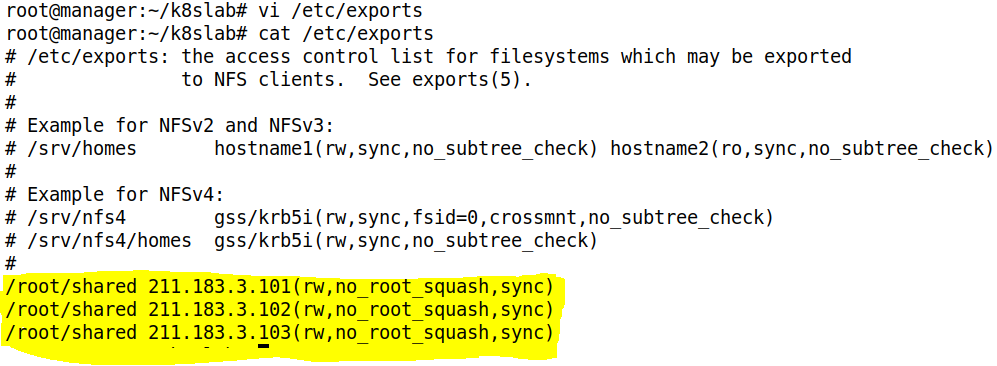
- 외부에 접근을 허용할 디렉토리와 허용 Ip 를 설정하자
- no_root_squash 를 하면, 외부 노드에서 작성한 파일을 로컬 ( nfs-server ) 에서 확인했을 때, root 가 작성한 것으로 간주해준다 ( 파일의 소유주를 root 로 설정 )
- 211.183.3.0/24 or 211.183.3.*/24 로 한 줄만 써줘도 된다

- 방화벽을 비활성화 시키고, nfs-server 을 재시작시켜서 설정을 반영하자
Pod 배포
apiVersion: v1
kind: Pod
metadata:
name: nfs-pod
spec:
containers:
- name: nfs-mount-container
image: busybox
args: [ "tail", "-f", "/dev/null" ]
volumeMounts:
- name: nfs-volume # 사용할 볼륨
mountPath: /mnt # pod 의 마운트할 디렉토리
volumes:
- name : nfs-volume
nfs: # nfs-server 설정
path: /root/shared # 마운트할 server 의 디렉토리
server: 211.183.3.100 # server 의 주소- 위와 같이 작성하여 배포하자
- 배포해주자
Mount 확인

- master 에서 파일을 하나 생성하면, Bind 된 Pod 의 지정 디렉토리에서 파일을 확인할 수 있다

멋진 엔지니어가 될 때까지