앞선 BFS 풀이
문제 설명

생각 정리
// dfs 함수 내에서 탐색할 단어와 target단어가 같다면
// 최소변환 과정을 업데이트 시켜줘야함 (BFS에서는 이 과정이 필요가 없음)
// 리턴한다.
// words 배열을 탐색한다.
// 해당 idx를 방문하지 않았다면
//탐색할 단어와 target단어를 비교하면서 '한개의 알파벳만 다른지' 확인한다.
//한개의 알파벳만 다르다면
//해당 idx를 방문표시한다.
//해당 단어를 가지고 dfs함수를 부른다.
//방문표시를 해제한다. (재귀함수에서 리턴이 되었다는 것은, 이전단계로 돌아왔다는 것이며, 이는 해당 idx를 방문하지 않음을 의미하기 때문에 방문표시를 해제한다.)
정리된 생각에 대한 논리
BFS(너비 우선 탐색)로 풀이를 할 때에는 처음 찾은 변환과정이 가장 짧은 변환과정이라고 할 수 있기 때문에, 가장 짧은 변환과정을 업데이트하는 과정을 따로 거치지 않았다.
하지만 DFS(깊이 우선 탐색)는 처음 찾은 변환과정이 가장 짧은 변환과정이라고 할 수 없기 때문에, 가장 짧은 변환과정을 업데이트하는 과정을 거쳐야한다. (이것을 하지 않았을 때는 모든 테스트 케이스를 통과하지 못했다.)
나는 이것이 DFS와 BFS문제의 가장 큰 차이점이라고 생각한다.
완성
class Solution {
static boolean[] visited;
static int answer = 0;
public int solution(String begin, String target, String[] words) {
visited = new boolean[words.length];
dfs(begin, target, words, 0);
return answer;
}
static void dfs(String begin, String target, String[] words, int cnt) {
if(begin.equals(target)) {
if(answer >= cnt || answer == 0) {
answer = cnt;
}
//answer는 target을 찾는데 까지 걸린 단계를 의미한다.
//answer이 cnt보다 크거나 같은 경우, 즉 기존에 걸린 단계수 가 이번에 찾은 단계수보다 크거나 같다면, answer는 업데이트 된다. (answer가 0일 때도 업데이트 해준다.)
return ;
}
for(int i=0; i<words.length; i++) {
if(visited[i]) continue;
int count = 0;
for(int j=0; j<begin.length(); j++) {
if(begin.charAt(j) == words[i].charAt(j)){
count++;
}
}
if(count == begin.length()-1) {
visited[i] = true;
dfs(words[i], target, words, cnt+1);
visited[i] = false;
}
}
}
}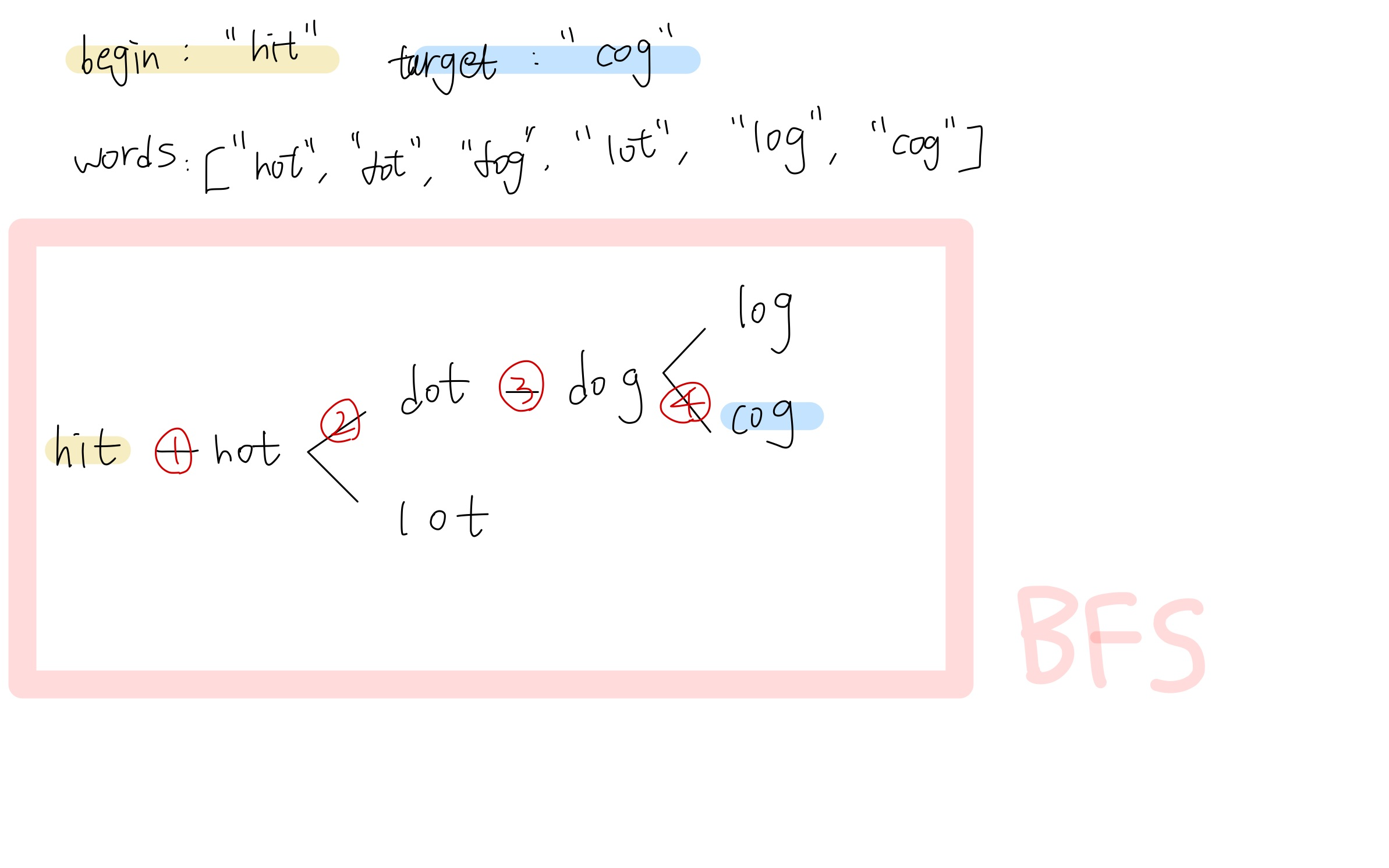
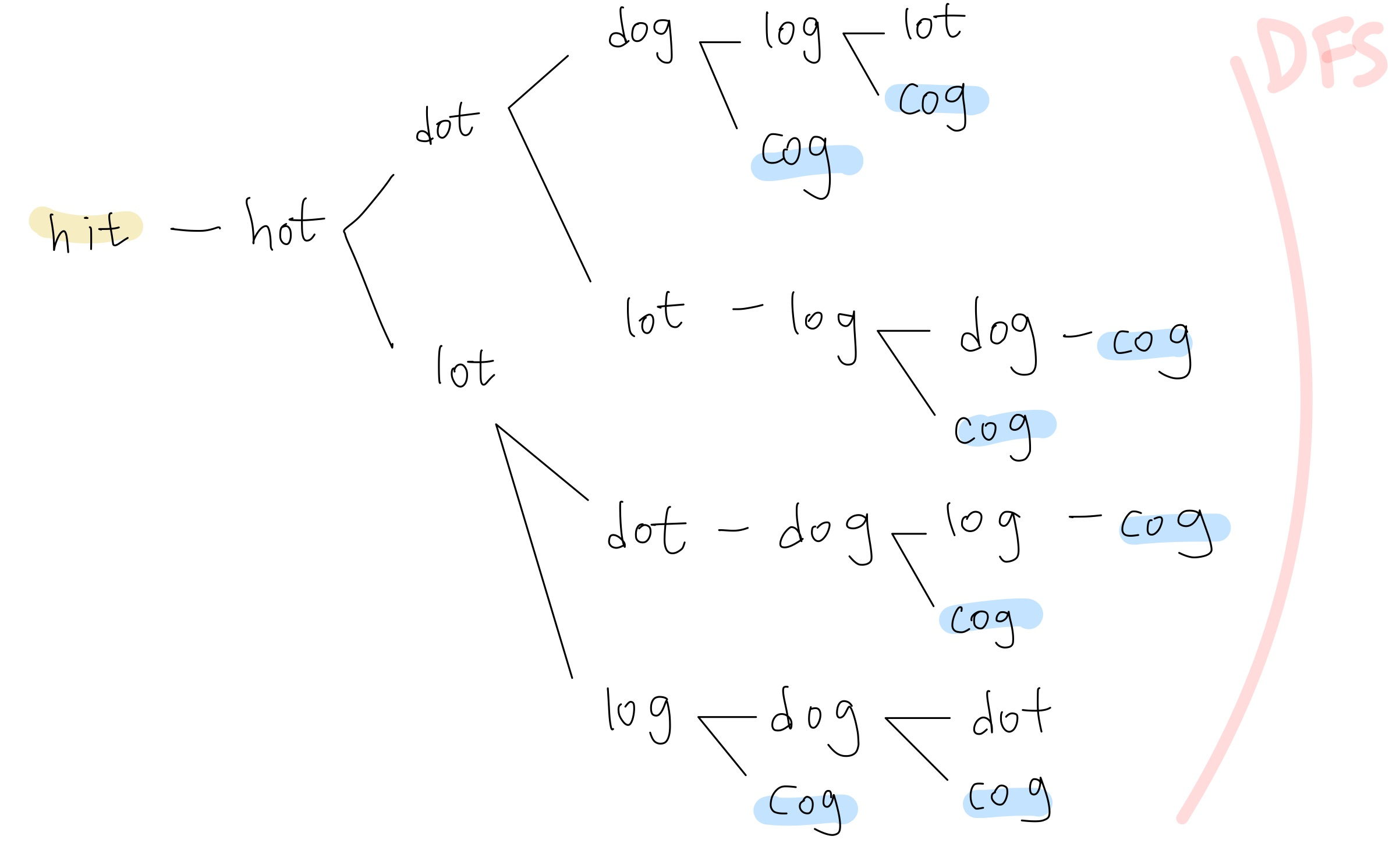
내가 생각하는 이 문제에 대한 BFS와 DFS의 과정은 다음과 같다.
(DFS보단 백트래킹으로 보는게 맞지 않나 싶다.)

배우고 성장하는 개발자가 되기!