목표
- 정렬의 다양한 방법과 구현 방법에 대해 배운다.
- 스택, 큐의 개념과 활용법에 대해 배운다.
- 해쉬 개념과 활용법에 대해 배운다.
- 정렬 : 데이터를 순서대로 나열하는 방법
- 스택, 큐 : 들어가고 나오는 곳이 정해져 있는 자료구조
- 스택 : last in, first out
- 큐 : first in, first out - 해쉬 : 해쉬알고리즘을 통해 문자열을 고정된 길이의 데이터로 만들 수 있다.
⠀
버블 정렬
가장 기본 적인 정렬 방법으로 첫 번째 자료와 두 번째 자료를 비교해서 바꾸고, 두 번째, 세 번재 자료를 비교해서 바꾸는 식으로 교환하면서 자료를 정렬하는 방식이다.
파이썬에서는 Swap 함수가 잘 구현되어 있다.
a,b = b,a라고 작성하면 된다.
>>> a = 3
>>> b = 4
>>> a, b = b, a
>>> print(a)
4
>>> print(b)
3Q. 다음과 같이 숫자로 이루어진 배열이 있을 때, 오름차순으로 버블 정렬을 이용해서 정렬하시오.
input = [4, 6, 2, 9, 1]
코드 ↓
input = [4, 6, 2, 9, 1]
def bubble_sort(array):
n = len(array)
for i in range(n - 1):
for j in range(n - i - 1):
if array[j] > array[j+1]:
array[j], array[j+1] = array[j+1], array[j]
return
bubble_sort(input)
print(input)버블 정렬의 시간 복잡도는 이다.
⠀
선택 정렬
선택 해서 정렬하는 방법
선택 정렬도 각 배열을 계속해서 탐색하는 방식이라서 2중 반복문을 사용하게 된다.
버블 정렬과 선택 정렬이 다른 점은 "최솟값"을 찾아 변경하는 것이다. min_index라는 변수를 통해 각각의 인덱스들과 비교하고, 내부의 반복문이 끝나면, 최소 값의 인덱스와 i의 값들을 교체해준다.
input = [4, 6, 2, 9, 1]
def selection_sort(array):
n = len(array)
for i in range(n - 1):
min_index = i
for j in range(n - i):
if array[i+j] < array[min_index]:
min_index = i + j
array[i], array[min_index] = array[min_index], array[i]
return array
selection_sort(input)
print(input) # [1, 2, 4, 6, 9] 가 되어야 합니다!손으로 하나씩 단계를 그려보면 이해하기 쉽다!
⠀
삽입 정렬
삽입 정렬은 전체에서 하나씩 올바른 위체에 "삽입"하는 방식이다.
선택 정렬은 현재 데이터의 상태와 상관없이 항상 비교하고 위치를 바꾸지만, 삽입 정렬은 필요할 때만 위치를 변경하므로 더 효율적인 방식이다.
삽입 정렬을 항상 정렬된 상태를 유지하면서 정렬하는 방식이기 때문에 새로운 원소가 들어오면 자기 자리를 찾아서 이동하는 식으로 정렬이 된다.
1번째 : [4, 6, 2, 9, 1]
⠀⠀⠀⠀⠀⠀← 비교!
2번째 : [4, 6, 2, 9, 1]
⠀⠀⠀⠀⠀⠀← ← 비교!
3번째 : [2, 4, 6, 9, 1]
⠀⠀⠀⠀⠀⠀← ← ← 비교!
4번째 : [2, 4, 6, 9, 1]
⠀⠀⠀⠀⠀⠀← ← ← ← 비교!
1만큼 비교했다가, 1개씩 늘어나면서 반복하게 된다.
for i in range(1, 5):
for j in range(i):
print(i - j)이 for문 구조를 사용하면 된다.
2번째 for문에서 i(=1)을 사용하는 이유는 배열의 첫번째 원소는 정렬되었다고 생각하고 정렬을 시작하기 때문이다. 그래서 두번째 원소를 첫번째 원소와 비교하여 더 큰 수를 뒤로 보내는 작업을 한다.
input = [4, 6, 2, 9, 1]
def insertion_sort(array):
n = len(array)
for i in range(1, n):
for j in range(i): # print(i-j)
if array[i-j-1] > array[i-j]:
array[i-j-1], array[i-j] = array[i-j], array[i-j-1]
else:
break # 비교할 필요가 없을 때 break 를 한다. 즉, 더 효율적임
return
insertion_sort(input)
print(input) # [1, 2, 4, 6, 9] 가 되어야 합니다!삽입 정렬의 시간 복잡도는 만큼 걸린다. 하지만, 최선의 경우에는 만큼의 시간 복잡도가 걸릴 수 있다. 거의 정렬된 배열이 들어온다면 break 문에 의해 2번재 for 문이 반복되지 않을 수 있기 때문이다.
⠀
병합 - merge
병합 정렬은 배열의 앞부분과 뒷부분의 두 그룹으로 나누어 각각 정렬한 후 병합하는 작업을 반복하는 알고리즘이다.
A 라고 하는 배열이 1, 2, 3, 5 로 정렬되어 있고,
B 라고 하는 배열이 4, 6, 7, 8 로 정렬되어 있다면
이 두 집합을 합쳐가면서 정렬하는 방법이다.
array_a = [1, 2, 3, 5]
array_b = [4, 6, 7, 8]
def merge(array1, array2):
array_c = []
array1_index = 0
array2_index = 0
while array1_index < len(array1) and array2_index < len(array2):
if array1[array1_index] < array2[array2_index]:
array_c.append(array1[array1_index])
array1_index += 1
else:
array_c.append(array2[array2_index])
array2_index += 1
if array1_index == len(array1):
while array2_index < len(array2):
array_c.append(array2[array2_index])
array2_index += 1
if array2_index == len(array2):
while array1_index < len(array1):
array_c.append(array1[array1_index])
array1_index += 1
return array_c
print(merge(array_a, array_b)) # [1, 2, 3, 4, 5, 6, 7, 8] 가 되어야 합니다!이 코드는 내 힘으로 직접 풀어보려고 했는데, 풀다보니 각 배열의 인덱스가 필요하다는 것을 끝에가서 알게 되었고, 다시 생각해 보다 강의를 보았는데, for 문이 아닌 while 문을 사용하여 문제를 풀면 더 쉽게 풀 수 있다는 것을 알게 되었다.
그래서 while문을 이용하여 첫번째, 두번째 배열을 컨트롤 할 수 있다는 것을 알게 되었다.
첫번째, 두번째 배열의 인덱스를 각각 정해두고, 각 인덱스 별로 비교하여 더 작은 것을 array_c에 저장하고, index를 한개 올리고 하는 방식으로 배열을 병합시킬 수 있다.
⠀
병합 정렬 - mergeSort
위에 내용들을 단지 병합만 했을 뿐이다. 그럼 병합 정렬을 무엇인가?
분할 정복의 개념을 적용해야 한다.
- 분할 정복은 문제를 작은 2개의 문제로 분리하고 각각을 해결한 다음, 결과를 모아서 원래의 문제를 해결하느 전략이다.
예를 들어서 [5, 4] 라는 배열이 있다면
이 배열을 [5] 와 [4] 를 가진 각각의 배열로 작은 2개의 문제로 분리해서 생각하는 것입니다.
그러면 이 둘을 합치면서 정렬한다면? 결국 전체의 정렬된 리스트가 될 수 있습니다.
⠀
이 개념을 조금 더 확대해서 생각해보겠습니다.
⠀
[5, 3, 2, 1, 6, 8, 7, 4] 이라는 배열이 있다고 하겠습니다. 이 배열을 반으로 쪼개면
[5, 3, 2, 1][6, 8, 7, 4] 이 됩니다. 또 반으로 쪼개면
[5, 3][2, 1] [6, 8][7, 4] 이 됩니다. 또 반으로 쪼개면
[5][3] [2][1] [6][8] [7][4] 이 됩니다.
⠀
이 배열들을 두개씩 병합을 하면 어떻게 될까요?
[5][3] 을 병합하면 [3, 5] 로
[2][1] 을 병합하면 [1, 2] 로
[6][8] 을 병합하면 [6, 8] 로
[7][4] 을 병합하면 [4, 7] 로
그러면 다시!
[3, 5] 과 [1, 2]을 병합하면 [1, 2, 3, 5] 로
[6, 8] 와 [4, 7]을 병합하면 [4, 6, 7, 8] 로
그러면 다시!
[1, 2, 3, 5] 과 [4, 6, 7, 8] 를 병합하면 [1, 2, 3, 4, 5, 6, 7, 8] 이 됩니다.
⠀
어떤가요? 문제를 쪼개서 일부분들을 해결하다보니, 어느새 전체가 해결되었습니다!
이를 분할 정복, Divide and Conquer 라고 합니다.
==> 재귀 함수 형식!
# [5, 3, 2, 1, 6, 8, 7, 4] 맨 처음 array 이고,
# left_arary [5, 3, 2, 1] 이를 반으로 자른 left_array
# right_arary [6, 8, 7, 4] 반으로 자른 나머지가 right_array 입니다!
# [5, 3, 2, 1] 그 다음 merge_sort 함수에는 left_array 가 array 가 되었습니다!
# left_arary [5, 3] 그리고 그 array를 반으로 자르고,
# right_arary [2, 1] 나머지를 또 right_array 에 넣은 뒤 반복합니다.
# [5, 3]
# left_arary [5]
# right_arary [3]
# [2, 1]
# left_arary [2]
# right_arary [1]
# [6, 8, 7, 4]
# left_arary [6, 8]
# right_arary [7, 4]
# [6, 8]
# left_arary [6]
# right_arary [8]
# [7, 4]
# left_arary [7]
# right_arary [4]이렇게 배열을 반으로 쪼개고, 재귀함수를 이용해서 또 쪼개서 배열의 길이가 1이 될때까지 쪼개고, 그 다음 2개씩 쪼개진 배열들끼리 병합 정렬하여 최종적으로 병합하며 정렬하는 방식으로 문제를 풀 수 있다.
array = [5, 3, 2, 1, 6, 8, 7, 4]
def merge_sort(array):
if len(array) <= 1:
return array
mid = len(array) // 2
left_array = merge_sort(array[0:mid])
right_array = merge_sort(array[mid:])
return merge(left_array, right_array)
def merge(array1, array2):
result = []
array1_index = 0
array2_index = 0
while array1_index < len(array1) and array2_index < len(array2):
if array1[array1_index] < array2[array2_index]:
result.append(array1[array1_index])
array1_index += 1
else:
result.append(array2[array2_index])
array2_index += 1
if array1_index == len(array1):
while array2_index < len(array2):
result.append(array2[array2_index])
array2_index += 1
if array2_index == len(array2):
while array1_index < len(array1):
result.append(array1[array1_index])
array1_index += 1
return result
print(merge_sort(array)) # [1, 2, 3, 4, 5, 6, 7, 8] 가 되어야 합니다!⠀
스택
한쪽 끝으로만 자료를 넣고 뺄 수 있는 자료 구조이다.
Last in, First Out = LIFO 자료구조라 말하기도 한다.
가장 마지막에 넣은 것이 가장 빨리 나온다.
- push(data) : 맨 앞에 데이터 넣기
- pop() : 리스트의 마지막 항목을 삭제하고 돌려줌
- peek() : 맨 앞의 데이터 보기
- isEmpty() : 스택이 비었는지 안 비었는지 여부 반환해주기
=> 스택은 데이터를 넣고 뽑는 걸 자주하는 자료구조다. 링크드 리스트와 유사하게 구현할 수 있다!
stack = [] ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀# 빈 스택 초기화
stack.append(4)⠀⠀⠀⠀⠀⠀# 스택 push(4)
stack.append(3)⠀⠀⠀⠀⠀⠀# 스택 push(3)
top = stack.pop()⠀⠀⠀⠀⠀# 스택 pop
print(top) ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀# 3!
range() 함수 : range(시작하는 점, 끝나는 점, 증감)
Q. 수평 직선에 탑 N대를 세웠습니다. 모든 탑의 꼭대기에는 신호를 송/수신하는 장치를 설치했습니다. 발사한 신호는 신호를 보낸 탑보다 높은 탑에서만 수신합니다. 또한 ,한 번 수신된 신호는 다른 탑으로 송신되지 않습니다.
⠀
예를 들어 높이가 6, 9, 5, 7, 4 인 다섯 탑이 왼쪽으로 동시에 레이저 신호를 발사합니다.
그러면, 탑은 다음과 같이 신호를 주고 받습니다.
⠀
높이가 4인 다섯 번째 탑에서 발사한 신호는 높이가 7인 네 번째 탑에서 수신하고,
높이가 7인 네 번째 탑의 신호는 높이가 9인 두 번째 탑이,
높이가 5인 세 번째 탑의 신호도 높이가 9인 두 번째 탑이 수신합니다.
⠀
높이가 9인 두 번째 탑과 높이가 6인 첫 번째 탑이 보낸 레이저 신호는
어떤 탑에서도 수신할 수 없습니다.
⠀
이 때, 맨 왼쪽부터 순서대로 탑의 높이를 담은 배열 heights가 매개변수로 주어질 때 각 탑이 쏜 신호를 어느 탑에서 받았는지 기록한 배열을 반환하시오.

레이저를 왼쪽으로 쏘고 있기 때문에, 자신보다 높은 왼쪽 탑들과 위치를 비교하며 레이저를 맞은 탑의 위치를 배열로 설정해주면 된다.
탑의 높이가 담긴 배열들을 stack이라 하면, 맨 마지막의 값부터 하나하나 pop해서 앞의 원소들과 크기를 비교한다.
answer 배열을 0으로 초기화를 미리 해주는 것이 좋다!
=> answer = [0] * len(heights)
top_heights = [6, 9, 5, 7, 4]
# 총 O(N^2) 의 시간 복잡도
def get_receiver_top_orders(heights):
answer = [0] * len(heights)
while heights: # O(N)
height = heights.pop()
# [6, 9, 5, 7]
for idx in range(len(heights)-1, 0, -1): # O(N)
if heights[idx] > height:
answer[len(heights)] = idx + 1
break
return answer
print(get_receiver_top_orders(top_heights)) # [0, 0, 2, 2, 4] 가 반환되어야 한다!⠀
큐
한쪽 끝으로 자료를 넣고, 반대쪽에서는 자료를 뺄 수 있는 선형구조
First In First Out = FIFO
=> 순서대로 처리해야 하는 일이 있을 때 큐를 사용한다.
- enqueue(data) : 맨 뒤에 데이터 추가하기
- dequeue() : 맨 앞의 데이터 뽑기
- peek() : 맨 앞의 데이터 보기
- isEmpty() : 큐가 비었는지 안 비었는지 여부 반환해주기
큐는 데이터 넣고 뽑는 걸 자주하는 자료 구조이다. 그래서 링크드 리스트를 사용한다. 그러나 스택과 다르게 큐는 시작과 끝의 노드르 전부 가지고 있어야 한다. self.head와 self.tail의 노드를 전부 가지고 있어야 한다.
enqueue
queue = [4] -> [2]
큐에 [3]을 enqueue 하면
[4] -> [2] -> [3] 이 된다.
여기서 [4] 는 self.head, [3]은 self.tail로 정해주어야 한다. 하지만 현재 queue의 head는 [4], tail은 [2] 이기 때문에 먼저
tail.next = new_node 현재 tail([2])에 새로운 노드를 포인터로 달아주고, tail을 새로운 노드로 저장시켜 주면 된다. -> tail = new_node
*** 그러나 이렇게만 하면 에러가 발생한다. 초기 상태는 head와 tail 모두가 None 이기 때문에 에러가 발생할 수 있다. 그래서 isEmpty() 함수로 큐에 노드가 있는지 미리 점검하는 코드를 작성해 주어야 한다.
dequeue
head ⠀⠀⠀⠀⠀tail
[3] -> [4] -> [5] 에서 제일 앞에 있는 [3]을 빼는 함수이다.
head ⠀ tail
[4] -> [5] 가 되게 하면 되므로 head에 [4]를 저장하면 되고, 미리 저장해둔 self.head(=[3])을 반환해주면 된다.
큐가 없을 때의 상황도 미리 작성해준다.
peek
제일 위에 있는 (head) 노드를 반환해 주면된다.
return self.head.data 해주면 된다.
큐가 없을 때의 상황도 미리 작성해준다.
isEmpty
링크드 리스트의 가장 위에 있는 노드를 반환해주면 된다.
return self.head is None
class Node:
def __init__(self, data):
self.data = data
self.next = None
class Queue:
def __init__(self):
self.head = None
self.tail = None
def enqueue(self, value):
new_node = Node(value)
if self.is_empty():
self.head = new_node
self.tail = new_node
return
self.tail.next = new_node
self.tail = new_node
def dequeue(self):
if self.is_empty():
return "Queue is Empty"
delete_node = self.head
self.head = self.head.next
return delete_node.data
def peek(self):
if self.is_empty():
return "Queue is Empty"
return self.head.data
def is_empty(self):
return self.head is None
queue = Queue()
queue.enqueue(3)
print(queue.peek())
queue.enqueue(4)
print(queue.peek())
queue.enqueue(5)
print(queue.peek())
print(queue.dequeue())
print(queue.peek())
print(queue.is_empty())해쉬
⠀
컴퓨팅에서 키를 값에 매핑할 수 있는 구조인, 연관 배열 추가에 사용되는 자료 구조이다.해시 테이블은 해시 함수를 사용하여 인덱스를 버킷이나 슬록의 배열로 계산한다.
데이터를 다루는 기법 중에 하나로 데이터의 검색과 저장이 아주 빠르게 진행된다.
파이썬의 딕셔너리를 해쉬 테이블이라 부르기도 한다!
dict = {"fast" : "빠른", "slow": "느린"} 찾는 데이터가 있는지 배열을 다 둘러보지 않아도 key 값으로 검색하여 조회할 수 있기 때문에 매우 유용한 자료구조이다.
여기, "fast"라는 key 값이 있는데, 이 key 값을 어떤 index에 넣어야 할지, 어디에서 찾아야 할지 어떻게 알 수 있을까?
=> 바로 해쉬 함수를 사용한다.
hash(object) 를 사용하여 배열에 들어갈 위치를 잡아준다.
>>> hash("fast")
-146084012848775433
이렇게 hash 함수를 사용하면 엄청나게 큰 수가 나오게 되는데, 이를 배열의 길이로 나눈 나머지 값(%) 을 사용하여 index를 사용한다.
만약 배열의 길이가 8이면,
index = hash("fast") % 8 으로 계산하여 0~7 사이의 index 수로 배열의 index를 정할 수 있다.
⠀
딕셔너리에는 put과 get 함수가 필요하다
⠀
put(key, value) : key에 value를 저장하는 함수
⠀
def put(self, key, value):
index = hash(key) % len(self.items)
self.items[index] = valueget(key) : key에 해당하는 value 가져오는 함수
해당 index를 가진 배열의 원소를 반환해주면 된다.
def get(self, key):
index = hash(key) % len(self.items)
return self.items[index]그런데 만약에 해쉬의 값이 같으면 어떻게 해야 할까?? 해쉬 값을 배열의 길이로 나누었더니 똑같은 나머지 수가 나오면 어떻게 될까?
--> 충돌이 생길 것이다.
충돌을 해결하는 첫번째 방법
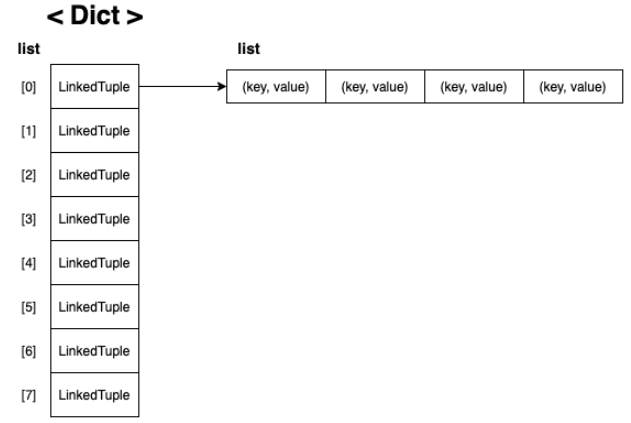
체이닝(Chaining)
링크드 리스트를 사용하는 방식이다.
같은 index 값이 나온 key 끼리 링크드 리스트 처럼 연결시켜 주는 것이다.
[None, None, (fast, "빠른") -> (slow, "느린"), ...]
class LinkedTuple:
def __init__(self):
self.items = []
def add(self, key, value):
self.items.append((key, value))
def get(self, key):
for k, v in self.items:
if k == key:
return vitems라는 배열을 생성하고, add() 함수가 호출 될 때, items 배열의 뒤에 (key, value) 구조로 내용을 붙인다. get() 함수가 호출되면, items 배열에 있는 k, v (key, value) 값을 하나씩 꺼내면서, k와 items에 있는 key 값이 같은지 비교하여 같으면 value 값을 꺼내는 방식으로 함수를 구현한다.
체이닝 방식으로 충돌을 막았으면, 이 방식으로 다시 딕셔너리를 구현해보자
class LinkedDict:
def __init__(self):
self.items = []
for i in range(8):
self.items.append(LinkedTuple())
def put(self, key, value):
index = hash(key) % len(self.items)
self.items[index].add(key, value)
# 만약, 입력된 key가 "fast" 인데 index 값이 2가 나왔다.
# 현재 self.items[2] 가 [("slow", "느린")] 이었다!
# 그렇다면 새로 넣는 key, value 값을 뒤에 붙여주자!
# self.items[2] == [("slow", "느린") -> ("fast", "빠른")] 이렇게!
def get(self, key):
index = hash(key) % len(self.items)
return self.items[index].get(key)
# 만약, 입력된 key가 "fast" 인데 index 값이 2가 나왔다.
# 현재 self.items[2] 가 [("slow", "느린") -> ("fast", "빠른")] 이었다!
# 그렇다면 그 리스트를 돌면서 key 가 일치하는 튜플을 찾아준다.
# ("fast", "빠른") 이 일치하므로 "빠른" 이란 값을 돌려주자!⠀
충돌을 해결하는 두번째 방법
개방 주소법(Open Addressing)
배열의 다음 남는 공간에 충돌된 (key, value)를 넣는 것이다.
fast 의 해쉬 값이 3이 나와서 items[3] 에 들어갔다고 하는데,
slow 의 해쉬 값이 동일하게 3이 나왔다.
그러면, items[4] 를 본다. items[4]도 이미 차 있다.
그러면 그 다음 칸인 items[5] 를 봅니다.
비어 있으니까 items[5] 에 slow의 value 값을 넣는다.
정리
해쉬 테이블은 "키"와 "데이터"를 저장함으로써 즉각적으로 데이터를 받아오고 업데이트하고 싶을 때 사용하는 자료구조이다.
⠀
해쉬 함수는 임의의 길이를 갖는 메시지를 입력하여 고정된 길이의 해쉬값을 출력하는 함수이다.
⠀
해쉬 테이블의 내부 구현은 키를 해쉬 함수를 통해 임의의 값으로 변경한 뒤, 배열의 인덱스로 변환하여 해당하는 값에 데이터를 저장한다.
⠀
만약, 해쉬 값, 인덱스가 중복되어 충돌이 일어나면 ->체이닝과개방 주소법방법으로 해결할 수 있다.
⠀
해쉬 테이블은 시간은 빠르되
공간을 대신 사용하는 자료구조라고 생각하시면 됩니다.
문제
Q. 오늘 수업에 많은 학생들이 참여했습니다. 단 한 명의 학생을 제외하고는 모든 학생이 출석했습니다.
⠀
모든 학생의 이름이 담긴 배열과 출석한 학생들의 배열이 주어질 때, 출석하지 않은 학생의 이름을 반환하시오.⠀all_students = ["나연", "정연", "모모", "사나", "지효", "미나", "다현", "채영", "쯔위"] present_students = ["정연", "모모", "채영", "쯔위", "사나", "나연", "미나", "다현"]
student 딕셔너리에 모든 학생의 이름이 되는 key 값을 hash()를 통해 저장하고, present_student를 돌면서 student에 저장되어 있는 출석한 학생의 키 값들을 삭제한다.
그러면 student 딕셔너리에는 결석한 학생의 이름만 남아 있게 된다.
del 예약어
예약어는 뒤에 한 칸을 띄고 사용한다.
파이썬에서 사용하는 예약어로 if, for, or, and 등이 있다고 한다.
del array[index] 형태로 사용한다. 즉, 요소의 위치를 지정해서 삭제할 수 있다.
범위 연산자 (:) 슬라이싱을 이용하면 범위에 한에서도 삭제할 수 있다.
++ remove()
함수로 array의 요소를 삭제한다.
-> array.remove() 로 사용된다.
한 번에 하나의 요소만 삭제가 가능하다.
dict.keys() : 딕셔너리의 key만을 모아서 key 값을 돌려준다.
주로 for 문을 이용하여 딕셔너리의 key 값을 확인한다.
for key in dict.keys():
print(key)정답
all_students = ["나연", "정연", "모모", "사나", "지효", "미나", "다현", "채영", "쯔위"]
present_students = ["정연", "모모", "채영", "쯔위", "사나", "나연", "미나", "다현"]
def get_absent_student(all_array, present_array):
student_dict = {}
for key in all_array:
student_dict[key] = True
for key in present_array:
del student_dict[key]
for key in student_dict.keys():
return key
return
print(get_absent_student(all_students, present_students))숙제
Q1.
다음과 같이 숫자로 이루어진 배열이 두 개가 있다.
하나는 상품의 가격을 담은 배열이고, 하나는 쿠폰을 담은 배열이다.
쿠폰의 할인율에 따라 상품의 가격을 할인 받을 수 있다.
이 때, 최대한 할인을 많이 받는다면 얼마를 내야 하는가?
단, 할인쿠폰은 한 제품에 한 번씩만 적용 가능하다.
=> 제일 할인을 많이 받으려면 가장 비싼 금액에서 가장 큰 할인율을 받으면 된다.
.sort(revers=True) 함수를 사용하여 내림차순(큰 순서)으로 정렬을 한다.
그렇게 되면, 가장 큰 금액의 상품을 가장 큰 할인율로 바로 할인할 수 있게 된다.
각 배열의 index를 정하고, max_price에 가장 많이 할인된 금액들을 차곡차곡 더해 나가면, 가장 할인을 많이 받을 수 있는 금액이 나오게 된다.
⠀
shop_prices = [30000, 2000, 1500000]
user_coupons = [20, 40]
# 제일 할인을 많이 받으려면 어떻게 해야 하는지
def get_max_discounted_price(prices, coupons):
prices.sort(reverse=True) # [1500000, 30000, 2000]
coupons.sort(reverse=True) # [40, 20]
prices_index = 0
coupons_index = 0
max_price = 0
while prices_index < len(prices) and coupons_index < len(coupons):
max_price += prices[prices_index] * (100 - coupons[coupons_index]) // 100
prices_index += 1
coupons_index += 1
while prices_index < len(prices):
max_price += prices[prices_index]
prices_index += 1
return max_price
print(get_max_discounted_price(shop_prices, user_coupons))⠀
Q2.
괄호가 바르게 짝지어졌다는 것은 '(' 문자로 열렸으면 반드시 짝지어서 ')' 문자로 닫혀야 한다는 뜻이다. 예를 들어
⠀
()() 또는 (())() 는 올바르다.
)()( 또는 (()( 는 올바르지 않다.
⠀
이 때, '(' 또는 ')' 로만 이루어진 문자열 s가 주어졌을 때, 문자열 s가 올바른 괄호이면 True 를 반환하고 아니라면 False 를 반환하시오.⠀"(())()" # True "((((" # False
문제를 분석하던 중 '('와 ')'는 짝이 이루어져야 한다는 것을 알게 되었다. 그래서 그 짝이 맞지 않으면 False를 반환해 주고, 짝이 맞으면 True를 반환해주면 된다고 생각했다.
하.지.만.
이 수업은 알고리즘 수업이기 때문에 알고리즘 적 사고를 해야 한다는 것이었다!!
그래서 알고리즘적으로 사고를 해서 이 문제를 다시 보면, stack 구조를 사용하면 된다!
'(' 가 있었다면, stack에 쌓아 놓다가, ')'가 나오면 stack에 가장 마지막에 쌓아 놓은 '('를 pop으로 꺼내서 마지막에 stack이 비어있으면 True, 비어 있지 않으면, False를 반환해 주면 된다.
++ 여기서 주의해야 할 점은, ')'가 '('보다 먼저 더 많이 나올 수 있기 때문에 미리 stack에 들어 있는 '('를 체크해서 '('게 없다면 바로 False를 반환해 줄 수 있어야 한다.
s = "((())))"
def is_correct_parenthesis(string):
stack = []
for i in range(len(string)):
if string[i] == "(":
stack.append(i)
elif string[i] == ")":
if len(stack) == 0:
return False
stack.pop()
if len(stack) != 0:
return False
else:
return True
# 이건 그냥 짝 맞춰서 푼 방법 (알고리즘xx)
# first_small_letter_exist = 0
# last_small_letter_exist = 0
# for letter in string:
# if letter == '(':
# first_small_letter_exist += 1
# elif letter == ')':
# last_small_letter_exist += 1
# if first_small_letter_exist == last_small_letter_exist:
# return True
# else:
# return False
print(is_correct_parenthesis(s)) # True 를 반환해야 합니다!
print("정답 = True / 현재 풀이 값 = ", is_correct_parenthesis("(())"))
print("정답 = False / 현재 풀이 값 = ", is_correct_parenthesis(")"))
print("정답 = False / 현재 풀이 값 = ", is_correct_parenthesis("((())))"))
print("정답 = False / 현재 풀이 값 = ", is_correct_parenthesis("())()"))
print("정답 = False / 현재 풀이 값 = ", is_correct_parenthesis("((())"))⠀
Q3.
멜론에서 장르 별로 가장 많이 재생된 노래를 두 개씩 모아 베스트 앨범을 출시하려 한다.
⠀
노래는 인덱스 구분하며, 노래를 수록하는 기준은 다음과 같다.
⠀
1. 속한 노래가 많이 재생된 장르를 먼저 수록한다. (단, 각 장르에 속한 노래의재생 수 총합은 모두 다르다.)
⠀
2. 장르 내에서 많이 재생된 노래를 먼저 수록한다.
⠀
3. 장르 내에서 재생 횟수가 같은 노래 중에서는 고유 번호가 낮은 노래를 먼저 수록한다.
⠀
노래의 장르를 나타내는 문자열 배열 genres와
노래별 재생 횟수를 나타내는 정수 배열 plays가 주어질 때,
⠀
베스트 앨범에 들어갈 노래의 인덱스를 순서대로 반환하시오.# 1 genres = ["classic", "pop", "classic", "classic", "pop"] plays = [500, 600, 150, 800, 2500] # 정답 = [4, 1, 3, 0] ⠀ # 2 genres = ["hiphop", "classic", "pop", "classic", "classic", "pop", "hiphop"] plays = [2000, 500, 600, 150, 800, 2500, 2000] # 정답 = [0, 6, 5, 2, 4, 1]
{ } : 딕셔너리를 선언, 초기화 할 때 사용하는 기호
먼저, 어느 장르가 가장 많이 재생 되었는지 확이해야 하기 때문에 장르와 play 수를 확인할 수 있는 딕셔너리를 만들어서 확인해야 한다.
genre_play_dict = {}
장르 배열에서 장르를 빼오고, 그 장르에 맞는 play 수를 합산해서 어느 장르가 총 play 수가 더 많은지 확인해 보자.
n = len(genre_array)
genre_play_dict = {}
for i in range(n):
genre = genre_array[i]
play = play_array[i]
if genre not in genre_play_dict:
genre_play_dict[genre] = play
else:
genre_play_dict[genre] += playlist에 genre가 없다면, play 수를 입력하고, play가 이미 있다면 play 수를 더해 최종적으로 play 수가 얼마인지 나오게 한다.
각 장르의 총 play 수를 구했으니, 장르 내에서도 정렬을 해야 한다.
장르별 key에 재생 수와 인덱스를 배열로 묶어 배열에 저장하면 된다.
genre_index_play_dict = {}
...
for i in range(n):
if genre not in genre_play_dict:
genre_index_play_dict[genre] = [[i, play]]
else:
genre_index_play_dict[genre].append([i, play])장르의 각 곡의 index와 play 수를 배열로 저장하였다.
{'classic': [[0, 500], [2, 150], [3, 800]], 'pop': [[1, 600], [4, 2500]]}
이제 어느 장르가 더 많이 play 되었고, 그 장르 안에서 어떤 index의 곡이 더 많이 재생되었는지 확인하여 배열에 저장해야 한다.
classic, pop 장르 사이에 어떤 곡이 더 많이 play 되었는지 컴퓨터가 확인하려면, genre_play_dict를 정렬해보면 된다.
genre_play_dict.items() 를 통해 확인해 보면, dict_items([('classic', 1450), ('pop', 3100)])로 딕셔너리의 key - value 값을 배열 형태로 출력해준다.
'classic' : 1450, 'pop' : '3100' 이라는 딕셔너리를 value 값에 따라 정렬하려면 sorted라는 함수를 사용해준다.
- sorted : 정렬할 배열을 기준에 따라 정렬해주는 함수, key 라는 인자에 람다값을 전달해준다.
- 람다값 : 어떤 것을 정렬할지에 대해 정해주는 기준
sorted(genre_play_dict.items(), key=lambda item: item[0]) 이렇게 item[0]으로 기준을 잡으면, 'classic'이 기준이 된다.
item[1]로 잡으면, 1450이 기준이 되어 배열을 정렬할 수 있게 된다.
sorted(genre_play_dict.items(), key=lambda item: item[1])
⠀
⠀
이 정렬대로면, 오름차순으로 정렬 되는데, 내가 구해야 하는 값은 가장 많이 재생된 수이기 때문에 역순으로 정렬되게 설정해 주어야 한다.
sorted(genre_play_dict.items(), key=lambda item: item[1], reverse=True)
⠀
sorted_genre_play_array = sorted(genre_play_dict.items(), key=lambda item: item[1], reverse=True)
# [('pop', 3100), ('classic', 1450)]'pop'이 더 많이 재생된 장르라는 것을 알게 되었으니, 이 장르를 가지고, 그 장르에 해당하는 곡들 중 어느 곡이 더 많이 재생되었는지 확인하고 배열에 넣는 작업만 마무리하면 된다.
result = []
for genre, value in sorted_genre_play_array:
index_play_array = genre_index_play_dict[genre]
sorted_index_genre_play_array = sorted(index_play_array, key=lambda item: item[1], reverse=True)
for i in range(len(sorted_index_genre_play_array)):
if i > 1:
break
else:
result.append(sorted_index_genre_play_array[i][0])
return resultsorted_genre_play_array에서 구분한 genre를
genre_index_play_dict에서 찾는다. genre가 'pop'이라고 하면, index_play_array에는 'pop': [[1, 600], [4, 2500]]이 들어오게 된다. index_play_array를 sorted( ) 시키면 [[4, 2500], [1, 600]]으로 정렬된다.
for 문에 의해서 result 배열에 삽입될 곡을 지정할 수 있게 된다.
문제에서 '노래를 두 개씩 모아' 베스트 앨범에 수록한다고 했으니까 if 문으로 조건을 주고 2개가 넘으면 break으로 for 문을 빠져나가게 했고, result 배열에 들어갈 데이터는 각 곡의 index이기 때문에 sorted_index_genre_play_array[i][0] 으로 곡의 index만 저장할 수 있게 한다.
# 변수 이름이 다를 수 있음
genres = ["classic", "pop", "classic", "classic", "pop"]
plays = [500, 600, 150, 800, 2500]
def get_melon_best_album(genre_array, play_array):
n = len(genre_array)
genre_play_dict = {}
genre_index_play_array_dict = {}
for i in range(n):
genre = genre_array[i]
play = play_array[i]
if genre not in genre_play_dict:
genre_play_dict[genre] = play
genre_index_play_array_dict[genre] = [[i, play]]
else:
genre_play_dict[genre] += play
genre_index_play_array_dict[genre].append([i, play])
# print(genre_play_dict.items())
# print(genre_index_play_array_dict)
sorted_genre_play_array = sorted(genre_play_dict.items(), key=lambda item: item[1], reverse=True)
# print(sorted_genre_play_array)
result = []
for genre, _value in sorted_genre_play_array:
index_play_array = genre_index_play_array_dict[genre]
sorted_by_play_and_index_play_index_array = sorted(index_play_array, key=lambda item: item[1], reverse=True)
print(sorted_by_play_and_index_play_index_array)
for i in range(len(sorted_by_play_and_index_play_index_array)):
if i > 1:
break
result.append(sorted_by_play_and_index_play_index_array[i][0])
return result
print(get_melon_best_album(genres, plays)) # 결과로 [4, 1, 3, 0] 가 와야 합니다!
print("정답 = [0, 6, 5, 2, 4, 1] / 현재 풀이 값 = ", get_melon_best_album(["hiphop", "classic", "pop", "classic", "classic", "pop", "hiphop"], [2000, 500, 600, 150, 800, 2500, 2000]))⠀
⠀
오우 이번주도 역시나 빡센 공부였다. 하지만, 알고리즘 문제를 어떤 식으로 풀어나가야 하는지 조금씩 알게 되는 수업이었다. 문제들을 혼자 힘으로 풀어보거나, 어떤 식으로 방향을 잡아 나가야 하는지 알 수 있었던 것 같다.
아직 혼자 힘으로 문제를 풀라고 하면 어떤 개념을 적용해서 풀어야 할지는 모르겠지만, 여러 문제를 풀어가면서 그 유형을 익혀야겠다고 생각했다.
혼자 힘으로 생각한 문제풀이는 알고리즘적인 방식이 아니라 그냥 문제 해결 방식이었다. 알고리즘 개념들을 더 익혀서 내것으로 만들어 문제에 적용시켜 보는 연습이 필요할 것으로 보인다.!!!
