
Contents
- Introduction
- Related work
- Formulation
- Implementation
- Results
- Limitations and Discussion
1. Introduction
- 본 연구는, paired training example 없이 이미지 집합의 고유한 특징들을 파악하고, 이 특성들이 어떻게 다른 이미지 집합으로 전이될 수 있는지에 대한 방법을 제시한다.
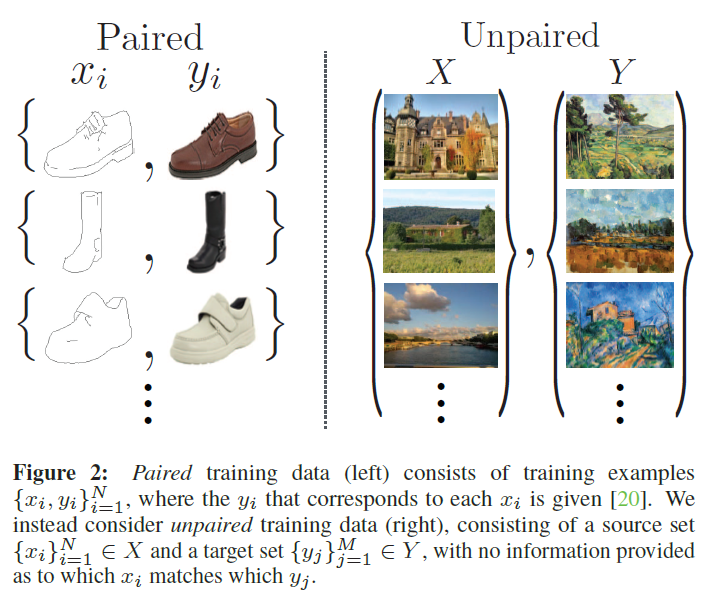
어떤 domain의 image에서 다른 domain의 image로 변환하는 작업을 image-to-image translation이라고 한다. 이러한 작업은 paired dataset을 이용가능할때, 잘 작동하는 시스템을 만들 수 있다고 한다. (pix2pix)
그러나, 일반적으로 paired training data는 얻기 어렵고, 비용이 많이 든다는 단점이 존재한다.
이러한 문제를 해결하기 위해서, 본 연구에서는 paired example이 없는 상황에서 domain간에 translation 학습이 가능한 알고리즘을 찾기 위해 노력했다. 두 image domain 사이에 어떤 relationship이 존재한다고 가정하고 그 관계를 학습시키는 방식을 이용했다.
domain 로부터 domain 로의 mapping을 라고 하고, 에 대한 network를 학습시켰을 때, 생성된 는 와 구별할 수 없어야 한다. 이러한 관계는 GAN의 기본 원리로, generator에 의해 생성된 데이터가 target class 데이터의 분포와 가까워지면서, 최종적으로는 그럴싸한 target class가 되는 원리이다.
그러나, 저자는 일반적인 GAN의 원리로는 본 연구에서 해결하려는 unpaired image-to-image translation의 mode collapse를 해결할 수 없다고 말한다.
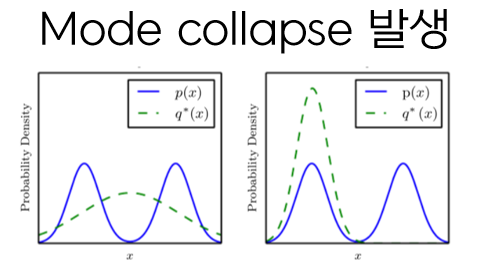
mode collapse는 다음의 그림처럼, 파란색의 실제 데이터 분포가 주어졌을 때, generator가 이 실제 데이터의 분포와 유사하게 학습하기를 원한다. 그러나, 단순히 loss만을 줄이기 위해서 학습을 하기 때문에, G가 전체 데이터 분포를 찾지 못하고, 오른쪽 그림과 같이 하나의 mode에만 강하게 몰리는 경우가 발생한다. 따라서, 서로 다른 두 image의 output이 동일한 사진으로 나오는 경우가 발생하게 된다.
따라서, 새로운 loss에 대한 고민을 하게 되었고, 저자는 cycle consistent라는 구조를 도입하게 된다.
와 를 구분하기 어렵도록 adversarial loss term을 사용하며, 이 term만으로 유의미한 mapping을 학습할 수 있다는 보장이 어렵기에, mapping network가 추가적으로 cycle consistent를 만족시키도록 cycle consistency loss term을 결합하여 사용한다.
2. Related work
* Generative Adversarial Networks (GANs)
GAN의 핵심 아이디어는, generated image들이 real image와 구분하지 못하도록 만드는 adversarial loss에 있다. 본 연구에서는, translated image들이 target domain에 있는 image들과 구분되지 않도록 adversarial loss를 사용했다.
* Image-to-Image Translation
기존의 image-to-image translation은 paired dataset을 사용했지만, 본 연구에서는 unpaired dataset을 사용하고자 한다.
* Unpaired Image-to-Image Translation
이전까지의 unpaired image-to-imgae translation은 predefined metric space에서의 input과 output을 비슷하게 만들기 위해 adversarial network를 사용했지만, 본 연구에서는 이러한 방식을 사용하지 않았다.
* Cycle Consistency
Structured data를 regularize하기 위해 transitivity를 사용하는 방법은 예전부터 사용되었다. 본 연구에서는, domain X에서 Y로의 mapping인 와 domain Y에서 X로의 mapping인 를 비슷하게 만드는 similar loss를 소개한다.
* Neural Style Tranfer
본 연구에서 제안하는 방법은 painting에서 photo로 변환시키는 등, 다양한 분야로 확장시킬 수 있을 것이다.
3. Formulation
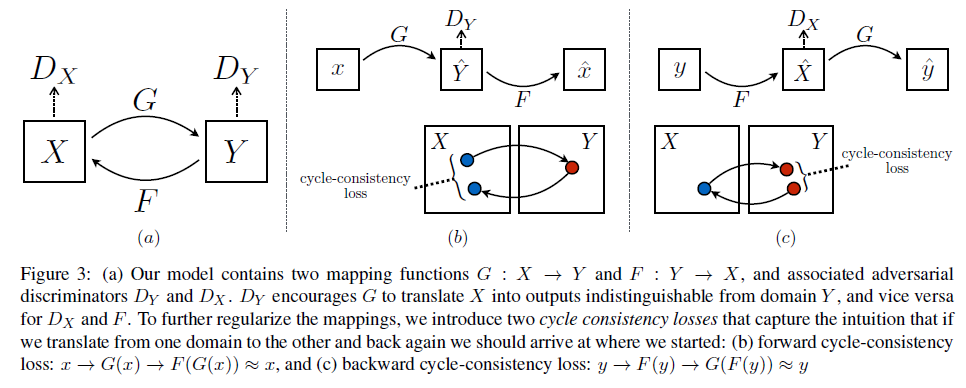
본 연구의 목표는 두 domain 를 연결하는 mapping function을 학습시키는 것이다. 위 그림의 (a)처럼, 저자들이 제안하는 model은 두 개의 mapping을 갖고 있다. (, )
또한, 두 개의 adversarial discriminator를 가진다. 는 실제 domain X의 이미지 x와 가 생성한 를 구분하기 위한 것이다. (는 y와 를 구분하기 위한 것)
(즉, base 모델은 두 개의 Generator와 두 개의 Discriminator로 학습되는 것으로 예상)
* Adversarial Loss
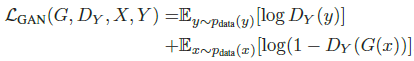
본 연구에서는 mapping function 두 개에 모두 adversarial loss를 적용했다.
* Cycle Consistency Loss
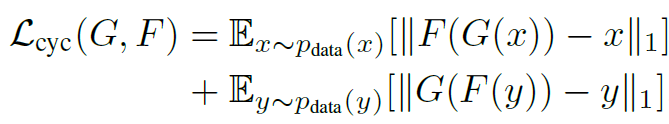
Adversarial training은 이론적으로 mapping을 학습한다. 하지만, network는 하나의 image를 target domain에 있는 여러 image와 mapping할 수 있다. 이는, adversarial loss 하나로 individual input 가 우리가 원하는 output 와 mapping 될 수 있다는 보장이 없기 때문이다. 그렇기에, mapping function을 cycle consistent하게 했다.
위 그림의 (b)를 보면, 인 것을 확인할 수 있는데, 이를 forward cycle consistency라고 부른다. ((c)는 backward cycle consistency)
cycle consistency loss를 위해, 위와 같은 두개의 consistency를 만들고, 이를 loss에 반영했다. 해당 loss를 통해 unpaired domain X, Y를 쌍으로 연결할 수 있게 된다.
* Full Objective
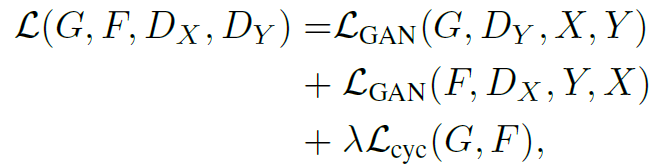
최종 loss는 앞서 언급한 Adversarial Loss와 Cycle Consistency Loss를 결합한 형태로 위와 같이 표현된다. 해당 loss를 통해 generator는 실제 이미지에 가까운 이미지를 만들기 위해 노력하며, discriminator는 generated된 이미지를 실제 이미지와 판별하는 것을 목표로 한다.
4. Implementation
본 연구에서 Generator network는 Johnson et al. 2016의 구조를 사용했으며, Discriminator network는 pix2pix와 동일하게 PatchGAN 70X70을 사용했다.
Training details
-
학습을 안정화 시키기 위해, 본 연구에서는 original GAN의 adversarial loss 대신 Least Square의 adversarial loss를 사용했다. (훈련이 더 안정적이고, 좋은 결과를 준다고 함)
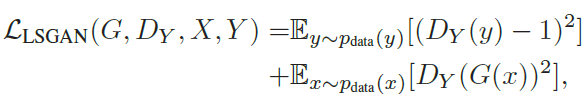
-
model oscillation을 줄이기 위해, Shrivastava et al's strategy를 활용했다.
-
가 생성한 하나의 최근 image를 이용하여 를 바로 훈련시키는 것이 아니라, 그동안 생성한 image history buffer를 활용하여 최근 생성한 50개의 image를 지속적으로 저장하고 그것들을 이용해 training을 진행했다.
5. Results
실험 1. cycleGAN for paired data setting
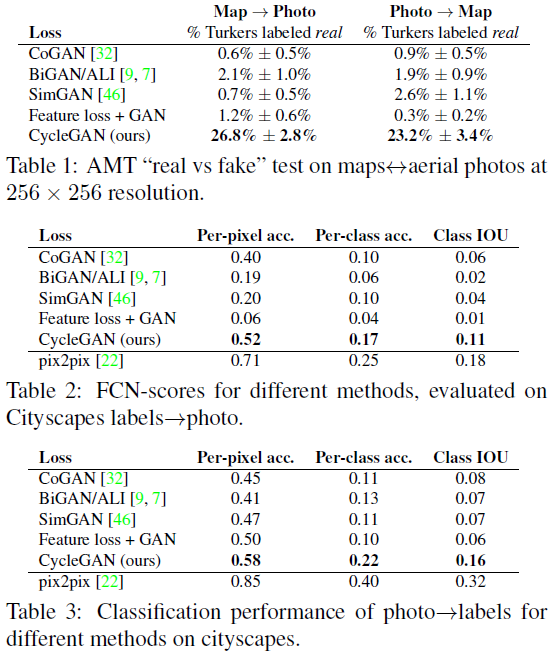
Table 1을 보면, AMT에서 cycleGAN은 약 25%의 사람들을 사람들을 속인 것을 확인할 수 있다. 그러나, Table 2, 3에서 pix2pix가 cycleGAN보다 더 우수한 성능을 보이는 것을 확인할 수 있다. baseline model(CoGAN, BiGAN/ALL, SimGAM, Feature loss+GAN)보다는 cycleGAN이 우수한 성능을 보이지만, paired data가 존재하는 경우에는 pix2pix를 사용하는 것이 더 효과적이라는 것을 확인할 수 있다.
실험 2. ablation study on loss term
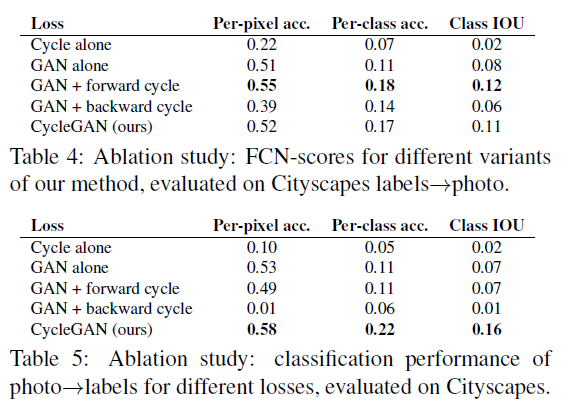

실험 2번은 각각의 loss에 대한 영향력을 확인하기 위한 실험이다. GAN loss는 필수적이라는 것을 확인할 수 있다. 또한, cycle consistency loss는 양방향(forward, backward)을 모두 사용해야 효과적인 것을 확인할 수 있다.
실험 3. cycleGAN for unpaired data setting
* Object transfiguration


* Season transfer

* Collection style transfer

* Photo generation from paintings

* Photo enhancement

6. Limitations and Discussion

cycleGAN이 좋은 성능을 내는 것은 맞지만, 모든 task에서 좋은 성능을 보이는 것은 아니다. color나 texture를 바꾸는 task는 거의 성공적으로 수행하지만, 객체의 모양 자체를 바꾸는 task는 수행하지 못했다. (위 예시에 나온, 개를 고양이로 바꾸는 task, 고양이를 개로 바꾸는 task, 얼룩말을 말로 바꾸는 task 등)
또한, 학습에 사용한 데이터셋의 불균형에 따른 문제도 존재한다. 말을 타고 있는 사람의 image는 제공된 dataset 내에 존재하지 않기 때문에, 사람과 말을 구분하지 못하고, 모두 얼룩으로 만들었다.
추가적으로, paired dataset으로 훈련시킨 것과 성능 차이가 벌어지기도 한다.
