
DB Connection
DB Connection 이란 애플리케이션과 데이터베이스 서버가 통신할 수 있도록 하는 기능이다.
아래 코드는 Java 의 DB Connection 을 JDBC 를 이용해 구현한 예이다.
public Connection getConnection() {
try {
return DriverManager.getConnection("jdbc:mysql://" + SERVER + "/" + DATABASE + OPTION, USERNAME, PASSWORD);
} catch (final SQLException e) {
System.err.println("DB 연결 오류:" + e.getMessage());
e.printStackTrace();
return null;
}
}연결에 성공하면 Connection 객체가 반환된다.
Connection 객체가 반환되는 과정
- DB 드라이버 로드: 우선 사용하려는 DB 에 해당하는 JDBC 드라이버를 로드해야 한다.
- DB 연결 정보 설정: 연결하려는 DB 의 URL, 사용자 이름, 비밀번호 등의 연결 정보를 설정한다.
- Connection 객체 생성: DriverManager 클래스를 사용하여 DB 와 연결 하고, 이 연결을 나타내는 Connection 객체를 얻는다.
(참고) jdbc 드라이버란
자바가 다양한 데이터베이스를 지원할 수 있는 이유는 각 데이터베이스에 맞는 JDBC 드라이버가 구현되어 있기 때문이다.
이 드라이버는 Java 애플리케이션과 각 DB 간의 통신을 중개하여, 동일한 JDBC API 를 사용하여도 각 DB에 적합한 프로토콜로 요청을 전달하고 응답을 받을 수 있다.
// 드라이버는 DB 공급업체(Oracle, MySQL ..) 에서 제공하는 JDBC 드라이버 jar 파일을 classpath 에 추가하여 로드한다.
Connection 이후
- Connection 객체 사용: 반환된 Connection 객체를 사용하여 DB 관련 작업(쿼리 실행, 트랜잭션 관리 등)을 수행한다.
- 연결 종료: DB 작업을 마치면 Connection 객체를 명시적으로 닫아야 한다. 리소스 누수를 방지하고 DB 연결을 제대로 해제하기 위함이다.
connection.close();그런데 DB 를 연결할 때마다 Connection 객체를 새로 만드는 것은 비용이 많이 들고 비효율적이다.
DB 를 연결할 때마다 Connection 객체를 새로 만드는 것이 좋지 않은 이유
- 네트워크 비용: DB 연결을 설정하는 과정은 네트워크 통신을 동반한다.
새로운 Connection 객체를 생성할 때마다 DB 서버와의 네트워크 연결을 해야 하며, 이 과정은 일정 시간이 소요된다.
따라서 빈번한 Connection 생성은 불필요한 네트워크 비용을 발생시킨다. - 리소스 사용: 각 Connection 객체는 DB 서버의 연결 세션을 나타낸다. DB 서버는 동시에 처리할 수 있는 연결 세션 수에 제한이 있으며, 무분별한 Connection 생성은 서버 리소스를 소모할 수 있다.
- 비용적 측면: Connection 객체 생성은 시간과 메모리를 소모한다.
특히 DB 연결 설정 및 인증 과정은 비용이 큰 작업이다.
그럼 어떻게 해야할까 ?
DB Connection Pool
위에서 살펴본 Connection 객체의 반복적인 생성과 해제를 피하고, 효율적으로 데이터베이스 연결을 관리하기 위해 Connection 풀링이 사용된다.
DB Connection Pool 이란, 데이터베이스로의 추가 요청이 필요할 때 연결을 재사용할 수 있도록 관리되는 데이터베이스 연결의 캐시이다.
간단하게 말하자면, 애플리케이션 시작 시 미리 일정 수의 Connection 객체를 생성하여 Pool 에 보관한다. 이후에 DB 작업이 필요할 때마다 Pool 에서 Connection 객체를 가져다 사용하고, 작업이 끝나면 Pool 에 반환한다
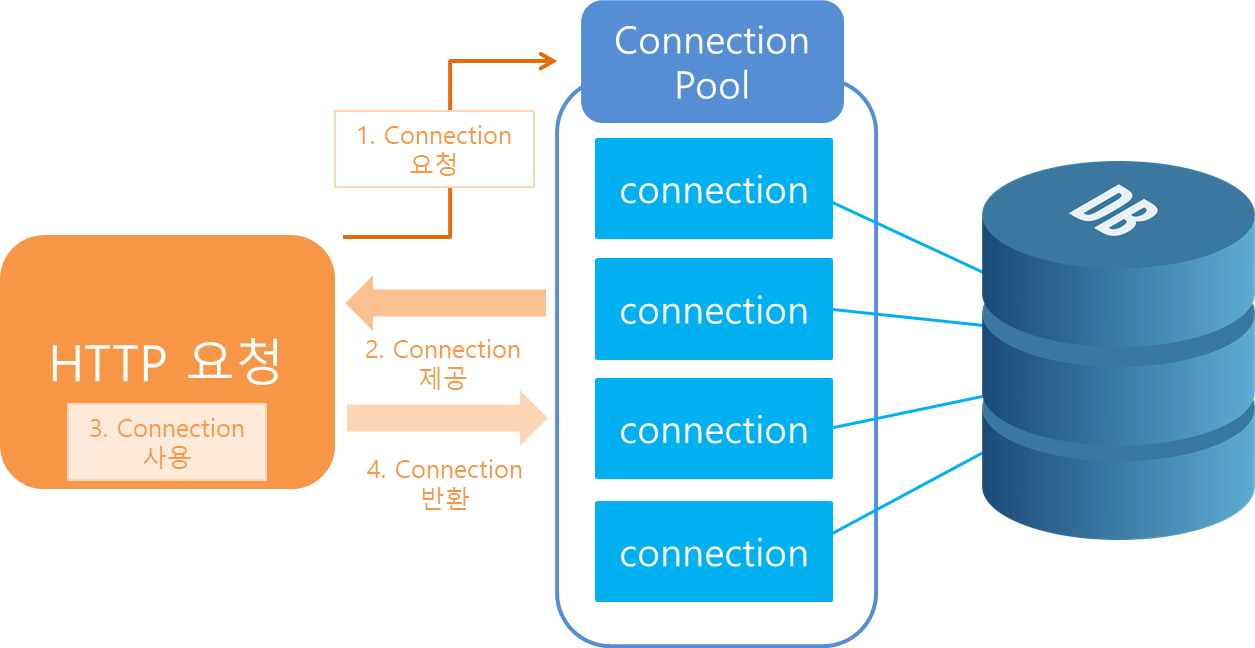
Connection Pool 의 장점
- 성능 향상: 미리 연결된 DB 연결을 Pool 에 유지하고, 요청이 들어올 때마다 해당 연결을 재사용함으로써 응답 시간을 단축하고 애플리케이션의 성능을 향상시킨다.
- 자원 관리: 연결을 생성하고 유지하는 데 필요한 자원을 최적화한다. 불필요한 연결을 만들지 않고, 연결을 재사용함으로써 메모리와 CPU 등의 자원을 효율적으로 관리할 수 있다.
- 동시성 관리: 동시에 여러 요청을 처리할 수 있는 연결을 제공하므로, 다수의 사용자가 동시에 애플리케이션에 접속해도 안정적으로 처리할 수 있다.
- 연결 풀링: 연결의 개수를 제한하고, 초과하는 요청이 들어올 경우 대기하도록 처리함으로써 데이터베이스 서버의 부하를 관리하고 과부하를 방지한다.
- 커넥션 오버헤드 감소: 반복적인 데이터베이스 연결/해제 작업에 따른 오버헤드를 감소시킨다.
// 커넥션 오버헤드 - DB 연결을 생성하고 해제하는 과정에서 발생하는 추가적인 비용과 부하
Connection Pool 의 단점
- 리소스 사용: 일정 수의 연결을 미리 생성 및 유지해야 하므로, 메모리 등의 리소스를 일정 부분 소비한다.
- 설정 및 관리의 복잡성: 다양한 환경에서 최적의 성능을 발휘하기 위해서는 일정한 관리와 모니터링이 필요하다. 설정 파라미터의 조절이 필요한 경우에는 초기 설정 및 튜닝에 시간이 소요될 수 있다.
- 커넥션 누수: 애플리케이션에서 연결을 올바르게 반환하지 않거나 예외가 발생하는 경우, 커넥션 풀에서 연결이 제대로 반환되지 않을 수 있다. 이 경우 커넥션 누수가 발생할 수 있다.
Connection Pool 사용 예시
Connection Pool 의 종류 중 하나인 HikariCP 를 사용한 예시 코드이다.
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class ConnectionPoolExample {
public static void main(String[] args) {
// HikariCP 설정
HikariConfig config = new HikariConfig();
config.setJdbcUrl("jdbc:mysql://localhost:3306/mydatabase");
config.setUsername("username");
config.setPassword("password");
// HikariCP 데이터소스 생성
HikariDataSource dataSource = new HikariDataSource(config);
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
// 커넥션 풀에서 커넥션 획득
connection = dataSource.getConnection();
// SQL 쿼리 실행
String sql = "SELECT * FROM users WHERE id = ?";
preparedStatement = connection.prepareStatement(sql);
preparedStatement.setInt(1, 1); // 예시로 사용자 ID가 1인 사용자 조회
resultSet = preparedStatement.executeQuery();
// 결과 처리
if (resultSet.next()) {
String username = resultSet.getString("username");
System.out.println("Username: " + username);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
// 리소스 해제 (역순으로 해제)
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (preparedStatement != null) {
try {
preparedStatement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close(); // 커넥션을 풀에 반환
} catch (SQLException e) {
e.printStackTrace();
}
}
// HikariCP 데이터소스 종료
if (dataSource != null) {
dataSource.close();
}
}
}
}
Connection Pool 이 커지면 성능이 무조건 좋아질까?
커넥션 풀을 크게 설정하면
- 많은 메모리를 사용하지만, 동시에 많은 사용자가 대기 시간이 줄어들어 성능이 향상될 수 있다.
커넥션 풀을 작게 설정하면
- 메모리 소모는 줄어들지만, 동시 접속자가 많아지면 대기 시간이 길어질 수 있다.
따라서 커넥션 풀의 크기를 적절히 조절하여 최적의 성능을 유지해야 한다.
Connection Pool 의 적절한 크기
- 시스템 리소스 및 성능 모니터링: 시스템의 리소스 사용량과 성능을 모니터링하여 커넥션 풀의 최적 크기를 결정해야 한다.
ex) 메모리 사용량, CPU 부하, 네트워크 성능 등 - 부하 예측과 테스트: 애플리케이션의 부하 예측을 토대로 커넥션 풀의 크기를 조절하고, 실제 동작하는 환경에서 테스트하여 최적의 성능을 확인해야 한다.
(참고) Hikari CP는 적절한 Connection Pool의 크기를 1 connections = ((core_count) * 2) + effective_spindle_count) 로 정의하고 있다.
- core_count (코어 수): 시스템에서 사용 가능한 CPU 코어의 수다.
- effective_spindle_count (유효 스핀들 수): 데이터베이스의 유효 디스크 스핀들(회전하는 디스크 드라이브)의 수
Reference


DB 공부 입문자로서 너무 어렵네요..