
모델훈련
- 다양한 머신러닝 모델과 훈련 알고리즘의 상세 사항을 실제로 알아야 할 필요는 없으나,
어떻게 작동하는지 이해하고 있으면 적절한 모델, 올바른 훈련 알고리즘, 작업에 맞는 좋은 하이퍼파라미터를 빠르게 찾을 수 있습니다. - 먼저 가장 간단한 모델중 하나인 선형회귀 부터 살펴보고 다음은 비선형 데이터 셋을 훈련시킬수 있는 조금더 복잡한 모델인 다항회귀 마지막으로는 분류 작업에 널리 사용하는 모델인 로지스틱 회귀와 소프트맥스 회귀를 살펴보겠습니다.
선형회귀


실습
- 정규 방정식을 이용한 파라미터 구하기
import numpy as np X = 2 * np.random.rand(100, 1) y = 4 + 3 * X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X] # 모든 샘플에 x0 = 1을 추가합니다. theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y) theta_bestarray([[4.21509616], [2.77011339]])

- sklearn을 이용한 파라미터 구하기
from sklearn.linear_model import LinearRegression lin_reg = LinearRegression() lin_reg.fit(X, y) lin_reg.intercept_, lin_reg.coef_(array([4.21509616]), array([[2.77011339]]))
- 선형회귀 모델의 예측식 과 유사역행렬을 이용
np.linalg.pinv()을 사용해서 유사역행렬을 직접 계산할 수 있습니다
np.linalg.pinv(X_b).dot(y)array([[4.21509616], [2.77011339]])
경사하강법
- 비용 함수를 최소화하기 위해 반복적으로 모델 파라미터를 조정

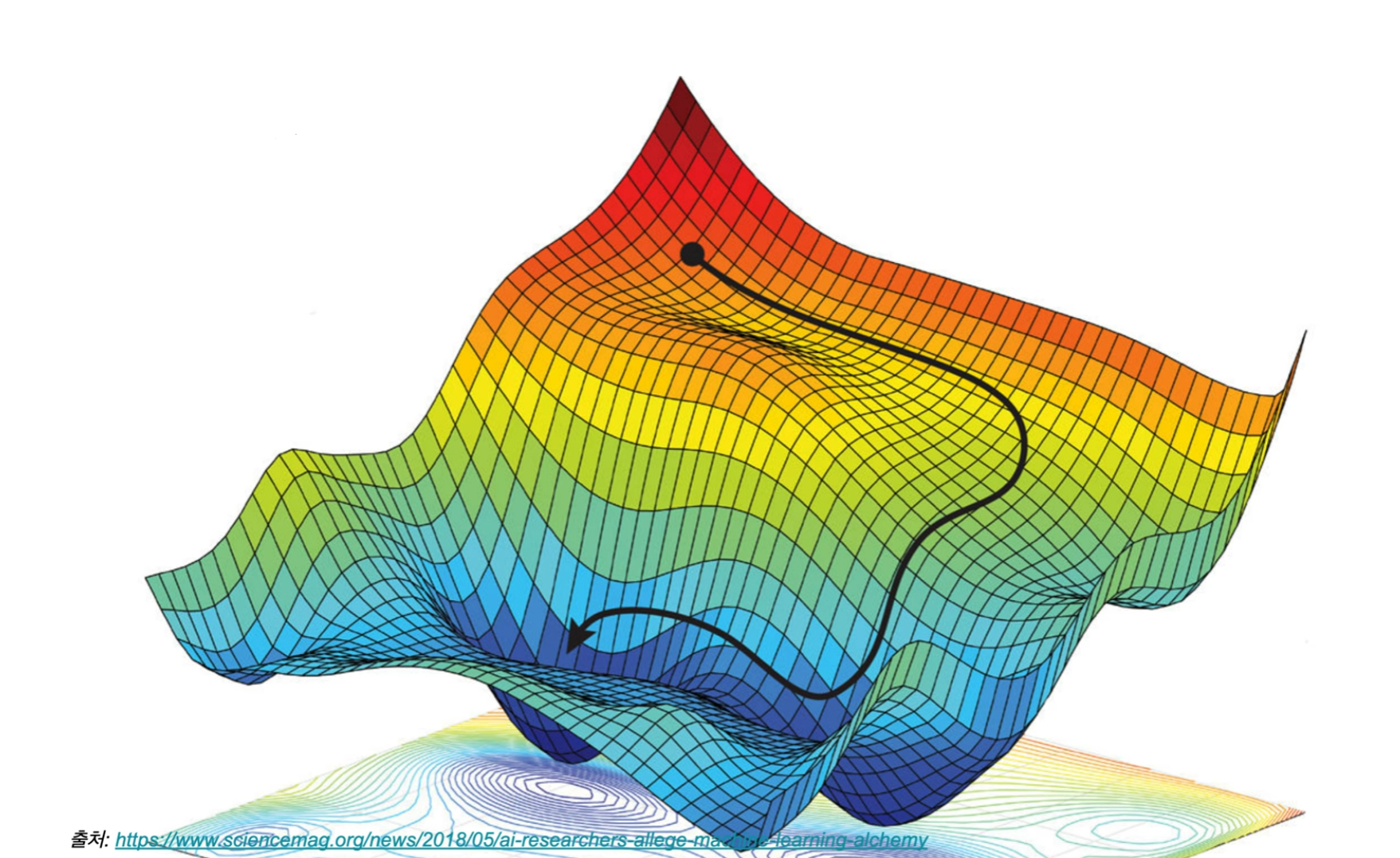
- 경사하강법의 문제
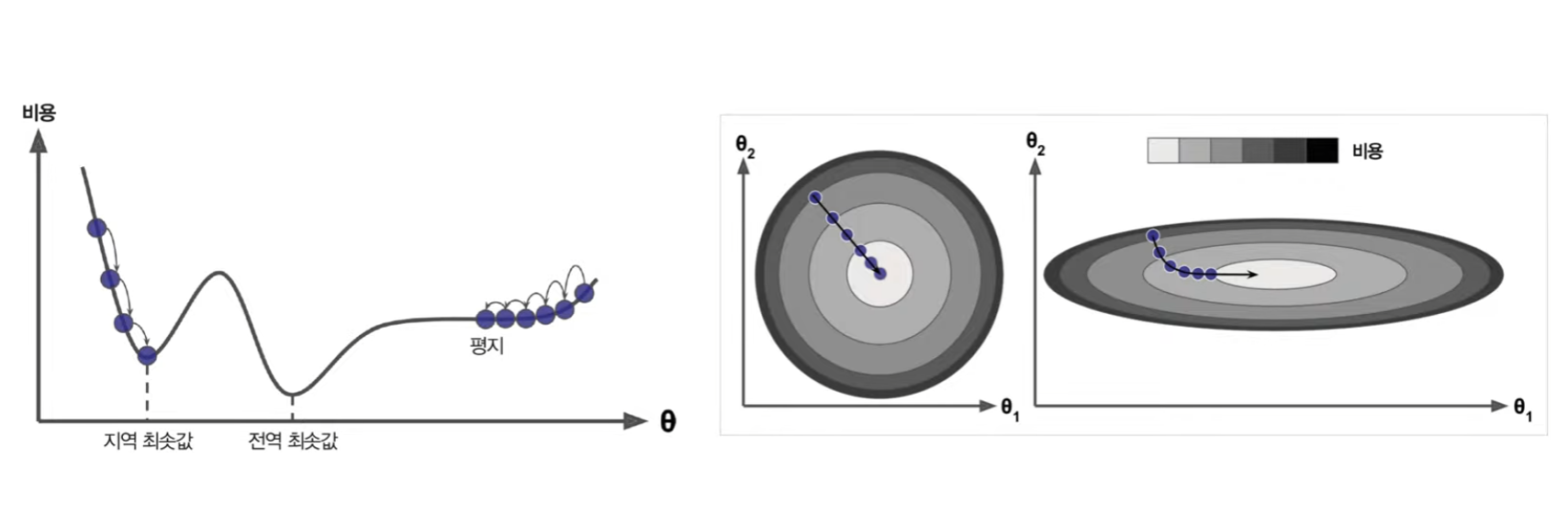
배치 경사 하강법
1회 학습에 전체 데이터 사용
-
비용함수의 편도함수
- 파라미터가 조금 변경될때 비용함수가 얼마나 바뀌는지에 대한 식

- 파라미터가 조금 변경될때 비용함수가 얼마나 바뀌는지에 대한 식
-
비용함수의 그레디언트 벡터
- 파라미터가 많아질때 일관 계산하기 위한 식
- 파라미터가 많아질때 일관 계산하기 위한 식
-
경사 하강법의 스텝
- 하강하는 학습률의 크기를 결정하기 위한 식
- 하강하는 학습률의 크기를 결정하기 위한 식
실습
- 편도 함수를 이용한 학습
eta = 0.1 # 학습률 n_iterations = 1000 m = 100 theta = np.random.randn(2,1) # 랜덤 초기화 for iteration in range(n_iterations): gradients = 2/m * X_b.T.dot(X_b.dot(theta) - y) theta = theta - eta * gradients thetaarray([[4.21509616], [2.77011339]])

확률적 경사 하강법
1회 학습에 하나의 데이터 사용
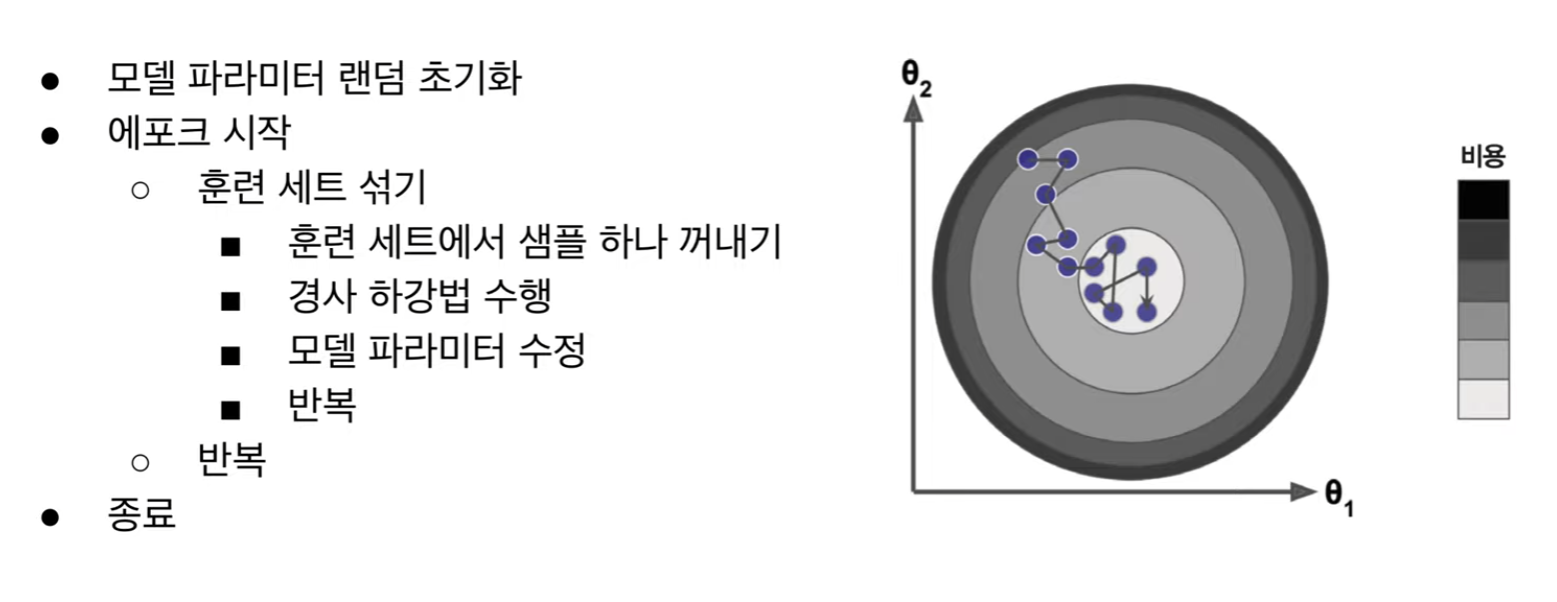
실습
- sklearn 을 이용한 학습
from sklearn.linear_model import SGDRegressor sgd_reg = SGDRegressor(max_iter=1000, tol=1e-3, penalty=None, eta0=0.1, random_state=42) sgd_reg.fit(X, y.ravel()) sgd_reg.intercept_, sgd_reg.coef_(array([4.24365286]), array([2.8250878]))
미니배치 경사 하강법
1회 학습에 하나의 묶음 데이터 사용
실습
- 미니배치를 이용한 학습
theta_path_mgd = [] n_iterations = 50 minibatch_size = 20 np.random.seed(42) theta = np.random.randn(2,1) # 랜덤 초기화 t0, t1 = 200, 1000 def learning_schedule(t): return t0 / (t + t1) t = 0 for epoch in range(n_iterations): shuffled_indices = np.random.permutation(m) X_b_shuffled = X_b[shuffled_indices] y_shuffled = y[shuffled_indices] for i in range(0, m, minibatch_size): t += 1 xi = X_b_shuffled[i:i+minibatch_size] yi = y_shuffled[i:i+minibatch_size] gradients = 2/minibatch_size * xi.T.dot(xi.dot(theta) - yi) eta = learning_schedule(t) theta = theta - eta * gradients theta_path_mgd.append(theta) thetaarray([[4.25214635], [2.7896408 ]])
선형 회귀 알고리즘 정리
-
경사 하강법 알고리즘 비교

-
선형 회귀 알고리즘 비교


AI Tensorflow Python