
DataFrame 병합
Keypoint!
- 두 DataFrame을 하나로 합칠 수 있고, 이를 병합(Merge)라고 합니다.
- 병합하는 방법에 따라
concat()이나merge()를 사용할 수 있습니다.
0. 데이터 준비하기
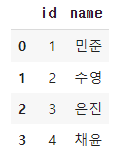
- 사용자 정보 데이터를
pandas의DataFrame으로 만듭니다.import pandas as pd user = pd.DataFrame({"id": [1, 2, 3, 4], "name": ["민준", "수영", "은진", "채윤"]}) user
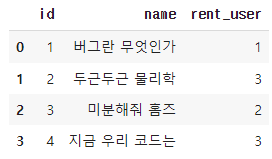
- 책 데이터를 pandas의 DataFrame으로 만들어봅시다.
book = pd.DataFrame({"id": [1, 2, 3, 4], "name": ["버그란 무엇인가", "두근두근 물리학", "미분해줘 홈즈", "지금 우리 코드는"], "rent_user": [1, 3, 2, 3]}) book
1. 세로로 합치기 : append()
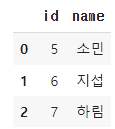
- 새로운 유저 정보가 담긴 데이터를 생성
new_user = pd.DataFrame({"id": [5, 6, 7], "name": ["소민", "지섭", "하림"]}) new_user
.append을 활용해서 두DataFrame을 병합- cf) ignore_index : True라면 연결하는 과정에서 인덱스를 새로 지정 (0, 1, ...)
new = user.append(new_user, ignore_index = True) new

.concat()을 활용해서 병합new_with_concat = pd.concat([user,new_user], ignore_index= True) new_with_concat

2. 가로로 합치기 : merge()
.merge를 이용해 두DataFrame을 가로로 병합book.merge(new, left_on = 'rent_user', right_on = 'id')
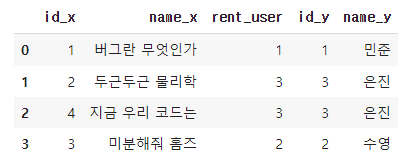
이때, 왼쪽 DataFrame의 기준 Column을 left_on으로 지정하고, 오른쪽 DataFrame의 기준 Column을 right_on으로 지정합니다.
suffixes메소드를 활용해column명을 변경ans = book.merge(new, left_on = 'rent_user', right_on = 'id', suffixes = ("","_user")) ans
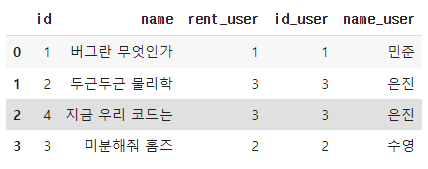
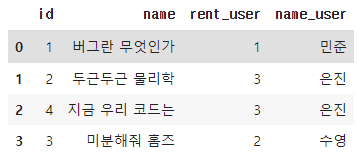
.drop을 사용해 중복되는Column을 삭제ans.drop([col for col in ans.columns if 'id_user' in col], axis = 1, inplace = True) ans


AI Tensorflow Python