목표
- Kubernetes에서 etcd 백업 및 복구하기
방법
1. 환경 변수 설정
export ETCDCTL_API=3
export ETCDCTL_ENDPOINTS=https://127.0.0.1:2379
export ETCDCTL_CACERT=/etc/ssl/etcd/ssl/ca.pem
export ETCDCTL_KEY=/etc/ssl/etcd/ssl/admin-gpu01-key.pem
export ETCDCTL_CERT=/etc/ssl/etcd/ssl/admin-gpu01.pem
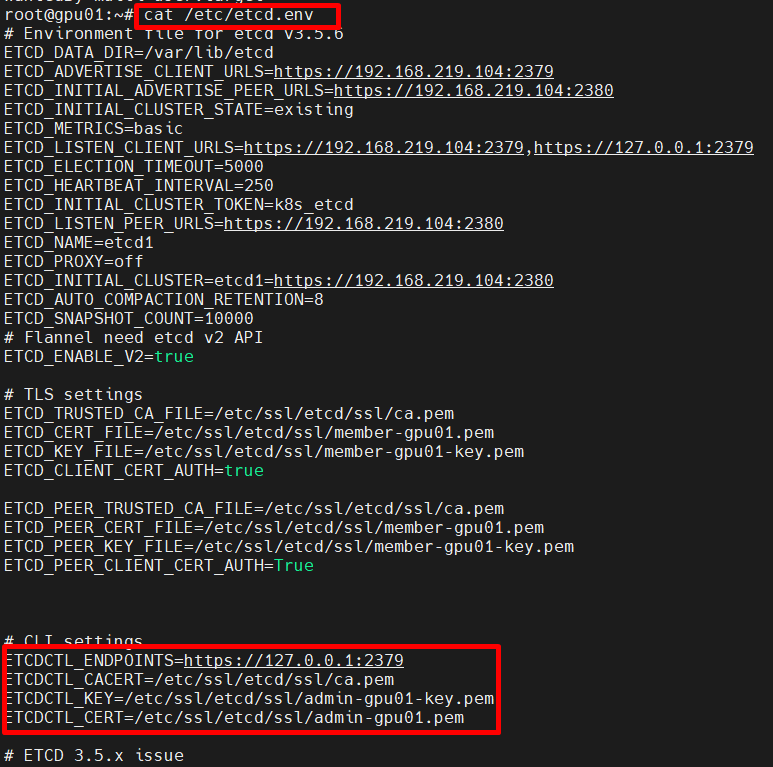
해당 파일에서 인증서 경로를 찾을 수 있음.
2. etcd 데이터 백업
etcdctl snapshot save /backup/etcd-backup.db- /backup/etcd-backup.db는 백업 파일이 저장될 경로
- 설정된 환경 변수를 사용하여 etcd 데이터베이스의 스냅샷을 생성하고, 지정된 경로에 백업 파일을 저장함.
백업이 완료되면, 다음 명령어로 백업 파일이 생성되었는지 확인
etcdctl snapshot status /backup/etcd-backup.db
etcdutl 설치
wget https://github.com/etcd-io/etcd/releases/download/v3.5.0/etcd-v3.5.0-linux-amd64.tar.gz
tar -xvf etcd-v3.5.0-linux-amd64.tar.gz
sudo mv etcd-v3.5.0-linux-amd64/etcdutl /usr/local/bin/
3. 데이터 복구
etcd 서비스 중지
sudo systemctl stop etcd기존 데이터 삭제
sudo rm -rf /var/lib/etcd/*백업 파일 복구
etcdctl snapshot restore /backup/etcd-backup.db --data-dir=/var/lib/etcd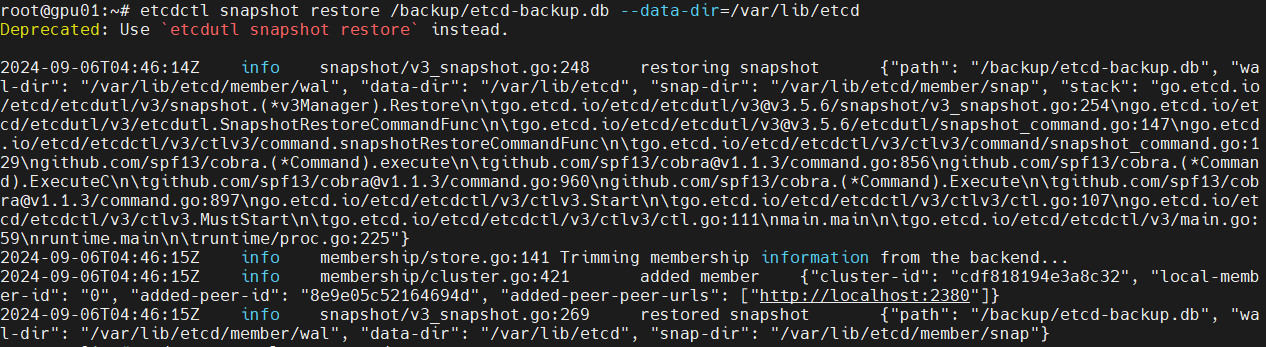
'etcd' 서비스 재시작
sudo systemctl start etcd복구 상태 확인
etcdctl endpoint status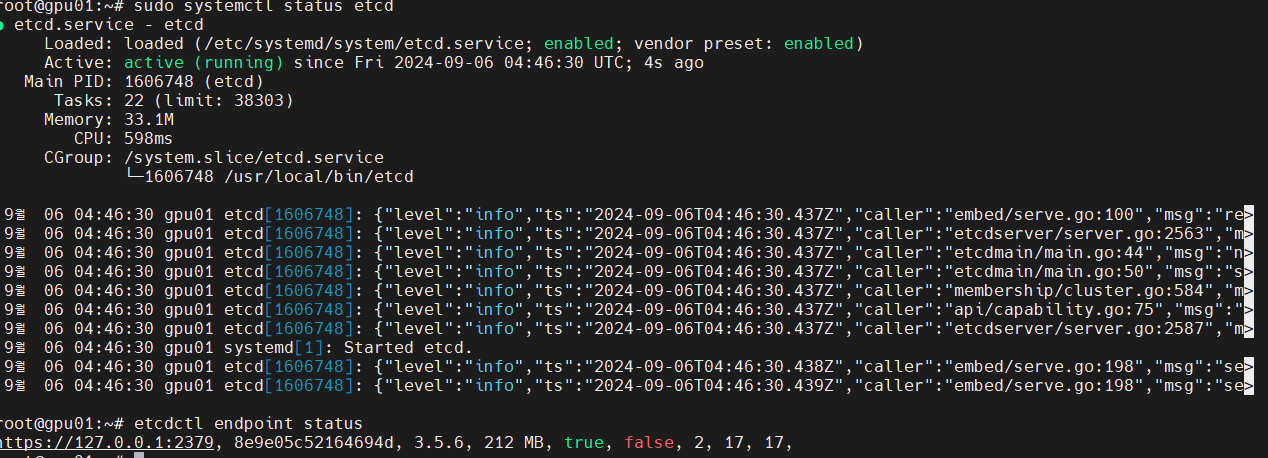
- https://127.0.0.1:2379 : 'etcd' 엔드포인트 주소
- 8e9e05c52164694d : 'etcd' 멤버의 ID. 각 etcd 멤버는 고유한 ID를 가지며, 이는 클러스터 내에서 멤버를 식별하는 데 사용됨.
- 3.5.6 : etcd 서버의 버전
- 212 MB : DB 크기
- true : isLeader 플래그. 이 값이 true인 경우, 해당 노드가 클러스터 내에서 리더 역할을 하고 있음을 나타냄. etcd 클러스터는 하나의 리더를 가지고 있으며, 나머지 노드는 팔로워 역할을 함.
- false : isLearner 플래그. 이 값은 해당 노드가 Learner 노드인지 여부를 나타냄.
- 2 : Raft term 값, 'etcd' 클러스터의 리더 선출 주기를 나타냄. 클러스터의 리더가 변경될 때마다 이값이 증가함.
- 17: Applied Index, 이값은 현재 노드가 얼마나 많은 Faft로그 항목을 적용했는지 보여줌.
- 17: Raft Index, Raft 로그에서 마지막으로 커밋된 항목의 인덱스를 나타냄.
방법2
Velero를 사용한 백업 및 복구
1. Velero 설치
velero install --provider <provider> --bucket <bucket_name> --secret-file <credentials_file> --use-restic --backup-location-config region=<region>Velero는 클라우드 스토리지를 이용하여 백업을 저장할 수 있음. 예를 들어, AWS, Azure, Google Cloud와 같은 클라우드 프로바이더에 백업 데이터를 저장 가능.
2. backup 수행
velero backup create <backup_name> --include-namespaces <namespace_name>특정 네임스페이스 또는 전체 클러스터에 대한 백업을 수행함.
3. 복구 수행
velero restore create --from-backup <backup_name>방법3. rsync 또는 파일 시스템 스냅샷을 이용한 백업
1. etcd 서비스 중지
sudo systemctl stop etcd2. 데이터 디렉토리 백업 (rsync 또는 cp 사용)
sudo rsync -avz /var/lib/etcd /backup/etcd-backup/또는
sudo cp -r /var/lib/etcd /backup/etcd-backup/3. 복원
sudo rsync -avz /backup/etcd-backup/ /var/lib/etcd또는
sudo cp -r /backup/etcd-backup/ /var/lib/etcd4. etcd 서비스 시작
sudo systemctl start etcd방법4. restic을 통한 백업 및 복구
restic은 파일 기반의 백업 도구로, etcd 데이터 디렉토리와 같은 파일 시스템의 데이터를 백업할 수 있는 도구임. S3 호환 스토리지, 로컬 스토리지 등 다양한 백엔드 스토리지를 지원함.
1. restic을 설치
wget -O restic.bz2 https://github.com/restic/restic/releases/download/v0.9.5/restic_0.9.5_linux_amd64.bz2
bunzip2 restic.bz2
chmod +x restic
mv restic /usr/local/bin/2. 백업 저장소를 초기화
restic init -r /backup/etcd3. restic을 사용하여 etcd 데이터 디렉토리를 백업
restic -r /backup/etcd backup /var/lib/etcd4. 복구
restic -r /backup/etcd restore latest --target /var/lib/etcd방법5. 쿠버네티스 Persistent Volume (PV) 스냅샷
쿠버네티스 환경에서 etcd가 Persistent Volume(PV)에 저장된 경우, PV 스냅샷 기능을 사용할 수 있음.
1. pv 스냅샷 생성
쿠버네티스 스냅샷 API를 사용하여 etcd의 PV를 백업함.
스냅샷 리소스를 생성하여 PV의 상태를 캡처할 수 있음.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: etcd-snapshot
spec:
volumeSnapshotClassName: <snapshot-class>
source:
persistentVolumeClaimName: <etcd-pvc-name>스냅샷을 생성한 후, 쿠버네티스 리소스 상태를 확인
2. 복구
스냅샷을 이용하여 새로운 PVC를 생성함.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: etcd-pvc-restore
spec:
dataSource:
name: etcd-snapshot
kind: VolumeSnapshot
apiGroup: snapshot.storage.k8s.io
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi새로운 PVC를 기존 etcd에 연결하고 서비스를 재시작
방법6. 파드에서 실행 중인 etcd의 백업 및 복구를 수행
1. etcd 파드 식별
kubectl get pods -n kube-system -l component=etcd2. etcd 파드에 접근
kubectl exec -it etcd-master1 -n kube-system -- /bin/sh3. etcdctl로 백업 수행
export ETCDCTL_API=3
etcdctl --endpoints=https://127.0.0.1:2379 \
--cacert=/etc/kubernetes/pki/etcd/ca.crt \
--cert=/etc/kubernetes/pki/etcd/server.crt \
--key=/etc/kubernetes/pki/etcd/server.key \
snapshot save /var/lib/etcd/backup.db4. etcd 복구
1) 파드 중지
etcd가 자동으로 재시작되는 것을 방지하기 위해 etcd 디플로이먼트나 스테이트풀셋을 중지합니다. 보통 etcd는 쿠버네티스의 스태틱 파드로 관리되므로, 이 경우 etcd 매니페스트 파일을 수정하거나 파드를 직접 삭제합니다.
kubectl delete pod etcd-master1 -n kube-system스테이트풀셋으로 구성된 경우:
kubectl scale statefulset etcd --replicas=0 -n kube-system2) etcd 데이터 복원
etcdctl snapshot restore /var/lib/etcd/backup.db --data-dir=/var/lib/etcd/new_etcd_data3) etcd 재시작
kubectl scale statefulset etcd --replicas=1 -n kube-system- 복구 후 상태 확인
kubectl get pods -n kube-system -l component=etcd
etcdctl --endpoints=https://127.0.0.1:2379 endpoint status- 고려사항
1) 클러스터가 안정적인 상태에서 수행
2) 리더 노드에서 백업
export ETCDCTL_API=3
export ETCDCTL_CACERT=/etc/kubernetes/pki/etcd/ca.crt
export ETCDCTL_CERT=/etc/kubernetes/pki/etcd/server.crt
export ETCDCTL_KEY=/etc/kubernetes/pki/etcd/server.key"IS LEADER" 컬럼이 true로 되어 있는 노드가 리더 노드
etcdctl --endpoints=https://127.0.0.1:2379 endpoint status --write-out=table클러스터 멤버 리스트 확인
etcdctl --endpoints=https://127.0.0.1:2379 member list3) 복구 시 기존 데이터를 보존하거나 백업 후 완전히 지우고 복원하는 방식으로 진행
출처 :
1. https://etcd.io/docs/v3.5/op-guide/recovery/
2. https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/
3. https://velero.io/docs/v1.14/
4. https://rsync.samba.org/documentation.html
5. https://restic.readthedocs.io/en/stable/
6. https://kubernetes.io/docs/concepts/storage/volume-snapshots/
