3.3(1) 인덱스 스캔 효율화
-
IOT , 클러스터, 파티션은 테이블 랜덤 액세스 최소화하는데 매우 효과적인 저장구조
-
운영 시스템 환경에서 이를 적용하려면성능 검증을 위해 많은 테스트를 진행 해야하므로 어려움이 따른다.
- 즉 시스템 개발 단계에서 물리 설계가 중요
-
운영환경에서 가능한 일반적인 튜닝 기법은 인덱스 컬럼 추가
인덱스 탐색
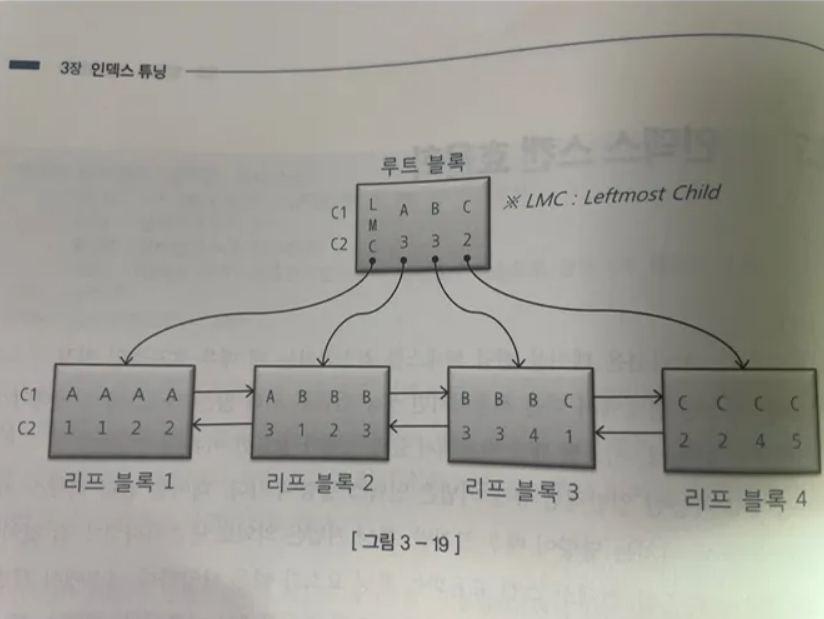
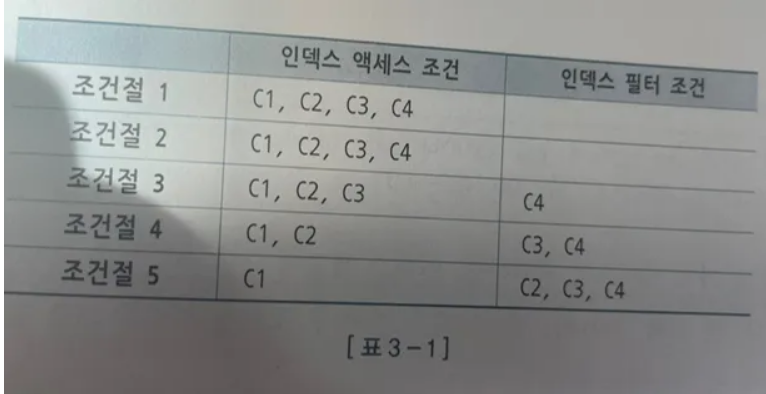
다음 같은 인덱스 구조에서
WERER C1 = 'B'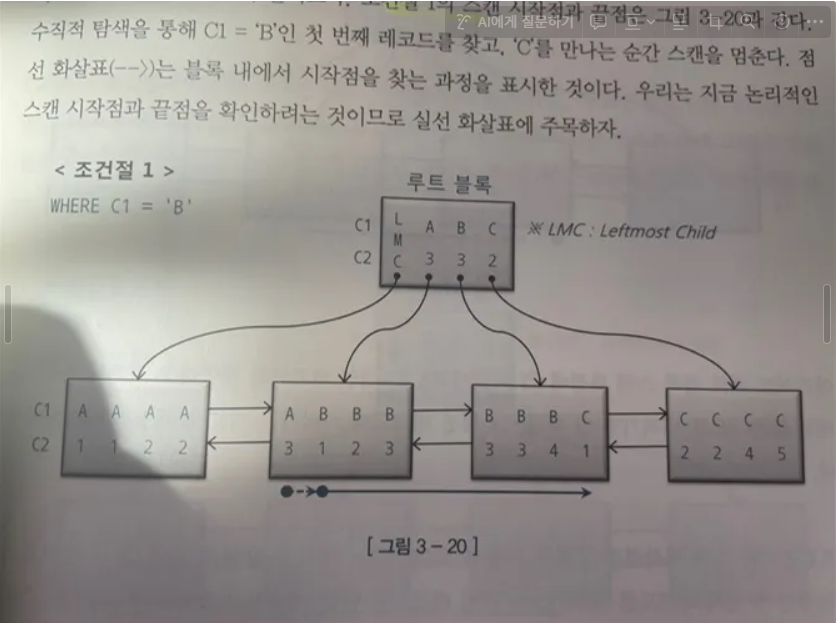
WHERE C1 = 'B' AND C2 = 3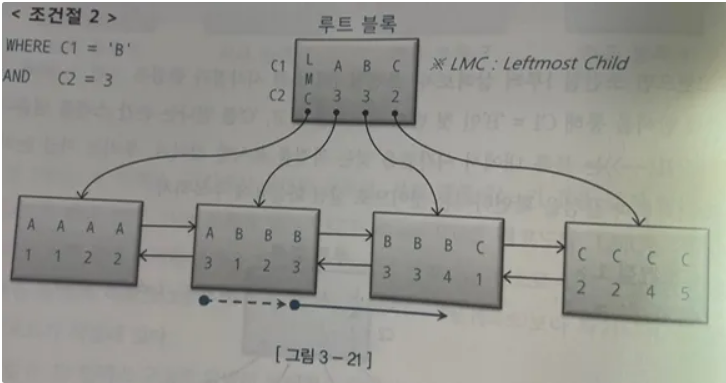
WHERE C1 = 'B' AND C2>=3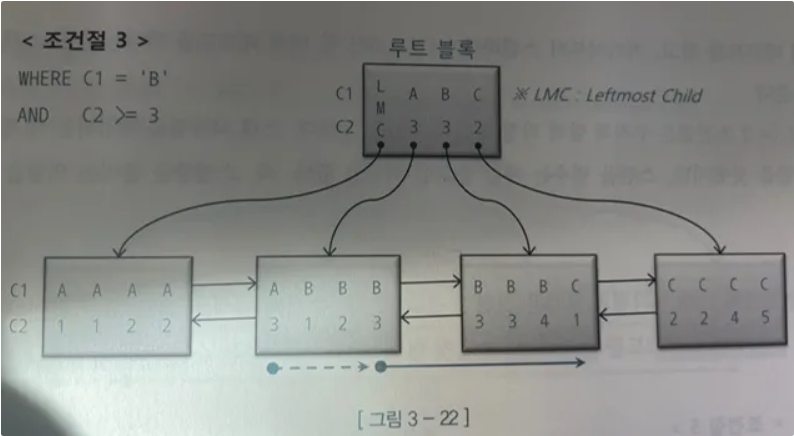
WHERE C1 = 'B' AND C2 <=3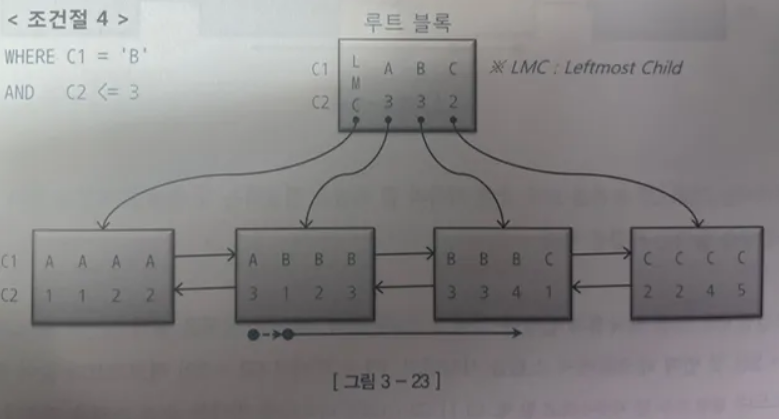
WHERE C1 = 'B' AND C2 BETWEEN 2 AND 3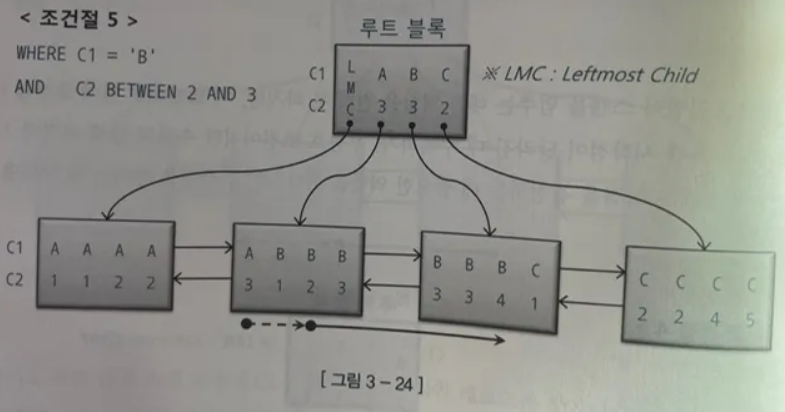
WHERE C1 BETWEEN 'A' AND 'C' C2 BETWEEN 2 AND 3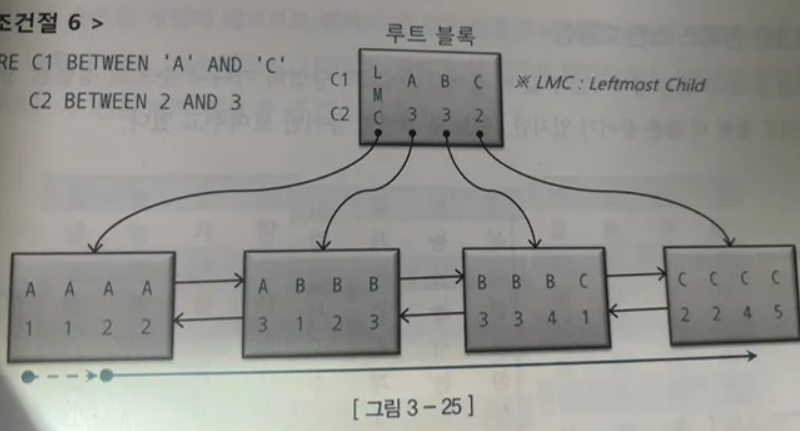
조건 6은 C1은 스캔시작 과 끝 지점을 결정하는데 중요 역할을 했지만 C21는 그렇지 못하다 즉 C2는 스캔량을 줄이는데 거의 역할을 못했다.

- 성능검으로 용어를 검색할시
- 성능검사 , 성능검증 , 성능계수 까지 읽고 스캔을 끝낸다
- 성능 으로 시작하고 네번째 문자가 선인 용어 검색시
-
전체 다 읽어야한다.
-
결과는 같은 두건인지만 성능 선 일시 더 많은 용어를 스캔한다.
즉 1번은
WHERE C1 = '성' AND C2 = '능' AND C3 = '검'2번은
WHERE C1 = '성' AND C2 ='능' AND C4 ='선'이다
왜 결과는 같은 두건이지만 더 많은 용어를 스캔하는 것일까
그 이유는
인덱스 선행 컬럼이 조건절에 없기 때문
- 인덱스 선행 컬럼이 조건절에 없거나 ‘=’ 조건이 아니면 인덱스 스캔과정에 비효율이 발생한다.
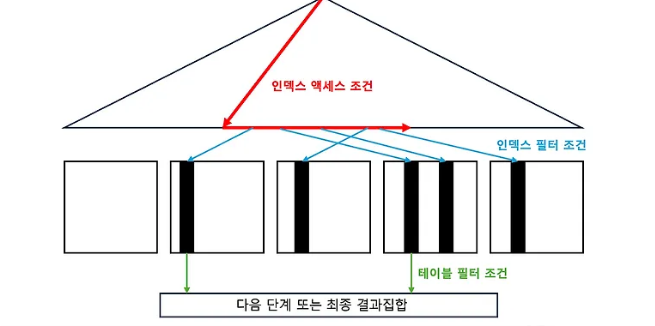
액세스 조건과 필터 조건
-
인덱스 액세스 조건은 인덱스 스캔 범위를 결정하는 조건절이다.
- 인덱스 수직적 탐색을 통해 시작점을 결정하는데 영향을 미치고 인덱스 리프 블록을 스캔하다 어디서 멈출지 결정하는데 영향을 미치는 조건절
-
인덱스 필터 조건은 테이블로 액세스 할지 결정하는 조건절이다.
- 인덱스를 이용하든 테이블을 Full Scan 하든 테이블 액세스 단계에서 처리되는 조건절은 모두 필터 조건이다.
- 테이블 필터 조건은 쿼리 수행 다음 단계로 전달하거나 최종 겨로가 집합에 포함할지를 결정한다
비교 연사자 종류와 컬럼 순서에 따른 군집성
- 테이블과 달리 인덱스에는 같은 값을 갖는 레코드들이 서로 군집해 있다.
- 같은 값을 찾을때 연산자를 사용하므로 인덱스 컬럼을 앞쪽부터 누락없이 = 연산자로 조회하면 조건절을 만족하는 레코드는 모두 모여있다.
- = 조건이 아닌 연산자로 조회할시 조건절을 만족하는 레코드가 서로 흩어진 상태가 된다.
WEHERE C = 1 AND C2 = 'A' AND C3 = '나' AND C4 = 'A'
WHERE C1 = 1 AND C2 ='A' AND C3 = '나' AND C4 > 'A'
WHERE C1 = 1 AND C2 = 'A' AND C3 BETWEEN '가' AND '다' AND C4 = 'A'-
가장 밑 조건은 C3와 C4 조건까지 만족하는 레코드는 흩어지게 된다.
-
즉 선행 컬럼이 모두 = 조건인 상태에서 첫번째 나타나는 범위 검색 조건 까지만 만족하는 인덱스 레코드는 모두 연속해서 모여 있지만 그 이하 조건 까지 만족하는 레코드는 비교 연산자 종류에 상관없이 흩어진다.
인덱스 선행 컬럼이 등치 조건이 아닐때 생기는 비효율
- 인덱스를 아파트 시세 코드 + 평형 + 평형타입+ 인터넷 매물 순으로 구성 했을시
WHERE 아파트시세코드 = :A
WHERE 아파트 시세코드 = :A AND : B
WHERE 아파트 시세코드 = :A AND : B AND 평형타입 = :C
WHERE 아파트 시세코드 = :A AND : B AND 평형타입 BETWEEN :C AND :D
반면 인덱스 선행 컬럼이 조건절에 없거나 부등호, BETWEEN, LIKE 범위 검색 조건이면 인덱스 스캔하는 단계에서 비효율이 생긴다.
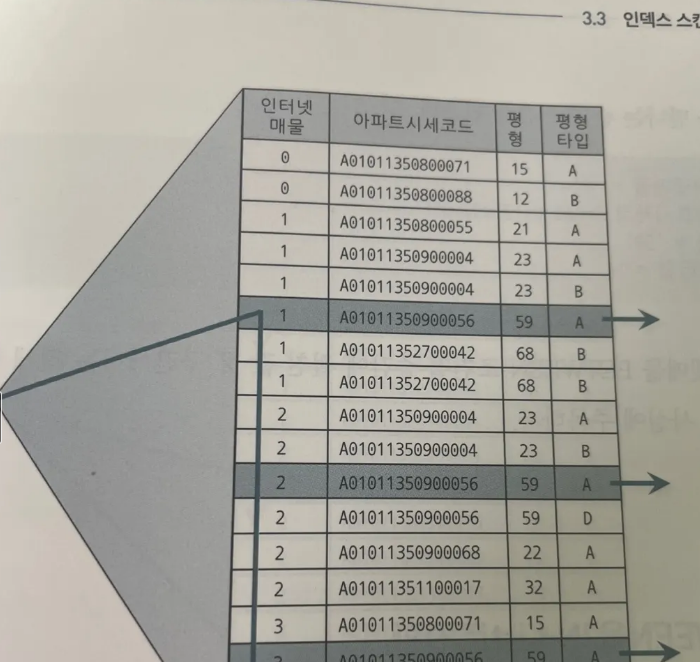
SELECT 해당층, 평당가, 입력일, 해당동, 매물구분, 연사용일수, 중개업소코드 FROM 매물아파트매매
WHERE 아파트시세코드 = 'A01011350900056'
AND 평형 = '59'
AND 평형타입 = 'A'
AND 인터넷 매물 BETWEEN '1' AND '3'
ORDER BY 입력일 DESC
- 인덱스 선행 컬럼이 모두 = 조건일때 필요한 범위만 스캔하고 멈출수 있는 것은 조건을 만족하는 레코드가 모두 한데 모여 있기 때문
인덱스를 인터넷 매물 + 아파트 시세 코드 + 평형 + 평형 타입 순으로 바꾼 후 같은 SQL을 수행하면