BETWEEN을 IN-LIST로 전환
- 범위검색 컬럼이 맨 뒤로 가도록 인덱스 순을 변경하면 좋겠지만 운영 시스템에서 인덱스 구성을 바꾸기는 쉽지 않음
SELECT 해당층, 평당가 , 입력일, 해당동, 매물구분, 연사용일수, 중개업소코드 FROM
매물 아파트매매
WHERE 인터넷매물 IN ('1', '2', '3')
AND 아파트 시세코드 = 'A01011350900056'
AND 평형 = '59'
AND 평형 타입 = 'A'
ORDER BY 입력일 DESC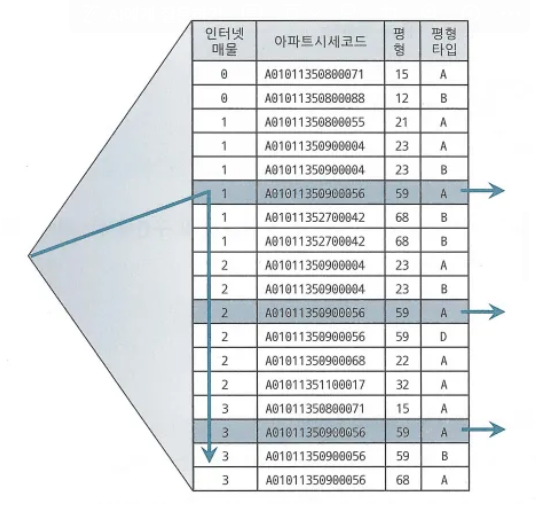
- 화살표가 세개인 이유는 인덱스 수직적 탐색이 세번 발생하기 때문
- dbms_xplan.display_cursor 함수 이용시
이는 다음과 같은 sql을 작성한 거와 같음
SELECT 해당층, 평당가, 입력일, 해당동, 매물구분, 연사용일수, 중개업소코드
FORM 매물 아파트 매매
WHERE 인터넷 매물= '1'
AND 아파트시세코드 = 'A01011350900056'
AND 평형 = '59'
AND 평형타입 = 'A'
UION ALL
SELECT 해당층, 평당가, 입력일, 해당동, 매물구분, 연사용일수, 중개업소코드
FORM 매물 아파트 매매
WHERE 인터넷 매물= '2'
AND 아파트시세코드 = 'A01011350900056'
AND 평형 = '59'
AND 평형타입 = 'A'
UNION ALL
SELECT 해당층, 평당가, 입력일, 해당동, 매물구분, 연사용일수, 중개업소코드
FORM 매물 아파트 매매
WHERE 인터넷 매물= '3'
AND 아파트시세코드 = 'A01011350900056'
AND 평형 = '59'
AND 평형타입 = 'A'
ORDER BY 입력일 DESC
-
IN-LIST 개수만큼 UNION ALL 브랜치가 생성
-
각 브랜치마다 모든 컬럼을 = 조건으로 검색하므로 앞선 선두 컬럼에 BETWEEN을 사용할 때와 같은 비효율이 사라짐
-
INDEX SKIP SCAN 방식으로 유도해도 비슷한 효과를 얻을 수 있음
-
IN-List 항목 개수가 늘어날 수 있다면 BETWEEN을 IN-List 로 전환하는 방식은 사용하기 곤란하다
- 그럴 때는 NL 방식의 조인문이나 서브쿼리로 구현하면 된다.
SELECT /*+ ORDERD USE_NL(b) */ b.해당층, b.평당가, b.입력일,
b.해당동, b.매물구분, b.연사용일수, b.중개업소코드
from 통합코드 a, 매물아파트매매 b
where a.코드구분, 'CD064' -- 인터넷매물구분
and a.코드 between '1' and '3'
and b.인터넷매물 = a.코드
and b.아파트시세코드 = 'A01011350900056'
and b.평형 = '59'
and b.평형타입 = 'A'
ORDER BY b.입력일 DESC BETWEEN 조건을 IN-LIST로 전환할시 주의사항
- IN-List 개수가 많지 않아야함
- 많을시 수직적 탐색이 많이 발생
- IN-List 개수만큼 브랜치 블록을 반복 탐색하는 비효율이 더 클수 있다
- 특히 루트에서 브랜치 블록가지 Depth가 깊을시
고객 등급 + 고객 번호 순으로 구성한 인덱스에서 고객번호 = 123 조건을 만족하는 레코드가 서로 멀리떨어져 있을때 BETWEEN 족너을 IN-List로 전환하는 기법이 유용
WHERE 고객등급 BETWEEN 'C' AND 'D'
AND 고객번호 = 123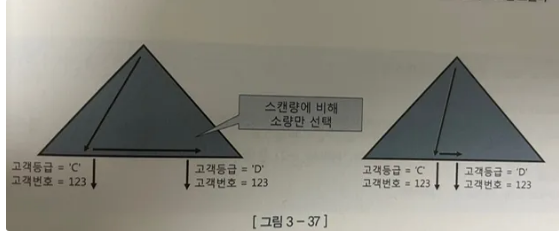
- 우측 그림에서 고객번호 = 123 조건을 만족하는 래코드는 두건 밖에 없지만 두건이 서로 가까이 있음
- 둘사이 놓인 인덱스 블록이 매우 소량
- 이럴때 BETWEEN 을 IN-List 로 변환하면 효과가 전혀 없거나 수직적 탐색 때문에 오히려 블록 I/O가 더 많이 발생
즉 BETWEEN 조건 때문에 인덱스를 비효율적으로 스캔하더라도 블록 I/O 측면에서는 대개 소량에 그치는 경우가 많음
데이터 분포나 수직적 탐색 비용을 따져 보지도 않고 BETWEEN 을 IN-List로 변환하는 우를 범하지 않기!!
Index Skip Scan 활용
create table 월별고객별판매집계
as
select rownum 고객번호
, '2018' || lpad(ceil(rownum/100000), 2, '0') 판매월
, decode(mod(rownum, 12),1, 'A', 'B') 판매구분
, round(dbms_random.value(1000,10000), -2)판매금액 from dual
connect by level <= 1200000;- 2018년 1월 부터 12월 까지 월별 10만개 판매 데이터 입력 후
create index 월별고객판매집계_IDX1 on 월별고객별판매집계(판매구분, 판매월);인덱스 설정후
select count(*)
from 월별고객별판매집계 t
where 판매구분 = 'A'
AND 판매월 BETWEEN '201801' AND '201812'조회시 281개의 블록 I/O 발생
테이블 엑세스는 전혀 발생하지 않음
CREATE INDEX 월별고객판매집계_IDX2 ON 월별고객판매집계(판매월, 판매구분);BETWEEN 조건 판매월 컬럼이 선두 아래 인덱스 사용시
3090개 블록 IO발생
B인 레코드 까지 모두 스캔하고 버렸기 때문
IN-List 로 변경
SELECT /** index(t 월별고객판매집계_IDX2)* /COUNT(*)
FROM 월별고객별판매집계 T
WHERE 판매구분 ='A'
AND 판매월 IN ('201801',201802','201803',201804','201805',201806'
,'201807',201808','201809',201810',
'201811',201812');3090개이던 블록 I/O 개수가 314개로 감소
인덱스 브랜치 블록을 열두번 반복 탐색 했지만 리프 블록을 스캔할때의 비효율을 제거함으로써 성능이 열배 좋아짐
Index Skip Scan으로 변경
select /*+ INDEX_SS(t 월별고객별판매집계_IDX2) */ COUNT(*)
FROM 월별고객별판매집계 T
WHERE 판매구분 ='A'
AND 판매월 BETWEEN '201801' AND '201812';300블록 읽음
| 구분 | IDX1 인덱스 | BETWEEN | IN-LIST | SKIP SCAN |
|---|---|---|---|---|
| 블록I/O | 281 | 3090 | 3140 | 300 |
- 선두컬럼이 BETWEEN 이어서 나머지 검색 조건을 만족하는 데이터들이 서로 멀리 떨어져 있을때 Index Skip Scan 위력이 나타난다
IN 조건은 = 인가
- IN 조건은 = 이 아니다
- 따라서 인덱스를 어떻게 구성하는냐에 따라 성능도 달라질 수 있다.
SELECT * FROM 고객별가입상품
WHERE 고객번호 = :CUST_NO AND 상품ID IN ('NH00037', NH'00041' 'NH00050');인덱스를 상품 + 고객 번호 순으로 생성하면 상품은 고객 번호 순으로 정렬된 하나 혹은 두개의 리프 블록에 저장
반면 고객번호 기준으로 같은 고객번호가 상품 ID 에 따라 뿔뿔이 흩어진 상태가됨
인덱스가 이런식으로 구성 되면 상품 ID 조건절이 IN-List Iterator 방식으로 풀리는 것이 효과적
고객 번호 조건을 만족하는 레코드가 서로 멀리 떨어져 있기 때문
- in 조건은 = 이됨
SELECT *
FROM 고객별가입상품
WHERE 고객번호 = :cust_no
AND 상품ID IN = ‘NH00037’
UNION ALL
SELECT *
FROM 고객별가입상품
WHERE 고객번호 = :cust_no
AND 상품ID IN = ‘NH00041’
UNION ALL
SELECT *
FROM 고객별가입상품
WHERE 고객번호 = :cust_no
AND 상품ID IN = ‘NH00050’다음과 같이 상품 id 조건절을 이처럼 IN-List Iterator 방식으로 풀면 고객번호와 상품 ID 둘다 인덱스 엑세스 조건으로 사용
인덱스를 고객번호 + 상품 ID 순으로 생성시
고객 상품 ID 순으로 정렬된 상태로 같은 리프 블록에 저장
요컨대, IN 조건은 ‘=’이 아니다. IN조건이 ‘=’이 되려면 IN-List Iterator 방식으로 풀려야만 한다. 그렇지 않으면, IN 조건은 필터 조건이다.NUM_INDEX_KEYS 힌트 활용
- IN-List 를 액세스 조건 또는 필터 조건으로 유도한는 방법
- 인덱스가 고객번호 + 상품ID 순으로 구성된 상황에서
- 고객번호만 인덱스 액세스 조건으로 사용하려면
SELECT /*+ num_index_keys(a 고객별가입상품_x1 1) */ *
from 고객별가입상품 a
where 고객번호 = :cust_no
and 상품ID IN ('NH00037', 'NH00041', 'NH00050')- 세번째 인자 ‘1’은 첫번째 컬럼까지만 액세스 조건으로 사용하라는 의미
힌트를 사용하지 않고 인덱스 컬럼을 가공하는 방법
SELECT *
FROM 고객별가입상품
WHERE 고객번호 = :CUST_NO
AND RTRIM(상품ID) IN ('NH00037', 'NH00041', 'NH00050')
SELECT *
FROM 고객별가입상품
WHERE 고객번호 = :CUST_NO
AND 상품ID|| ' ' IN ('NH00037', 'NH00041', 'NH00050')
BETWEEN LIKE 스캔 범위 비교
- LIKE 보다 BETWEEN 을 사용하는게 더 좋다
EX)
WHERE 판매월 BETWEEN '201901' AND '201912'
AND 판매구분 = 'B'
WHERE 판매월 LIKE '2019%'
AND 판매구분 = 'B'
- 조건절 1은 201901 판매구문 B 인 첫번째 레코드에서 스캔 시작
- 조건절 2 는 판매월 201901인 첫 레코드에서 스캔을 시작
WHERE 판매월 BETWEEN '201901' AND '201912'
ANS 판매구분 = 'A'
WHERE 판매월 LIKE '2019%'
AND 판매구분 = 'A'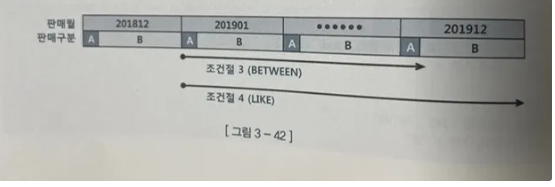
- 조건절 3은 판매월 201912 이고ㅓ 판매구분 B인 첫번째 순간 스캔을 멈춘다
- 조건절 4는 판매월 201912레코드를 모두 스캔하고나서 멈춘다 201913도 있을 수 있으니
OR 조건 활용
SELECT * FROM 거래
WHERE (:cust_id is null or 고객ID = :cust_id)
and 거래일자 between :dt1 and dt2고객 ID 거래 일자 순으로 인덱스 구성해도 이를 사용할 수 없다
- 즉 인덱스 선두 컬럼에는 OR 을 사용하면 안된다
거래일자 + 고객 ID 순으로 구성한 인덱스는 사용할 수 있다
- 하지만 고객 ID 를 필터 조건으로 사용하는데 문제가 있다.
- 인덱스 스캔 단계에서 필터링 해도 비효율적
- 테이블 엑세스 단계에서 필터링
즉 OR 조건 활용한 옵션 조건 처리는
- 인덱스 액세스 조건으로 사용불가
- 인덱스 필터 조건으로 사용블가
- 테이블 필터 조건으로만 사용 가능
select * from 거래
where 고객ID = :cust_id
and ((:dt_type = 'A' AND 거래일자 BETWEEN :DT1 AND DT2)
OR
(:dt_type = 'B' AND 거래일자 BETWEEN :dt1 and dt2))- or 조건절에는 or-expansion 을 토앻 인덱스 사용이 가능하다
LIKE/BETWEEN 활용
- 필수 조건 컬럼을 인덱스 선두에 두고 액세스 조건으로 사용하면 , LIKE/BETWEEN 이 인덱스 필터 조건이어도 충분히 좋은 성능을 낼수 있다.
SELECT * FROM 상품
WHERE 등록일시 >= trunc(sysdate) // 필수 조건
and 상품분류코드 like :prd_cls_cd || '%' // 옵션조건- 필수 조건이 = 이면 옵션 조건인 상품 분류 코드 까지도 인덱스 액세스 조건이므로 최적의 성능으 ㄹ뇔수 있다.
SELECT * FROM 상품
WHERE 상품대분류코드 >= :prd_lcls_Cd // 필수 조건
and 상품코드 like :prd_cls_cd || '%' // 옵션조건- 다음과 같이 필수 조건이 변별력이 좋지 않을시 문제이다
- 이는 상품 코드 까지 입력시 최적의 성능을 내겠지만 그렇지 않을시 성능 문제가 생긴다
LIKE/BETWEEN 패턴 사용하고자 할때 반드시 점검 내용
- 인덱스 선두 컬럼
- NULL 허용 컬럼
- 숫자형 컬럼
- 가변 길이 컬럼
UNION ALL 활용
SELECT * FROM 거래
WHERE :cust_id is null
and 거래일자 between :dt1 and :dt2
union all
select * from 거래
where :cust_id is not null
and 고객id= :cust_id
and 거래일자 between :dt1 and dt2- 고객 id를 입력하지 않으면 거래일자 가 선두인 인덱스 사용하고
- 변수를 입력하면 고객id + 거래일자 인덱스를 사용한다
- 단점은 sql 코딩량이 길어진다
NVL/ DECODE 함수
select * from 거래
where 고객ID = nvl(:cust_id, 고객ID)
and 거래일자 between :dt1 and dt2
또는
select * from 거래
where 고객ID = decode(:cust_id, null, 고객ID, :cust_id)
and 거래일자 between :dt1 and dt2
-
:cust_id 를 입력하지 않음 거래일자 선두 인덱스
-
변수 입력시 고객 +거래일자 인덱스 사용
-
UNION ALL 보다 단순하면서도 UNION ALL 과 같은 성능을 낸다
-
단점은 앞서 설명한 LIKE 패턴처럼 NULL 허용 컬럼에 사용할 수 없다는데 있다.
-
옵션 조건 처리용 NVL/DECODE 함수를 여러개 사용하면 그중 변별력이 가장 좋은 컬럼 기준으로 한번만 OR Expansion이 일어난다
PL/SQL
- PL/SQL 사용자 정의 함수는 개발자들이 일반적으로 생각하는 것보다 느리다
느린 이유
- 가상머신 상 실행되는 인프리터 언어
- 호출 시마다 컨텍스트 스위칭 발생
- 내장 SQL 에 대한 RECURSIVE CALL 발생
효과적인 인덱스 구성을 통한 함수 호출 최소화
select /*+ full(a) */ 회원번호, 회원명, 생년, 생월일, 등록일자
from 회원 a
where 암호화된_전화번호 = encryption(:phone_no)- 회원테이블을 full scan 방식으로 읽으면 encryption 함수는 테이블 건수만큼 수행
select /*+ full(a) */ 회원번호, 회원명 , 생년, 생월일, 등록일자 from 회원 a
where 생년 = '1987'
and 암호화된_전화번호 = encryption(:phone_no)
// 조건절 생년을 만족하는 건수만큼 수행됨
create index 회원_X01 on 회원 (생년);
// 암호화된 전화번호 조건절을 테이블 액세스 단계에서 필터링 즉 생년 조건을 만족하는 건수만큼 수행
create index 회원_X02 on 회원 (생년, 생월일, 암호화된_전화번호);
// 인덱스 필터 조건 인덱스 스캔 횟수 즉 생년 조건을 만족하는 건수만큼 수행
create index 회원_X03 on 회원 (생년, 암호화된_전화번호);
// encryption 함수 단 함번 수행 