Data가 분산되어 저장되어 있을 수 있다. 각 DB는 DBMS에 의해 독립적으로 관리된다. 각 분산 Data는 독립적이어야 하며 원자성을 보장 받아야 한다.
분산 DB의 종류
- Homogeneous
각 site의 DB가 같은 type의 DBMS에 의해서 관리된다. - Heterogeneous
각 site의 DB가 다른 type의 DBMS에 의해서 관리된다.

분산 DB 아키텍처
- Client - Server 구조
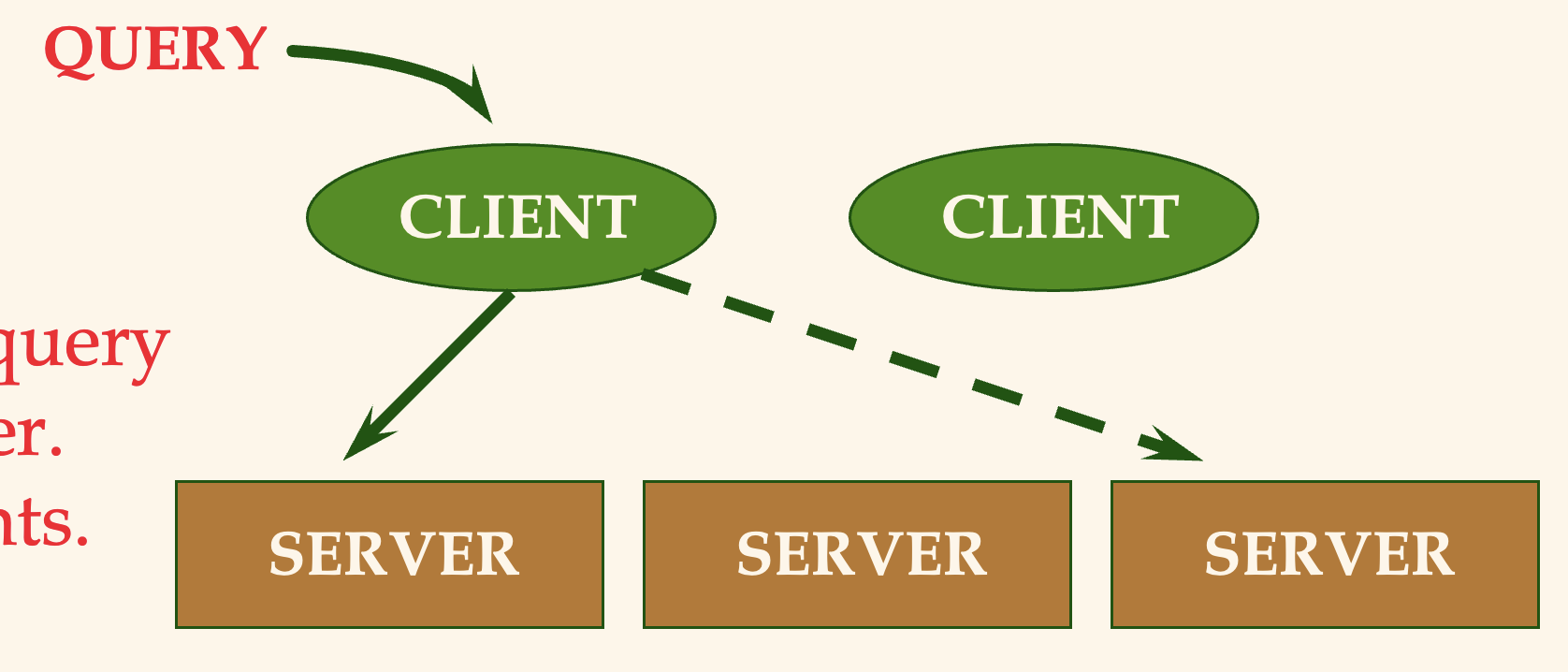
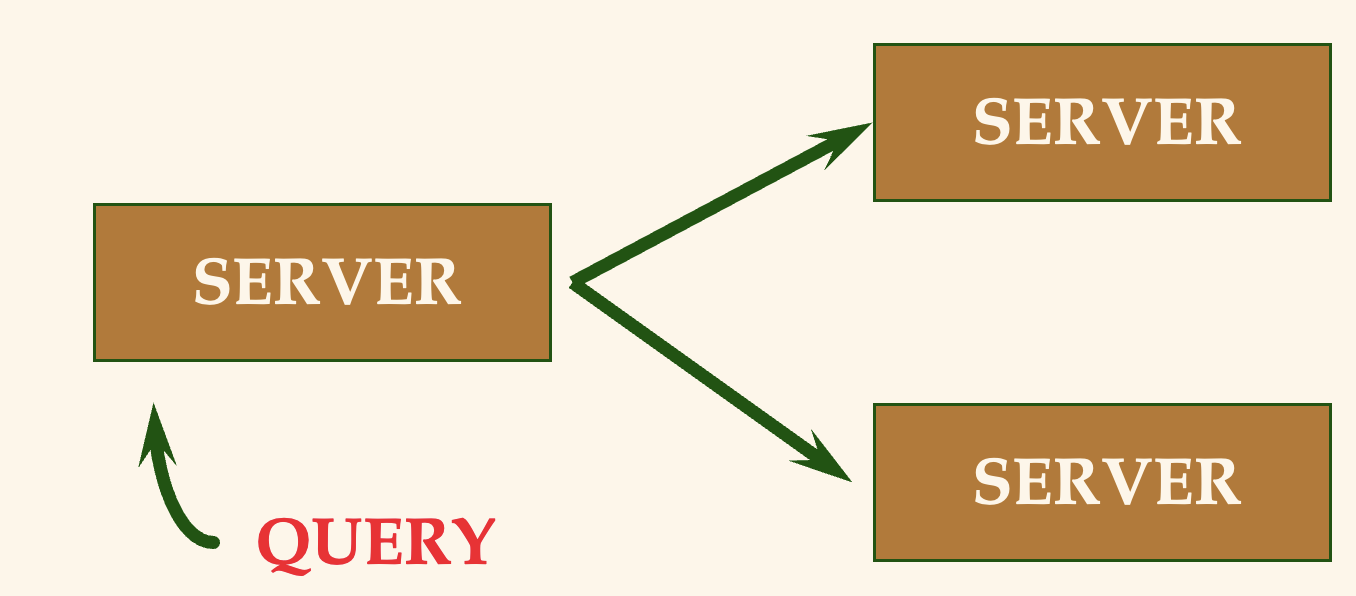
- Collaborating - Server 구조
분산 데이터 저장 방법
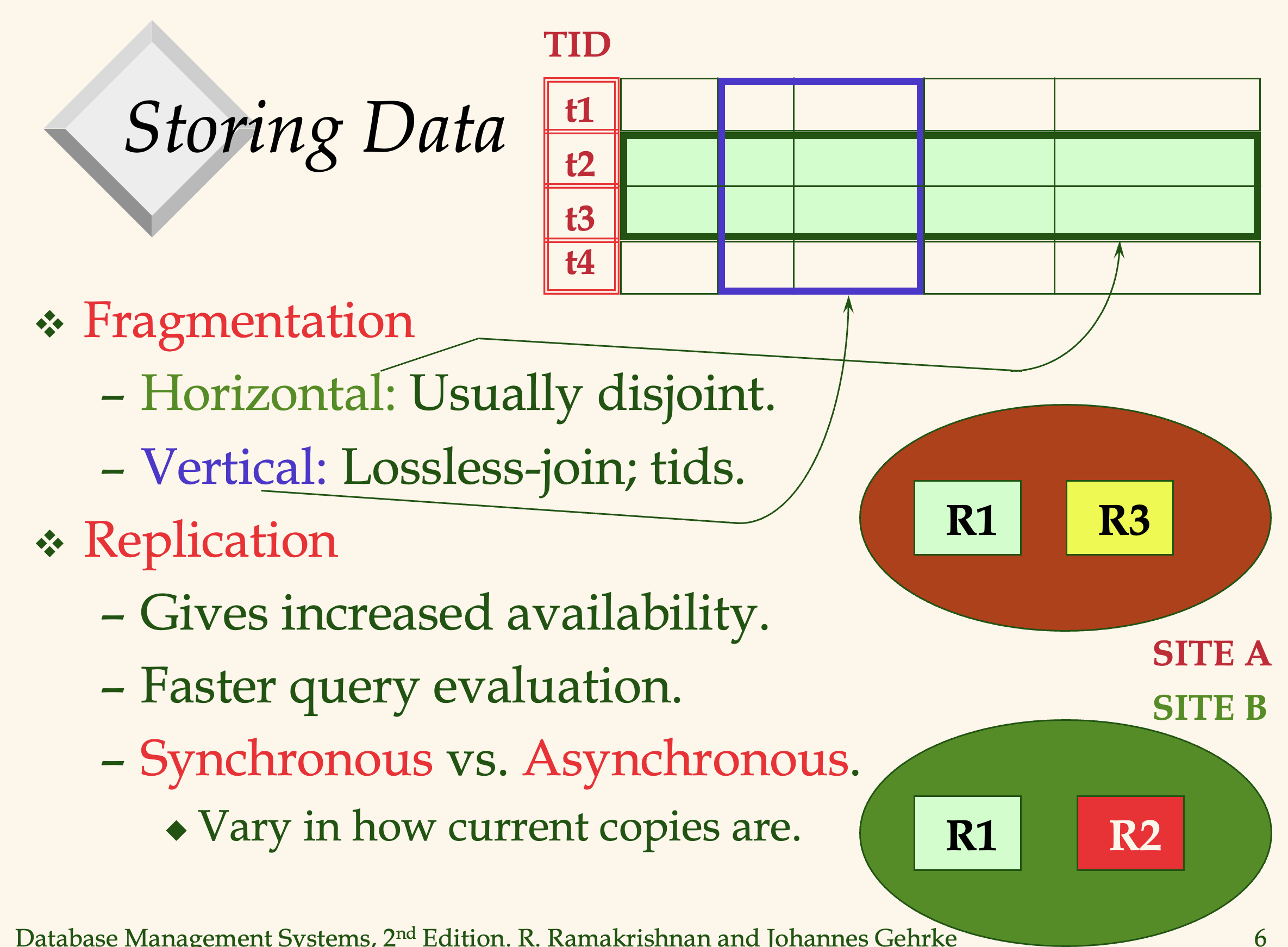
- Fragmentation
해당 저장방법에서는 각 relation들이 파편화, 즉 잘게 쪼개진다. 또한 각 파편들은 각자 다른 site에 저장된다.- Horizontal
relation을 row by row로 나누어서 site에 분산 저장한다. - Vertical
relation을 col by col로 나누어서 site에 분산 저장한다.
- Horizontal
- Replication
해당 저장방법에서는 각 relation들이 copy되어 각 site에 저장된다. 가용성이 증가한다.- 동기식
- 비동기식
반영시간의 차이
분산 Catalog 관리법
- Data가 어떻게 분산되었는지 tracking하고 있어야 한다.
- 각 fragment의 각 replica 마다 naming이 필요하다.

- Site Catalog
각 site마다 모든 Object들( fragment, replica)을 기술한다.
각 site마다 생성되는 relation들의 replica를 traking한다.- relation을 찾기 위해 birth-site catalog를 참조한다.
- relation이 이동하여도, birth-site는 절대 변하지 않는다.
분산 질의
분산된 DB의 데이터 저장 방법에 따른 질의 실행 방법

- Horizontally Fragmented ( relation이 row by row 로 분산 저장 )
- row by row 로 분산 저장되어 있다.
- rating < 5 인 tuple은 상하이에 저장되어 있다.
- rating >= 5 인 tuple은 도쿄에 저장되어 있다.
- 각 site (상하이,도쿄)별로 SUM(age)와 COUNT(age)를 계산해야한다.
- 만일 where절에 s.rating > 6 과 같은 조건식이 있다면 도쿄에서만 계산해도 된다.- Vertically Fragmented ( relation이 col by col 로 분산 저장 )
- sid와 rating은 상하이에 저장되어있다.
- sname과 age는 도쿄에 저장되어있다.
- tid는 두 곳 모두에 저장되어있다.
- 질의를 평가하기 위해 tid를 통해 원격지들의 relation을 join해주어야한다.- Replicated ( Relation이 복사되어 분산 저장 )
- Sailors 테이블이 각 site에 모두 저장되어있다.
- local cost와 shipping cost를 고려해서 site를 지정한 후 compute한다.분산 조인

두 테이블을 자연 조인하는 상황
- 필요한 만큼 page를 fetch 한다.
- 500*D + 500*1000(D+S)
런던 site에서 Sailors 테이블의 페이지들을 가져오는 cost : 500*D
파리 site에서 Reserves 테이블의 페이지들을 가져오는 cost : 1000*D
추가적으로 파리 site에서 런던 site로 data를 가져오는 cost: S
즉, 파리에서 페이지 fetch 후 런던에 shipping하는 cost : 1000*(S+D)
- 500*D + 500*1000(D+S)
- Ship to One Site : Reserve를 London으로 이동
- 1000*S + 4500*D
세미 조인

- London site에서 조인에 필요한 col만 추출하여 파리로 이동
- Paris site에서 추출된 col로 Reserve와 조인진행
- Reduction of Reserve를 다시 London으로 이동
- London site에서 Sailors와 reduction of Reserves의 조인 진행
즉, 모든 테이블을 원격지로 이동하는 것은 비효율적이므로 조인에 필요한 col만 추출하여 조인을 진행해서 테이블 사이즈를 줄이고 다시 가져와서 조인을 하는 형태이다.
아래의 예시를 통해, 얼마나 효율적인지 알아보자

Bloom 조인

- London site에서 K 사이즈의 vit-vector 계산진행
- tuple에 대해 모듈로 K로 hash를 진행하여 , 0~k-1 bit vector 표시
- 만일 특정 tuple의 hash결과값이 i라면 , i번째 bit를 1로 설정
- bit-vector를 paris로 이동
- Paris site에서 위와 동일하게 Reserve tuple에 대해 hashing을 진행하여
K' bit vector 생성. London으로부터 받은 bit vector와 대조하여 london bit vector가 0인 바스켓의 K' bit vector 바스켓의 tuple들은 폐기 ( 어차피 런던 원격지에서 존재하지 않는 tuple이기 때문에 조인에 필요없기 때문예) - 이후 Paris에서 bit vector reduction된 table을 London으로 보낸다
- London에서 받은 bit vector reduction table을 바탕으로 조인 진행
- 가장 효과적인 shipping 알고리즘
분산 Data 업데이트
동기식 복제 (Synchronous Replication)
모든 relation의 copy들은 해당 relation을 수정하는 TX이 발생했을 경우 Commit되기 전에, 전부 update되어야한다.
- Voting
- Read-any-Write-all
비동기식 복제 (Asynchronous Replication)
수정사항이 발생했을 때 copy들에 대한 update가 수정과는 관련없이 주기적으로 이루어진다.
- Primary site
1개의 master copy 존재 - peer-to-peer
여러개의 master copy 존재
분산 locking
많은 site에 걸쳐 존재하는 lock들을 어떻게 관리할까?

- Centralized
마스터 site만 locking을 진행한다. - Primary copy
Object가 생성된 site에서 locking을 진행한다. - Fully distributed
Object가 저장된 모든 Site마다 locking을 진행한다.
분산 Deadlock 탐지
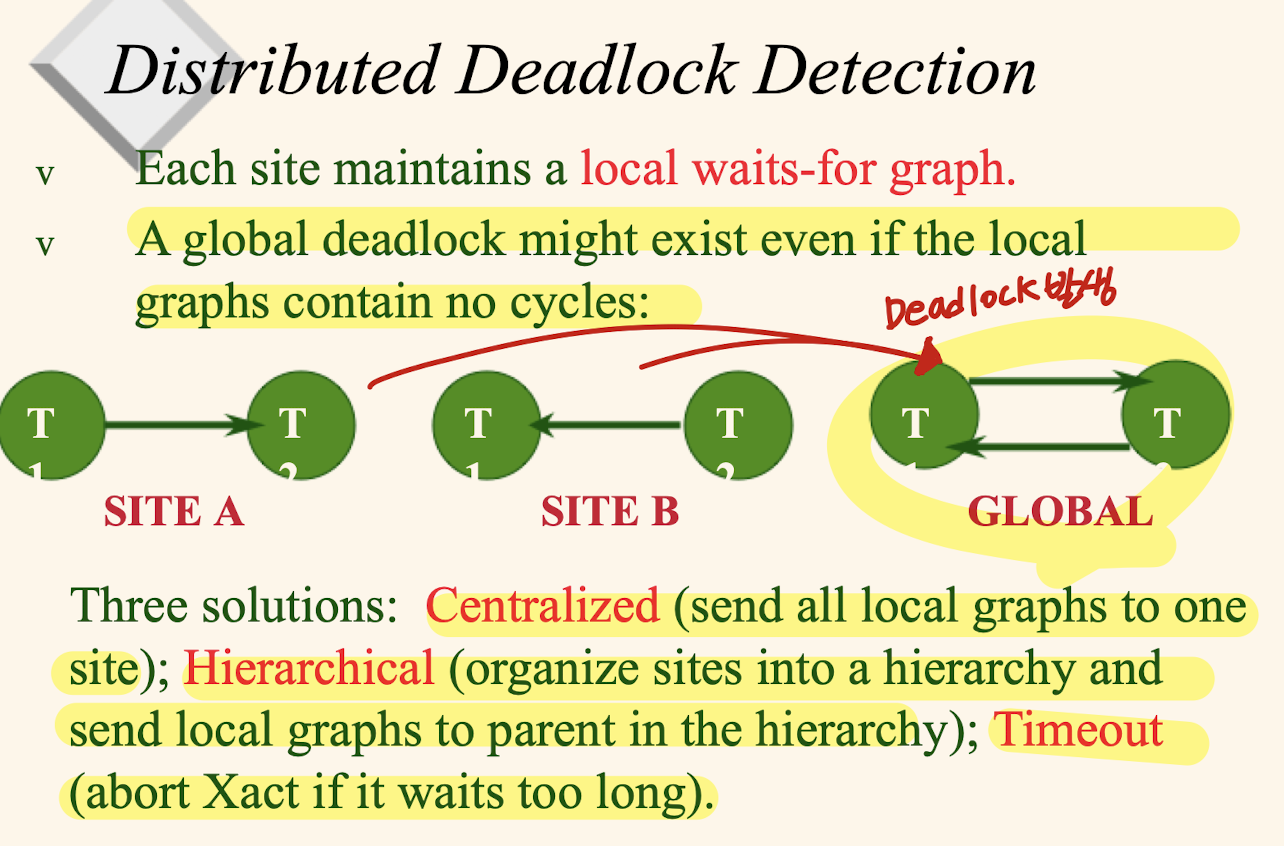
- 각 site의 local에서 TX 사이의 가중치 그래프를 그려준다.
- local 그래프들을 합쳐서 cycle 발생시 deadlock 발생
해결책
- Centralized ( 중앙집중식 )
모든 local 그래프들을 한 site로 넣어준다. - Hierarchical ( 계층식 )
site들을 계층화하여 해결해 준다. - Timeout ( 시간제한 )
TX이 너무 오래기다릴 경우 해당 TX을 abort하는 방식으로 해결해준다.
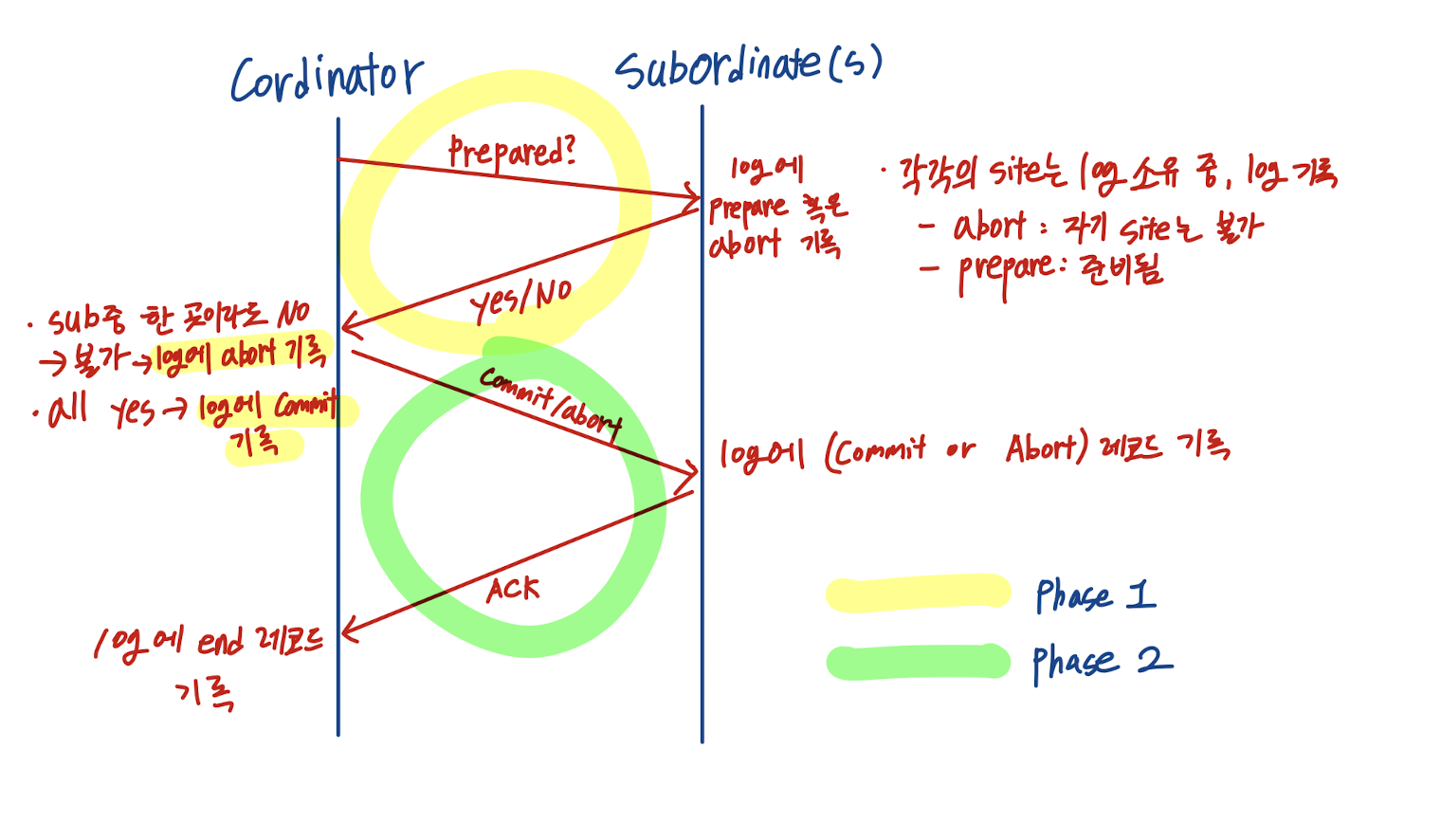
2 Phase Commit
코디네이터가 분산 DB상의 Commit을 중재하여 원격지 site들의 atmoic한 TX을 보장한다.

CS 박제