크롤링이 뭔가요??
크롤링은 인터넷 상에 있는 수많은 자료들을 가져와 프로그래밍하기 쉽게, 혹은 데이터 분석하기 쉬운 형태로 가공하는 작업을 의미합니다.
예를 들어서 공지를 자주 확인해야 한다면, 크롤링을 통하여 한번에 다양한 공지들을 한번에 확인할 수 있습니다.
크롤링의 방법은 여러 방법들이 있겠지만, 파이썬을 이용한 크롤링을 해보려 합니다.
1. 어떤 라이브러리 / 프레임워크를 사용하나요??
아는 방법은 두 가지가 있습니다.
- request와 beautifulSoup 이용
- Selenium과 WebDriver 이용
이 두 방안 중 오늘은 request와 beautifulSoup를 이용하는 방안을 이야기 해보려 합니다.
위의 requests와 beautifulSoup는
pip install request
pip install beautifulsoup4위와 같은 명령어로 설치해주시면 됩니다.
pip가 설치되지 않았다면, pip부터 설치해주셔야 합니다.
2. requests
requests는 HTTP요청을 보내는 모듈입니다. 간결한 코드로 HTTP요청을 보낼 수 있기에 많이 쓰입니다.
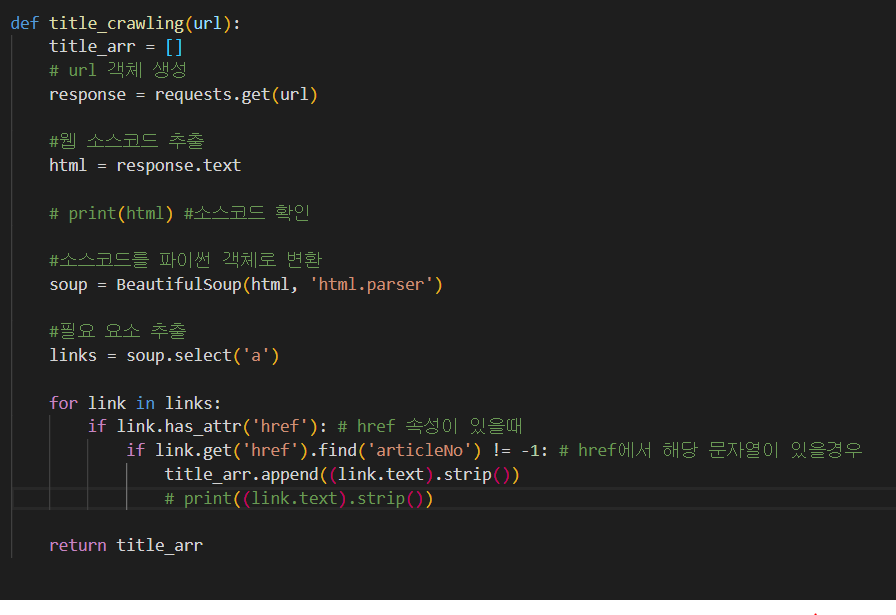
import requests위와 같이 라이브러리를 먼저 import시켜주고 시작합니다.
최초에 url에 따른 객체를 만들어 주어야 합니다.
response = requests.get(url)url을 객체화 시켜서 response라는 변수에 저장하였습니다.
그 다음은, 탐색하기 위해 웹의 소스코드를 추출해야 합니다.
소스코드는 크롬에서 ctrl+U로 접근이 가능합니다.
html = response.texthtml을 출력하는 방식으로 콘솔 창에서 소스코드를 볼 수 있겠지만, 그냥 크롬에서 위의 방식으로 체크하시는 것을 추천드립니다.
이제 이 소스코드를 필요에 맞게 조작,탐색해야합니다.
지금부터 필요한 것이 위에서 말했던 beautifulsoup4입니다.
3. BeautifulSoup
beautifulsoup는 HTML 파싱 라이브러리로서, 몇 개의 메소드만으로 손쉽게 추출이 가능합니다.
from bs4 import BeautifulSoup최상단에 BeautifulSoup를 위와 같은 코드로 import해줍니다.
HTML추출 이후부터 다시 진행해보겠습니다.
입력받은 소스코드를 파이썬에 맞게 파이썬 객체로 변환하여야 합니다.
soup = BeautifulSoup(html, 'html.parser')위의 코드를 통해 추출한 url의 소스코드가 파이썬 객체로 저장되었습니다.
이제 이 soup를 통해 필요한 값을 찾아가는 일만 남았습니다.
찾기 전에 내가 필요한 값이 a태그 내부에 있음을 알기에 select를 통해 a태그의 값만 빼내주겠습니다.
links = soup.select('a')이 코드를 조금 응용하면 select함수의 인자로 들어가는 자리에 'a > div'라고 사용한다면, a태그 내부의 div태그 내부의 소스를 저장해줍니다.
..2에서 계속