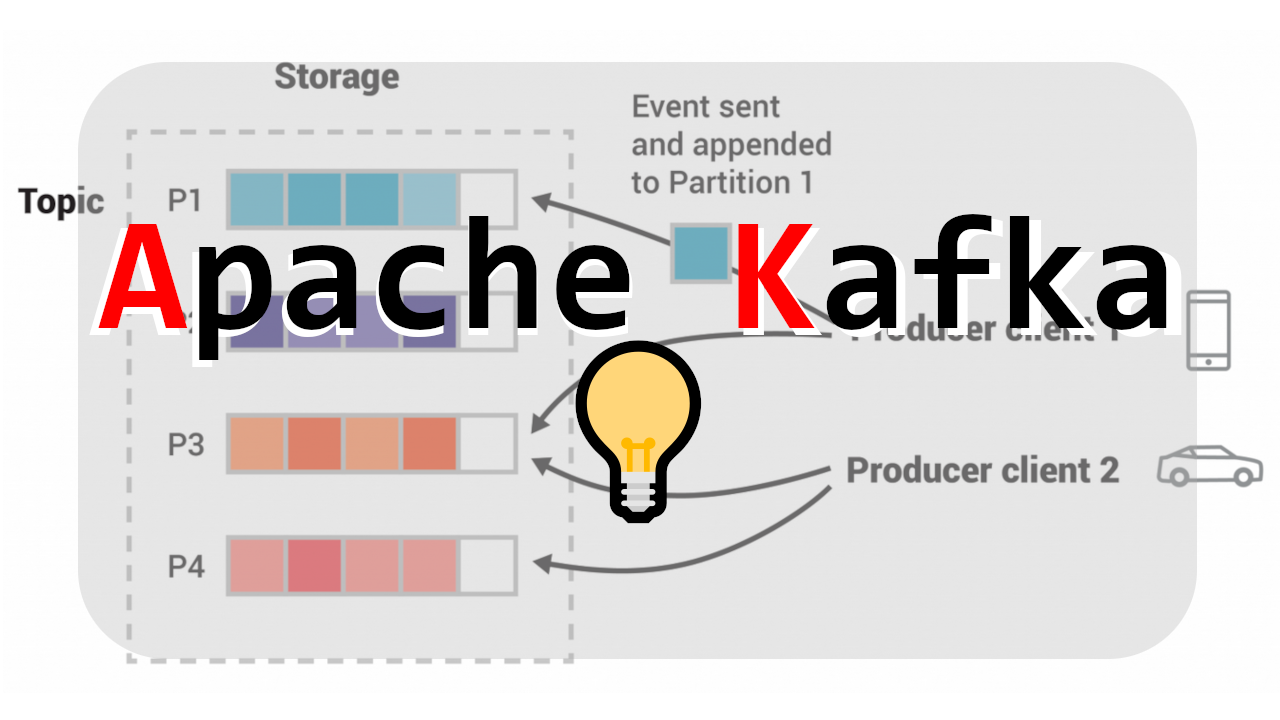
1. Streams
💬 Streams 란
- 토픽에 적재된 데이터를
실시간으로처리하고 분석하기 위한 라이브러리다. - 데이터를 변환, 필터링, 집계 등 분석할 수 있다.
💬 Streams 제공
filter(),map(),groupBy()등 다양한 처리, 집계 함수를 제공State Store사용으로 메시지키 별,시간 간격 별등으로 집계할 수 있다.
💬 Streams Processing
- application 이벤트에 즉각적으로 반응한다.
- 지속적으로 유입되는 데이터 분석에 최적화 되어있다.
💬 Streams 한마디로 정리
- Topic으로 들어오는 데이터를 Consume하여 Kafka Streams에서 제공하는 처리 로직을 통해 처리 후 다른 Topic으로 전송하거나 끝내는 부분을 수행해주는 라이브러리다.
2. Streams 구조
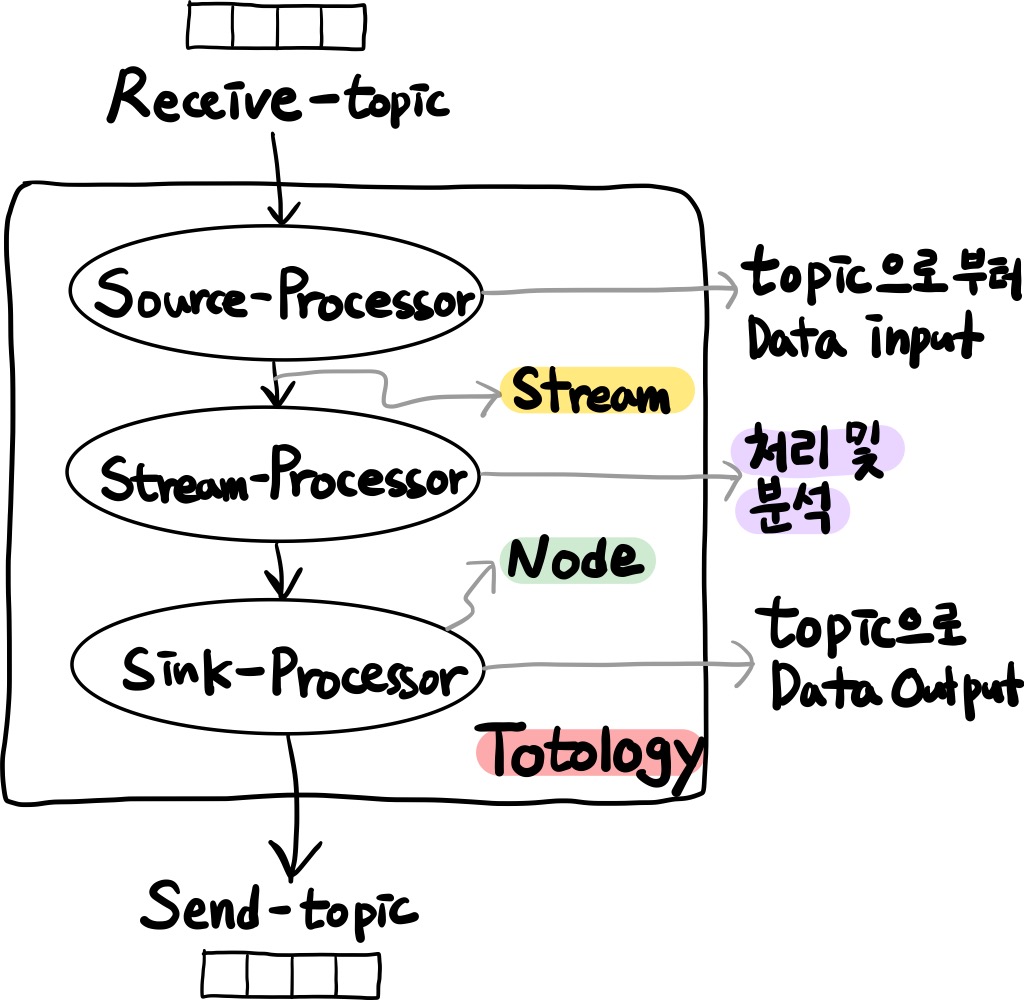
💬 Topology
- 토폴로지는
노드와,스트림으로 이루어져 있다.
💬 Stream
- 카프카 스트림즈 API를 사용해서 생성된 토폴로지로 끊임없이 전달되는 데이터느 세트를 의미한다.
key-value형태로 띄고 있다.
💬 Source Processor
- 토폴로지의 시작 노드이다.
- 카프카와 연결되는 프로세서이다.
- 하나 이상의 토픽에서 데이터를 가져오는 역할을 한다.
💬 Stream Processor
- 연결된 하나의 입력 스트림으로부터 데이터를 받아서
처리 및 분석한 다음 다시 연결된 프로세서에 보내는 역할을 한다.
💬 Sink Processor
- 토폴로지를 이루는 마지막 노드이다.
- 카프카와 연결되는 프로세서이다.
- 데이터를 카프카의 특정 토픽으로 저장하는 역할을 한다.
3. Processor API
💬 KStream
- KStream으로 데이터를 조회하면 토픽에 존재하는 모든 데이터가 출력
- 토픽에 존재하는 데이터의
key의 중복을 허용한다.
💬 KTable
- KStream으로 데이터를 조회하면 토픽에 존재하는 데이터의 key의 중복을 허용하지 않고,
가장 최신에 넣어진 key의 값으로 덮어씌어 진다. - 스냅샷, 파티션 별로 로컬에서 관리하는 상태 저장소
💬 GlobalKTable
- 입력 토픽 데이터를 읽어 모든 application process에서 접근 가능한 전역 저장소이다.
- 입력 토픽의 모든 파티션 데이터를 읽어 상태 저장소를 구성
📚 참고
- https://kafka.apache.org/documentation/streams/
- https://velog.io/@jwpark06/Kafka-%EC%8A%A4%ED%8A%B8%EB%A6%BC%EC%A6%88-%EC%95%8C%EC%95%84%EB%B3%B4%EA%B8%B0
- https://jobc.tistory.com/215
- https://ooeunz.tistory.com/137
- https://velog.io/@jwpark06/Kafka-%EC%8A%A4%ED%8A%B8%EB%A6%BC%EC%A6%88-%EC%95%8C%EC%95%84%EB%B3%B4%EA%B8%B0
- https://m.blog.naver.com/syam2000/222158302362

나도 보기 위해 정리해 놓은 벨로그