삽질 환경
증상
지속적인 HTTP 503 Service Unavailable 에러 발생.
규칙적인 발생이 아닌 불규칙 적인 발생.
별다른 Request가 없어도 주기적으로 503 발생.
로컬에서 작업당시 전혀 문제 없음.
언어
Nest.js
당시 시스템 아키텍처
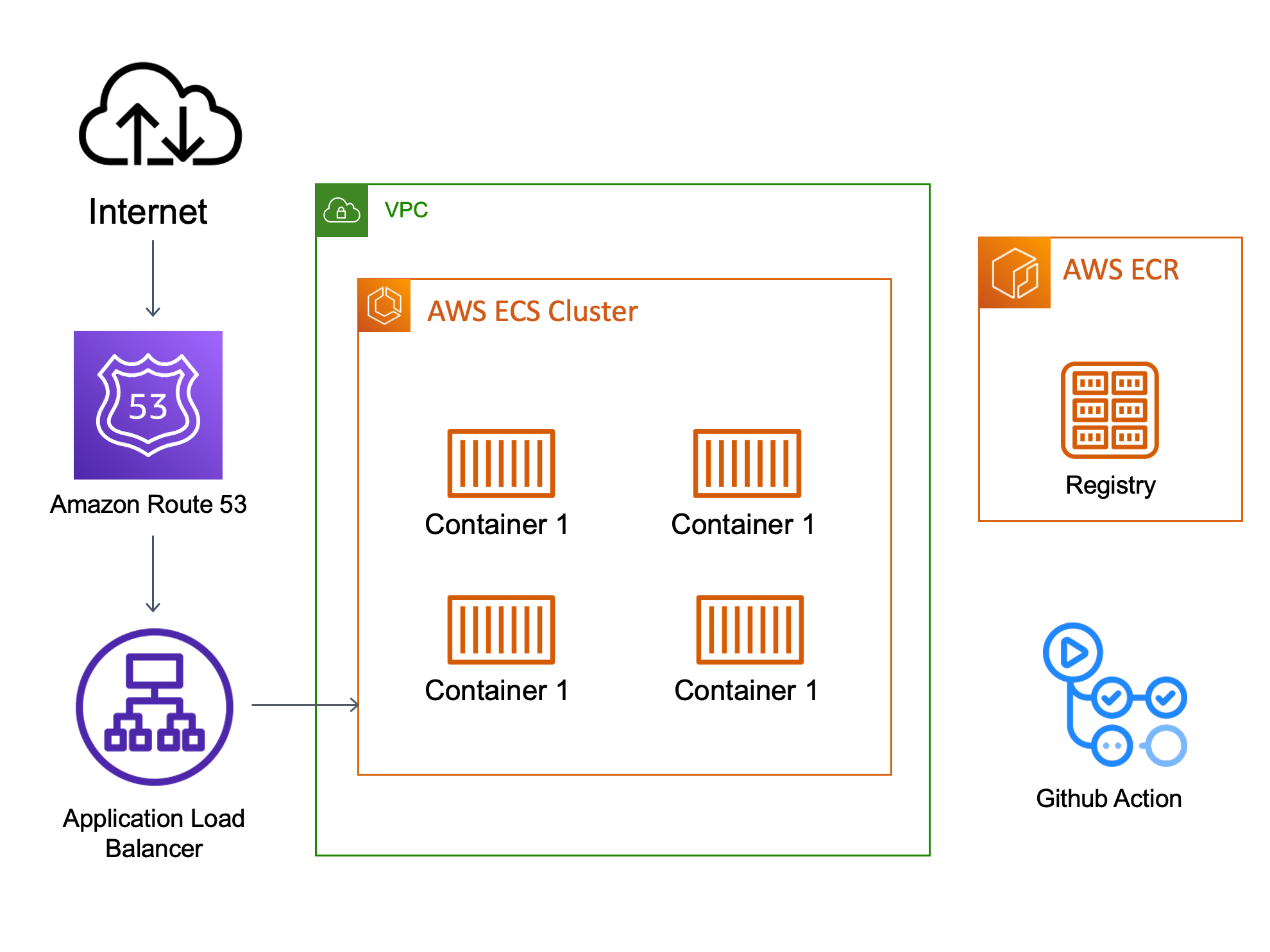
삽질 과정
서버 코드 점검
먼저 Validation을 실패한 부분이 없는지 여러가지 Test Input을 입력했다. 그럼에도 Local에서 지속적으로 작동이 잘 되는 것을 확인하였다. 같은 오류가 반복되자 Exception filters까지 사용하여 서버가 갑자기 중단되는 상황을 최소한으로 줄였다.
그럼에도 불구하고 지속적인 503 에러코드가 발생하였고, 끝없는 삽질 끝에 AWS를 확인하기 시작했다.
AWS 점검
- ECS 클러스터에서 Task의 상태를 확인했다.
- 상태는 ACTIVE 전혀 문제없었다.
- 작업상태를 파악해보았다.
- 작업 상태는 몇개의 서비스가 RUNNING을 유지했고 나머지는 Initial, Draining가 순차적으로 변경되고 있었다.
- 서비스가 안정적으로 작동하지 않는 것에 대해 의문점을 느꼈다.
- 서비스의 로그를 각각 확인했을때, 서버가 실행되었다는 로그 외에는 별다른 특징을 찾지 못했다.
- 무엇이 문제인지 확인이 안되어 삽질 끝에 ELB(Elastic Load Balancer)를 확인하라는 내용을 파악했다.
- 그리고 발견된 2개의 unhealthy
Health-check
ECS는 생성 당시 로드밸런서를 필수적으로 한개 이상 갖고 있어야한다.
Health 상태를 확인하고 싶으면 EC2의 로드밸런서 파트 중 대상그룹에서 확인할 수 있다.
ECS를 사용할때 ELB는 각각의 컨테이너 상태를 미리 파악하여 서비스가 정상적으로 실행되고 있는 컨테이너에게 사용자를 연결해준다. 이때 컨테이너의 상태가 정상인지 비정상인지 파악하는 방법을 Health-check라고 부르는데 방법은 단순하다.
각 서버에 Health-check를 할 수 있는 API를 요청한다. 물론, API는 사용자가 지정 해놓은 요청이다. 요청을 보내면 반환되는 status값을 기준으로 현재 서버가 정상적으로 실행되었는지 요청의 문제가 있는지 파악한다. 예를들어 ELB에서 특정 사이클마다 Health-check하는 요청을 보냈을때 200번대 값이 status 코드로 반환되면 ELB는 서버가 정상작동하고 있다고 판단하며 그외 400번대나 500번대 값이 반환되면 서버가 정상적으로 실행되고 있지 않다고 판단하는 것이다.
분명 서버가 구동중인데?
503번대 오류가 발생한 이유는 Health-check 과정이었다. 서버가 아예 실행되지 않으면 모를까 정상적으로 작동한다는 것과 불규칙적으로 서버가 시작과 멈춤을 반복하는 것이 한번에 이해되는 상황이었다. 첫 생성 당시 Health-Check를 위해 Health-check를 위한 요청주소를 작성한다. 기본 요청 주소는 '/'이다. google.com을 예로 들자면 google.com/에 요청을 보내고 반환되는 status 값이 사전에 healthy하다고 지정해놓은 status값과 동일하면 서버가 정상적으로 구동하고 있다고 판단하는 것이다. 하지만 API를 제공하는 서비스의 특징상 내 서비스에는 '/'와 관련된 API는 없었다. 직접 요청해보니 아래 값을 반환했다.
{"statusCode":404,"message":"Cannot GET /","error":"Not Found"}
내가 Health-Check를 위해 지정해 놓은 API는 기본 주소인 '/'이었고, heatly 하다고 판단하는 statusCode는 200번 이었다. 결과적으로 404 statusCode를 반환받은 ELB는 서버가 정상적으로 구동되지 않고 있다고 확인하고 대상을 계속 재시작하는 것이었다. ELB가 Health-check를 진행하기 전까지는 서비스가 잘 구동되다가 Health-check만 하면 서비스가 종료되는 이슈였다.
ELB에서는 Health-Check용 API를 사용자가 직접 지정할 수 있다.
Healthy 하다고 판단하는 Status Code 또한 직접 설정할 수 있다. ( 404도 가능 )
Healthy 여부를 요청하고 반환하는데까지 걸리는 시간 또한 직접 지정할 수 있다.
결론
서버는 건강한데 안건강한것 같다고 계속 재시동만했네 ,,
