자바 가상 머신(JVM)은 가비지 컬렉터(Garbage Collector)를 이용하여 Heap 메모리 영역에서 사용하지 않는 메모리를 자동으로 회수해 준다.
자바는 이 가비지 컬렉터를 이용해 자동으로 메모리를 실시간 최적화 시켜주어 개발자가 따로 메모리 관리를 하지 않아도 되어 손쉽게 프로그래밍을 할 수 있게 도와준다.
가비지 컬렉터(GC)는 자동으로 실행되지만 실행되는 시간은 정해져 있지가 않다.
전제 조건
GC는 'Weak Generational Hypothesis'라는 가술을 기반으로 만들어졌다.
- 대부분의 객체는 금방 접근 불가능(unreachable)한 상태가 된다.
- 오래된 객체에서 젊은 객체로의 참조는 아주 적게 발생한다.
Heap 구조
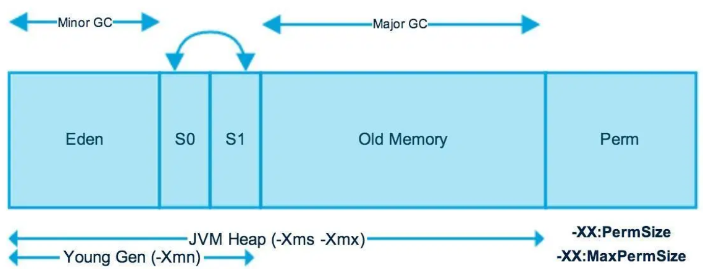
- Permanent 영역은 Java 8부터 MetaSpace로 변경되었다.
- Heap Area는 Eden, Survivor1, Survivor2, Old Generation으로 구분된다.
- Java 9부터는 Heap memory의 Young이나 Old가 논리적으로 분할되어 있으며 동적으로 영역 사이즈를 변경하게 된다.
- Eden, Survivor1, 2를 합쳐서 Young Generation이라고 칭한다.
- Young Generation에서 발생하는 GC를 Minor GC, Old Generation에서 발생하는 GC를 Major GC라고 하며 Minor GC보다 속도가 느리다.
STW(Stop The World)
- STW는 Stop The World의 약자로 자바 어플리케이션은 GC를 실행하기 위한 Thread를 제외하고 이외의 모든 Thread는 멈추고 GC가 완료된 이후에나 다시 Thread가 실행 상태로 돌아가게 하는데 이 멈춤 현상을 말한다.
마크 앤 스윕(Mark and Sweep)
가비지 컬렉터에는 GC Root라는 것이 있다. GC Root들은 힙 외부에서 접근할 수 있는 변수나 오브젝트를 뜻한다.
GC Root는 말그대로 가비지 컬렉션의 Root라는 뜻이다.
GC Root에서 시작해 이 Root가 참조하는 모든 오브젝트, 또 그 오브젝트들이 참조하는 다른 오브젝트들을 탐색해 내려가며 마크(Mark)한다.
이 탐색해 내려가며 마크하는 것을 Mark단계라고 한다.
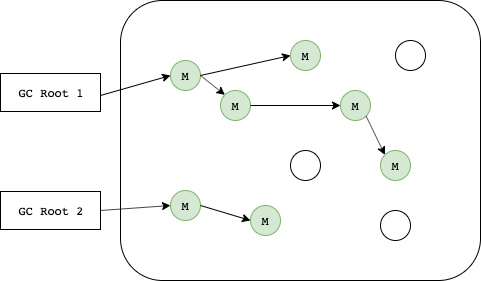
GC Root가 될 수 있는 것들은 다음과 같다.
- 실행중인 쓰레드 (Active Thread)
- 정적 변수 (Static Vartiable)
- 로컬 변수 (Local Variable)
- JNI 레퍼런스 (JNI Reference)
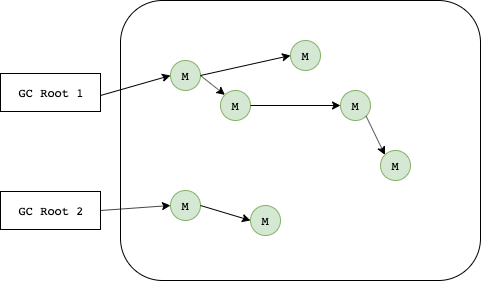
Mark가 끝나면 가비지 컬렉터는 힙 내부를 전체를 돌면서 Mark되지 않은 메모리들을 해제(Reclaim)한다. 이 과정을 Sweep이라고 부른다.
GC 동작 과정
- 객체가 생성이 되면 Eden 영역에 생성된다.
- Eden 영역이 차게 되면 Minor GC가 발생하고 Mark and Sweep과 aging을 거쳐 살아남은 객체를 Survivor1 또는 Survivor2 영역으로 이동시킨다.
- Survivor 영역을 거치지 않고 바로 Old Genration으로 이동하는 경우가 있는데, 객체의 크기가 Survivor 영역의 크기보다 클 경우이다.
- Survivor1과 Survivor2 영역은 둘 중 한 곳에만 객체가 존재하며, 다른 한 곳은 항상 비어져 있다.
- 보통 From, to 로 구분을 하는데, 객체가 존재하는 Survivor영역(From)이 가득 차면 다른 Survivor영역(To)으로 보내게되고, 기존의 Survivor영역(From)을 비우는 작업을 진행한다.
-
위 과정(1~2)을 반복하면서 Survivor 영역에서 계속 살아남는 객체들의 age값이 MaxTenuringThreshold 기준을 넘어가게 되면 Old Generation 영역으로 이동하게 된다.
-
Old Generation 영역에서 살아남았던 객체들이 일정 수준 쌓이게 되면 미사용된다고 식별된 객체들을 제거해주는 Full GC가 발생한다.
- 이 과정에서 STW(Stop-The-World)가 발생한다.
GC의 종류
- Serial GC
- Parallel GC
- Parallel Compacting GC
- Concurrent Mark-Sweep(CMS) GC
- G1(Garbage First) GC
- Z Garbage Collectors (ZGC)
- Shenandoah GC
Serial GC
하나의 스레드로 Young 영역과 Old 영역을 연속적으로 처리하는 방식이다.
GC가 수행될 때 STW가 발생한다.
Client VM의 기본 컬렉터이며 현재는 거의 사용되지 않는다.
Mark-Sweep-Compact 알고리즘을 사용한다.
Parallel GC
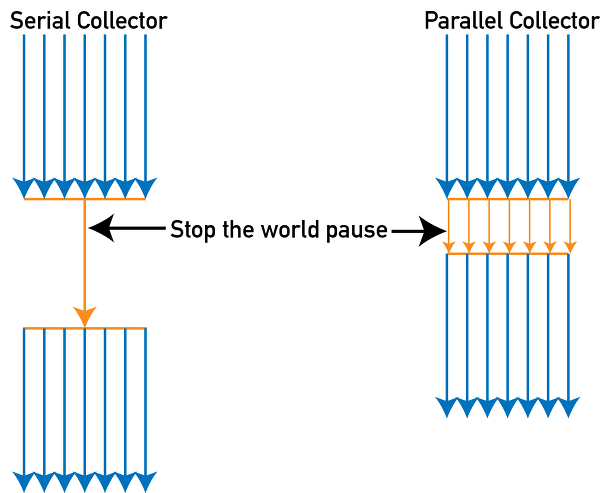
이 방식의 목표는 다른 CPU가 대기 상태로 남아 있는 것을 최소화하는 것이다.
Serial GC와 달리 Young 영역에서의 콜렉션을 병렬(Parallel)로 처리합니다. 많은 CPU 를 사용하기 때문에 GC의 부하를 줄이고 애플리케이션의 처리량을 증가시킬 수 있다.
Mark-Sweep-Compact 알고리즘을 사용한다.
Parallel Compacting GC
Parallel GC와 비교하여 Old 영역에 mark-summary-compact 알고리즘을 사용한다.
mark-summary-compact 알고리즘은 다음과 같다.
- Old 영역으로 이동된 객체들 중 살아있는 객체를 식별한다.(Mark)
- 전에 GC를 수행하여 Compaction 된 영역에 살아 있는 격체의 위치를 조사한다.(Summary)
- Compaction 수행 이후에는 Compaction 영역과 비어있는 영역으로 나눈다.(Compact)
Concurrent Mark-Sweep(CMS) GC
이 방식은 low-latency collector로도 알려져 있으며, 힙 메모리 영역의 크기가 클 때 적합하다.
애플리케이션 스레드와 GC 스레드를 동시에 수행하여 stop-the-world 시간을 최소화하는데 목적이 있다.
Young 영역에 대한 GC는 Parallel GC와 동일히다. Old 영역의 GC는 다음 단계를 거친다.
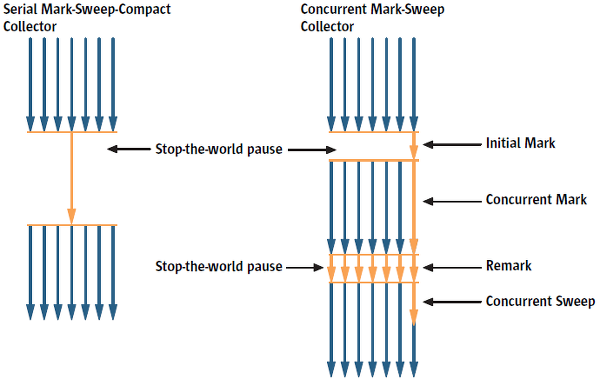
- Initial Mark : 매우 짧은 대기 시간으로 살아 있는 격체를 찾는다 (stop-the-world 발생)
- Concurrent Mark : 방금 살아있다고 확인한 객체에서 참조하고 있는 객체를 따라가면서 확인한다. 다른 스레드가 실행 중인 상태에서 stop-the-world 이벤트 없이 진행된다는 것이 특징이다.
- Remark : Concurrent Mark에서 확인하는 동안 새로 추가되거나 변경된 객체에 대해서 다시 확인한다. (stop-the-world 발생)
- Concurrent Sweep : 확인된 쓰레기를 정리한다. 이 작업도 다른 스레드가 실행 중인 상태에서 stop-the-world 이벤트 없이 진행된다는 것이 특징이다.
G1(Garbage First) GC
Java 7에 정식으로 등장하여 Java 9부터 default가 된 GC 방법이다. (그 전까진 Parallel GC)
G1 GC는 큰 힙 메모리에서 짧은 GC 시간을 보장하는데 그 목적을 둔다.
Eden, Survivor, Old 영역이 존재하지만 고정된 크기로 고정된 위치에 존재하는 것이아니며, 전체 힙 메모리 영역을 Region 이라는 특정한 크기로 나눠서 각 Region의 상태에 따라 그 Region에 역할(Eden, Survivor, Old)이 동적으로 부여되는 상태다.
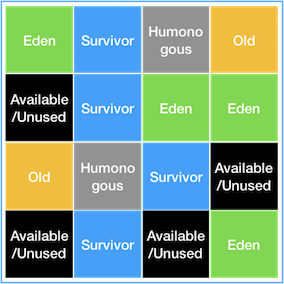
G1 GC에서는 그동안 봐왔던 Heap 영역에서 보지 못한 Humongous, Available/Unused 이 존재하며 두 Region에 대한 역할은 아래와 같다.
- Humongous : Region 크기의 50%를 초과하는 큰 객체를 저장하기 위한 공간이며, 이 Region 에서는 GC 동작이 최적으로 동작하지 않는다.
- Available/Unused : 아직 사용되지 않은 Region을 의미한다.
G1 GC에서 Young GC 를 수행할 때는 STW(Stop-The-World) 현상이 발생하며, STW 시간을 최대한 줄이기 위해 멀티스레드로 GC를 수행한다.
Young GC는 각 Region 중 GC 대상 객체가 가장 많은 Region(Eden 또는 Survivor 역할)에서 수행 되며, 이 Region 에서 살아남은 객체를 다른 Region(Survivor 역할) 으로 옮긴 후, 비워진 Region을 사용가능한 Region으로 돌리는 형태로 동작한다.
G1 GC에서 Full GC 가 수행될 때는 다음과 같은 과정을 겪는다.
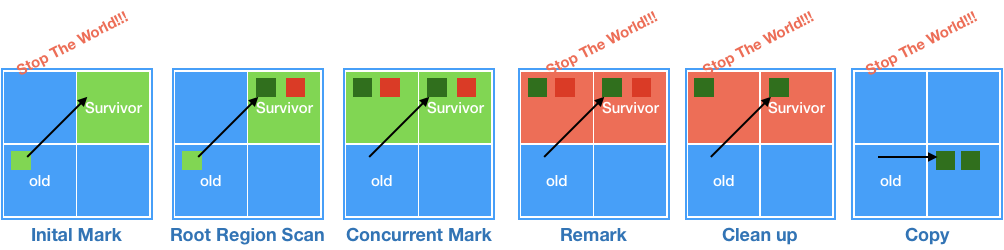
- Initial Mark
Old Region에 존재하는 객체들이 참조하는 Survivor Region 을 찾는다. 이 과정에서는 STW 현상이 발생하게 된다. - Root Region Scan
Initial Mark에서 찾은 Survivor Region에 대한 GC 대상 객체 스캔 작업을 진행한다. - Concurrent Mark
전체 힙의 Region에 대해 스캔 작업을 진행하며, GC 대상 객체가 발견되지 않은 Region은 이후 단계를 처리하는데 제외되도록 한다. - Remark
애플리케이션을 멈추고(STW) 최종적으로 GC 대상에서 제외될 객체(살아남을 객체)를 식별해낸다. - Cleanup
애플리케이션을 멈추고(STW) 살아있는 객체가 가장 적은 Region 에 대한 미사용 객체 제거 수행한다. 이후 STW를 끝내고, 앞선 GC 과정에서 완전히 비워진 Region을 Freelist에 추가하여 재사용될 수 있게 한다. - Copy
GC 대상 Region이었지만 Cleanup 과정에서 완전히 비워지지 않은 Region의 살아남은 객체들을 새로운(Available/Unused) Region 에 복사하여 Compaction 작업을 수행한다.
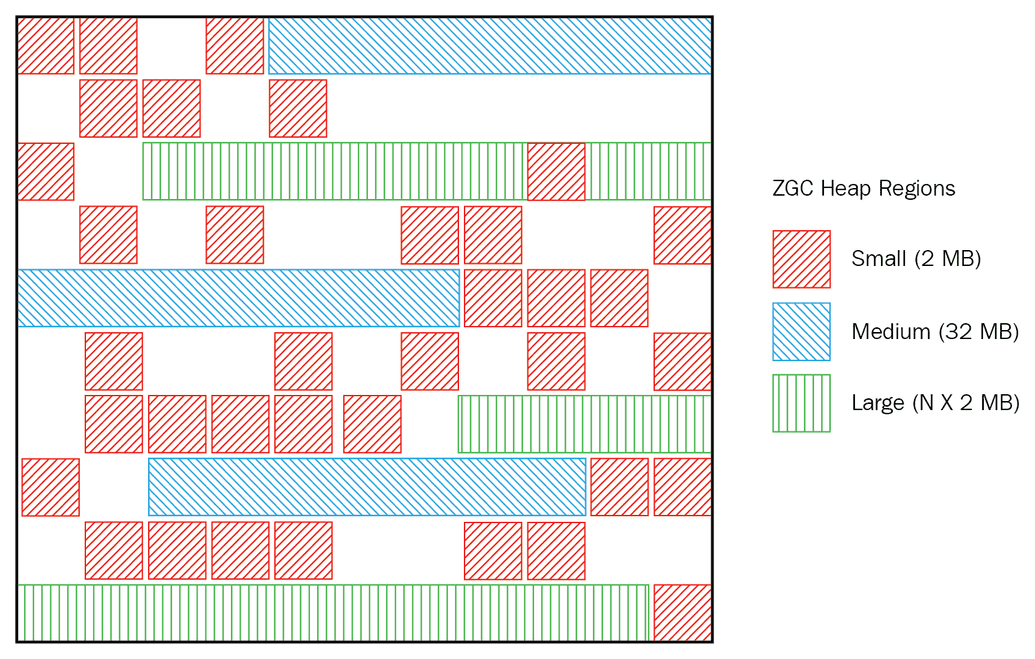
Z Garbage Collectors (ZGC)
JDK11에 early access로 포함되어 15에 Production Ready 상태인 gc 방법이다.
얼만큼의 Heap 공간을 갖고 있어도 STW 시간을 평균적으로 < 10ms 만큼 발생한다고 한다.
ZGC는 처럼 Region 구조를 가져가지만 G1GC와는 다른 메모리 구조를 가져간다.
ZGC에는 속도와 안정성을 위해 Colored pointers와 Load barriers라는 주요한 알고리즘 2가지가 들어가 있다
Colored pointers
Colored pointers는 객체를 가리키는 변수의 포인터에서 64bit라는 메모리를 활용하여 Mark를 진행하여 객체의 상태값을 저장하여 사용하는 방식이다
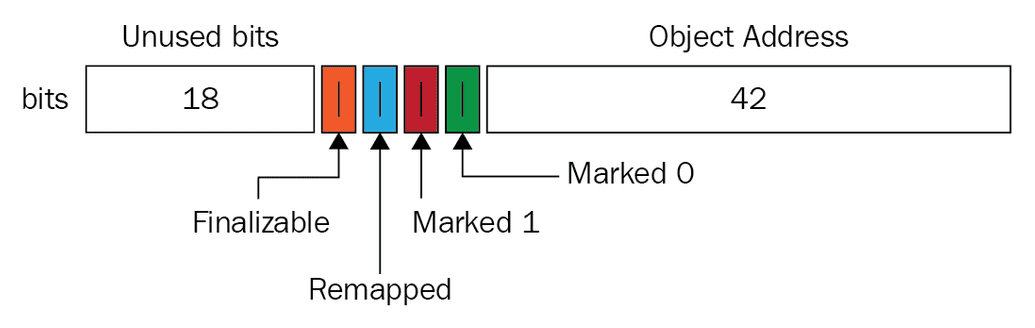
위에 이미지 처럼 42bit는 객체를 가리키는 주소값으로 사용하였고, 나머지 22bit중 4bit를 4가지 Finalizable, Remapped, Marked 1, Marked 0로 나눠서 표시했다.
이 때문에 ZGC는 64bit 운영체제에서만 작동한다.
- Finalizable : finalizer을 통해서만 참조되는 Object로 garbage로 보시면 됩니다
- Remapped : 재배치 여부를 판단하는 Mark
- Marked 1 : Live Object
- Marked 0 : Live Object
Load barriers
Load barriers은 Thread에서 참조 객체를 Load할때 실행되는 코드다
ZGC는 재배치에 대해서 STW없이 동시적으로 재배치를 실행하기 때문에 참조를 수정해야 하는 일이 일어나게 된다
이때 Load barriers가 RemapMark와 RelocationSet을 확인하며 참조와 Mark를 업데이트하고 올바른 참조값으로 인도해준다
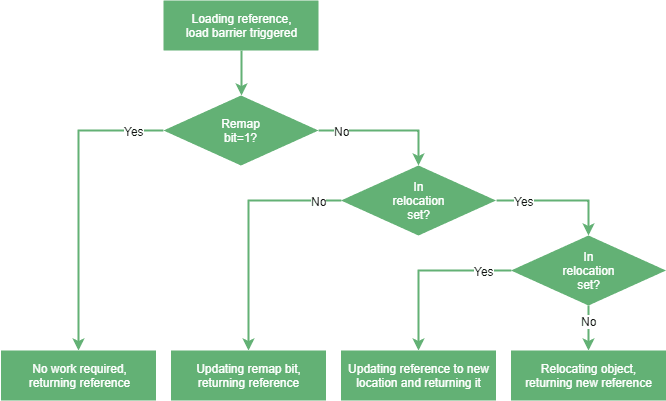
ZGC는 총 3번의 Pause만이 일어난다
- Pause Mark Start : ZGC의 Root에서 가리키는 객체 Mark 표시 (Live Object)
- Concurrent Mark/Remap : 객체의 참조를 탐색하며 모든 객체에 Mark를 표시 한다
- Pause Mark End : 새롭게 들어온 객체들의 대해서 Mark를 표시한다
- Concurrent Pereare for Reloc : 재배치 하려는 영역을 찾아 RelocationSet에 배치한다
- Pause Relocate Start : 모든 루트참조의 재배치를 진행하고 업데이트한다
- Concurrent Relocate : 이후 Load barriers를 사용하여 모든 객체를 재배치 및 참조를 수정한다
Shenandoah GC
Shenandoah GC는 '큰 GC 작업을 적은 횟수로 수행하는 것보다 작은 GC 작업을 여러분 수행하는게 더 좋다'는 개념을 적용해 만들어진 GC 입니다. Shenandoah GC는 작은 단위의 GC 수행을 자주 수행하기 위해 Concurrency를 보장합니다. 즉 말하자면, GC가 CPU를 더 사용하는 대신 pause 시간을 줄이겠다는 의미입니다.
Shenandoah GC는 기존 CMS가 가진 단편화, G1이 가진 pause의 이슈를 해결했습니다. 강력한 Concurrency와 가벼운 GC 로직으로 heap 사이즈에 영향을 받지 않고 일정한 pause 시간이 소요됩니다.
Single-Generational
Shenandoah GC는 G1 GC를 기반으로 만들어졌습니다. heap을 region 별로 나누고 mark-seep & evacuation을 진행합니다. 그러나 Shenandoah GC는 G1 GC와 다르게 Generation으로 영역을 나누지 않습니다. Generation을 나누게 되면 영역을 나누고 evacuation과정에서 메모리 copy가 계속 발생합니다. 그러나 Generation이 나누어지지 않으면 memory copy에 대한 비용이 없어집니다.
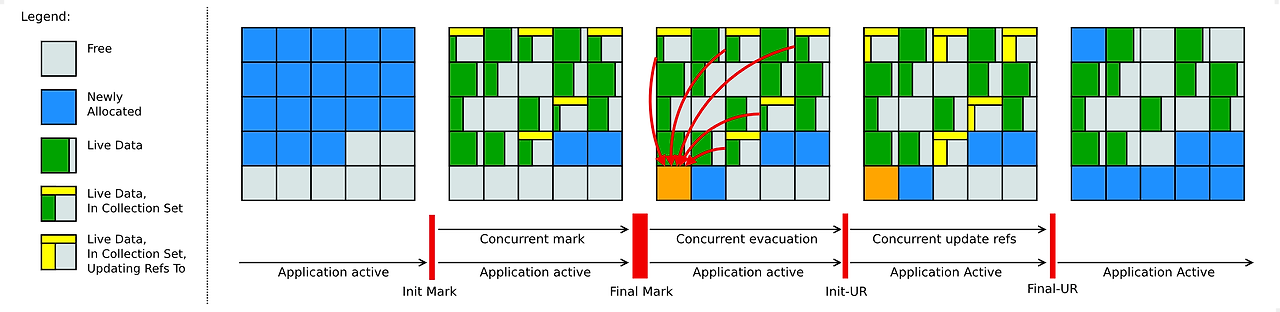
- Initial Marking
- Concurrent Marking
- Final Marking
- Concurrent Compaction
pause후 root set을 스캔하고 Java 스레드와 동시에 marking을 수행합니다. 그 이후 한번 더 pause를 수행하여 final marking을 수행하고 압축 마지막 단계에서 marking된 객체들을 제거합니다. 전체적인 흐름은 CMS GC와 비슷합니다.
