What is SEO?
SEO는 검색 엔진 최적화를 의미합니다. SEO의 목표는 검색 엔진 결과에서 순위를 높이는 전략을 만드는 것입니다. 순위가 높을수록 귀하의 사이트에 더 많은 유기적 트래픽이 발생하여 궁극적으로 더 많은 비즈니스로 이어집니다!
SEO는 브랜드에 대한 전환율과 신뢰도를 높이는 열쇠입니다. 더 높은 검색 순위 배치는 더 많은 유기적 방문자와 동일합니다. 검색 엔진 유기적 트래픽(검색 엔진에서 결과를 클릭하여 귀하의 사이트를 방문하는 방문자)은 세 가지 이유로 많은 비즈니스에서 핵심입니다.
- 질적 – 방문자가 고객으로 전환할 가능성이 높아집니다.
- 신뢰할 수 있음 – 브랜드 또는 미션에 대한 높은 신뢰도.
- 저비용 – 시간과 노력을 제외하고 검색 엔진 순위를 높이는 좋은 SEO 관행을 갖는 것은 무료입니다. 상위 유기적 검색 결과 위치에 표시되는 직접적인 비용은 없습니다.
최적화의 세 가지 요소
웹 사이트 최적화 프로세스는 세 가지 주요 기둥으로 나눌 수 있습니다.
- 기술 – 크롤링 및 웹 성능을 위해 웹사이트를 최적화합니다.
- 만들기 – 특정 키워드를 타겟팅하는 콘텐츠 전략을 만듭니다.
- 인기 – 검색 엔진이 귀하가 신뢰할 수 있는 소스임을 알 수 있도록 온라인에서 사이트의 인지도를 높입니다. 이는 귀하의 사이트로 다시 연결되는 타사 사이트인 백링크를 사용하여 수행됩니다.
검색 시스템
검색 시스템에는 네 가지 주요 책임이 있습니다.
- 크롤링 – 웹을 탐색하고 모든 웹사이트의 콘텐츠를 구문 분석하는 프로세스입니다. 사용 가능한 도메인이 3억 5천만 개가 넘으므로 이는 엄청난 작업입니다.
- 인덱싱 - 액세스할 수 있도록 크롤링 단계에서 수집된 모든 데이터를 저장할 위치를 찾습니다.
- 렌더링 - 사이트의 기능을 향상하고 콘텐츠를 풍부하게 할 수 있는 JavaScript와 같은 페이지의 모든 리소스를 실행합니다. 이 프로세스는 크롤링되는 모든 페이지에 대해 발생하지 않으며 경우에 따라 콘텐츠가 실제로 인덱싱되기 전에 발생합니다. 당시 작업을 수행할 수 있는 리소스가 없는 경우 인덱싱 후에 렌더링이 발생할 수 있습니다.
- 순위 – 데이터를 쿼리하여 사용자 입력을 기반으로 관련 결과 페이지를 만듭니다. 여기에서 검색 엔진에 다양한 순위 기준이 적용되어 사용자의 의도를 충족할 수 있는 최상의 답변을 제공합니다.
웹 크롤러란 무엇입니까?
웹사이트를 검색 결과에 표시하기 위해 Google(Bing, Yandex, Baidu, Naver, Yahoo 또는 DuckDuckGo와 같은 다른 검색 엔진 포함)은 웹 크롤러를 사용하여 웹 사이트를 탐색하여 웹 사이트와 해당 웹 페이지를 검색합니다.
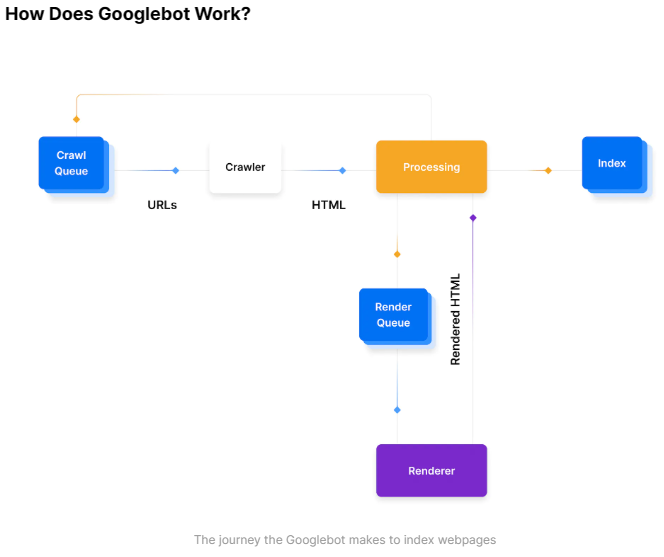
프로세스의 일반적인 개요는 다음과 같습니다.
- URL 찾기: Google은 Google Search Console, 웹사이트 간 링크 또는 XML 사이트맵을 비롯한 여러 위치의 URL을 가져옵니다.
- 크롤링 대기열에 추가: 이 URL은 Googlebot이 처리할 크롤링 대기열에 추가됩니다. 크롤링 대기열의 URL은 일반적으로 몇 초 동안 지속되지만 경우에 따라 특히 페이지를 렌더링, 색인화해야 하거나 URL이 이미 색인화되어 있는 경우 새로고침해야 하는 경우 최대 며칠이 걸릴 수 있습니다. 그러면 페이지가 렌더링 대기열에 들어갑니다.
- HTTP 요청: 크롤러는 헤더를 가져오기 위해 HTTP 요청을 만들고 반환된 상태 코드에 따라 작동합니다.
- 200 - HTML을 크롤링하고 구문 분석합니다.
- 30X - 리디렉션을 따릅니다.
- 40X - 오류를 기록하고 HTML을 로드하지 않음
- 50X - 상태 코드가 변경되었는지 확인하기 위해 나중에 돌아올 수 있습니다.
- 렌더링 대기열: 검색 시스템의 다양한 서비스 및 구성 요소가 HTML을 처리하고 콘텐츠를 구문 분석합니다. 페이지에 일부 JavaScript 클라이언트 기반 콘텐츠가 있는 경우 URL이 렌더링 대기열에 추가될 수 있습니다. 렌더링 대기열은 JavaScript를 렌더링하는 데 더 많은 리소스를 사용해야 하기 때문에 Google에 더 많은 비용이 들기 때문에 렌더링된 URL은 인터넷의 전체 페이지에서 차지하는 비율이 더 적습니다. 일부 다른 검색 엔진은 Google과 동일한 렌더링 용량을 가지고 있지 않을 수 있으며 여기에서 Next.js가 렌더링 전략에 도움을 줄 수 있습니다.
- 색인 생성 준비 완료: 모든 기준이 충족되면 페이지가 색인화되고 검색 결과에 표시될 수 있습니다.
What is a robots.txt File?
로봇 파일은 검색 엔진 크롤러가 귀하의 사이트에서 어떤 페이지나 파일을 요청할 수 있는지 또는 요청할 수 없는지 알려주는 파일입니다. 로봇 파일은 대부분의 좋은 봇이 특정 도메인에서 어떤 것을 요청하기 전에 소비하는 웹 표준 파일입니다.
CMS나 관리자, 전자상거래의 사용자 계정 또는 일부 API 경로 등과 같이 귀하의 웹사이트의 특정 영역을 크롤링되지 않도록 보호하고 싶을 수 있습니다.
이러한 파일은 각 호스트의 루트에 제공되어야 하며, 대안으로 루트 /robots.txt 경로를 대상 URL로 리디렉션하면 대부분의 봇이 따를 것입니다.
Next.js 프로젝트에 robots.txt 파일을 추가하는 방법
Next.js의 정적 파일 제공 덕분에 우리는 쉽게 robots.txt 파일을 추가할 수 있습니다. 우리는 루트 디렉토리의 public 폴더에 robots.txt라는 새로운 파일을 생성합니다.
이 파일에 넣을 수 있는 항목의 예는 다음과 같습니다.
# Block all crawlers for /accounts
User-agent: *
Disallow: /accounts
# Allow all crawlers
User-agent: *
Allow: /yarn dev로 앱을 실행하면 이제 http://localhost:3000/robots.txt에서 사용할 수 있습니다. public 폴더 이름은 URL의 일부가 아닙니다.
XML Sitemaps
사이트맵은 Google과 소통하는 가장 쉬운 방법입니다. 귀하의 웹사이트에 속한 URL을 지정하고 업데이트 시기를 알려주어 Google이 새로운 콘텐츠를 쉽게 감지하고 귀하의 웹사이트를 더 효율적으로 크롤링할 수 있도록 합니다.
You might need a sitemap if:
-
사이트맵은 귀하의 사이트의 페이지, 비디오 및 기타 파일에 대한 정보와 그들 사이의 관계에 대한 정보를 제공하는 파일입니다. Google과 같은 검색 엔진은 이 파일을 읽어 귀하의 사이트를 더 지능적으로 크롤링합니다.
-
귀하의 사이트가 정말 큽니다. 따라서 Google 웹 크롤러가 귀하의 새로운 또는 최근에 업데이트된 페이지 중 일부를 크롤링하지 못할 가능성이 높습니다.
-
귀하의 사이트에는 서로 참조되지 않거나 잘 연결되지 않은 컨텐츠 페이지의 대형 아카이브가 있습니다. 귀하의 사이트 페이지가 자연스럽게 서로 참조하지 않으면 사이트맵에 나열하여 Google이 귀하의 일부 페이지를 놓치지 않도록 할 수 있습니다.
-
귀하의 사이트가 새로운 것이며 외부 링크가 거의 없습니다. Googlebot과 다른 웹 크롤러는 한 페이지에서 다른 페이지로 링크를 따라 웹을 탐색합니다. 따라서 다른 사이트가 링크하지 않으면 Google은 귀하의 페이지를 찾지 못할 수 있습니다.
-
귀하의 사이트에는 많은 리치 미디어 콘텐츠(비디오, 이미지)가 있거나 Google News에 표시됩니다. 제공된 경우 Google은 검색에 적합한 경우 사이트맵에서 추가 정보를 고려할 수 있습니다.
사이트맵은 검색 엔진 성능에 필수적인 것은 아니지만 크롤링과 인덱싱을 용이하게 하여 귀하의 콘텐츠가 더 빨리 선택되고 순위가 매겨질 수 있도록 합니다.
사이트맵을 사용하는 것을 강력히 추천합니다. 귀하의 웹사이트 전체에 새로운 콘텐츠가 추가됨에 따라 동적으로 만들어야 합니다. 정적 사이트맵도 유효하지만 Google에게는 상수 발견 목적으로 유용하지 않을 수 있습니다.
How to Add Sitemaps to a Next.js Project
- 수동
비교적 단순하고 정적인 사이트가 있는 경우 프로젝트의 공용 디렉터리에 sitemap.xml을 수동으로 만들 수 있습니다.
<!-- public/sitemap.xml -->
<xml version="1.0" encoding="UTF-8">
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://www.example.com/foo</loc>
<lastmod>2021-06-01</lastmod>
</url>
</urlset>
</xml>- getServerSideProps
귀하의 사이트가 동적일 가능성이 높습니다. 이 경우 getServerSideProps를 활용하여 XML 사이트맵을 요청시 생성할 수 있습니다.
pages/sitemap.xml.js와 같은 페이지 디렉토리 내에 새 페이지를 만들 수 있습니다. 이 페이지의 목표는 API를 사용하여 동적 페이지의 URL을 알 수 있는 데이터를 얻는 것입니다. 그런 다음 /sitemap.xml에 대한 응답으로 XML 파일을 작성합니다.
//pages/sitemap.xml.js
const EXTERNAL_DATA_URL = 'https://jsonplaceholder.typicode.com/posts';
function generateSiteMap(posts) {
return `<?xml version="1.0" encoding="UTF-8"?>
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<!--We manually set the two URLs we know already-->
<url>
<loc>https://jsonplaceholder.typicode.com</loc>
</url>
<url>
<loc>https://jsonplaceholder.typicode.com/guide</loc>
</url>
${posts
.map(({ id }) => {
return `
<url>
<loc>${`${EXTERNAL_DATA_URL}/${id}`}</loc>
</url>
`;
})
.join('')}
</urlset>
`;
}
function SiteMap() {
// getServerSideProps will do the heavy lifting
}
export async function getServerSideProps({ res }) {
// We make an API call to gather the URLs for our site
const request = await fetch(EXTERNAL_DATA_URL);
const posts = await request.json();
// We generate the XML sitemap with the posts data
const sitemap = generateSiteMap(posts);
res.setHeader('Content-Type', 'text/xml');
// we send the XML to the browser
res.write(sitemap);
res.end();
return {
props: {},
};
}
export default SiteMap;검색 엔진을 위한 특수 메타 태그
메타 로봇 태그는 검색 엔진이 항상 존중할 지시어입니다. 이러한 로봇 태그를 추가하면 귀하의 웹사이트의 색인 작성이 더 쉬워집니다.
지시어와 제안 사이에는 차이가 있습니다. 메타 로봇 태그 또는 robots.txt 파일은 지시어이며 항상 준수됩니다. 정규 태그는 Google이 준수 여부를 결정할 수 있는 권장 사항입니다.
페이지 수준 메타 태그에는 많은 옵션이 있지만 다음은 SEO와 관련된 일반적인 예제입니다:
<meta name="robots" content="noindex,nofollow" />로봇 태그는 아마도 가장 일반적인 태그일 것입니다. 기본적으로 index,follow 값을 가지므로 지정할 필요가 없으며 all도 유효한 대체 버전입니다:
<meta name="robots" content="all" />로봇 태그를 위의 예제와 같이 noindex,nofollow로 설정하면 검색 엔진에 다음을 나타냅니다:
- noindex
검색 결과에 이 페이지를 표시하지 마십시오. noindex를 생략하면 페이지가 색인될 수 있고 검색 결과에 표시될 수 있음을 나타냅니다.
웹 사이트를 구축할 때 특정 페이지를 인덱싱하지 않을 수 있습니다. 일반적인 사용 사례에는 설정 페이지, 내부 검색 페이지, 정책 등이 포함됩니다. - nofollow
이 페이지의 링크를 따르지 마십시오. 이를 생략하면 로봇이 이 페이지의 크롤링 및 링크 따르기가 가능합니다. 다른 페이지에서 발견된 링크는 크롤링을 가능하게 할 수 있으므로 링크 A가 페이지 X와 Y에 나타나고 X에 nofollow 로봇 태그가 있지만 Y에는 없으면 Google은 링크를 크롤링하기로 결정할 수 있습니다.
Example
import Head from 'next/head';
function IndexPage() {
return (
<div>
<Head>
<title>Meta Tag Example</title>
<meta name="google" content="nositelinkssearchbox" key="sitelinks" />
<meta name="google" content="notranslate" key="notranslate" />
</Head>
<p>Here we show some meta tags off!</p>
</div>
);
}
export default IndexPage;예제에서 볼 수 있듯이 페이지 헤드에 요소를 추가하기 위한 내장 구성 요소인 next/head를 사용하고 있습니다.
head에 태그가 중복되는 것을 방지하려면 태그가 한 번만 렌더링되도록 하는 key 속성을 사용할 수 있습니다.
정식 태그란 무엇입니까?
표준 URL은 사이트의 중복 페이지 집합에서 검색 엔진이 가장 대표적이라고 생각하는 페이지의 URL입니다.
표준 URL을 검색 엔진에 직접 전달할 수 있지만 검색 엔진은 사용자에게 알리지 않고 여러 URL을 그룹화하도록 결정할 수도 있습니다. Google이 여러 경로에서 URL을 찾을 수 있는 경우 자동으로 발생할 수 있습니다.
Google은 이를 감지하는 데 큰 역할을 하지만 시스템은 대규모로 작동하며 모든 극단적인 경우를 다루지는 않습니다. 표준 태그는 웹사이트에서 우수한 성능을 보장하기 위해 다루어야 할 중요한 측면입니다.
전자 상거래 상점에서 example.com/products/phone 및 example.com/phone을 통해 제품에 액세스할 수 있다고 상상해 봅시다.
둘 다 유효하고 작동하는 URL이지만 우리는 우리가 소유한 중복 콘텐츠의 감지를 방지하기 위해 표준을 사용합니다. 순위에 https://example.com/products/phone이 고려되어야 한다고 결정한 경우 표준 태그를 생성합니다.
<link rel="canonical" href="https://example.com/products/phone" />표준 태그는 다른 URL을 만들 수 있을 뿐만 아니라 사용자 또는 마케팅 도구도 만들 수 있기 때문에 SEO 성능의 기본입니다.
캐노니컬의 주요 목적은 무엇입니까? -> 페이지 중복을 제거
Example
import Head from 'next/head';
function IndexPage() {
return (
<div>
<Head>
<title>Canonical Tag Example</title>
<link
rel="canonical"
href="https://example.com/blog/original-post"
key="canonical"
/>
</Head>
<p>This post exists on two URLs.</p>
</div>
);
}
export default IndexPage;
잘봤습니다 :)