
📚 학습정리
JAVA
Lambda
@FunctionalInterface
자바 8에서 도입된 어노테이션
- 해당 인터페이스가 함수형 인터페이스임을 명시적으로 지정하는 데 사용
- 함수형 인터페이스: 단 하나의 추상 메서드를 가지는 인터페이스로
- 람다 표현식과 메서드 참조를 사용하여 구현
- 기본 메서드와 정적 메서드를 포함 가능
- 람다 표현식과 메서드 참조를 사용하여 함수형 인터페이스를 간편하게 구현
- 컴파일러가 인터페이스가 함수형 인터페이스 규칙을 준수하는지 확인하여 오류를 방지
@FunctionalInterface
interface Message{
public void info();
}Message d = new Message(){
public void info(){
System.out.println("non-lambda");
}
}
Message d2 = () -> System.out.println("lambda");
d.info();
d2.info();메서드 오버라이딩
부모 클래스로부터 상속받은 메서드
필요성
- 데이터를 표현하는 클래스의 경우 개발자가 재정의
권장
모든 멤버 변수 값을 하나의 문자열로 결합해서 반환
주의사항
String 타입은 값을 수정할 때 마다 새로운 객체 생성 → 메모리 사용
문자열 조합 시에는 String보다 StringBuilder/StringBuffer 사용하는 것이 메모리 관리 차원에서 더 이득이다.
- 메모리에 갱신이 가능한 타입인 StringBuilder/StringBuffer 사용 후 String으로 변환해서 사용하기
- IDE에서
Generate toString()…사용하기
- IDE에서
@Override
public String toString() {
StringBuilder builder = new StringBuilder();
builder.append("Customer [id=");
builder.append(id);
builder.append(", pw=");
builder.append(pw);
builder.append("]");
return builder.toString();
}인터페이스
구성
- 상수
- 미완성 메서드
- 주석
주 용도
상속받는 하위 클래스 개발 → 미완성 메서드 재정의를 필수로 제시
- 모든 개발자들의 코드 표준화
- 벤더사는 상이하나 하나의 웹소스가 웹서버에서 동일한 구조로 실행
특징
미완성 메서드를 하나라도 가지고 있으면 객체 생성이 불가능하다.
- 해결 방법: 미완성 메서드를 재정의하는 하위 클래스 개발 및 객체 생성
익명 클래스
package test;
interface Calc {
public int calc(int a, int b);
}
class CalcSub implements Calc {
@Override
public int calc(int a, int b) {
return a + b;
}
}
public class LevelUp3 {
public static void main(String[] args) {
// Calc c = new Calc(); // 미완성 메서드 보유 인터페이스는 객체 생성 불가.
Calc cs = new CalcSub(); // 다형성 형식으로 객체 생성
Calc c2 = new Calc() {
@Override
public int calc(int a, int b) {
return a + b;
}
};
}
}
익명클래스를 생성하고 파일이 저장되는 경로를 확인해보면 클래스명$1 이라는 바이트 코드가 생성된다.
람다식 활용
Calc2 cc1 = (v1, v2) -> v1 + v2;- (v1,v2) - 값을 받고자 하는 선언
- 받은 데이터를 옮기겠다는 선언
- v1 + v2: 두 개의 변수가 보여준 데이터값을 더해 반환.
- 더한 값이 cc1 참조 변수로 활용 가능
Stream API
Java 8에서 도입된 기능, 컬렉션 데이터를 쉽게 조작하고 변환할 수 있는 도구
함수형 프로그래밍 스타일: 간결하고 가독성 높인 문법
forEach: 스트림의 각 요소에 대해 지정된 작업을 수행filter: 스트림의 각 요소에 대해 주어진 조건(predicate)을 만족하는 요소만으로 구성된 새로운 스트림을 반환map: 스트림의 각 요소에 대해 주어진 함수를 적용한 결과로 구성된 새로운 스트림을 반환mapToInt: int를 처리하는 스트림 IntStream을 반환하는 map 함수
::연산자 : 메서드 및 생성자 참조
List 응용
ArrayList<Customer> all = new ArrayList<>();
all.add(new Customer("id1", "pw1", 10, "add", "grade", "gender"));
all.add(new Customer("id2", "pw2", 15, "add", "grade", "gender"));
all.add(new Customer("id3", "pw3", 30, "add", "grade", "gender"));
int sum = all.stream()
.filter(a -> a.getAge() < 20)
.mapToInt(a -> a.getAge())
.sum();
int sum2 = all.stream()
.filter(a -> a.getAge() < 20)
.mapToInt(Customer::getAge)
.sum());
Optional
- Optional.ofNullable() - null과 객체 모두 수용
- Null 필터링은
ifPresent()메서드 활용도 가능.
- Null 필터링은
Optional<HashMap<String, Person>> opMap = Optional.ofNullable(map);
opMap.ifPresent(map2 -> {
System.out.println(
map2.values().stream()
.filter(c -> c.getAge() < 20)
.mapToInt(Customer::getAge)
.sum());
});
get()- 실제 Optional 객체에 저장된 데이터 값을 반환하는 메서드- Optional이 empty인 경우 NoSuchElementException 발생.
ifPresent()- Optional 객체 내부에 null이면 실행 skip
- null이 아닌 경우 실행
- ifPresent의 파라미터로는 Consumer가 들어간다. null이 아닐 경우 실행할 코드.
- Consumer:
T -> ()
T를 받고 반환값 없음(void)
- Consumer:
Optional.of()- null 불가 (NoSuchElementException)→ ifPresent() 필요하지 않음orElse(): null일 경우 다른 값을 넣음orElseThrow(): null일 경우 지정한 Exception 발생
SpringToolSuite 실행 불가 문제 (Mac)
위 Optional에 대한 학습정리를 작성하기 위해 기존에 설치했던 STS를 실행했더니
SpringToolSuite4.app 응용프로그램을 열 수 없습니다. 라는 문제가 발생하였다.
Mac 운영체제 자체의 인증 문제라고 한다.
해결 방법
$ codesign --force --deep --sign - /Applications/SpringToolSuite4.app위 코드를 터미널에 입력한다.
ELK Stack
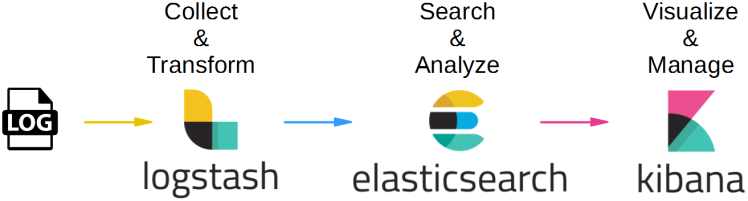
출처 : https://www.geeksforgeeks.org/what-is-elastic-stack-and-elasticsearch/
로그 데이터의 수집, 처리, 저장, 시각화를 위한 통합 솔루션.
- 실행: 각 설치 파일의
/bin디렉토리 하위의elasticsearch,kibana,logstash,filebeat파일을 실행한다.
ElasticSearch
분산형 검색 및 분석 엔진, 대용량 데이터의 실시간 검색, 분석, 저장
- 데이터 저장, 검색, 집계
- RESTful API 제공
- Postman과의 연계
- 9200 포트 사용
RDBMS와 비교
- RDBMS가 견고하고 연속성 있게 데이터를 저장 가능.
- Elasticsearch가 더 신속하고 빠르게 데이터 확인.
| 특성 | Elasticsearch | RDBMS |
|---|---|---|
| 데이터 모델 | 문서 지향 (JSON 문서) | 관계형 (테이블, 행, 열) |
| 쿼리 언어 | DSL (JSON 형식) | SQL (표준 쿼리 언어) |
| 성능 및 확장성 | 분산 아키텍처, 실시간 검색, 수평 확장 | 단일 노드, ACID 트랜잭션, 수직 확장 |
| 사용 사례 | 로그 분석, 전체 텍스트 검색, APM | 트랜잭션 기반 애플리케이션, 정형 데이터 관리, 복잡한 조인 |
| 일관성 모델 | 최종 일관성 | 즉각적 일관성, ACID 트랜잭션 |
| 적합한 환경 | 실시간 검색 및 분석이 필요한 경우에 적합 | 데이터 일관성과 무결성이 중요한 트랜잭션 기반 애플리케이션에 적합 |
Elasticsearch 다루기
Multi Elasticsearch Head 크롬 확장 프로그램을 통해 현재 저장된 인덱스를 확인 가능하다.
Kibana
데이터 시각화 및 탐색 가능한 웹 인터페이스 제공
- 데이터 시각화, 대시보드 생성, 탐색
- 웹 브라우저로 키바나에 접속 → Elasticsearch에 쿼리를 보내고 시각화
localhost:5601접속하기
- 데이터 분석 및 실시간 모니터링 가능.
Index Pattern
Elasticsearch에 있는 데이터를 키바나와 연동하려면?
-> Kibana의 Index Pattern 사용하기
- 데이터 추가
- 원하는 데이터 등록 (이름뒤에
*(Asterisk)붙이기) - 시계열 데이터 등록
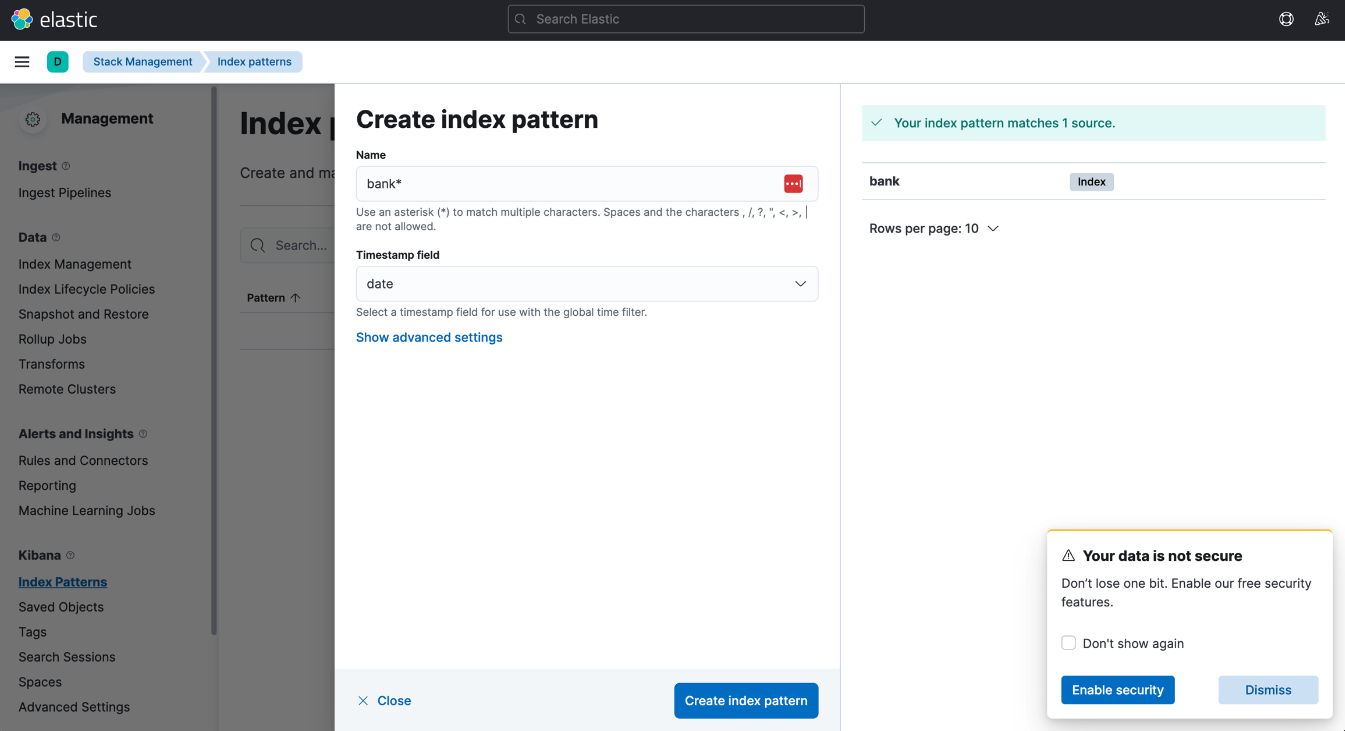
CSV 파일로 데이터 추가
Kibana 통해서 Elasticsearch에 데이터를 추가할 수 있다.
파일 용량 늘리기
- Kibana의 settings
→ setting management
→ advanced setting
→ Machine learning에서
File Data Visualizer maximum file upload size 1GB로 증가
CSV 파일 업로드
- 왼쪽 탭 Machine Learning → Data Visualizer → 파일 업로드하기
- 이름에 대문자랑
*안됨. - 이후 파이프라인 형태로 데이터 입력.
- 이름에 대문자랑
이후 키바나 Index Patterns나 ES 확장 프로그램에서 확인.
- 왼쪽 탭 Discover에서 기간 별로 데이터 확인 가능.
Visualize
키바나 왼쪽 탭 → Analytics → Visualize → Lens
참고: 새로운 버전에서는 Visualize Library 인 것으로 추정(공부에 사용한 버전은 7.11.1)
왼쪽 필드 -> 오른쪽 가로축에 드래그하고 세로축을 클릭하면 다양한 데이터가 나온다.
- 각 축에 이름 부여 가능
- 범례 추가 가능
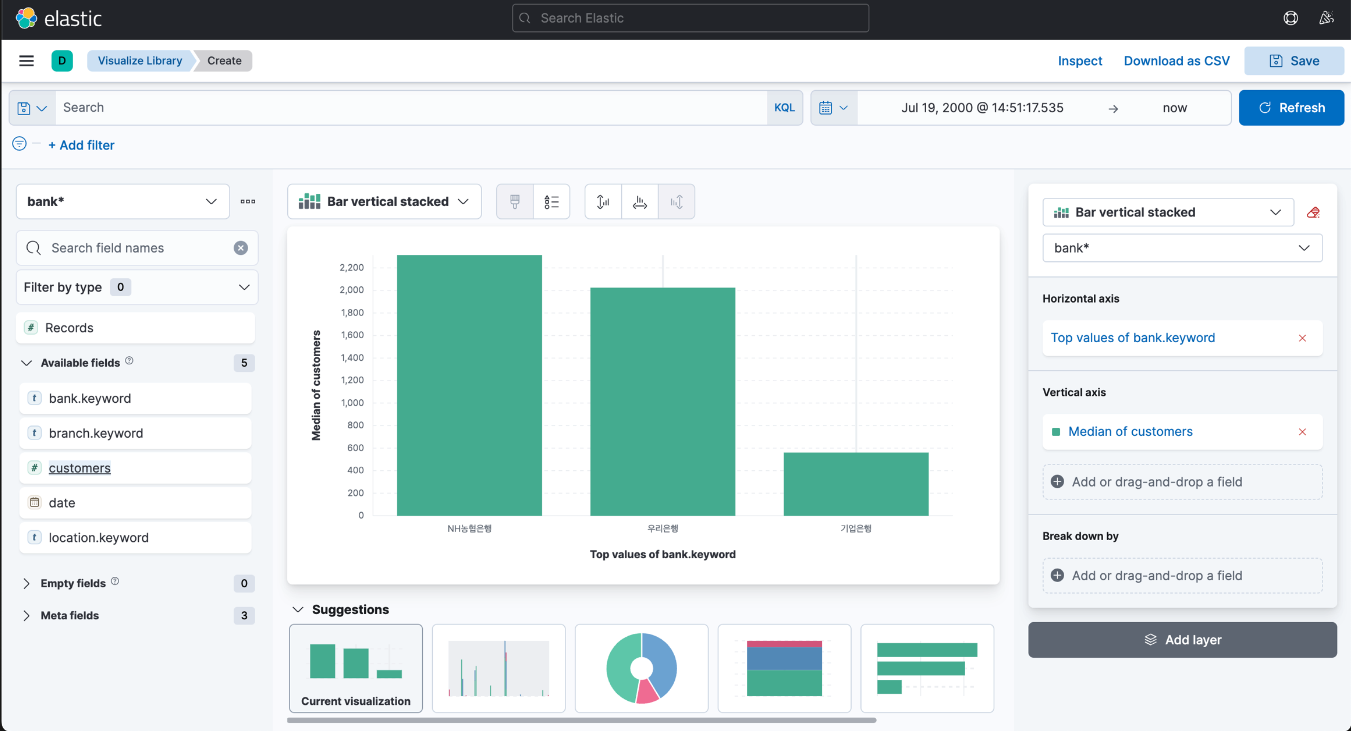
오른쪽 하단의 Add layer를 클릭하여 정보를 중첩해서 시각화하는 것도 가능하다.
Elasticsearch 쿼리
왼쪽 탭 → Management → Dev Tools
json 형식으로 Dev tools 화면에서 쿼리를 통해 데이터를 CRUD 하는 것이 가능하다.
집계 쿼리 예시
GET bank/_search
{
"size": 0, # size가 0이 아닐 시 데이터가 출력됨.
"aggs": {
"all_customers": {
"sum": { # 총 합계
"field": "customers"
}
}
}
}GET empall/_search
{
"size": 0,
"aggs": {
"emp_count": {
"value_count": { # 항목의 개수를 세기
"field": "EMPNO"
}
}
}
}검색 쿼리 예시
# 강남에 있는 모든 은행들 검색하기
# select * from bank where location='강남';
GET bank/_search
{
"query": {
"match": {
"location": "강남"
}
}
}텍스트 데이터 조회
match VS. match_phrase
GET my_index/_search
{
"query": {
"match": {
"message": "pink blue"
}
}
}match: 텍스트 필드의 각 단어를 개별적으로 검색, 단어의 위치와 순서를 고려하지 않음- 예제에서는 message 필드에 pink 또는 blue가 포함된 문서를 검색
GET my_index/_search
{
"query": {
"match_phrase": {
"message": "pink blue"
}
}match_phrase: 텍스트 필드에서 정확한 구문 검색- 지정된 단어들이 동일한 순서로 연속적으로 존재하는 문서만 매칭한다.
- 예제에서는 pink 다음에 바로 blue가 나오는 문서만 매칭
slop
두 단어 사이에 허용되는 최대 단어 수를 지정.
GET my_index/_search
{
"query": {
"match_phrase": {
"message": {
"query" : "pink blue",
"slop": 2
}
}
}
}pink와 blue 사이에 최대 2개의 다른 단어가 존재해도 매칭이 된다.
Logstash
데이터 수집, 변환, 저장하는 파이프라인 도구
- Filebeat으로부터 데이터 수집
- Filter를 이용하여 전처리 및 변환
- Elasticsearch 같은 출력 대상으로 보내기
작동과정
.conf 파일에 input, output, filter를 수정하여 원하는대로 데이터를 가공 가능하다.
.conf 파일
데이터를 수집, 변환 및 전달하는 과정을 정의한다.
입력, 필터, 출력 세 부분으로 나뉜다.
# .conf 파일 위치 (ubuntu)
/etc/logstash/conf.d/config파일이름.conf
# 일반적으로 설치한 경우 (mac)
/logstash-7.11.1/config/config파일이름.confinput {
# 데이터 입력 설정
# Filebeat로부터 입력 받기
beats {
port => 5044
}
}
filter {
# 데이터 변환 설정
# 날짜 필드를 변환
date {
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
target => "@timestamp"
}
# mutate 필터로 데이터 변환
mutate {
rename => { "host" => "source_host" }
convert => { "response_time" => "integer"
split => [ "message", "," ]
add_field => {
"date" => "%{[message][0]}"
"bank" => "%{[message][1]}"
"branch" => "%{[message][2]}"
"location" => "%{[message][3]}"
"customers" => "%{[message][4]}"
}
}
}
output {
# 데이터 출력 설정
# 디버깅을 위해 콘솔창에 어떤 데이터들로 필터링 되었는지 확인.
stdout {
codec => rubydebug
}
# ElasticSearch으로 bank이라는 이름으로 인덱싱
elasticsearch {
hosts => ["localhost:9200"]
index => "bank"
}
}Filebeat
경량 데이터 수집기
로그 파일이나 csv 파일 등에서 데이터를 수집하여 Logstash 또는 Elasticsearch로 전송한다.
- 둘 다 가능한 이유: filebeat.yml 설정 파일에서 둘 중 하나를 선택 가능하다.
기본 동작
- 로그 파일 모니터링:
filebeat.yml에서 지정한 경로에서 로그 파일을 모니터링한다. - 로그 데이터 읽기: 새로 생성된 로그 항목을 읽어들인다.
- 데이터 전송: 읽어들인 로그 데이터를 출력 대상으로 전송한다.
- 레지스트리 파일 관리: 각 파일의 읽은 위치를 레시트릐 파일에 저장, Filebeat가 재시작되어도 이전에 읽은 위치부터 계속 읽을 수 있도록 한다.
filebeat.yml
filebeat의 동작을 설정하는 파일
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
# 경로를 csv 파일로도 설정 가능하다.
output.elasticsearch:
hosts: ["localhost:9200"]
# elasticsearch, logstash 등으로 출력 가능🔨 Troubleshooting
csv파일에서 데이터를 읽어오도록 yml 파일에 설정하고, csv 파일을 수정하여 저장했을 때 elasticsearch에 데이터가 추가되는 것을 의도했으나 동작하지 않았다.
문제를 해결하기 위해 새 파일을 생성 -> 기존 파일 내용을 그대로 복사 -> filebeat.yml 파일에서 input 경로 수정 의 과정을 거쳤더니 정상적으로 동작했다.
Filebeat의 파일 상태 관리
Filebeat는 각 파일의 읽은 상태를 추적하기 위해 레지스트리 파일을 사용한다. 이 레지스트리 파일은 기본적으로 Filebeat가 모니터링하는 파일의 위치, 파일 오프셋, inode 정보를 저장한다.
- 파일 오프셋: 파일의 현재 읽은 위치를 추적하는데 사용되는 단위. 파일이 업데이트 되었을 때 어디서부터 읽어야할 지 결정한다.
- inode: 유닉스 파일 시스템에서 파일의 고유한 식별자. 파일이 변경되어도 inode 정보가 동일하다면 Filebeat는 이를 동일한 파일로 인식.
파일 변경 인식 과정
파일이 변경될 떄, Filebeat는 새로운 데이터를 다음과 같은 방법으로 인식한다:
- 파일의 변경 감지
- 새 데이터 읽기
- 오프셋 업데이트
이 때 파일의 이름이 변경되거나 다른 디렉터리로 이동한 경우, 경로 설정이 잘못되었을 경우 파일의 변경 사항을 인식하지 못할 수 있다.
Ubuntu에 ELK Stack 설치하기
설치 방법을 노션 사이트에 작성하였습니다. 추후 블로그로 이전 예정 (언젠가는..?)
🤔 회고
🎉 학습일지 챌린지 우수작성자 선정
지난 주 학습정리 글이 학습일지 챌린지 우수 작성자에 선정되었다!!! 별거 없다고 생각했는데 선정되서 너무 기쁘다.

상품으로 받은 스타벅스 기프트카드 5000원. 감사히 잘 쓰겠습니다.
가장 기분이 좋았던 말은 "너무 꼼꼼하게 작성된 글이라서 당연히 여성 분이 작성한 것일 줄 알았는데 아니었다"는 말이었다.
감사합니다🤣😂
💨 순식간에 지나간 2주차
사실 지난 1주차는 대학교 4년동안 열심히 공부한 게 있었던 덕분에 거의 다 아는 내용이었다.
그래서인지 사실 시간이 느리게 가서 힘든 느낌이 있었다. (살짝 훈련소 1주차 느낌)
하지만 이번주에 배운 ELK Stack은 완전히 처음 접하는 내용이었고, 환경 설정이나 관련 기능을 배우다 보니 정신없이 시간이 빨리 지나갔다. 수업 내용을 집중해서 듣지 않으면 내용을 다 놓치기 때문에 집중해서 들어야 했다.
하지만 피곤해서 가끔 졸 때도 있었다는게 문제.
가장 흥미로운 경험은 실제 금융 데이터를 받아 Kibana로 시각화하는 실습이었다.
보안 서약서까지 써가면서 실습을 진행했기 때문에 자세히 설명은 못하지만, 실습하는 내용이 많이 알찼다고 생각한다.
시각화한 내용을 가지고 발표하는 시간에는 같이 수업을 듣는 분들의 아이디어와 인사이트가 엄청 대단하다는 것을 느낄 수 있었다.
나에겐 데이터를 다루고 의미 있는 결과를 도출하는 능력이 많이 떨어진다는 것을 느끼기도 했다..
📝 공들여서 기록하기
금요일에는 로컬에서 ELK Stack 설치를 했던 경험을 바탕으로 가상 환경에 설치한 Ubuntu에 그대로 ELK Stack을 설치하는 과제가 주어졌다.
과제 관련해서는 실력차가 좀 있었던 것 같다.
어느 조에 계신 분들은 오전에 끝냈다는 이야기도 들었던 것 같고, Docker에 설치하는 분들도 있었다.
나는 프로젝트나 학교 수업에서 환경 설정으로 많이 머리를 부여잡고 고통받았던 경험 덕분이었을까.
막히는 부분이 있긴 했지만 생각보다 어렵지 않게 환경 설정을 완료했다.
남은 시간에는 내용을 노션에 정리했다.
같은 조에 있는 팀원을 도와주기도 했지만 내 능력으로는 해결할 수 없는 문제가 있기도 했고,
내가 했던 내용을 바로 정리하지 않는다면 전부 날아갈 것 같은 느낌이 들어 기록에 더 많은 시간을 투자했다.
이후 어떤 방식으로 실습을 진행했는지 발표하는 시간에 작성한 노션 내용을 가지고 발표했다.
매뉴얼 느낌으로 정리를 했는데, 발표가 끝나고 모두가 해당 내용을 살펴볼 수 있게 링크를 강의 슬랙 채널에 공유하였다.
수업이 끝나고 늦은 시간에 약속이 있어 남아서 공부를 더 했는데, 몇몇 분들이 내가 공유한 내용을 보고 따라서 작업을 진행하셨다. 내가 글을 불친절하게 작성한 탓에 안 되는 부분이 발생해서 찾아온 분들이 계셨다.
그 분들께 도움을 드리면서 추가적으로 내가 알아가는 부분들도 생겼다.
뿌듯하기도 했고, 글을 더 공들여서 써야겠다는 생각도 들었다.
여태껏 공부나 배운 내용을 노션에 정리하는 습관을 들였는데, 누군가가 글을 읽는다는 생각을 하지 않고 막 적었던 것 같다.
그런 습관 덕분에 제한된 시간 안에 보기 좋게 발표자료를 만들 수 있었지만, 내가 고려하지 못한 부분에서 오류가 발생할 수 있다는 것을 알게 되었다.
아무튼 알차고 기분 좋은 2주차 끝.
