
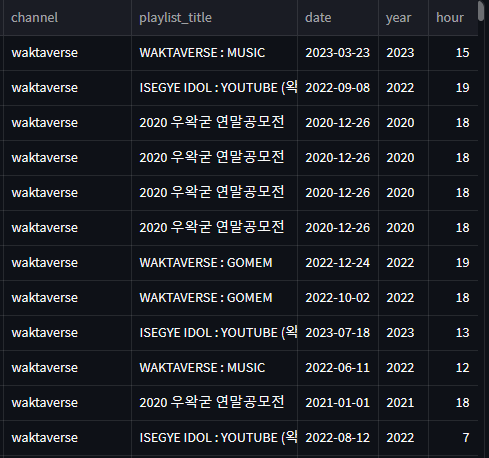
publishedAt에서year과hour컬럼을 따로 만들어 놓은 데이터프레임이 아래와 같을 때, 연도별(Year)로 업로드 시간(Hour)이 주로 언제 인지 알기위해서 pivot을 이용해야 했습니다!
table 형태
pivot() ?
python 에서 pivot을 이용하려면.. 간단하다!
df.pivot(index=None, columns=None, values=None)
- values: 요약될 값
- index: 피벗 테이블에서 값을 행으로 그룹화할 기준값
- columns: 피벗 테이블에서 값을 열로 그룹화할 기준값
- aggfunc: 값을 요약할 계산식, 기본값은 numpy.mean
- fill_value: 요약 후 결과 피벗 테이블에서 빈 값을 채울 값
- sort: 정렬 여부 결정
아래의 예시처럼 year 값을 기준으로 데이터를 바꿔야하므로, pivot()을 사용해보자!
| hour | 2020 | 2021 | 2022 | 2023 |
|---|---|---|---|---|
| 1 | 0 | 13 | 4 | 0 |
| 2 | 1 | 0 | 8 | 0 |
| 3 | 10 | 11 | 12 | 0 |
| ... |
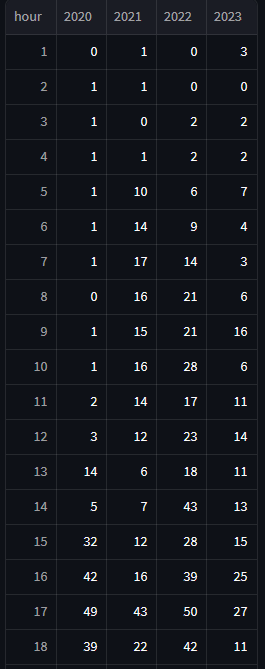
나의 경우 index='hour', columns='year'
년도별로 어떤 시간에 업로드 했는지 '개수'가 필요하기 때문에 aggfunc='size' 를 추가해야한다. 개수 뿐만 아니라 평균을 구하고싶다면 'size' 대신 'mean'을 사용하면 된다. 또한 값이 없는 경우 fill_value=0으로 채워준다.
hour_counts_by_year = filtered_df.pivot_table(index='hour', columns='year', aggfunc='size', fill_value=0)
결과 table
시각화
전체 data에 year 과 채널명에 filter를 걸어서
연도별 과 본채널(우왁굳의게임방송) 서브채널(waktaverse) 채널별로 주 업로드시간대가 언제인지 확인할 수 있게 해봤습니다.
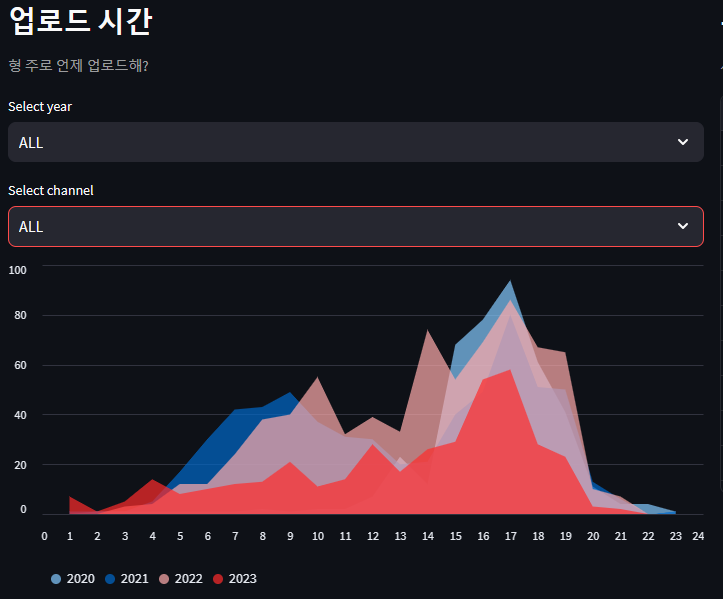
두채널 모두 15시 부터 19시 사이에 영상이 업로드 되고 있는것을 알 수 있습니다. 시간대를 보면 하교시간, 퇴근시간인데요. 아무래도 주 시청자가 10대~20대 이고 집에가면서 할 거 없을 때 습관적으로 유투브를 보기 좋은 시간대인 것 같습니다.🤤

다양한 컨텐츠가 있는 곳을 좋아합니다. 시리즈를 참고하시면 편하게 글을 보실 수 있습니다🫠
좋은 글 감사합니다.