✅ 지난시간
인코딩에 대한 기본적인 지식과, 세계 언어의 혼합을 위해 탄생한 유니키도, 그중 유니코드의 인코딩 방식 중 하나인 UTF-8과 UTF-16의 차이에 대해 공부를 해보았다. 이런 지식을 기반으로 문자열 처리 시에 이해를 도울 수 있을 것 같다.
🔨 코드 개선
📲 Session Write
기존에는 아래와 같이 new Span 을 통해 pakcId, playerId 값을 openSeg에 넘겨주었다. 이 부분을 조금 더 가독성 좋고, 효율적이게 변경해줄 수 있다.

Span 변수를 한 번만 선언하여 openSeg의 값을 받아와, Span의 offest 값만 변경하며 필요한 값들을 바이트 타입으로 변경 시킬 것이다.
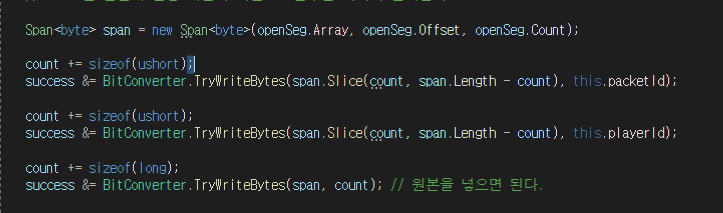
sizeof(ushort) -> 이 부분도 기존에는 숫자2를 그냥 담아주었으나, 더 직관적이게 표현하기 위해 변경해주었다.
Slice()의 기능
Slice는 해당 배열의 시작 위치 부터, 사이즈만큼을 복사해서 뱉어준다고 생각하면 된다. 그러니 기존의 배열에는 영향을 끼치지 않는다.
Slice()를 통해 필요한 부분만 잘라서, 그 곳에 바로 바이트 형식으로 넣어준다.
📳 Session Read
이제 Read를 해주는 곳에서도 Span을 사용하여 값을 받아와 Deserialization을 해줄 것이다.
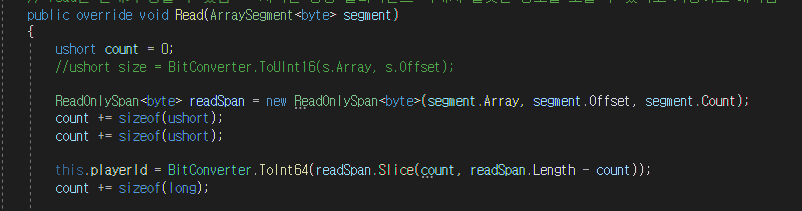
여기는 readOnlySpan을 사용하지만 말 그대로 Read만 되는 것이다. 여기도 Slice를 필요한 영역만 복사하여 ToInt64로 변환(long이 8바이트 짜리이기에) 하면 끝이다.
💌 String Pakcet
이번에는 String 타입의 패킷들은 어떻게 serialization 을 할 수 있는지 처리 하는 방법을 배워 볼 것이다.
String 타입이 숫자들과는 다른 이유가 long은 8바이트, short은 2바이트와 같이 크기가 정해져있지만 string 타입의 경우는 정해져있지 않기에 넘길 때 얼만큼 넘어가는 지 알려주는 과정이 다르다.
UTF-8인가 UTF-16인가
지난 시간에서 배운대로 둘은 약간의 차이를 가지고 있으나 C#에서는 string, char가 기본적으로 UTF-16이기에 굳이 8로 변경해주며 복잡하게 해줄 필요가 없어 UTF-16을 사용할 것이다.
💨 string packet 넘기는 방법
string packet은 말한대로 그 사이즈 예측이 어렵기에 두 단계로 구분하여 보내면 된다.
- size 먼저 보내기
- 데이터 값 보내기
🔹 Session Write - 재작업
Encoding.Unicode.GetbyteCount를 활용하면 쉽게 this.name의 사이즈를 불러올 수 있다.

위와 같은 방법으로 사이즈를 구했으면 Array.Copy를 사용해 바이트 타입의 this.name을 openSeg으로 구한 길이만큼 넘겨주면 된다.
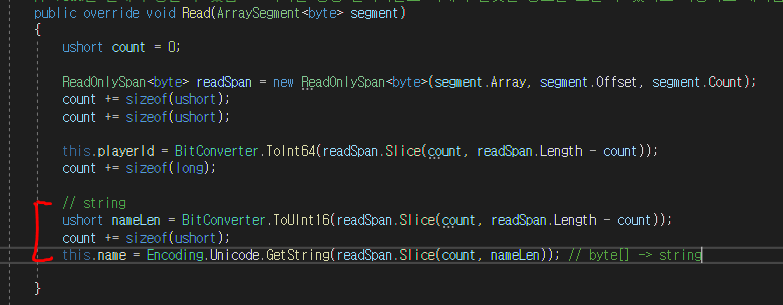
🔹 Session Read - 재작업
Read에서는 반대로 길이를 우선 가져오고, 그 길이만큼을 GetString()으로 가져와 읽어주면된다.
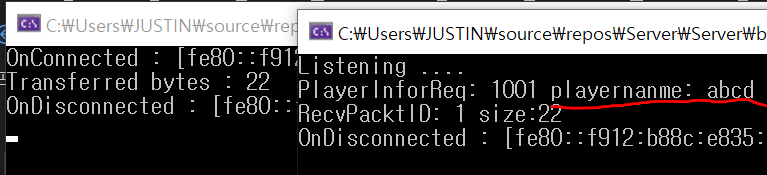
그후 playername 값에 abcd를 넣어 테스트를 해보면 string 값도 잘 읽어오는 걸 확인할 수 있다.
😲 코드 조금 더 개선해보기 Session Write
위에서 write를 할 때에 GetBytes()를 통해서 this.name을 바이트 타입으로 변환하고, ArrayCopy()를 통해 openSeg에 넣어주고 있었다. 이를 조금 더 개선을 해보면
GetBytes()의 다른 기능 활용
Encoding.Unicode.GetBytes (string s, int charIndex, int charCount, byte[] bytes, int byteIndex)
-> s 값을 charIndex ~ charCount 만큼을 byte타입으로 캐스팅하여 bytes의 byteIndex 넣어주고, 몇 바이트를 사용했는지 int 값으로 뱉어준다.
이를 활용하여 this.name을 0부터 this.name.legnth(8바이트) 만큼을 openSeg에 복사하여 담아준다.
ushort nameLen =
(ushort)Encoding.Unicode.GetBytes(this.name,
0, this.name.Length, openSeg.Array,
openSeg.Offset + count + sizeof(ushort));

적용을 하게되면, Array.Copy() 했던 방식과는 조금 다르게 GetBytes로 값을 먼저 담아주고, 크기 값들을 정리해주는 방식으로 변경하였다.
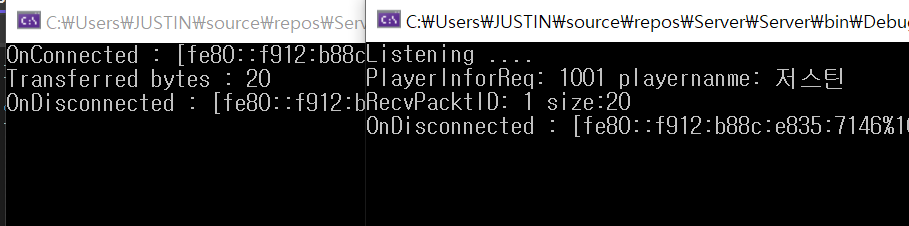
abcd는 재미없으니 이름을 바꿔서 결과를 확인해보면 정상 출력이 되고, 세글자로 변경하니 size 또한 기존 22에서 20으로 준 걸 확인할 수 있다.
