📒 해시 테이블(Hash Table)
📌 해시 테이블이란?
- 각각의 데이터(key)를 해시 함수를 통해 index로 변환하여 배열의 해당 index에 데이터를 보관하는 자료구조이다.
- C++ STL의 unordered_map, unordered_set 등이 이것으로 구현된다.
📌 해시 테이블이 필요한 이유
- 예를 들어, 영어 사전에 약 100,000개의 단어가 수록되어 있다고 가정하자.
- 이 사전에서 하나의 단어를 선형 탐색을 활용하여 탐색한다면 걸리는 시간 복잡도는 O(n)의 시간이 걸리게 될 것이다.
- 이를 해결하기 위해 AVL Tree 또는 Red-Black Tree를 활용한다면 O(log n)의 시간으로 줄일 수 있다.
- 하지만, 데이터의 수가 증가하거나, 탐색 횟수가 증가하게 될 경우 O(log n)의 속도도 만족스럽지 못할 것이다.
- 이때, 해시 테이블이 효율적이고 효과적인 자료구조로 활용될 수 있다.
📌 해시 테이블의 특징
- 배열의 각 요소는 키와 값 등으로 이루어진 구조체(및 클래스)로 이루어져 있다.
- key를 고유한 index(해시값)로 변환시키는(hashing) 다양한 해시 함수(hash function)가 존재하며, 해시 함수의 기능에 따라 성능이 좌우될 수 있다.
- hashing : 데이터를 고유한 숫자 값으로 표현하고, 그 값을 통해 데이터의 유무를 확인하거나 해당 숫자에 대응하는 원본 데이터를 추출할 수 있다.
- 해시 함수(hash function) : hashing 과정에서 주어진 데이터로부터 고유한 숫자 값(해시값)을 추출하는 함수
- 모든 key는 중복되지 않는다.
- 요소 삽입, 삭제, 탐색이 O(1)의 시간 복잡도를 가지며 최악의 상황에는 O(n)이 된다.
📌 해시 테이블의 기본 구조
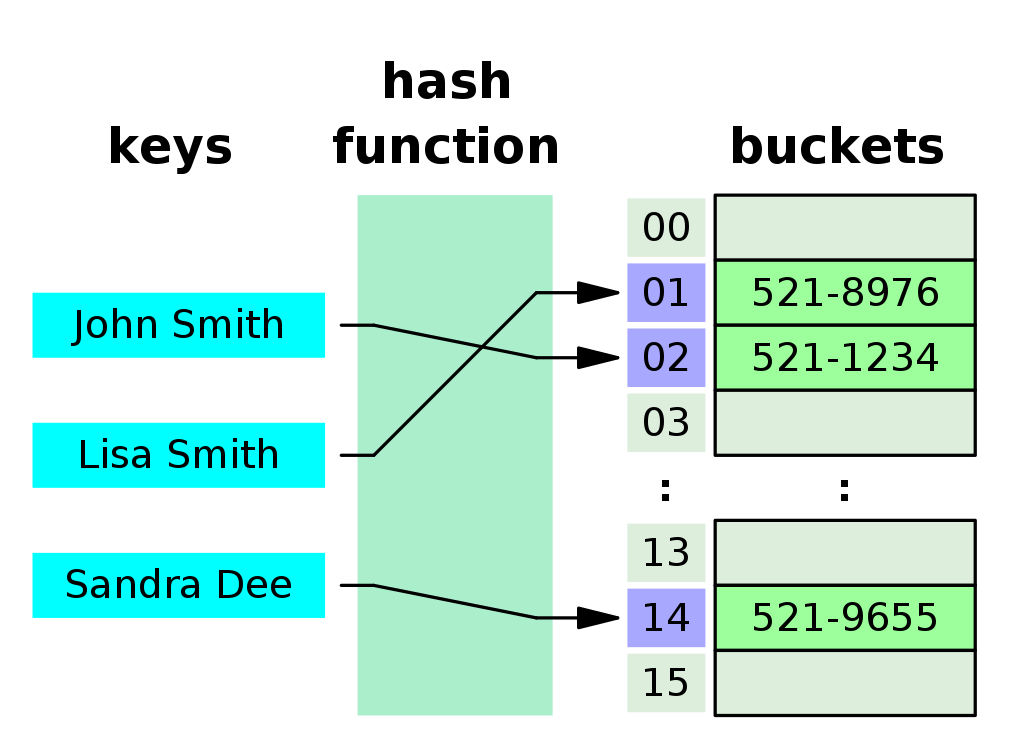 이미지 출처 : https://ko.wikipedia.org/wiki/%ED%95%B4%EC%8B%9C_%ED%85%8C%EC%9D%B4%EB%B8%94
이미지 출처 : https://ko.wikipedia.org/wiki/%ED%95%B4%EC%8B%9C_%ED%85%8C%EC%9D%B4%EB%B8%94
- 해시 테이블은 기본적으로 (key, value)를 저장하는 자료구조이며, 이는 map과 유사하다.
- 위 그림의 해시 테이블 크기는 16
- ("John Smith", "521-1234")라는 한 쌍의 데이터가 들어왔다면 먼저, key 값을 해시 함수로 고유한 숫자 값(해시값)을 추출한다.
- 위 그림에서는 "John Smith"의 해시값은 2로 추출되었고, buckets[2]에 value 값인 "521-1234"을 저장하게 된다.
- 나머지 데이터들도 위 과정을 통해 해시 테이블에 추가할 수 있다.
- 위의 그림에서 "John Smith"를 탐색해야 할 때, buckets를 선형으로 탐색할 필요 없이 "John Smith"를 해시 함수에 넣어 해시 값을 추출한 후, buckets[해시값]를 확인하면 된다.
- 그 때문에 데이터 탐색의 시간 복잡도가 O(1)이 될 수 있는 것이다.
📌 해시 테이블의 장점
- 특정 요소를 탐색할 때 O(1)이라는 시간 복잡도를 갖기 때문에 굉장히 빠르다.
📌 해시 테이블의 단점
- index의 충돌 가능성을 줄이기 위해 데이터 개수보다 큰 크기의 배열을 할당해야 하며, 배열보다 상대적으로 메모리를 많이 사용한다.
- index의 충돌이 일어날 경우 O(n)까지 느려질 수 있기 때문에 적절한 해시 함수 사용과 충돌에 대한 대비를 하여야 한다.
📌 해시 함수(hash function)
- 해시 함수는 간단한 것부터 정말 복잡한 것까지 다양하게 존재한다.
- 만약, 키가 정수일 경우에는 제일 간단한 방법으로는 키를 배열의 크기로 나머지 연산을 하는 것이다.
📌 충돌 관리
- Separate Chaining : 배열의 각 요소를 연결 리스트나 이진 탐색 트리로 만들어, 계속해서 해당 index에 데이터를 추가하는 방식
- 데이터를 탐색할 때는 해당 index에 있는 연결리스트(또는 이진 탐색 트리)를 이어서 탐색해야 한다. (배열을 사용하지 않는 이유는 특정 위치의 데이터를 빠르게 삭제하기 위함임)
- Open Addressing : 해당 index부터 시작해서 빈 곳이 나올 때까지 다음 index로 넘어가서 데이터를 삽입하는 방식(index를 넘기는 대표적인 방법에는 세 가지가 있음)
- 선형 프로빙(Linear probing) : 간격을 고정하여 증가
- 이차 프로빙(Quadratic probing) : 임의의 2차 다항식의 연속적인 값을 추가하여 증가
- 이중 해싱(Double Hashing) : 간격이 보조 해시 함수에 의해 계산
- 데이터를 탐색할 때도 들어온 키와 저장되어 있는 key를 비교하며 다음 index로 넘어가며 탐색하게 된다.
- 그렇기 때문에 Open Addressing의 경우에는 요소를 삭제할 때 주의 사항이 있다.
- 만약, 똑같은 hash의 결과 값으로 충돌이 일어난 세 가지 데이터가 있다고 가정하자.(apple, mango, banana 순으로 저장)
- 그런데, 중간에 있는 데이터인 "mango"가 지워지고 그 자리는 EMPTY 상태가 되었다. (apple, EMPTY State, banana)
- 이럴 경우, banana를 찾으려 할 때, EMPTY 상태를 만날 때까지 요소를 순회하게 되는데, 조금 전 "mango"를 삭제함으로 인해, 그 자리가 EMPTY 상태가 되어, banana를 찾을 수 없게 되었다.
- 이럴 경우, 삭제된 데이터 자리에 dummy 데이터를 두거나, state를 따로 추가하여 관리해야 해시 테이블의 구조를 유지할 수 있다.
- 저장할 key의 개수에 비해 해시 테이블의 크기가 작으면, 충돌이 자주 발생하여 리스트의 길이가 길어지게 된다.
- 리스트의 길이가 길어지게 되면 해시 테이블의 장점이었던 O(1)의 시간 복잡도가 느려지게 되고, 메모리의 낭비도 발생하게 된다.
📌 부하율(load factor)
- 부하율(load factor) : 전체 key의 개수 / 해시 테이블의 크기
- 즉, 부하율은 해시 테이블에서 각각의 연결리스트에 저장되는 평균 키의 개수를 의미한다.
- 전체 키 개수 = 해시 테이블의 크기(부하율 1) : 매우 이상적인 상태이며 모든 연산이 O(1)에 가깝고, 메모리 낭비 또한 적다.
- 부하율 < 1 : 메모리 낭비가 발생하고 있다는 것을 의미한다.
- 부하율 > 1 : 연결리스트의 평균 길이가 1보다 크다는 것을 의미하고, 이는 탐색의 과정이 느리게 동작할 수 있다는 것을 의미한다.
- 그러므로 부하율을 1에 가깝도록 유지하는 것이 이상적이며, 실제로 이를 유지하기 위해 해시 함수를 변경하는 등의 rehasing을 진행하는 해시 테이블도 존재한다.
- 하지만 만약, 크기가 n인 해시 테이블의 모든 키 n개가 하나의 연결리스트에 모두 저장되어 있다고 가정해 보자.
- 이 경우에는 부하율은 1이지만, 탐색의 시간 복잡도는 O(n)이 걸릴 것이다.
- 때문에, 부하율도 중요하지만, 최대한 key를 분산시킬 수 있도록 해시 함수를 구현하는 것이 중요하다.
📌 배열 크기 재조정
- 특정 부하율이 넘어가게 되면 크기를 재조정한다.
- 크기를 재조정하면서, 기존의 해시값들을 늘어난 배열의 크기로 나머지 연산을 수행하게 되면, 기존에 충돌했던 데이터들도 다시 배치되며 충돌되지 않게 삽입될 가능성이 있다. (재조정 하면서 다시 해시 함수를 거치게 됨)

복습하기 위해 쓰는 글