[Computer Architecture] CPU

컴퓨터가 이해하는 정보
비트와 바이트 — 모든 정보의 출발점
1비트(bit)
- 표현 가능 값: 0 또는 1 (2가지)
여러 비트가 모이면?
- 2비트 → 4가지 값
- 3비트 → 8가지 값
- n비트 → 2ⁿ가지 값 표현 가능
바이트(byte)
- 1바이트 = 8비트
- 1바이트로 표현 가능한 정보 개수 = 2⁸ = 256가지
정보 단위
| 단위 | 의미 |
|---|---|
| 1 Byte | 8 bit |
| 1 KB | 1,000 Byte |
| 1 MB | 1,000 KB |
| 1 GB | 1,000 MB |
| 1 TB | 1,000 GB |
※ 1,024단위는 KiB, MiB 등 2진 기반 단위.
워드(Word) — CPU의 데이터 처리 단위
프로그램이 2GB라고 해서 CPU가 한 번에 2GB를 읽는 게 아니다.
CPU는 자신의 워드 크기 단위로 데이터를 처리한다.
- 32비트 CPU → 워드 = 32bit
- 64비트 CPU → 워드 = 64bit
워드 크기는 CPU 아키텍처를 결정하는 핵심 요소
(주소 공간 크기, 레지스터 크기, 연산 성능 등)
0과 1로 숫자 표현하기 — 2진법과 16진법
2진법(binary)
- CPU는 0/1 신호만 이해 → 내부 데이터는 모두 2진수
예)
- 10진 5 → 2진 101(₂)
- 10진 6 → 2진 110(₂)
왜 16진법(hexadecimal)을 쓰나?
2진수는 너무 길고 읽기 어렵기 때문.
예)
- 128 → 2진:
10000000(8자리) - 128 → 16진:
0x80(2자리)
네트워크(MAC 주소, IPv6) 등에서도 16진법을 많이 사용한다.
0과 1로 실수 표현하기 — 부동소수점(IEEE 754)
프로그래밍에서 유명한 문제:
0.1 + 0.2 == 0.3 # False왜냐?
부동소수점은 “정확한 표현이 불가능한 수”가 있다
10진의 0.1은 2진에서 무한 반복 소수가 되기 때문에
CPU는 ‘근사값’을 저장한다. → 항상 약간의 오차가 존재.
IEEE 754 구조
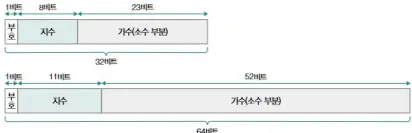
- float(32bit): 1비트 부호비트 + 8비트 지수 + 23비트 가수
- double(64bit): 1비트 부호비트 + 11비트 지수 + 52비트 가수
- 가수는 항상
1.xxxxxx형태(정규화), 앞의 1은 저장하지 않음
중요한 포인트
- 모든 실수는 정확하게 표현되지 않는다
- 금융, 금액, 물류 수량 계산 → 부동소수점 사용하면 X → 소수는 정수 기반(예: 원 단위 저장) 또는 Decimal 타입 사용
면접에서 단골 질문이다.
0과 1로 문자 표현하기 — 문자 인코딩
문자 집합(Character Set)
컴퓨터가 어떤 문자들을 표현할 수 있는지 정의한 목록
예)
- ASCII
- EUC-KR
- Unicode
인코딩(Encoding)
문자 → 0과 1(코드값) 변환
디코딩(Decoding)
0과 1 → 문자 변환
ASCII — 7비트로 128개 문자
- 영어 + 숫자 + 특수문자
- ‘A’ → 65 →
1000001(₂)
한글 X
EUC-KR — 한글 인코딩(2바이트)
- 한글 완성형 2,350자 정도 표현
- '한' →
C7D1 - '글' →
B1DB한글 조합 불가 → 모든 한글 표현 불가능
Unicode — 전 세계 문자를 통합한 문자 집합
유니코드는 “문자에 부여된 코드 포인트”를 정의한 것이고,
이 값을 어떻게 저장할지는 UTF 방식에 따라 달라진다.
UTF 종류
| 인코딩 | 특징 |
|---|---|
| UTF-8 | 가변 길이(1~4바이트), 웹 표준 |
| UTF-16 | 가변 길이(2~4바이트), Windows 내부 |
| UTF-32 | 고정 길이(4바이트), 메모리 많이 씀 |
예시 한글
- ‘한’ 코드 포인트 → U+D55C
- ‘글’ 코드 포인트 → U+AE00
UTF-8 인코딩 시:
- ‘한’ →
ED 95 9C - ‘글’ →
EA B8 80
Base64 — 바이너리 데이터를 문자로 안전하게 전송하는 방법
이미지, 파일, 바이너리 데이터를
문자열 형태(ASCII)로 안전하게 변환하는 방식.
- 6비트씩 끊어서 64개의 문자 중 하나로 매핑
- 이메일 첨부 파일, 토큰 값 등에 사용
- 패딩(
=) 사용함
명령어 — 연산 코드 + 오퍼랜드
명령어는 두 영역으로 구성된다.
연산 코드(opcode)
무엇을 할지
예: ADD, MOVE, LOAD, JUMP, COMPARE …
오퍼랜드(operand)
연산에 사용할 데이터 또는 주소
대부분 주소(address field)가 들어간다.
예)
더해라 100번지 값에 10을명령어를 기계어·어셈블리어로 표현하기
기계어(machine code)
CPU가 직접 실행하는 0/1 정보
보기 매우 어려움
어셈블리어(assembly)
기계어를 사람이 읽을 수 있게 번역한 언어
CPU 아키텍처별로 다름
예: CISC 기반(x86)
push rbp
mov rbp, rsp
imul eax, eax
ret예: RISC 기반(ARM)
push {r7}
mul r3, r3, r3
bx lrCPU마다 명령어·레지스터 체계가 다르기 때문에
기계어/어셈블리어도 반드시 달라진다.
명령어 사이클 — CPU가 명령어를 처리하는 과정
CPU는 프로그램을 “명령어 단위"로 읽고 실행한다.
이때 각 명령어는 다음 주기를 반복한다.
(1) 인출 사이클(Fetch)
메모리에서 명령어를 가져오기
레지스터 PC(Program Counter)가 명령어 주소를 가리킴
(2) 간접 사이클(Indirect)
명령어의 오퍼랜드가 메모리 주소일 경우
추가로 메모리에 접근해 데이터를 가져오는 단계
(3) 실행 사이클(Execute)
ALU/레지스터/메모리를 이용해 명령어 실제 실행
(4) 인터럽트 사이클(Interrupt)
I/O, 예외, 타이머 등 외부 요청 처리
→ 다음 장에서 본격적으로 등장
CPU
CPU 내부의 핵심 저장장치: 레지스터
CPU 안에는 여러 종류의 ‘초고속 메모리’가 있다. 이를 레지스터라고 한다.
대표 레지스터들을 보자.
프로그램 카운터 (PC)
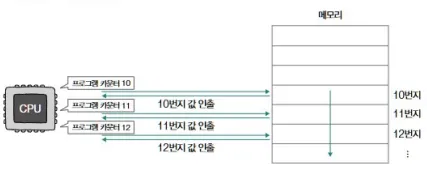
- 다음 실행할 명령어의 주소를 저장
- 대부분 1씩 증가 → 프로그램이 순차적으로 실행되는 이유
- 조건문, JUMP, return이 발생하면 PC가 임의 위치로 변경됨
명령어 레지스터 (IR)
- 방금 메모리에서 읽어온 명령어 자체를 저장
- 제어장치가 IR에 저장된 명령어를 해석한다.
범용 레지스터 (General Purpose Register)
- CPU가 실제로 연산할 때 쓰는 임시 저장소
- 연산값
- 주소
- 임시 데이터
- x86에는 EAX, EBX, ECX 같은 레지스터가 있음
플래그 레지스터 (FLAGS)
CPU 연산 결과에 대한 상태 정보가 담긴 비트 모음
대표 플래그:
| 플래그 | 의미 |
|---|---|
| Zero | 연산 결과 = 0 |
| Sign | 결과가 음수인지 |
| Carry | 올림/빌림 발생 |
| Overflow | 오버플로우 발생 |
| Interrupt | 인터럽트 허용 여부 |
| Supervisor | 커널 모드인지 |
이 값들을 보고 CPU는 다음 명령어의 흐름을 결정한다.
스택 포인터 (SP)
- 메모리의 스택 영역에서 현재 top 위치를 가리킴
- 함수 호출·리턴할 때 필수
인터럽트 — CPU가 “외부 요청”을 처리하는 방식
인터럽트는 CPU 작업을 중단시키는 신호다.
종류는 크게 2가지
동기 인터럽트(예외, Exception)
CPU 내부에서 발생
(예: 0으로 나누기, 페이지 폴트, 잘못된 명령어)
비동기 인터럽트(하드웨어 인터럽트)
CPU 외부에서 발생
(예: 키보드 입력, 마우스 이벤트, 프린터 작업 완료)
CPU는 인터럽트를 어떻게 처리할까?
인터럽트 발생 → CPU가 처리하는 절차는 항상 동일하다.
CPU의 인터럽트 처리 순서
-
하드웨어가 CPU에게 인터럽트 요청 신호 보냄
-
CPU는 명령어 끝날 때 인터럽트 플래그를 확인
-
인터럽트 허용 상태라면 현재 작업을 스택에 백업
-
인터럽트 벡터를 보고
→ 어떤 인터럽트 서비스 루틴(ISR)을 실행할지 결정
-
ISR 실행
-
끝나면 스택에서 복구 → 이전 작업 재개
인터럽트 = 일종의 자동 호출 함수
인터럽트 벡터
인터럽트 서비스 루틴을 식별하기 위한 정보
인터럽트 서비스 루틴의 시작 주소를 포함하고 있음
CPU가 인터럽트 요청을 보낸 대상으로부터 버스를 통해 인터럽트 벡터를 전달 받는다.
예외(동기 인터럽트)의 종류
Fault
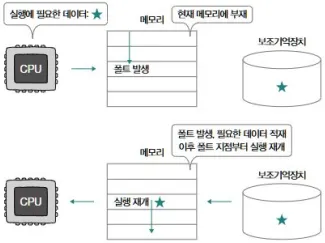
- 문제 해결 후 발생한 명령어부터 다시 실행
- 대표 예: 페이지 폴트
Trap
- 디버거 breakpoint처럼
- 예외가 끝난 뒤 다음 명령어부터 재개
Abort
- 복구 불가능한 치명적 오류
- 프로그램 강제 종료
CPU 성능 요소: 클럭·코어·스레드
클럭(clock)
- CPU가 1초에 몇 번 명령어 사이클을 반복하는가?
- 단위: GHz (초당 10억 번)
클럭 높으면 빠르지만 발열·전력 증가 → 한계 존재.
코어(Core)
- CPU 내부에서 실제 연산을 수행하는 "작은 CPU"
- 4코어 CPU = 실제 처리 장치가 4개
하드웨어 스레드(Hardware Thread, 논리 코어)
- 하나의 코어가 동시에 처리할 수 있는 명령어 흐름 수
- 인텔의 하이퍼스레딩가 대표 기술 → 4코어 8스레드 CPU 가능
소프트웨어 스레드와의 차이
| 종류 | 의미 | 예 |
|---|---|---|
| 하드웨어 스레드 | 물리적 병렬 처리 단위 | 4스레드 CPU |
| 소프트웨어 스레드 | 실행 흐름 단위(코드) | Thread.run() |
병렬성 vs 동시성
병렬성 (Parallelism)
물리적으로 동시에 실행
→ 코어 또는 하드웨어 스레드 수가 증가해야 가능
동시성 (Concurrency)
빠르게 번갈아 실행되어 동시에 실행되는 것처럼 보임
→ 단일 코어에서도 가능
명령어 파이프라이닝 — 현대 CPU 성능의 핵심 기술
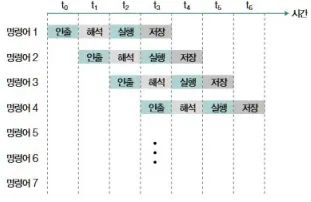
CPU는 명령어를 다음 단계로 나누어 겹쳐서 처리한다.
- 인출
- 해석
- 실행
- 메모리 접근
- 결과 저장
이 단계들을 공장 생산 라인처럼 겹쳐 실행하면
CPU가 쉬는 시간이 없어져 성능이 크게 증가한다.
파이프라이닝의 최적·비최적 아키텍처: CISC vs RISC

| CISC (x86) | RISC (ARM, M1) |
|---|---|
| 명령어 복잡·길이 불규칙 | 명령어 단순·규칙적 |
| 하나의 명령어로 많은 기능 가능 | 명령어 수 많지만 단순 |
| 파이프라이닝 비효율적 | 파이프라이닝 최적화 |
파이프라인이 실패하는 경우 — 파이프라인 위험(Hazard)
데이터 위험(Data Hazard)
데이터 의존성 문제
이전 명령어 결과가 필요한데 아직 나오지 않은 경우
"A = B + C" 다음에 "D = A + E" 같은 패턴
제어 위험(Control Hazard)
프로그램의 갑작스러운 변화
분기, 조건문, JUMP로 인해 PC가 갑자기 변경됨
→ 이미 인출한 명령어들이 의미 없음
구조적 위험(Structural Hazard)
둘 이상의 명령어가 동시에 같은 CPU 자원을 쓰려고 할 때
(ALU 충돌, 레지스터 충돌 등)
