
감으로 튜닝하지 않고 지표를 근거로 성능을 개선한 경험
들어가며
HotSpot의 사용량 이벤트 소비 경로는 단순히 Kafka 메시지를 읽는 구조가 아니었다.
이벤트를 받으면 Redis Lua를 통해 사용량을 반영하고 이후 후속 처리와 영속화까지 이어지는 파이프라인이었다. 평소에는 잘 동작했지만 내가 궁금했던 건 “정상 동작하는가”가 아니라 “지속적인 고부하에서도 실제로 버틸 수 있는가”였다.
그래서 usage-events 토픽 하나를 대상으로 일정 시간 동안 초당 수천 건의 메시지를 지속 발행하는 부하테스트를 진행했다.
목표는 단순히 최대 TPS를 찍는 것이 아니라 어느 구간부터 backlog가 쌓이기 시작하는지, 그리고 그 병목이 Kafka인지, 자바 로직인지, Redis인지, DB인지를 실제 지표로 확인하는 것이었다.
이 과정에서 내가 중요하게 본 것은 “튜닝 목록”이 아니라 측정된 현상을 근거로 다음 개선 포인트를 좁혀가는 방식이었다.
지속 부하에서는 따라가지 못했다
첫 번째 기준점은 usage-events에 대해 초당 5,000건을 10분간 지속 발행하는 테스트였다.
이 테스트에서 Producer는 목표 부하에 가깝게 안정적으로 메시지를 밀어 넣었고 Consumer도 아예 멈춘 것은 아니었다. 문제는 계속 처리하고 있음에도 backlog가 점진적으로 누적되었다는 점이었다.
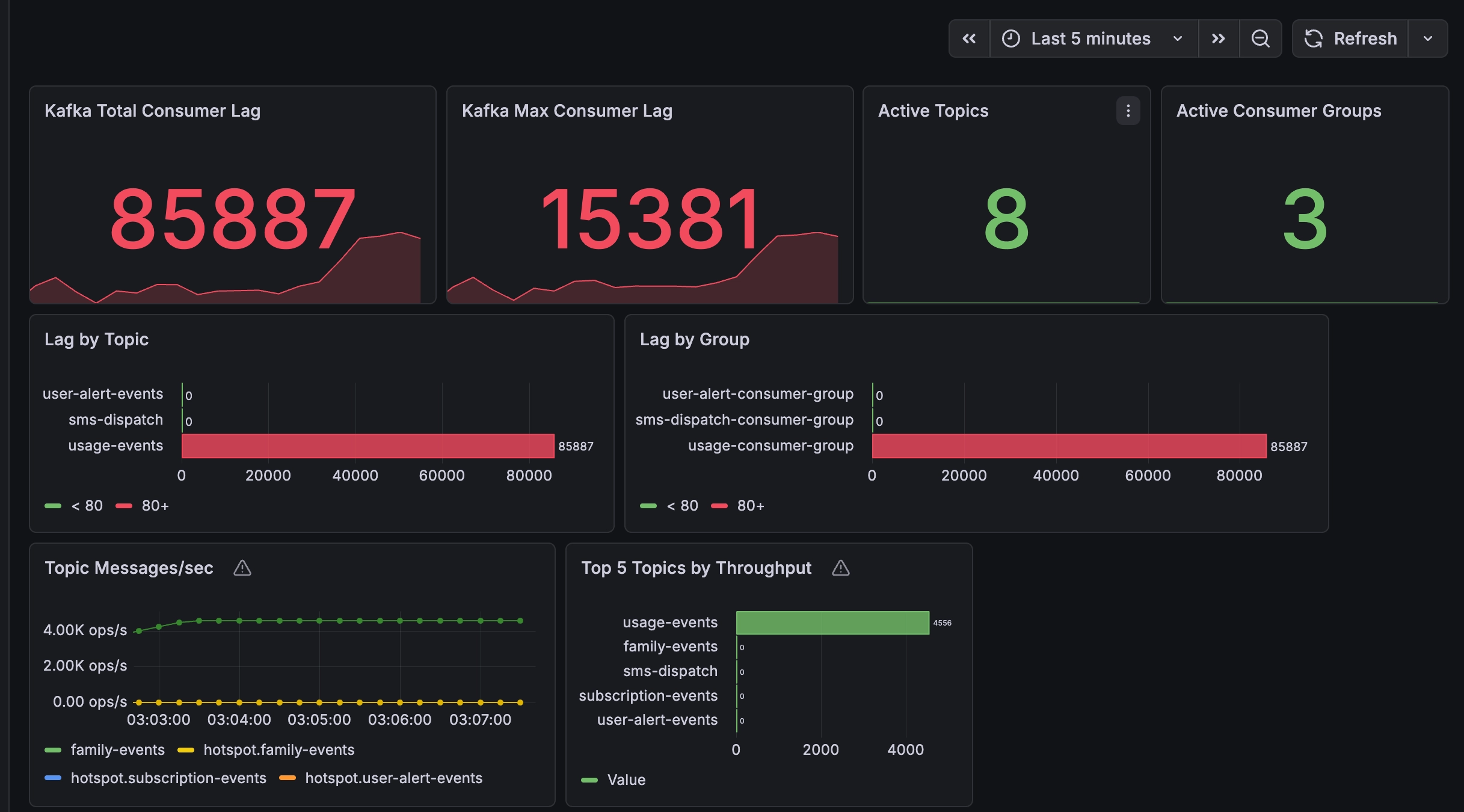
당시 측정 결과를 보면 최종 lag는 약 8.6만 건 수준까지 쌓였고 최대 lag도 1.5만 건을 넘겼다. 전체 입력량 대비 비율로 보면 아주 치명적인 실패는 아니었지만 분명한 사실 하나는 확인할 수 있었다.
현재 구조는 5,000 TPS를 “처리하지 못하는 것”은 아니지만 지속 부하를 완전히 실시간으로 따라가지는 못한다.
이 지점에서 중요한 건 단순히 “느리다”는 결론이 아니었다. Producer는 안정적이었고 lag는 usage-events 소비 경로에 집중되어 있었다. 즉 문제는 usage-events를 소비하는 내부 파이프라인 어딘가에 병목이 있다는 쪽으로 좁혀졌다.
병목은 Kafka 자체보다 소비 경로 내부 오버헤드일 가능성이 컸다
처음 5k 테스트 결과를 보고 가장 먼저 세운 가설은 이거였다.
- Producer는 충분히 부하를 만들고 있다
- Kafka 클러스터 전체가 무너진 것은 아니다
- lag는 usage-events 경로에 집중된다
- 즉 병목은 consumer 내부에 있다
이때 나는 단순히 consumer 수만 늘리기보다 먼저 이벤트 1건을 처리할 때 발생하는 불필요한 비용부터 줄이는 것이 맞다고 판단했다.
그래서 첫 번째 개선은 크게 네 방향으로 잡았다.
- Lua 결과만으로 후속 payload를 만들도록 바꿔 Redis 재조회를 없애기
- per-record ACK 대신 batch ACK로 offset 처리 비용 줄이기
- queue block 방식 대신 pause/resume 기반 backpressure로 listener block 완화하기
- fetch/poll 관련 Kafka 설정을 명시적으로 조정 가능하게 만들기
이 개선은 특정 기술 하나를 바꾼 것이 아니라 핫패스 안에서 “매 이벤트마다 당연하게 치르던 비용”을 하나씩 제거하는 작업에 가까웠다.
첫 번째 개선 결과
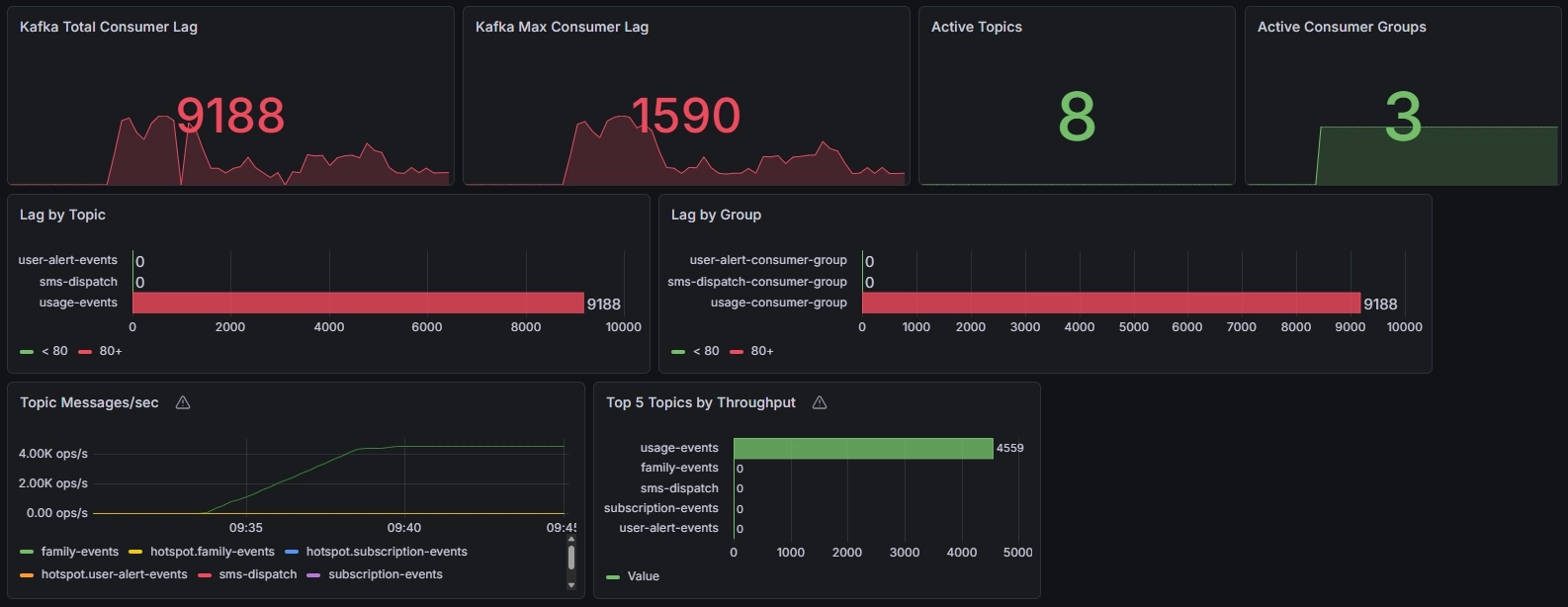
이 개선 이후 같은 조건으로 다시 5,000 TPS 테스트를 수행했을 때 결과는 꽤 분명했다.
- Total Consumer Lag: 85,887 → 9,188
- Max Consumer Lag: 15,381 → 1,590
즉 Total Lag 기준 약 89%, Max Lag 기준 약 90% 가까이 감소했다.
중요한 건 이때 Producer throughput은 거의 비슷했다는 점이다. 즉 부하가 낮아져서 좋아진 것이 아니라 같은 수준의 입력을 Consumer가 더 잘 따라가게 된 것이다.
이 결과를 보면서 나는 첫 번째 확신을 얻었다.
usage-events 경로의 내부 오버헤드가 누적되어 실시간성을 깎고 있었던 것이다.
7,000 TPS에서는 다시 한계가 드러났다
5k 구간이 안정화되자 다음 질문은 자연스럽게 이어졌다.
“그렇다면 7,000 TPS에서도 버틸 수 있는가?”
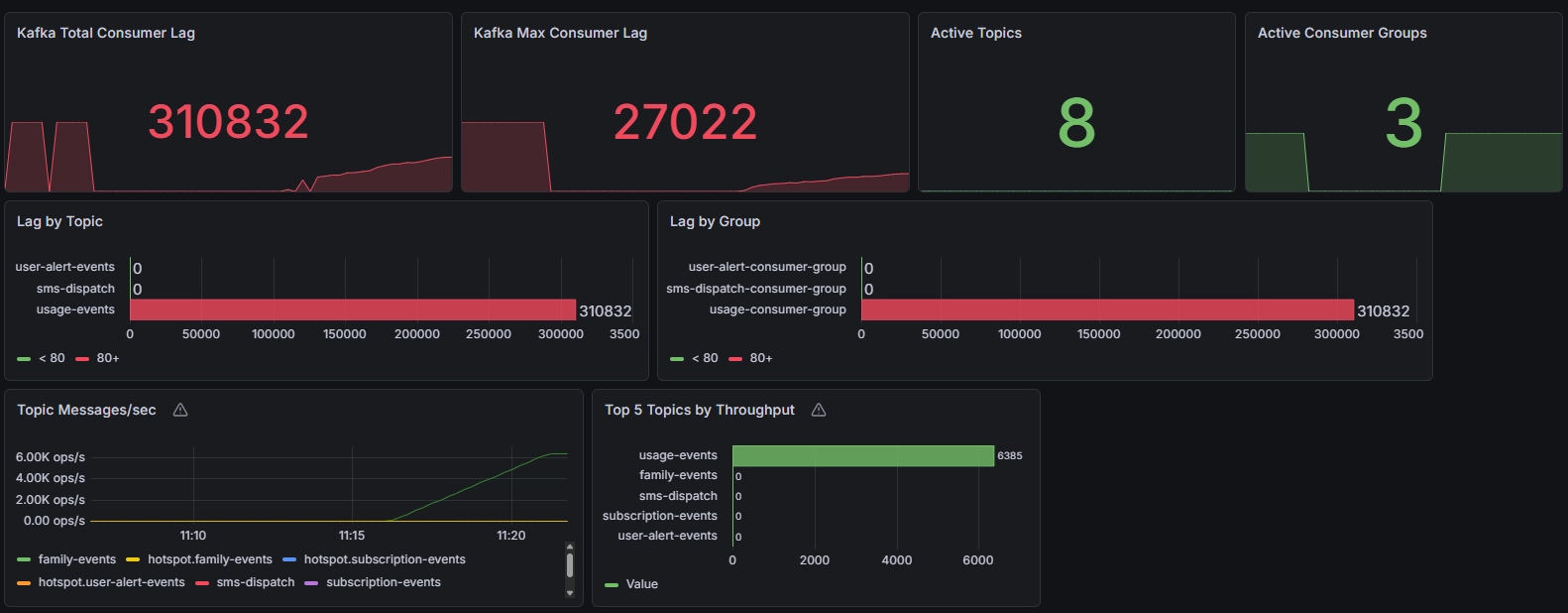
같은 구조로 부하를 더 올려 7k 테스트를 해보니 여기서 다시 다른 그림이 나왔다. 개선된 구조였음에도 backlog가 수십만 건 단위로 쌓였고 Max Lag도 치솟았다. backlog 비율 역시 5k 때와는 비교하기 어려울 정도로 악화됐다.
이 결과는 두 가지를 보여줬다.
첫째, 5k에서 효과를 냈던 개선이 실제로 의미는 있었지만 그 효과만으로 7k sustained load까지 감당할 정도의 headroom이 생긴 것은 아니었다. 둘째, 부하가 일정 수준을 넘으면 lag가 선형적으로 조금씩 늘어나는 것이 아니라 처리 한계를 넘어서는 순간 backlog가 비선형적으로 폭증한다는 점이었다.
즉 이 시점에서 현재 구조의 실효 처리 한계가 어디쯤인지 먼저 파악해야 한다고 생각했다.
모니터링으로 병목을 더 좁히다
여기서부터는 단순 Kafka lag만 봐서는 부족했다. 그래서 처리 경로를 더 세분화해 보기 시작했다. 핵심은 이벤트 1건이 소비될 때 시간이 어디에서 쓰이는지를 나누어 측정하는 것이었다.
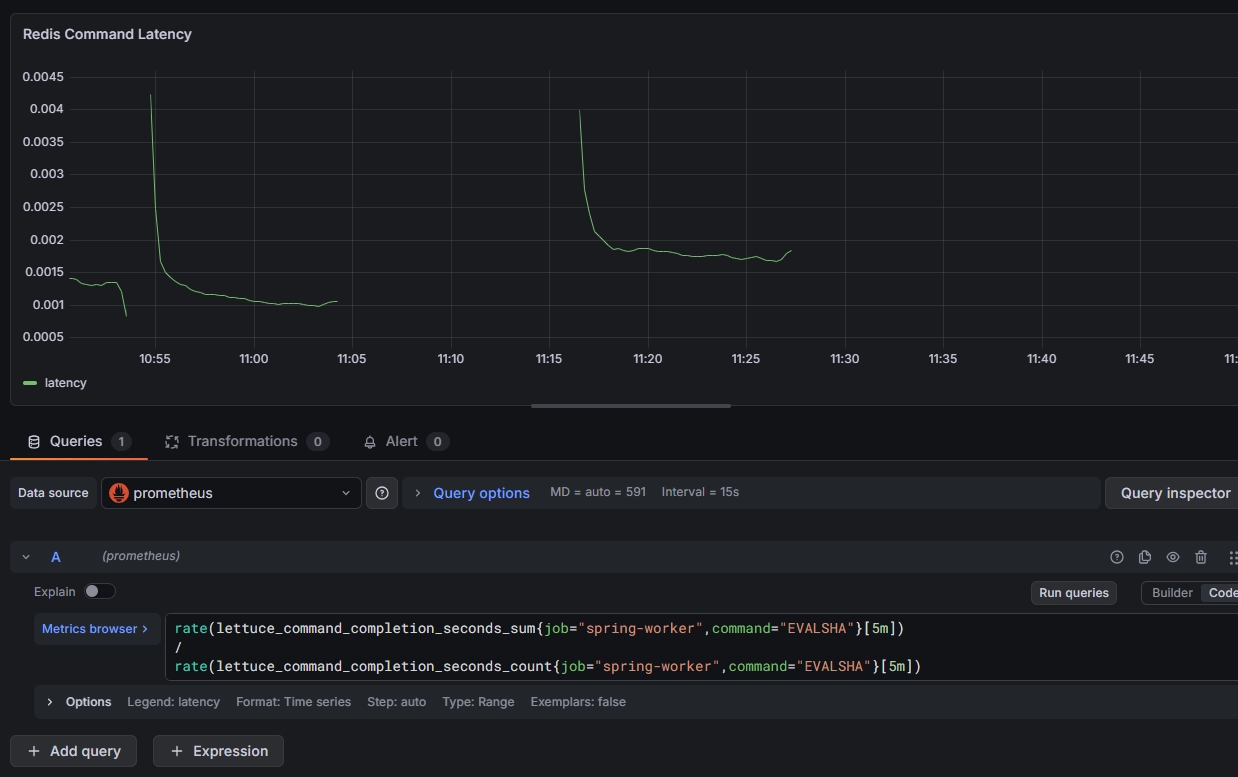

그 결과는 꽤 명확했다.
- Handler 전체 처리시간의 대부분이 Lua 실행 시간이었다
- Lua 실행 시간의 대부분이 실제 Redis 실행 시간이었다
- 반면 파싱, 자바 후처리, DB writer 구간은 상대적으로 매우 작았다
즉 “핸들러가 느리다”는 말은 사실상 “Redis EVALSHA가 느리다”는 말과 거의 같았다.
이 지점이 아주 중요했다.
왜냐하면 이전까지는 Kafka thread 수를 늘리거나 Java 로직을 다듬는 것이 효과를 낼 수 있다고 생각할 여지가 있었지만 지표를 분해해보니 실제 병목은 거의 Redis Lua 실행 경로 자체로 수렴했기 때문이다.
이벤트 1건당 Redis 호출 비용을 어떻게 줄일지를 고민해야 하는 단계였다.
Redis 1회 호출 비용을 줄여야 했다
7k에서 lag가 크게 늘어난 이유를 단순히 partition 부족으로만 보기 어려웠던 것도 이 때문이다. Consumer 병렬성을 늘려도 이벤트 1건당 Redis 호출 시간이 길다면 결국 전체 처리량의 상한은 Redis latency에 의해 결정된다.
실제로 당시 평균 처리시간을 기준으로 보면 concurrency를 늘려도 1건당 약 2ms 안팎이 걸리는 구조에서는 실효 처리 상한이 5k대 중후반 수준에 머무는 것이 자연스러웠다. 7k가 들어오면 결국 조금씩 밀릴 수밖에 없는 구조였다.
그래서 두 번째 개선은 Kafka나 Java보다 Lua 자체를 더 가볍게 만드는 방향으로 잡았다.
핵심은 다음과 같았다.
- 반복적으로 갱신하던 EXPIRE 제거
- 실제로 임계치 변화가 있을 때만 notify 관련 호출 수행
- 같은 해시에 대한 여러 번의 조회를 묶어서 읽기
- 값이 0인 증가 명령은 아예 생략
이 개선은 겉으로 보기에는 사소해 보일 수 있다. 하지만 내가 중요하게 본 것은 “명령 하나의 최적화”가 아니라 매 이벤트마다 반복되는 Redis 명령 수를 줄여 steady-state 비용을 깎는 것이었다.
Lua 최적화 결과
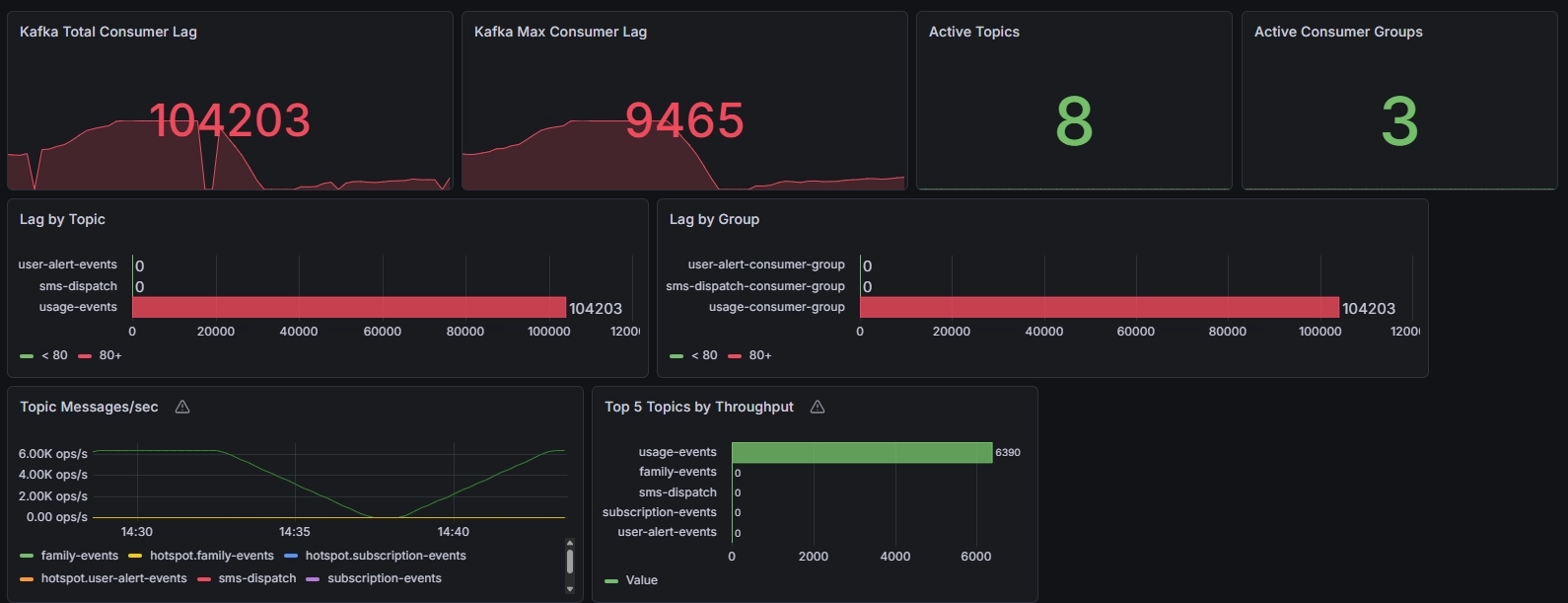

같은 7,000 TPS, 같은 partition/concurrency 조건에서 Lua 최적화 전후를 비교했을 때 결과는 꽤 설득력 있었다.
- Redis 실행 평균 시간: 2554µs → 1840µs
- Handler 평균 처리시간: 2595µs → 1872µs
- Total Lag: 310,832 → 104,203
- Max Lag: 27,022 → 9,465
즉 Redis 실행시간이 약 28% 줄어들었고 그 감소 폭이 거의 그대로 Handler 처리시간 감소와 연결되었으며 최종적으로 Kafka Lag도 크게 줄어들었다.
이 결과를 보며 가장 만족스러웠던 점은 “느린 것 같다”는 감각이 아니라 지표로 확인한 병목을 정확히 건드렸고 그 효과가 다시 지표로 돌아왔다는 점이었다.
병목이 Redis 실행 구간이라는 것을 확인했고
그 병목을 직접 줄여 실질적인 처리량 개선으로 연결한 단계
라고 정리할 수 있었다.
처리시간이 줄었다면 이제 병렬성도
Lua 최적화 이후에는 다시 병렬성 문제를 볼 수 있었다. 처리시간이 줄어들었더라도 목표 TPS를 안정적으로 따라가려면 결국 평균 처리시간 대비 충분한 병렬성 여유가 필요했기 때문이다.
이때 내가 참고한 단순한 기준은 필요 concurrency ≈ 초당 유입량 × 이벤트 평균 처리시간이라는 관점이었다.
이 기준으로 보면, 7k 구간에서 기존 12 partition은 평균값 기준으로도 여유가 거의 없는 상태였다. 실전에서는 평균값뿐 아니라 순간적인 Redis latency 상승, 특정 파티션 쏠림, poll/commit 편차 같은 변동성도 있기 때문에 평균상 “간신히 맞는 수준”이면 backlog가 계속 쌓일 수 있다.
그래서 partition과 concurrency를 12에서 18로 확장했다.
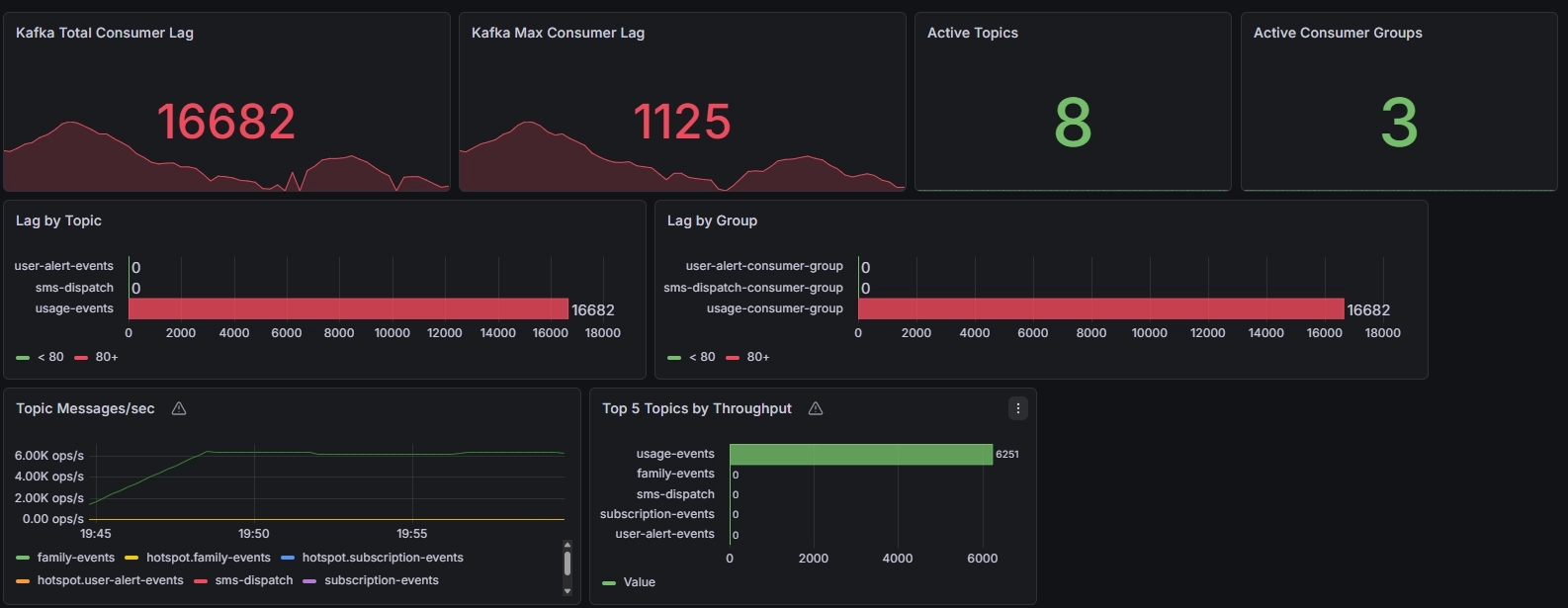
그 결과:
- Total Lag: 104,203 → 16,682
- Max Lag: 9,465 → 1,125
로 다시 큰 폭의 개선이 일어났다.
이 결과는 단순히 partition이 많아져서가 아니라 줄어든 처리시간에 맞춰 필요한 병렬성 + 여유분을 확보했을 때 실제 backlog가 크게 줄어든다는 걸 보여줬다.
즉 이 단계에서 나는 성능 개선을 “코드 최적화”와 “병렬성 설계”를 따로 보는 것이 아니라 처리시간을 줄이고 그에 맞는 concurrency를 확보하는 일로 함께 보게 됐다.
10,000 TPS에서는 또 다른 한계가 드러났다
이후 10k 테스트를 위해 partition을 24까지 늘렸지만 이 구간에서는 또 다른 양상이 나타났다.
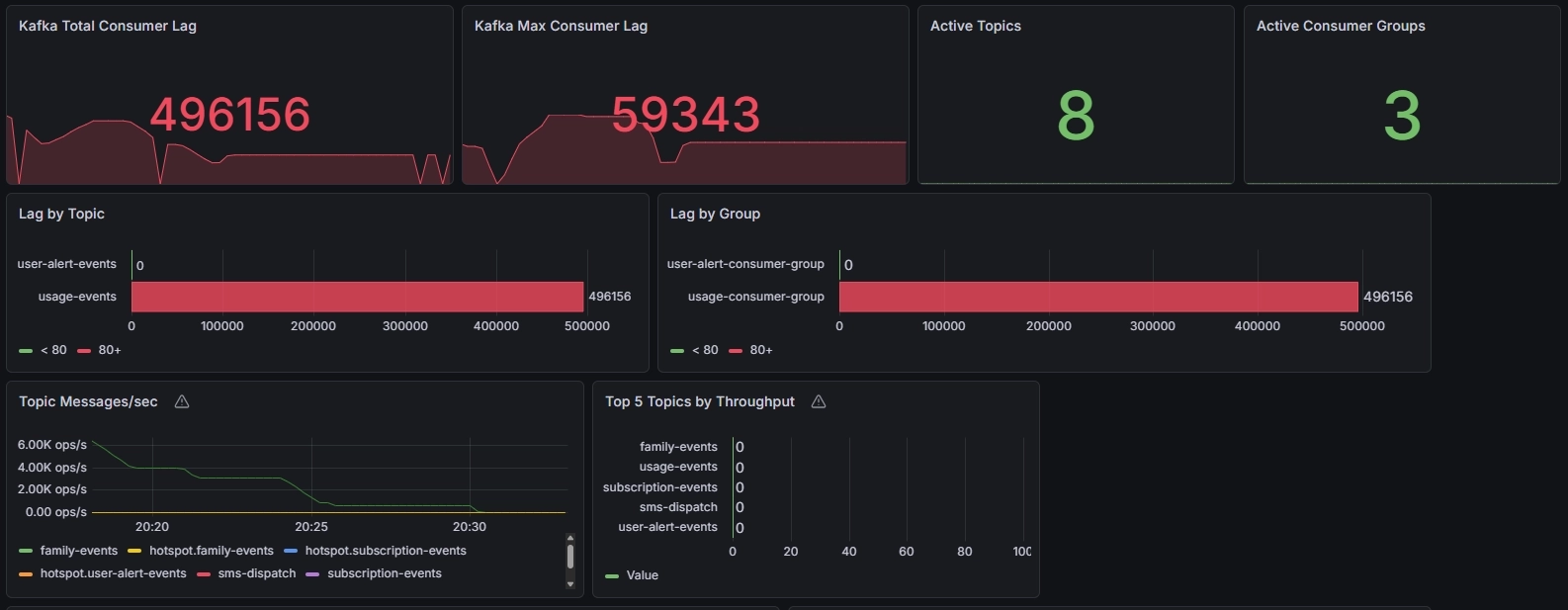
겉으로 보면 partition 수는 충분해 보였지만 실제로는 backlog가 다시 크게 쌓였고 throughput도 끝까지 안정적으로 유지되지 못했다. 여기서 중요한 건 이 결과를 단순히 “partition이 부족했다”로 해석하면 안 된다는 점이었다.
왜냐하면 평균 처리시간 기준으로만 보면 24 partition이면 계산상 충분할 수 있었기 때문이다. 실제 문제는 부하가 올라가면서 Redis 처리시간 자체가 악화되었다는 점이었다.
즉 partition을 늘려 병렬 consume은 가능해졌지만 그만큼 Redis에 동시 요청이 더 강하게 몰리면서 오히려 Lua 실행 시간이 늘어나는 구간이 생긴 것이다. 여기에 더해 당시 테스트에서는 발행 스케줄러와 consumer가 같은 서버에서 함께 동작하고 있었다.
즉 producer, validator, consumer, Redis client, DB writer가 같은 자원을 두고 경쟁하는 구조였고 이는 CPU, 스레드 스케줄링, GC, 네트워크, client event loop까지 복합적으로 영향을 줄 수 있었다.
이걸 보면서 나는 한 가지를 더 분명히 배웠다.
실제 병목이 외부 의존 구간에 있을 때는 병렬성 확대가 오히려 병목을 더 강하게 두드릴 수도 있다.
producer/consumer 자원 분리와 Redis 실행 경로 자체의 추가 개선이 선행되어야 한다는 걸 보여준 테스트였다.
마무리
처음에는 성능 개선을 “consumer를 더 늘릴까”, “설정을 조금 바꿔볼까” 같은 감각적인 문제로 볼 수도 있었다. 하지만 이번 경험을 통해 나는 성능 문제를 그렇게 다루면 안 된다는 걸 더 분명히 느꼈다.
정말 중요한 것은
- 어디서 backlog가 생기는지 보고
- 그 원인이 전체 처리량 부족인지, 특정 구간의 latency인지 구분하고
- 평균 처리시간과 병렬성의 관계를 같이 보며
- 지표가 가리키는 병목을 직접 줄이는 것
이었다.
결국 이번 경험은 “부하테스트를 했다”가 아니라,
부하테스트와 모니터링을 통해 병목을 감으로 추정하지 않고
지표로 좁혀가며 성능을 개선한 경험
이라고 정리할 수 있다.
그리고 그 과정에서 내가 가장 크게 배운 것은 이것이다.
성능 개선은 무작정 빠르게 만드는 일이 아니라
가장 비싼 경로를 정확히 찾아 그 비용을 줄이는 일이다.
