[MySQL] I/O 및 쿼리 실행 절차

HDD(Hard Disk Drive) vs SSD(Solid State Drive)
What is HDD?
HDD는 가장 대중적으로 사용되는 비휘발성 데이터 저장장치이다.
Platter라고 하는 원판에 자기를 사용하여 실제로 데이터를 읽고 쓴다.
CPU 및 시스템 보드의 소프트웨어에 의해 헤드가 플래터의 각 섹터로 이동하여 데이터를 저장한다.

HDD에 데이터를 쓸 때 파일의 크기에 따라 섹터의 일부를 사용한다. 데이터에 대한 업데이트가 발생하면 CPU는 HDD에 사용 가능한 다음 섹터에 데이터를 쓰도록 지시한다. 그 전 섹터에서 해당 새 섹터까지의 거리가 데이터를 읽는 속도에 추가되어 이러한 데이터의 분리 인스턴스가 많아질 수록 속도가 느려진다.
이러한 데이터 분리를 디스크 조각화라고 한다.
우리가 흔히 알고 있는 디스크 조각 모음을 하면 컴퓨터의 성능이 빨라진다고 하는 것이 디스크 조각화된 데이터들을 한 곳에 재정렬하는 행위이다.
What is SSD?
HDD와 동일한 비휘발성 데이터 저장장치이다.
기존 HDD에서 플래터를 제거하고 그 대신 NAND 플래쉬 메모리와 고성능 컨트롤러를 탑재해서 HDD를 대체하고 있다.
모든 컴포넌트가 전기 장치이며 HDD와 같은 기계 장치를 가지고 있지 않다.
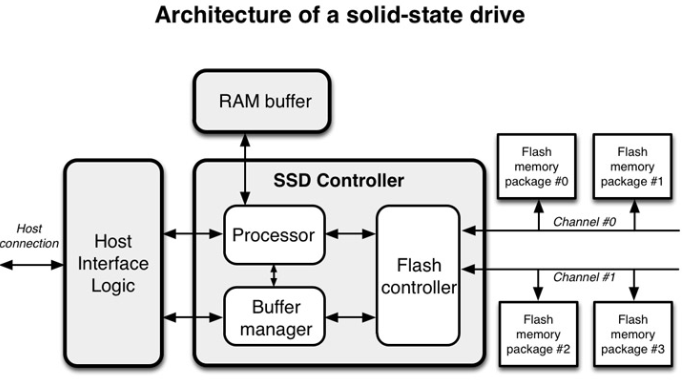
SSD 컨트롤러에 장착된 프로세서가 명령을 받아서 Flash 컨트롤러로 전달한다.
SSD는 자체적으로 보드에 내장된 메모리(RAM)을 가지는데 일반적으로 맵핑 정보를 저장하거나 흔히 아는 캐시 용도로 사용된다.
여러개의 Channel을 통해 서로 NAND 플래쉬 메모리 패키지로 구성된다.
What is Differences?
-
성능
HDD는 직접 읽어오려는 주소의 데이터의 섹터가 도착할 때까지 기다려야 하는 Sleep 타임이 길다.
그에 반해 SSD는 전기 신호로 해결하기 때문에 데이터를 쓰고 읽는 속도가 월등히 빠르다.
HDD가 데이터 센터에 직접 걸어가서 필요한 자료를 찾아 집에 오는 방식이라면, SSD는 데이터 센터에 전화를 걸어 확인하는 방식이라고 이해하면 쉽다.
-
데이터 보존력
SSD는 데이터 휘발성이 HDD에 비해 높다.
플래쉬 메모리는 정전기에 취약하고 데이터가 자연 증발하기도 한다.
HDD는 손상되어도 자기 기록의 흔적이 남아있으면 일부라도 복구가 가능하지만, SSD는 데이터 정보가 증발하면 말 그대로 흔적 없이 소멸된다.
-
가격 대비 용량
HDD가 SSD에 비해 가격 대비 용량이 월등히 높다. (약 4배)
I/O Mechanism
What is I/O?
Database는 Data를 Block 단위로 읽고 저장한다.
대부분의 데이터베이스는 8kb가 적합, Oracle도 기본 사이즈가 8kb
데이터베이스 튜닝에서 중요한 것이
>> 블록 단위의 I/O 줄이기
왜? 왜 블록 단위 I/O를 줄여야 해?
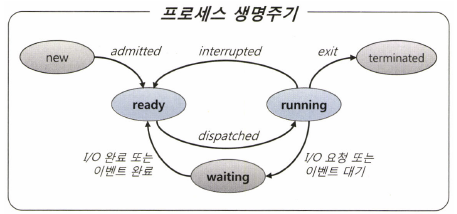
OS 또는 I/O 서브 시스템이 I/O를 처리하는 동안 프로세스는 잠을 잔다. (Waiting)
생성 이후 종료 전까지 준비와 실행과 대기 상태를 반복한다.
여러 프로세스가 하나의 CPU를 공유할 수 있지만, 특정 순간에는 하나의 프로세스만 CPU를 사용할 수 있기 때문에 이런 메커니즘이 필요하다.
Interrupt 없이 일하던 프로세스도 디스크에서 데이터를 읽어야 할 때는 CPU를 OS에 반환하고 잠시 Waiting 상태에서 I/O가 완료되기를 기다린다.
Random I/O vs Sequential I/O
Random I/O
데이터를 임의의 위치에서 읽거나 쓰는 작업
Sequential I/O
데이터를 연속적인 블록으로 순차적으로 읽거나 쓰는 작업
HDD에서 여러개의 데이터를 입력할 때 순차 I/O는 헤더를 한 번만 움직이지만, 랜덤 I/O는 데이터의 개수 만큼 움직여야 한다.
디스크의 헤더를 움직이는 시간이 데이터를 쓰고 읽는 데 걸리는 시간에서 가장 많은 부분을 차지하는 병목이 되는 지점
SSD는 기계적 장치를 사용하지 않고 전기적 신호를 통해 데이터를 읽고 쓰기 때문에 그럼 상관없겠네?
라고 생각할 수 있지만, SSD에서도 랜덤 I/O는 순차 I/O보다 Throughput이 떨어진다.
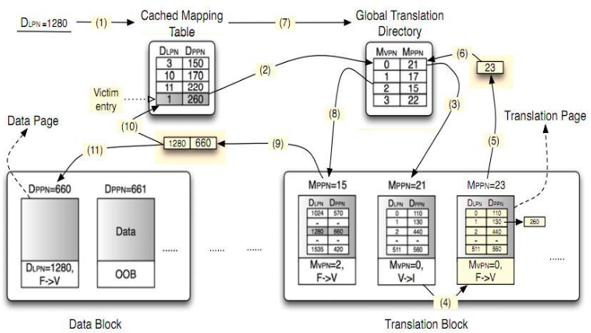
- SSD는 물리적으로 NAND 플래쉬 메모리에 데이터를 읽고 쓰는 것이 아니고 위에서 설명한 것처럼 논리적 주소를 물리적 주소로 변환하기 위한 매핑 테이블을 사용한다.
- 매핑 테이블을 업데이트 하려면 NAND 플래쉬 메모리의 물리적 위치를 찾아가서 데이터를 가져와야 하는 과정이 추가로 발생한다.
위에서 언급한 쿼리의 튜닝은 그냥 I/O 보다는 랜덤 I/O를 줄이는 것이 목적이라고 할 수 있다.
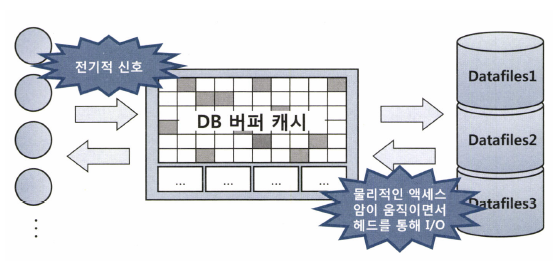
What is DB Buffer Cache?
SQL을 수행하는 과정에서 계속해서 데이터 블록을 읽게 되는데 자주 읽는 블록을 매번 디스크에서 읽어 오는 것은 비효율적이다.
>> 모든 DBMS에 데이터 캐싱 메커니즘이 필수인 이유
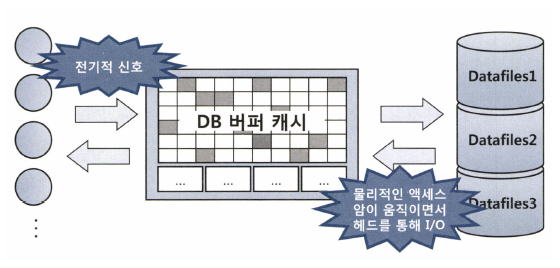
서버 프로세스와 데이터 파일 사이에 존재해서 데이터 블록을 읽을 땐 항상 버퍼 캐시부터 탐색한다.
공유되는 메모리 영역이기 때문에 같은 블록을 읽어야 하는 다른 프로세스도 이득을 보는 경우가 있다.
Memory I/O vs Disk I/O
-
Memory I/O
메인 메모리(RAM)에서 데이터를 읽고 쓰는 작업
디스크에서 한 번 읽힌 데이터는 버퍼 캐시에 적재됨
이후 동일한 데이터를 다시 사용할 때는 디스크가 아닌 메모리에서 즉시 접근
디스크 I/O에 비해서 월등하게 빠름
-
Disk I/O
디스크(HDD / SSD)에서 데이터를 읽고 쓰는 작업
DB 파일, 테이블, 인덱스 등은 기본적으로 디스크에 저장
사용자가 쿼리를 실행하면 해당 데이터를 디스크에서 메모리로 불러오는 과정이 발생
결론적으로 DB 성능 최적화를 위해서 디스크 I/O를 줄여야 함
Logical I/O vs Physical I/O
-
Logical I/O
메모리(버퍼 캐시)에서 데이터 페이지를 읽는 작업
디스크에서 이미 읽혀져 메모리에 올라와있는 페이지를 접근하는 것
인덱스 탐색, 버퍼 풀 조회
-
Physical I/O
디스크에서 데이터 페이지를 직접 읽는 작업
버퍼 풀에 데이터가 없을 때
How to do I/O efficiency?
위에서도 언급했듯이 I/O 튜닝의 핵심은 I/O 요청 횟수를 최소화 하는 데에 있다.
디스크 접근을 줄이고 메모리에 있는 데이터를 최대환 활용해서 처리해야 한다.
-
SQL 최적화
- 필요한 데이터만 읽도록 SQL 설계
- SELECT * 사용은 Full Table Access 가능성을 높이고 I/O 비용 증가로 이어짐
- WHERE 조건 정밀화
-
인덱스를 사용 가능하도록 범위 조건, 비교 연산, 등호 연산 등을 명확히 작성
LIKE ‘%값%’ 등 Prefix가 없는 조건은 인덱스 미사용 → Full Scan 유발
-
- 필요한 데이터만 읽도록 SQL 설계
-
옵티마이저가 최적 경로를 선택할 수 있게 정보 제공
- 전략적 인덱스 설계
- 자주 사용되는 Filter 조건과 Join 조건에 인덱스 생성
- DBMS 기능
- Index : 빠른 검색과 정렬
- Partition : 대용량 데이터를 논리적으로 분리 후 필요한 부분만 접근
- Cluster : 관련 데이터를 물리적으로 근접 배치
- Window Function : 불필요한 서브 쿼리 제거 후 연산 효율성 확보
- 전략적 인덱스 설계
-
통계 정보 최신화
- CBO(Cost-Based Optimizer)는 테이블, 컬럼, 인덱스의 통계 정보를 기반으로 실행 계획 결정
- 통계 정보에는 Row 수, 블록 수, 카디널리티, 히스토그램 등이 포함
- 최신 통계가 없을 경우 옵티마이저가 부정확한 실행 계획 선택!!
-
Full Table Scan 방지를 위한 힌트
- Hint는 SQL 구문 내부에 작성해서 옵티마이저에게 실행 계획을 강제 또는 유도하는 명령
- 힌트는 옵티마이저가 비효율적인 실행 계획을 선택하는 경우에 I/O 비용을 최소화하고 FTS를 회피할 수 있도록 원하는 액세스 경로로 유도하는 유용한 수단
- 하지만 통계 정보와 데이터 분포에 민감하게 반응
- 사용 후 실행 계획 확인 및 유지 관리 필요
Optimizer
Create Query
SELECT (Column) : 작성순서 (1), 실행순서 (5)
FROM (Table) : 작성순서 (2), 실행순서 (1)
WHERE (Table Condition) : 작성순서 (3), 실행순서 (2)
GROUP BY (Column) : 작성순서 (4), 실행순서 (3)
HAVING (Group Condtion) : 작성순서 (5), 실행순서 (4)
ORDER BY (Column) : 작성순서 (6), 실행순서 (6)
실행 순서에 따른 설명
- FROM
- SQL은 쿼리 실행시 접근할 테이블의 유무를 확인하기 위해 가장 먼저 확인
- WHERE
- FROM의 테이블이 존재하면 해당 테이블에서 조건에 맞는 테이블을 추출
- GROUP BY
- 조건에 맞는 데이터가 추출되면 공통 데이터들끼리 그룹 생성
- HAVING
- 그룹화된 데이터들 중, 주어진 조건에 맞는 그룹들을 추출
- SELECT
- 최종적으로 추출된 데이터 조회
- ORDER BY
- 추출된 데이터들을 조건에 맞게 정렬
Query Execution Structure of MySQL
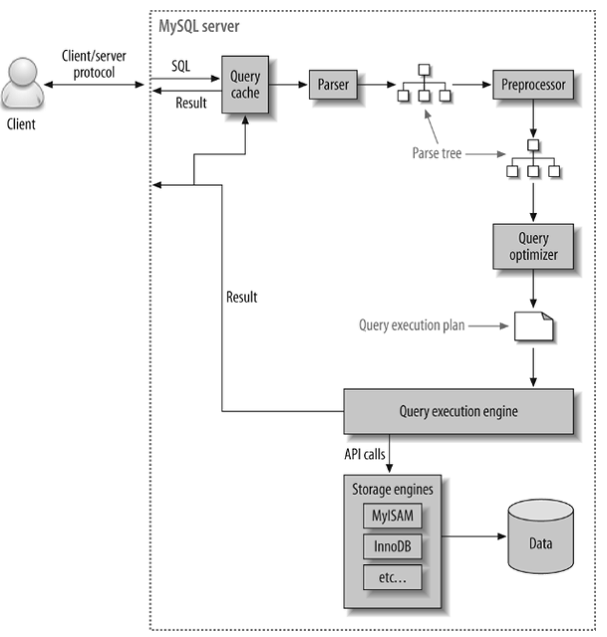
- Query Cache(쿼리 캐시)
- 쿼리의 결과가 저장되어있으며, 동일한 쿼리 요청이 왔을 시에 쿼리 캐시에서 캐싱된 결과를 송신한다.
- Parser(파서)
- 클라이언트가 송신한 쿼리의 기본 문법 오류를 체크한다.
- Parse Tree
- 파서를 통해 문법 오류가 없을 시에, 해당 쿼리 문장을 토큰으로 분해하여 트리 구조로 만든다.
- PreProcessor(전처리기)
- 파서 트리를 기반으로 쿼리 문장에 구조적인 문제점이 있는지 확인하여 테이블 명, 칼럼 명, 내장 함수 등 객체들을 맵핑하여 해당 객체의 존재 여부 및 접근 권한을 확인하는 과정을 수행한다.
- Query Optimizer(옵티마이저)
- 클라이언트가 요청한 쿼리를 최소한의 값으로 가장 빠르게 처리할 지 결정하는 역할을 한다.
- Query Execution engine(실행 엔진)
- 옵티마이저에서 받아온 명령을 핸들러에게 전달하는 역할을 한다.
- Handler API
- 쿼리 실행기에서 데이터를 쓰거나 읽기 위해 스토리지 엔진에게 전송/전달 받는 역할을 한다.
- Storage engines
- 서버 엔진이 필요한 물리적인 데이터를 가져오는 장치로, .frm 파일에 접근하는 속성을 설정한다.
What is Optimizer?
쿼리의 실행 절차 중 parse tree를 기반으로 실행 계획을 세우는 역할을 한다.
자체적인 동작 순서
- 불필요한 조건 제거
- 복잡한 연산 단순화
- 어떤 순서로 테이블을 읽을지 결정
- 어떤 인덱스를 사용할 지 결정
- 임시 테이블을 활용할지 결정
- 실행 계획 생성
종류
-
비용 기반 최적화, CBO(Cost-Based Optimizer)
쿼리를 처리하기 위한 여러 가능한 방법을 만듦
각 단위 작업의 비용(부하) 정보와 대상 테이블의 예측된 통계 정보를 이용해 실행 계획별 비용을 산출
이렇게 산출된 실행 방법 별로 비용이 최소로 소요되는 처리 방식을 선택해 최종적으로 쿼리를 실행
- MySQL이 채택한 옵티마이저
-
규칙 기반 최적화, RBO(Rule-Based Optimizer)
기본적으로 대상 테이블의 레코드 건수나 선택도 등을 고려하지 않음
옵티마이저에 내장된 우선 순위에 따라 실행 계획 수립
통계 정보를 조사하지 않기 때문에 같은 쿼리에 대해서는 거의 항상 같은 실행 방법
- 사용자 데이터는 분포도가 매우 다양해서 이에 대한 경쟁력이 없음
Table Full Scan vs Index Range Scan
-
Table Full Scan
Sequenctial access와 Multiblock I/O 방식으로 디스크 블록을 읽는다.
- 한 블록에 속한 모든 레코드를 한 번에 읽고 캐시에서 못 찾으면 I/O call을 통해 인접한 수십 ~ 수백 개의 블록을 한 번에 I/O 하는 메커니즘
- 큰 테이블에서 소량 데이터를 검색할 때는 비효율적
MySQL 옵티마이저는 다음과 같은 조건일 때 선택
- 테이블의 레코드 건수가 작아서 인덱스를 이용하는 거보다 빠른 경우 (일반적으로 테이블이 페이지 1개로 구성)
- WHERE 절이나 ON 절에 인덱스를 이용할 적절 조건이 없는 경우
- Index Range Scan을 사용할 수 있는 쿼리라고 하더라도 옵티마이저가 판단한 조건 일치 레코드 건수가 너무 많은 경우(인덱스의 B-Tree 샘플링 통계 정보 기준)
-
Index Range Scan
Randomly access와 Single Bloc I/O 방식으로 디스크 블록을 읽는다.
- 캐시에서 블록 레코드를 찾지 못하면 레코드 하나를 읽기 위해 매번 대기 큐에 있어야 하는 I/O 메커니즘
- 따라서 많은 데이터를 읽을 때는 불리
- 읽었던 블록을 반복해서 읽는 비효율적인 측면 존재
병렬, ORDER BY(Index, filesort), GROUP BY, DISTINCT, 내부 임시 테이블, 스위치 옵션, 조인 등의 쿼리 최적화 관련은 후 주차에 정리할 내용이라 그 때 정리할 예정이다.
Query Plan
그래서 Optimzer가 실행 계획을 세운다는 건 알겠는데, 그 근거가 뭔데?
SQL 서버는 쿼리를 최적화 하기 위해 통계를 사용한다.
이 통계는 데이터 분포에 대한 정보를 SQL 서버에 제공하여 효율적인 실행 계획을 생성을 돕는다.
통계는 특히 Index가 있는 컬럼이나 WHERE 절에서 자주 사용되는 컬럼에서 중요한 역할을 한다.
잘못된 통계는 부적절한 실행 계획을 생성할 수 있고 성능 저하를 야기할 수 있다.
What is Statistics?
SQL 서버의 통계는 특정 컬럼에 대한 데이터 분포를 나타낸다.
이를 통해 쿼리 최적화 도구는 쿼리 실행 시 가장 효율적인 접근 방식을 선택할 수 있다.
통계는 주로 히스토그램과 밀도 정보로 구성됩니다.
- 히스토그램
- 해당 컬럼의 값 분포를 보여주며, SQL 서버가 데이터의 범위와 중복도를 예측하는 데 도움을 준다.
- 밀도 정보
- 해당 컬럼의 고유 값에 대한 정보를 제공한다.
- 인덱스를 사용할 때 도움이 된다.
통계는 주로 다음 두 가지 방식으로 생성
- 자동 통계 생성
- SQL 서버는 기본적으로 필요할 때 자동으로 통계를 생성한다.
- 수동 통게 생성
- 특정 요구 사항이 있는 경우, 사용자가 직접 통계를 생성할 수 있다.
How Statistics affect to Query Plan?
- 적합한 인덱스 선택
- 통계는 인덱스 선택을 돕고, 잘못된 통계는 부적절한 인덱스를 선택하게 한다.
- 조인 순서 및 방식 결정
- SQL 서버는 통계 정보를 통해 테이블 간의 조인 순서와 방법을 결정한다.
- 최적의 실행 계획 생성
- 통계는 쿼리에서 특정 조건에 따라 가장 효율적인 실행 계획을 수립하는 데 사용된다.
예시
만약 통계가 부정확하거나 최신화되지 않은 경우
- SQL 서버는 데이터가 적다고 잘못 판단해서 풀 테이블 스캔을 선택할 수 있다.
- 하지만 실제 데이터가 매우 클 수 있으며 성능 저하로 이어질 수 있다.
Statistics Management
- 자동 통계 기능 활성화
- 기본적으로 SQL 서버는 통계를 자동으로 생성 및 업데이트 한다.
- 수동 통계 업데이트
- 대규모 데이터 변경이 발생한 경우, 수동으로 통계를 업데이트하여 최적의 쿼리 실행 계획을 보장할 수 있다.
- 통계 확인
- sys.stats와 같은 시스템 뷰를 통해 현재 테이블의 통계 정보를 확인할 수 있다.
