[MySQL] Index

인덱스란 무엇인가?
핵심 정의
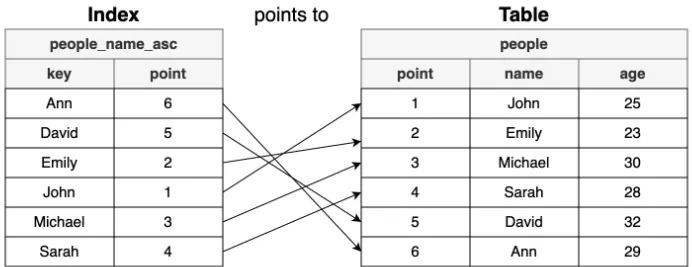
데이터를 정렬된 상태로 관리하는 별도 구조(B-Tree 등)
본 데이터는 순서 상관 없이 저장되고 Index는 설정한 순서에 따라 정렬된 key - value 쌍을 만들어둠
느린 I/O를 줄이기 위해 최소한의 정보만 모아둔 찾기 전용 구조
장단점
| 장점 | 단점 |
|---|---|
| SELECT가 매우 빨라짐 | INSERT/UPDATE/DELETE 성능 저하 |
| 정렬/범위 검색 성능 향상 | 인덱스 생성·유지 비용 발생 |
| 옵티마이저의 다양한 최적화 기법 사용 가능 | 인덱스를 너무 많이 만들면 전체 성능 망가짐 |
인덱스는 읽기 성능을 위해 쓰기 성능을 희생하는 구조이다.
웹 서비스에서는 조회가 압도적으로 많기 때문에 인덱스를 잘 설계하는 것이 필수
인덱스 종류
PK 인덱스
- PRIMARY KEY는 자동으로 유니크 + NOT NULL + 인덱스가 생성됨
- 테이블의 대표 식별자
Secondary Index
- PK를 제외한 모든 인덱스
- 조회 최적화를 위해 사용하는 대부분의 인덱스
유니크 인덱스
- 중복 금지
- 성능적으로 PK와 거의 동일
- 하지만 쓰기 시 중복 체크 때문에 느림
주의
유니크 인덱스 + 일반 인덱스를 같은 컬럼에 둘 다 만들면 중복이다
→ 하나만 쓰기
인덱스 저장 방식별 분류
B-Tree 인덱스 (가장 일반적)
- MySQL/InnoDB 기본 인덱스
- 값이 변형 없이 정렬된 상태로 저장된다.
- 리프 노드에는 → 실제 데이터 위치(또는 PK) 저장
Hash 인덱스
- Key → Hash → Value
- 매우 빠른 검색(=O(1))
- 하지만 범위 검색 불가
- 메모리 기반 DB(예: Redis)에서 적합
R-Tree (공간 인덱스)
- 2D 공간 데이터 (위도·경도) 검색용
- GIS, 지도서비스 등에 사용 (반경 5km 검색 등)
전문(Full-text) 인덱스
- 문서 내용 전체를 인덱싱
- MATCH AGAINST 사용
- 형태소 분석(MeCab) 또는 n-gram 기반
함수 기반 인덱스 (MySQL 8.0+)
- CONCAT(), LOWER() 같은 함수 결과물에 인덱스 생성 가능
- 컬럼 변형 후 검색하는 경우 필수
멀티 밸류 인덱스(JSON)
- JSON 배열 하나에 여러 인덱스 키를 매핑 가능
JSON_CONTAINS()같은 함수와 함께 사용
B-Tree 구조의 핵심 이해
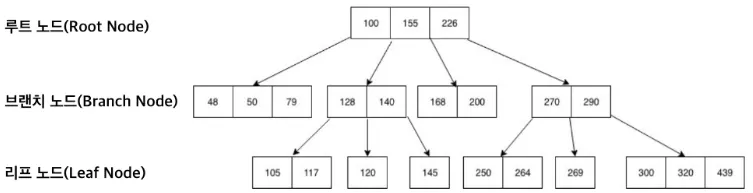
B-Tree(Balanced Tree)는 이진 트리를 확장하여 N개의 자식을 가질 수 있도록 고안됨
좌우 자식 간 균형이 맞지 않으면 매우 비효율적이어서 항상 균형을 맞춰야 함
- 루트 노드
- 브랜치 노드 (중간)
- 리프 노드 (실제 데이터 위치 보유)
리프 노드만 실제 데이터 주소(PK or 물리주소)를 가진다.
MySQL/InnoDB의 중요한 차이
- MyISAM
- 리프 노드 = 실제 물리적 주소
- 바로 데이터 접근 가능
- InnoDB
- 리프 노드 = PK 값
- → PK 인덱스를 한 번 더 검색해야 실제 데이터 접근 가능
- 즉, Secondary Index는 2번 접근 필요
이게 느려보이지만 장점도 존재한다 → 아래 클러스터링 인덱스에서 설명.
인덱스가 필요한 이유
인덱스를 사용하면 조회가 빠른 이유
인덱스 사용 시 수행되는 동작은 단순히 두 가지이다.
- 인덱스를 탐색하여 PK를 찾고
- PK를 통해 실제 레코드를 읽는 것
이 두 단계는 B-Tree 깊이에 비례하여 매우 적은 수의 I/O로 처리된다.
인덱스 조회 비용이 4~5배 큰 이유
DBMS는 옵티마이저의 판단을 위한 비용(cost) 모델을 갖고 있음
- 인덱스 조회 = 랜덤 I/O 다량 발생
- 테이블 스캔 = 순차 I/O (매우 빠름)
| 작업 | 비용 |
|---|---|
| 테이블에서 연속된 데이터 1건 읽기 | 비용 1 |
| 인덱스로 1건 읽기 | 비용 4~5 |
랜덤 I/O가 순차 I/O보다 훨씬 비싸기 때문
그럼에도 인덱스를 쓰는 이유
인덱스가 없다면
- 원하는 값이 어디 있는지 모르므로
- 전체 테이블(full scan) 을 모두 읽어야 한다
레코드가 수십만 건만 되어도 이 작업은 매우 느리다.
소수의 레코드를 찾는 경우 → 인덱스 압도적 승리
많은 레코드를 읽는 경우 → 테이블 스캔 승리
언제 인덱스를 안 쓰는 게 더 빠른가?
일반적으로 다음과 같은 기준을 사용
조회해야 하는 레코드가 전체의 20~25% 이상이면
인덱스를 타지 않고 테이블 스캔이 더 빠르다.
인덱스 성능에 영향을 주는 주요 요소
PK의 크기
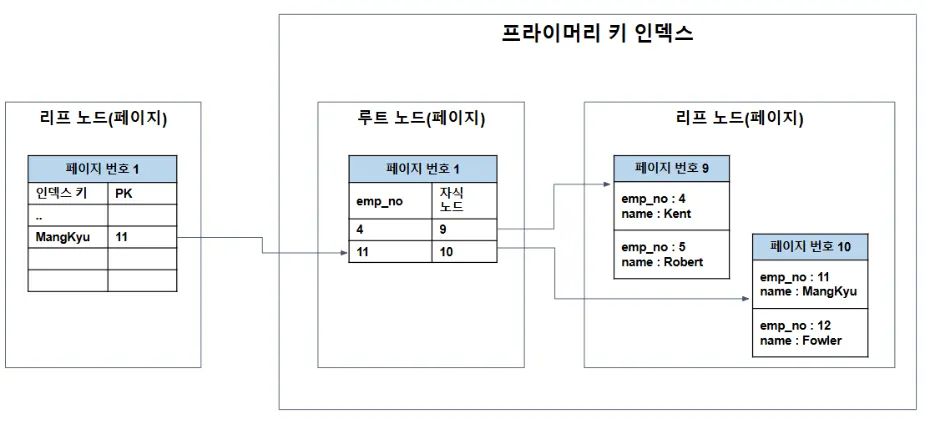
InnoDB는 클러스터링 인덱스를 사용하기 때문에
세컨더리 인덱스는 레코드 주소가 아닌 PK 값을 저장한다.
PK가 길면 생기는 문제
- 세컨더리 인덱스 크기 증가
- 한 페이지에 들어가는 키 개수 감소
- 트리 깊이가 증가 → 탐색 비용 증가
- 버퍼 풀 캐싱 효율 하락
해답
- PK는 짧고 단순한 값이 이상적
- 자연키(이메일, 주민번호 등)는 PK로 적합하지 않음
- 대부분 AUTO_INCREMENT 또는 UUID(압축형)를 사용
다중 컬럼 인덱스의 컬럼 순서
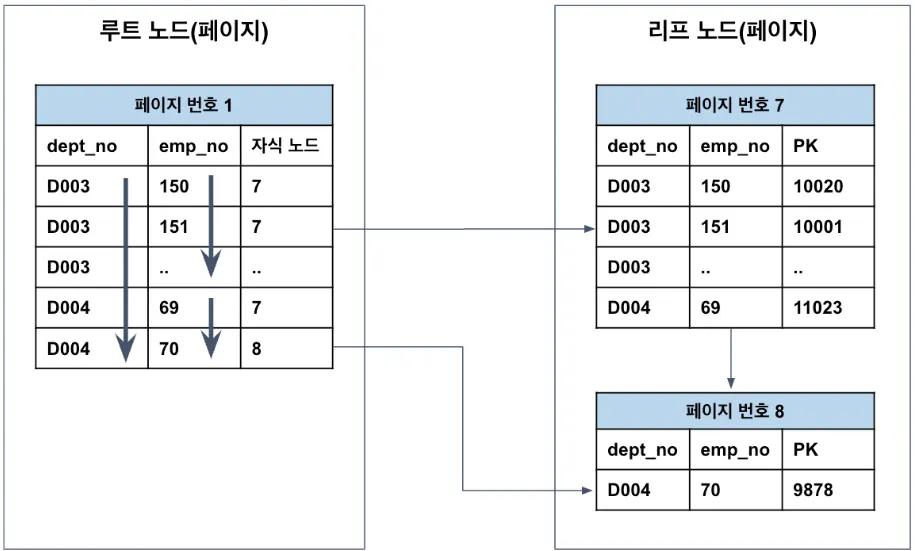
다중 컬럼 인덱스는 다음 원칙을 반드시 기억해야 한다.
왼쪽 → 오른쪽 순서로 정렬되며, 오른쪽 컬럼은 왼쪽 컬럼에 의존한다
INDEX idx (dept_no, emp_no)이 인덱스로 가능한 조건
- dept_no = ‘D003'
- dept_no = 'D003' AND emp_no = '150'
이 인덱스로 불가능한 조건
- emp_no = '150' (왼쪽 컬럼 누락 → 정렬 의미 없음)
다중 컬럼 인덱스 설계 = WHERE 조건의 등 값 조건 순서대로 배치
카디날리티(Cardinality)
카디날리티 = 컬럼의 유니크한 값 개수
- 유니크 값 많음 → 카디날리티 높음 → 인덱스 효율 Good
- 유니크 값 적음 → 카디날리티 낮음 → 인덱스 효율 Bad
예)
- 성별(M/F): 카디날리티 = 2 → 인덱스 의미 거의 없음
- 이메일: 카디날리티 매우 높음 → 인덱스 훌륭함
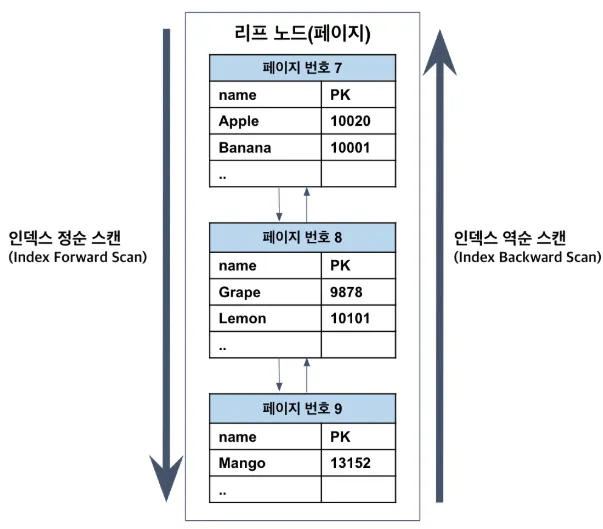
인덱스 정렬 및 스캔 방향
인덱스는 정렬되어 저장된다
인덱스 생성 시
INDEX idx (dept_no ASC, emp_no DESC)이렇게 방향을 지정해도
MySQL은 실행 계획에 따라 오름/내림차순으로 자유롭게 역순 스캔 가능하다.
정순 스캔 vs 역순 스캔
- 정순 스캔: 가장 빠름 (기본 구조가 정순에 최적화)
- 역순 스캔: 가능하지만 느림
이유
- 페이지 잠금 구조가 정순 기준으로 최적화됨
- 리프 노드의 페이지는 이중 연결 리스트로 되어 있음
- 페이지 잠금 과정에서 데드락을 방지하기 위한 잠금을 획득 하는 것이 정순에서만 가능하고 역순은 복잡한 과정 필요
- 페이지 내부 인덱스 레코드 연결이 단방향
- 페이지 내부에서 순차적으로 4~8개 정도씩 묶어서 그룹을 만듦
- 그리고 그룹의 대표키를 선정해서 리스트로 관리, Page Directory
- 페이지 디렉토리가 단방향 연결이라 역방향 접근이 불가능 → 역방향 이동 시 오버헤드 증가 https://tech.kakao.com/posts/351
B-Tree 인덱스 유지 비용
B-Tree 인덱스는 항상 정렬된 상태를 유지해야 하는 구조
따라서 레코드의 추가(INSERT), 삭제(DELETE), 수정(UPDATE) 시 인덱스에도 즉각 반영되어야 하며, 이 과정에서 상당한 디스크 I/O가 발생
레코드 추가(INSERT)
레코드가 추가되면 인덱스에서도 다음 작업 수행
(1) 인덱스는 항상 정렬 유지
즉시 B-Tree 내부에서 적절한 위치를 찾아 저장
그래서
- 레코드 추가 비용 = 1
- 인덱스 1개 추가 비용 ≈ 1.5 이렇게 가정할 수 있다.
인덱스가 3개면
레코드 작업 비용 = 1 + (1.5 × 3) = 5.5→ 디스크 작업이므로 비용이 매우 크다.
(2) Insert Buffer(변경 버퍼: Change Buffer)를 통한 지연 처리
MyISAM / MEMORY 엔진은 즉시 인덱스를 업데이트
InnoDB는 일부 인덱스(유니크 X)에 대해 변경을 지연시키는 메커니즘
장점
- 디스크 쓰기 횟수 감소
- 트랜잭션 응답 시간이 짧아짐
- 여러 변경을 모아서 한 번에 반영
단점
- 유니크 인덱스는 지연 불가 → 중복 여부 검사 때문에 즉시 인덱스를 확인해야 함.
(3) 유니크 인덱스는 작업 비용이 훨씬 크다
유니크 인덱스는 저장 시:
- 중복 값 있는지 인덱스에서 찾음(읽기 락)
- 없으면 저장(쓰기 락)
- 이 과정에서 데드락 발생 빈도가 매우 높음
그래서 유니크 인덱스는 정말 필요한 경우가 아닌 이상 남발하면 절대 안 된다.
(4) 페이지 분할(Page Split)
리프 노드(페이지)가 꽉 차 있으면
- 페이지를 둘로 쪼갬 (Split)
- 상위 브랜치 노드의 포인터도 변경해야 함
→ 이 과정은 디스크 I/O를 여러 번 발생시키므로 INSERT가 매우 느려질 수 있음
레코드 삭제(DELETE)
(1) 인덱스에선 실제 삭제가 아니라 삭제 마킹
레코드는 테이블에서 제거되지만,
인덱스에서는 리프 노드에 삭제 플래그만 붙인다.
삭제 마킹의 특징
- 디스크 쓰기 I/O 발생
- 삭제된 인덱스 공간은 재활용하거나 방치할 수 있음
- 즉시 정리하지 않는 경우도 많음 (내부적으로 청소됨)
(2) DELETE는 적절한 인덱스를 사용하지 않으면 매우 위험
InnoDB의 잠금 메커니즘 특성상
UPDATE/DELETE는 검색에 사용된 인덱스를 기준으로 잠금을 건다.
WHERE 절에서 인덱스를 사용하지 않으면
넥스트 키 락 / 갭 락이 광범위하게 걸리면서 불필요하게 많은 레코드를 잠그게 됨
심하면 테이블 전체 잠금 같은 상황이 발생
→ DELETE/UPDATE에는 반드시 적절한 인덱스가 필요함.
레코드 수정(UPDATE)
UPDATE는 사실상 다음과 동일
UPDATE = DELETE + INSERT
아래 3 종류의 컬럼에 따라 부담이 다름
(1) PK(Primary Key) 수정
절대로 하면 안 되는 작업
PK가 바뀌면
-
기존 PK 인덱스에서 삭제
-
새로운 PK 추가
-
세컨더리 인덱스에는 PK가 저장되므로,
모든 세컨더리 인덱스도 함께 업데이트해야 함
결과
- 디스크 I/O 폭증
- 페이지 스플릿 가능성 증가
- 잠금 경쟁 증가
PK를 변경하는 UPDATE는 최악의 성능을 가진다.
(2) 인덱스 컬럼 수정
이 경우도 DELETE + INSERT처럼 동작하므로 비용이 큼
- 기존 인덱스 항목 삭제
- 새로운 값으로 인덱스 항목 새로 삽입
- 정렬 유지해야 하므로 위치 탐색 및 페이지 분할 가능
가능하면 인덱스 컬럼은 변경을 최소화해야 한다.
(3) 일반 값(비인덱스 컬럼) 수정
가장 비용이 적음
- 인덱스 변경 필요 없음
- 테이블 레코드만 갱신하면 끝
레코드 검색(READ)
(1) PK 검색 (가장 빠른 검색 방법)
InnoDB는 클러스터링 인덱스 구조를 사용한다.
PK가 곧 레코드의 실제 저장 위치를 결정하는 키
(리프 노드에 PK와 레코드가 함께 저장됨)
동작 과정
- PK B-Tree 트리 탐색
- 리프 노드에서 바로 레코드 획득
특징
- 트리를 1번만 탐색하면 끝
- 랜덤 I/O도 최소
- 가장 빠르고 효율적인 검색 방식
예시
SELECT * FROM member WHERE id = 10;(2) Secondary Index 검색 (빠르지만 PK보다 한 단계 추가 비용 존재)
Secondary index의 리프 노드에는 실제 레코드가 아닌 PK가 저장된다.
(인덱스 키, PK) 형태
따라서 레코드를 찾기 위해서는 두 단계가 필요하다.
동작 과정
- 인덱스 B-Tree에서 조건에 맞는 PK 찾기
- 찾은 PK를 이용해 PK B-Tree를 다시 탐색
- 리프 노드에서 레코드 읽기
→ 트리를 2번 탐색해야 하므로 PK보다 비용이 더 든다.
특징
- 그래도 매우 빠름(정렬·트리 기반 탐색)
- 범위 검색, 정렬에 특히 강함
- 조건절이 인덱스를 잘 타도록 설계하는 것이 매우 중요
유니크 인덱스는 더 빠르다?
- 유니크 인덱스는 1건만 찾으면 끝이라는 힌트를 옵티마이저에게 제공
- CPU 레벨 비교 작업이 줄어들어 미세하게 빠름
- 단, 체감할 만큼 큰 차이는 아님
(3) 인덱스를 사용하지 않는 검색 (Full Table Scan)
인덱스가 없다면 DB는 데이터가 어디 있는지 전혀 모르므로
테이블의 모든 레코드를 처음부터 끝까지 검사해야 한다.
이것을 테이블 풀 스캔이라고 한다.
발생 케이스
- WHERE 절이 인덱스를 타지 못하는 경우
- LIKE '%text%'
- 함수/연산 적용된 컬럼
- 자료형 변환이 필요한 비교
- 다중 컬럼 인덱스에서 선행 컬럼 불사용
- 인덱스 자체가 없는 컬럼
특징
- 레코드 1건 찾는 데도 수천~수백만 건을 읽을 수 있음
- 디스크 I/O 폭발 → 매우 느림
- UPDATE/DELETE 시에는 잠금 범위가 테이블 전체로 번짐
- 대량 트래픽 환경에서는 치명적
(4) 어떤 검색은 인덱스를 사용할 수 없는가?
B-Tree는 왼쪽부터 정렬되어 있으므로 아래 방식은 인덱스를 사용할 수 없다.
뒷부분 검색
WHERE name LIKE '%park%'컬럼에 연산 / 함수 적용
WHERE DATE(created_at) = '2024-01-01'자료형 변환이 필요한 비교
WHERE phone = 01012341234 -- 문자열 vs 숫자 비교다중 컬럼 인덱스에서 선행 컬럼 누락
인덱스 (A, B)에 대해
WHERE B = 10 -- 인덱스 미사용인덱스 접근 방식
인덱스 레인지 스캔 (Index Range Scan)
가장 이상적인 인덱스 사용 방식
→ 인덱스 조건으로 범위가 명확하게 정해진 경우 사용
SELECT * FROM employee
WHERE name BETWEEN 'Lemon' AND 'Mango';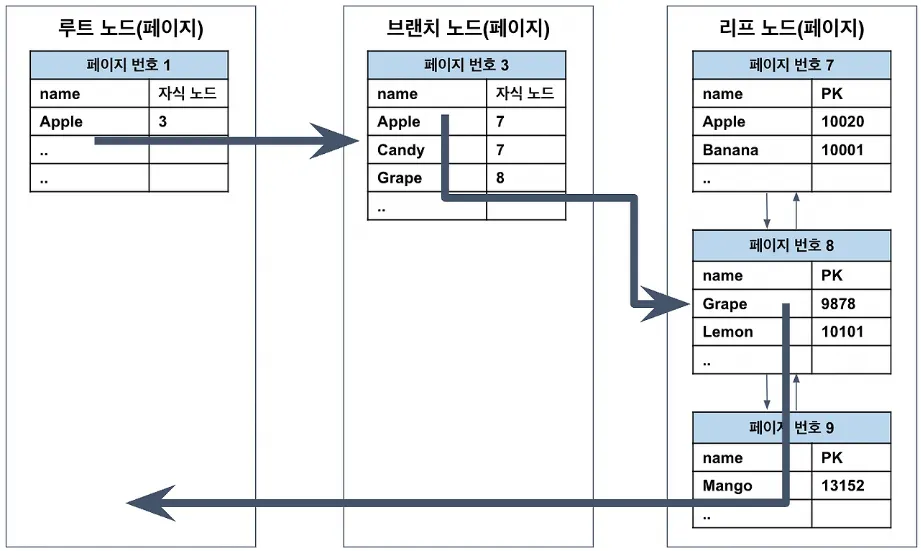
작동 흐름
-
인덱스 탐색(Search)
루트 → 브랜치 → 리프 노드를 따라
Lemon이 시작되는 위치까지 찾아감.
-
인덱스 스캔(Scan)
시작점부터 Mango까지 정렬된 순서대로 연속 읽기
(리프 노드는 정렬되어 있고, 페이지 간 링크 존재)
-
랜덤 I/O
인덱스가 PK를 가지고 있으므로
→ PK로 실제 레코드를 테이블에서 읽어옴.
커버링 인덱스면 더 빠름
- 쿼리가 인덱스에 있는 컬럼만 읽으면 테이블을 보지 않음
- → 디스크 랜덤 I/O 0
- → 매우 빠름
특징
- 가장 빠른 인덱스 방식
- 범위 검색, 정렬, 부등호 등에서 활용
- 테이블 접근은 랜덤 I/O이므로 너무 많은 레코드를 읽으면 비효율적
인덱스 풀 스캔 (Index Full Scan)
인덱스를 처음부터 끝까지 순차적으로 읽는 방식
- 조건절이 인덱스 선행 컬럼을 사용하지 않는 경우
(인덱스가 (A, B)인데 WHERE B=… 로 검색하는 경우)- COUNT(*) 처럼 테이블 전체를 읽지만 PK/인덱스만으로 처리 가능한 경우
SELECT COUNT(*) FROM employee;특징
- 테이블 풀 스캔보다 빠름 → 인덱스는 테이블보다 훨씬 가벼운 구조이므로
- 하지만 레인지 스캔보다 느림
루스 인덱스 스캔 (Loose Index Scan)
인덱스 중 필요한 부분만 건너뛰며 듬성듬성 읽는 방식
GROUP BY 최적화에 아주 자주 등장한다.
SELECT dept_no, MIN(emp_no)
FROM dept_emp
WHERE dept_no BETWEEN 'D002' AND 'D004'
GROUP BY dept_no;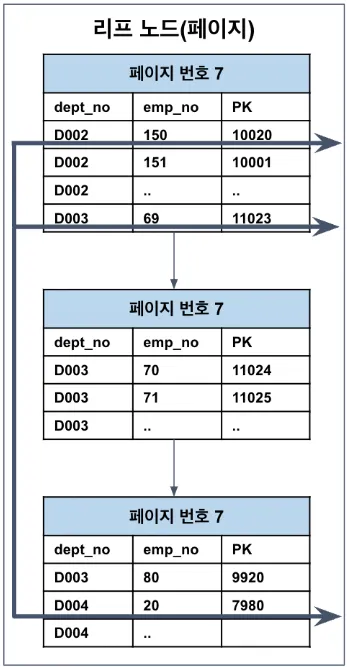
왜 가능한가?
- D002 → 첫 번째 emp_no만 읽음
- D003 → 첫 번째 emp_no만 읽음
- D004 → 첫 번째 emp_no만 읽음
중간 값들은 불필요한 값이므로 건너뛰어도 됨
특징
- GROUP BY, MIN(), MAX() 최적화에 사용
- 인덱스의 정렬 특성을 활용
- 타이트 스캔(모든 인덱스를 읽는 스캔)과 반대 개념
인덱스 스킵 스캔 (Index Skip Scan) — MySQL 8.0+
선행 인덱스 컬럼이 WHERE 절에 없어도
자동으로 인덱스를 사용할 수 있게 하는 기능
기존에는 불가능했던 케이스
인덱스가 (gender, birth_date)일 때
SELECT * FROM employee
WHERE birth_date >= '1994-12-26';→ gender 조건이 없으므로 인덱스 사용 불가
MySQL 8.0의 스킵 스캔 작동 방식
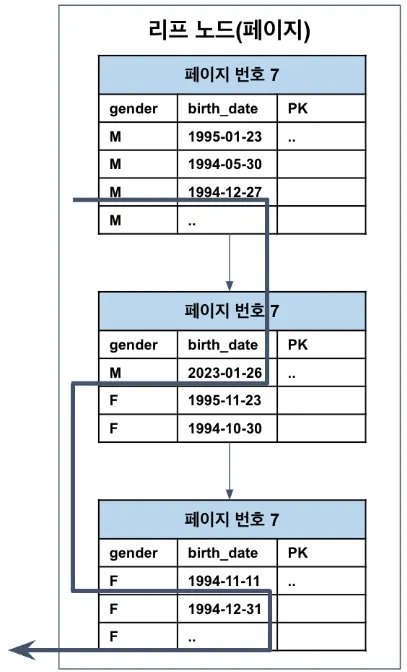
옵티마이저가 내부적으로 쿼리를
gender = 'M'
birth_date >= …
gender = 'F'
birth_date >= …이렇게 두 번 실행하는 것처럼 최적화하여 인덱스를 사용
인덱스 스킵 스캔 조건
다음 3개를 반드시 만족해야 한다.
- 조회되는 컬럼이 인덱스만으로 처리 가능(커버링 인덱스)
- 인덱스 선행 컬럼이 WHERE 절에 없음
- 선행 컬럼의 카디널리티가 낮아야 함
- 즉, gender처럼 값 종류가 적은 컬럼이어야 함
- 값이 너무 많으면 스킵 스캔 오히려 비효율
특징
- MySQL 8.0 이후 사용 가능
- 완벽한 최적화는 아니기에 제한적
- 선행 컬럼 조건 없이 인덱스를 활용할 수 있다는 큰 장점
인덱스 사용 시의 주의사항
인덱스는 SELECT뿐만 아니라 UPDATE / DELETE에도 쓰인다
그리고 UPDATE/DELETE에선 인덱스가 더 중요
검색에 사용된 인덱스 범위 전부 잠금
인덱스를 못 쓰면 불필요하게 많은 레코드를 잠그게 됨
심하면 테이블 전체 Lock 수준으로 번짐
변경 작업(UPDATE, DELETE)에는 반드시 적절한 인덱스가 필요
인덱스는 “값이 변형되는 경우” 사용할 수 없음
아래는 인덱스 타지 못함
- 함수 사용
- 컬럼 일부만 사용 (
SUBSTRING(name,1,3)) - 후방 검색 (
LIKE '%abc') - 형변환으로 인덱스 타입 변경
정렬된 인덱스의 순서(정렬 효과)를 활용할 수 없기 때문
인덱스는 정순 스캔이 가장 빠르다
MySQL B-Tree는 내부적으로
- 페이지 간 연결 구조
- 페이지 내부 단방향 디렉토리
- 데드락 방지를 위한 정순 락 획득 방식
때문에
정순(Index Forward Scan)이 가장 빠르게 동작한다.
역순(Index Backward Scan)도 가능하지만
구조적 한계 때문에 상대적으로 느리다.
인덱스를 무조건적으로 많이 만들면 오히려 성능 저하
인덱스는 읽기를 빠르게 해주지만,
쓰기(INSERT, UPDATE, DELETE)는 더 비싸진다.
- 인덱스는 항상 정렬된 상태 유지
- 수정 시 B-Tree 위치 조정
- 페이지 Split / Merge 발생 가능
- 디스크 I/O 증가
인덱스 1개 추가 = INSERT 비용 +1.5
인덱스 3개 있는 테이블 = INSERT 비용 약 5.5배 증가
실제로 사용되는 WHERE 조건, JOIN, ORDER/GROUP BY에만 인덱스 생성해야 한다.
커버링 인덱스는 매우 빠르다
쿼리가 인덱스 내부 정보만으로 처리되면(리프 노드에서 끝나면)
→ PK lookup(랜덤 I/O)이 필요 없음
SELECT emp_no FROM employee WHERE name = 'Kim';인덱스가 (name, emp_no) 형태라면 테이블까지 안 가도 됨.
다중 컬럼 인덱스 (Composite Index)
INDEX (A, B, C)
정렬 순서
A → A 같은 값에서 B → B 같은 값에서 C
인덱스가 효율적으로 사용되기 위한 조건
- 반드시 선행 컬럼부터 사용해야 함
- 즉, B 또는 C 단독 조건으로는 사용 불가 (Skip Scan 예외)
B는 필터 조건일 뿐 검색 범위를 줄이지 못한다
INDEX (A, B) 인데
WHERE B = ? AND A = ? 로 검색한다면 → 비효율
A 정렬 기반 구조를 깨기 때문
클러스터링 인덱스 (InnoDB 전용)
InnoDB에서 테이블 자체가 PK 인덱스를 기준으로 B-Tree 구조로 저장
- 테이블 데이터는 PK 기준으로 물리적으로 정렬됨
- 하나의 클러스터링된 구조
장점
- PK 기반 검색/범위 검색 매우 빠름
- 모든 세컨더리 인덱스가 PK를 보유 → 커버링 인덱스 활용 가능
단점
- PK가 클 경우 → 모든 인덱스 크기 증가
- PK 변경 시 레코드 재배치 필요 → 매우 느림
- INSERT 속도도 PK값에 따라 성능 차이 발생
PK 선정 팁
- 반드시 PK 생성 (안 하면 InnoDB가 내부적으로 만든 숨은 PK 사용)
- PK는 짧고 변하지 않는 값이 좋다 (INT, BIGINT auto increment)
- 자연키가 길면 인조키(AI)를 PK로 사용하고 자연키는 Unique Index로 따로 관리하는 것이 좋음
외래키 + 인덱스
외래키가 걸리면 인덱스가 자동 생성되는 이유
외래키(FK)는 부모 테이블의 PK를 참조하는 제약 조건이다.
FK 제약이 존재하면 DBMS는 반드시 FK 컬럼에 인덱스를 만든다.
이유 : FK 제약 검증이 매우 느려지는 것을 방지하기 위해
자식 테이블에서 부모 테이블을 참조할 때,
데이터 추가·수정·삭제 시 매번 참조 일관성을 검사해야 한다.
INSERT INTO orders (user_id, ...) VALUES (3, ...);DB는 이렇게 체크
user_id = 3이 parent 테이블에 존재하는지 검사- 존재하지 않으면 에러 (참조 무결성 위반)
여기서 user_id에 인덱스가 없으면?
→ 매번 테이블 풀 스캔
→ 성능 폭발적으로 저하
→ 수십~수백만건이면 사실상 불가능
그래서 DBMS는 보호 차원에서 자동으로 인덱스를 생성해준다.
외래키는 삭제를 막는다 (ON DELETE RESTRICT)
외래키가 존재하면 부모 테이블의 레코드를 마음대로 삭제할 수 없다.
DELETE FROM user WHERE id = 3;user_id = 3 을 참조하는 자식 레코드가 있다면?
→ DB는 무결성 깨짐을 막기 위해 삭제를 거부한다.
이는 외래키 설계 이유 자체가
참조 무결성을 깨뜨리는 연산을 차단하기 때문
해결 방법
ON DELETE CASCADE→ 부모 삭제 시 자식 자동 삭제
ON DELETE SET NULL→ 부모 삭제 시 FK null로 변경
- 참조 중인 레코드를 먼저 삭제
외래키가 성능 문제를 일으키는 대부분의 이유 = 쓰기 잠금 경합(lock contention)
외래키는 읽기 성능 문제가 아니라, 거의 100% 쓰기(write)에서 문제를 발생시킨다.
이유 : 부모/자식 테이블 모두에 락(Lock)이 걸림
INSERT, UPDATE, DELETE 같은 변경 작업이 일어나면
InnoDB는 FK 무결성을 보장하기 위해 양쪽 테이블에 잠금을 건다.
(1) INSERT 시 락이 걸리는 이유
INSERT INTO orders (user_id, ...) VALUES (3, ...)DB는 다음 작업을 수행한다:
- parent(user) 테이블에서
id = 3검색 - 해당 레코드에 공유 락(Shared Lock) 획득
- FK 검사 완료 후 해제
만약 동시에 여러 INSERT가 parent를 조회하면
같은 레코드에 공유 락들이 몰리고
경합이 발생한다.
(2) DELETE/UPDATE는 훨씬 더 심각한 락 발생
부모 테이블을 수정하는 순간,
DB는 FK가 걸린 자식 테이블을 잠그거나 검사해야 한다.
DELETE FROM user WHERE id = 3;user_id = 3 이 orders 테이블에서 참조 중이라면
- orders 테이블에 레코드 잠금 발생
- FK 검사로 인해 자식 테이블이 광범위하게 잠길 수 있음
- 대량 트래픽 환경에서는 대기열 증가 → 데드락 빈번
특히 인덱스가 없는 FK는 지옥
외래키 컬럼에 인덱스가 없으면?
- 자식 테이블 전체 스캔 (lock + full scan)
- 모든 row에 잠금
- 동시성 완전 붕괴
- 데드락 난무
→ 그래서 MySQL은 FK에 인덱스를 강제하는 것이다.
외래키가 성능 저하를 일으키는 대표 사례
DELETE parent 시 자식 존재 여부 검사하는 과정에서 경합 발생
부모 테이블에서 삭제가 거의 불가능해짐.
자식 INSERT 시 부모 키 유효성 검사로 인해 parent 락 경합
트래픽 높은 서비스는 parent 테이블에 요청이 몰림.
많은 FK가 걸린 스키마는 병목이 발생하기 쉽다
테이블 간 의존성이 많아질수록 업데이트/삭제가 전체 DB 락 트리를 흔들어댄다.
그래서 대규모 서비스에서는 FK를 일부러 안 쓰는 경우도 많음
트위터, 페이스북, 우버 같은 초대형 서비스들은
DB 성능과 확장성 때문에 FK를 실제 운영에서는 거의 사용하지 않는다.
대신
- 애플리케이션 레벨에서 무결성 관리
- Soft delete 도입
- FK 대신 인덱스 + 비즈니스 로직으로 무결성 유지
