009일차 - Pandas
Pandas란?
- Panel Data System에서 명칭이 유래되었다.
- numpy 기반 라이브러리로, numpy의 기능을 사용할 수 있다. (브로드캐스트 등)
🔗Pandas_Cheat_Sheet - Irv Lustig
iloc & loc
loc은 label 값으로 접근,iloc은 index 기준으로 접근pd.dataframe.loc[]은 슬라이싱 할때 start, end 모두 포함- 보통 값을 통해 인덱스 접근 ex) 불리언 인덱싱
iloc은 end 포함 안함
groupby
- 데이터프레임에서 고유값을 가지는 열(PK)을 포함하여
groupby하면 더 이쁘게 볼 수 있다.
df.groupby(['class', 'id'])[['score']].first()💡위의 score에 해당하는 열을 선택하는 부분에서 리스트를 넘기면 데이터프레임을, 문자열을 넘기면 시리즈를 반환한다.
형변환 및 함수 적용
- numpy의
.astype()메서드로 시리즈의 자료형을 변환할 수 있다. - 문자열로 표현된 날짜~시간 데이터를 Python 날짜 자료형으로 변환할 수 있다.
# astype 이용
df['date'].astype('datetime64[ns]')
# pandas 모듈 이용
pd.datetime(df['date'])- 시리즈 객체에
시리즈.자료형.메서드()형태로 전체 열에 함수(메서드)를 적용할 수 있다. - 이 때, 함수가 ufunc이라면 브로드캐스팅되어 실행속도가 빠르다.
# 문자열 자료형 시리즈인 name 열에 대하여 각 요소의 길이 반환
df['name'].str.len()
# datetime 자료형 시리즈인 date 열에 대하여 각 요소의 연도 반환
df['date'].dt.year # datetime 자료형의 year attribute에 접근
# 요일명을 한국어로 반환
df['date'].dt.day_name('korean')🔗[Pandas] Series.dt 사용하기 (날짜, 요일 등) - 시꾸러
melt
- tidy한 데이터프레임를 녹여 아래로 길게 만드는 메서드이다.
- 촛대에서 촛농이 떨어지는 것에서 명칭이 유래되었다.
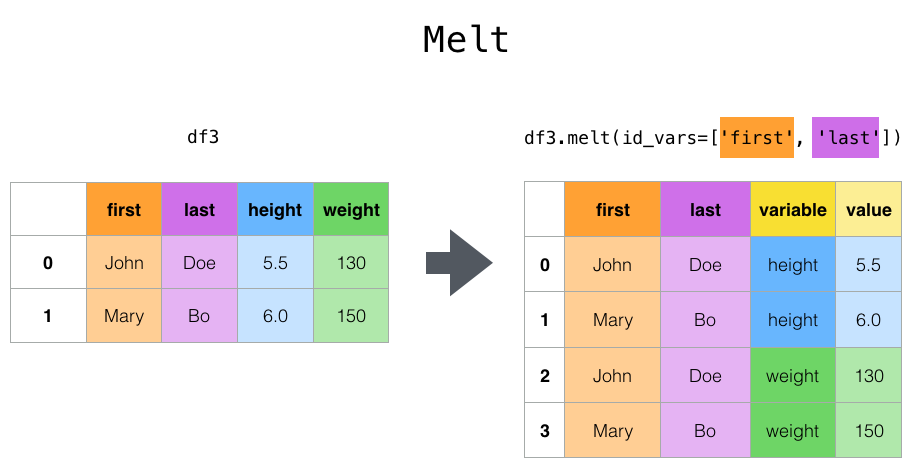
df3.melt(id_vars=['first', 'last']).groupby('variable')['value'].mean()💡위의 코드예제처럼 melt된 경우 groupby로 통계량을 구하기 더 용이해진다.
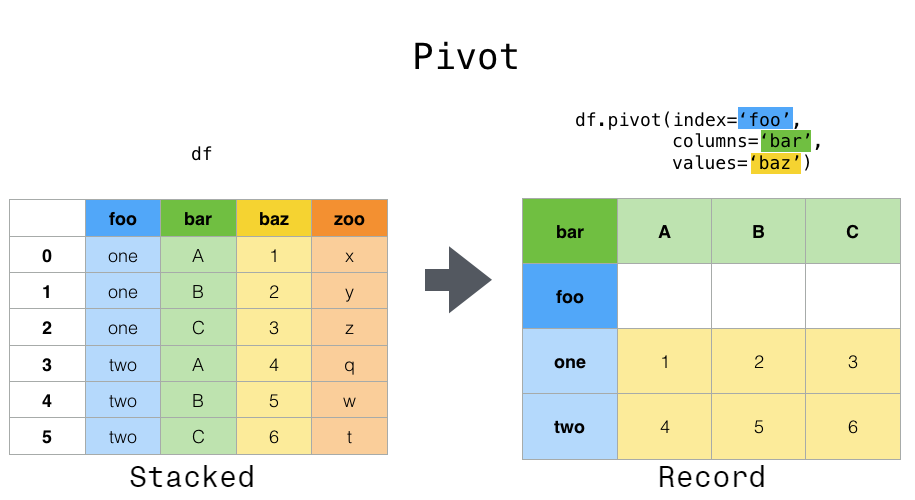
pivot
- melt의 반대 연산자로 이해할 수 있고, 중복된 값이 있는 데이터프레임을 옆으로 길게 늘려준다.
- 표본을 각 행에 대응되게 만든다.
apply
- 데이터프레임 혹은 시리즈를 대상으로 사용자 정의 함수를 적용할 수 있는 메서드이다.
- 호출 형식에 따라 함수에 입력되는 형태가 달라진다.
- 데이터프레임의 각 열
- 데이터프레임의 각 행
- 시리즈의 각 요소
- 추가 인자와 함께 사용 (kwargs)
import numpy as np
import pandas as pd
# 1. 데이터프레임의 각 열 - df.apply(func)
col_sum = df.apply(np.sum()) # axis 기본값은 0 → 열 단위
# 2. 데이터프레임의 각 행 - df.apply(func, axis=1)
# 각 행의 최대값과 최소값의 차이(범위, range) 구하기
row_range = df.apply(lambda row: row.max() - row.min(), axis=1) # axis=1 → 행 단위
# 3. 시리즈의 각 요소 - series.apply(func)
s_squared = s.apply(lambda x: x**2)
# 4. 추가 인자와 함께 사용 (kwargs)
def add_constant(col, c=0)"
return col + c
# 모든 열에 특정 상수 더하기
df_plus_100 = df.apply(add_constant, c=100) # kwargs 방식으로 c 값을 넘겨 줌
💡apply를 사용자 정의 함수와 함께 사용할 경우 python 수준의 반복이 적용되기 때문에 느리다.
💡가능한 경우 C언어로 구현된 numpy 함수를 사용하여 속도의 이점을 가져가는 것이 좋다고 생각한다.
# 나이 열 구간화
np.select(
[
df['age'] < 10,
df['age'] < 20,
df['age'] < 40,
df['age'] >= 40
],
['kid', 'teenager', 'adult', 'senior'],
default=np.nan
)